







文章目录
代码仓库在gitlab,本博客对应于03文件夹。
一、可视化工具介绍
常用的可视化工具有三个:Matplotlib、Seaborn、Plotly。其中,Matplotlib是最基础的,其他二者的都是基于它进行的封装。
1.特点
-
Matplotlib:
简单、灵活、支持多种图形
能满足使用,但是动态效果之类的无法实现 -
Seaborn:
封装了Matplotlib,易用
支持更多调色板,唯美
专注于统计专用的图表 -
Plotly:
没有前两种主流
交互性强,图形种类丰富
web应用支持很友好
Matplotlib是使用上相对最复杂的,另外两个效果更美观更现代。Plotly交互性最强,集成、交互性