







文章目录
结构体
结构体是一些变量的集合,这些变量成为成员变量,可以是不同类型。
结构体的声明、创建变量和初始化
struct Stu
{
char name[20];
int age;
int score;
}Zhangsan;//分号不能漏!!!
struct Stu lisi = {"lisi", 20, 98};
此时分号后面的Zhangsan是用这个结构体类型创建了一个变量叫Zhangsan
也可以不按顺序初始化:
struct Stu
{
int age;
int score;
};
struct Stu Zhangsan = {.score = 98, .age = 20};
匿名结构体声明
struct
{
char name[20];
int age;
int score;
}Zhangsan;
这一次这个结构体类型是匿名的,就只能用一次了,如果再对它进行修改就会报错
结构的自引用
若定义一个链表的节点,不能在结构体中包含自己,不然结构体的大小将会变得无限大。
struct test
{
int data;
struct test;
}//这样写是错误的!!
应该这样写:
struct test
{
int data;
struct test* next;
}
另外,在结构体类型重命名前就使用重命名之后的名字,也是不行的
typedef struct test
{
int data;
Test* nect;
}Test;//这样也是错误的!!!
结构成员访问操作符
.和->都可以用来访问结构成员,只不过一个是用变量访问,一个是用指针访问
结构体变量.成员变量名
结构体指针->成员变量名
struct Stu
{
int age;
int score;
};
struct Stu s = {.score = 98, .age = 20};
struct Stu* p = &s;
printf("%d, %d", s,score, p->age);
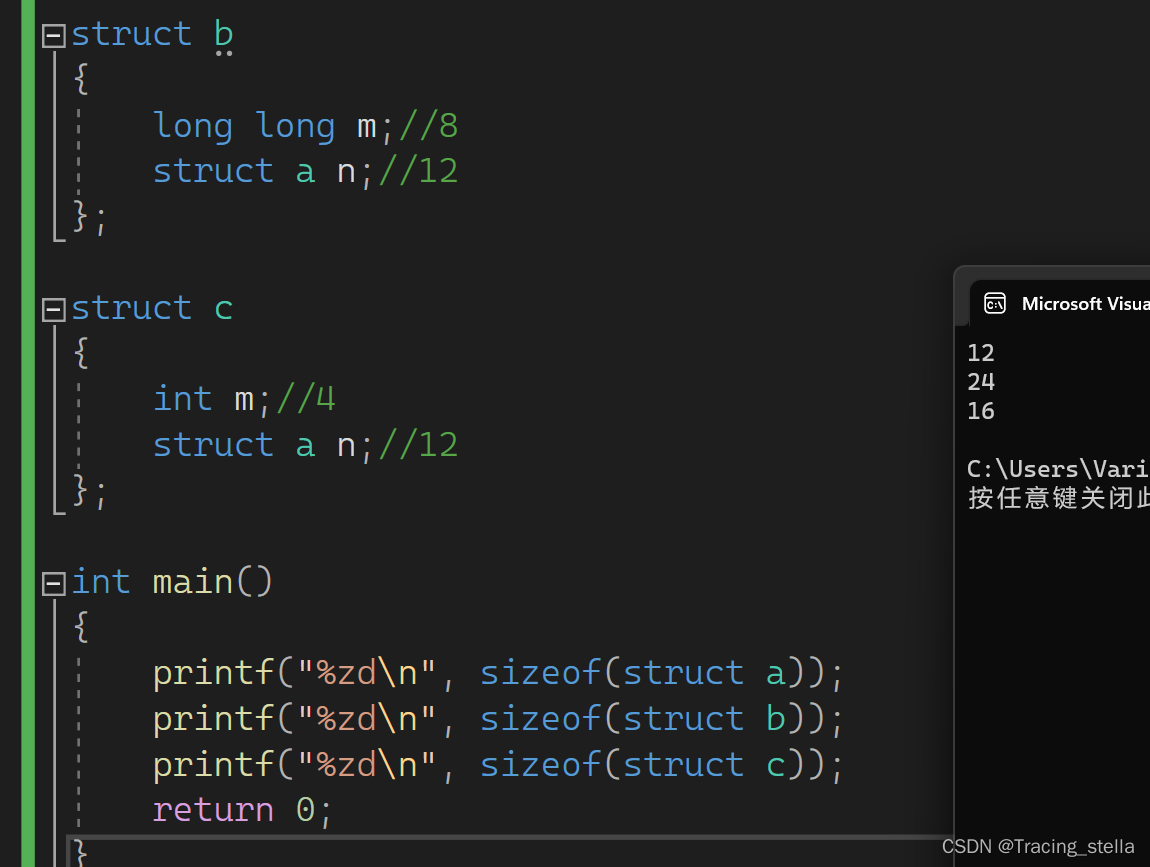
结构体内存对齐
结构体对齐规则:
- 结构体第一个成员的起始地址相对于结构体变量偏移量为0
- 其他成员要对齐到对齐数的整数倍偏移量处
- 对齐数 = 编译器默认的一个数 与 该成员变量大小的 较小值
- VS默认对齐数为8
- Linux没有默认对齐数,对齐数永远是该成员自身的大小
- 结构体大小永远是所有成员对齐数的最大值的整数倍
- 如果嵌套了结构体,那么嵌套的结构体成员对齐到自己成员中最大对齐数的整数倍处,整体的大小是所有最大对齐数的整数倍
为什么存在内存对齐?
- 平台原因:某些硬件平台只能访问某些特定地址,取出特定类型的数据。
- 性能原因:数据结构应当尽可能在自然边界上对齐。假设一个处理器总是从内存中读取8个字节,如果访问未对齐的内存,处理器需要两次访问,因为类对象可能被分在两个8字节块中;而对齐的内存只需要一次。
内存对齐,实际上是用空间换取时间的做法。如果想要节省空间,可以使占用空间小的成员尽量集中到一起。
修改默认对齐数
有一个预处理指令,可以修改编译器的默认对齐数。
#include<stdio.h>
#pragma pack(1)//修改默认对齐数为1
结构体传参
结构体传参优先选择传址调用,因为传入参数之后要先压栈,如果结构体太大,传值调用可能会占用较多空间
位段
位段的成员必须是int、unsigned int或signed int,C99中也可以是其他类型。
struct Stu
{
int age:6;
int score:8;
};
以上的age和score就是位段类型。
表示age占6个比特位,score占8个比特位。
位段大小不能超过原来类型本身的大小!!
位段在空间上是以4个字节或者1个字节的方式来开辟的
位段涉及很多不确定因素,是不跨平台的,所以可移植程序应该避免使用位段。
位段应用举例
网络数据报中IP数据的格式:

位段能够省下一定空间
联合体
联合体的声明、访问和结构体类似:
union U
{
char a;
int b;
}
联合体内,所有成员共用同一块空间,改变b很有可能会改变a
在空间分配上,联合体的大小至少是最大成员的大小。当最大成员大小不是对齐数的整数倍时,会自动补齐到整数倍。
联合体应用
假设要写一份商品清单,内容有:
书(库存,价格,书名,作者)
杯子(库存,价格,颜色)
衬衫(库存,价格,颜色,样式)
struct list
{
int stock;
int price;
union
{
struct
{
char name[50];
char author[50];
}book;
struct
{
char color[20];
}cup;
struct
{
char color[20];
char type[50];
}shirt;
}item;
};
由于一次只需要访问一件商品,所以把这三个物品的特有属性放进联合体,更省空间。
写一个函数判断当前机器是大端字节序还是小端字节序:
int check()
{
union un
{
int a;
char b;
};
un.a = 1;
return un.c;//大端返回1,小端返回0
}
枚举
顾名思义,枚举就是将变量可能的取值一一列举出来。
enum day
{
Mon,
Tue,
Wedn,
Thu,
Fri,
Sat,
Sun
};
当使用枚举时,Mon被默认替换成0,Tue被默认替换成1,以此类推…
也可以改变枚举的取值:
enum day
{
Mon = 1,
Tue,
Wedn,
Thu,
Fri,
Sat,
Sun
};
把第一个改成1之后,后面的也会依次递增。
可以把枚举中的元素初始化成任意值,但是一旦初始化之后,枚举内的元素就是常量了,是无法被修改的。
与#define的对比
枚举与define有异曲同工之妙,但是也有所区别:
- 枚举将可能结果一一列出,更为直观
- 枚举有类型检查而#define是没有类型的,编译器对枚举的使用要求更严格
- 便于调试,预处理阶段#define会被删去
- 枚举遵循作用域规则
枚举的使用
enum color
{
BLUE = 1,
RED = 3,
GREEN = 5
};
enum color cl1 = BLUE;
在C语言中,可以用整数给枚举类型赋值,如enum color cl1 = 1;,但是C++不行。















 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









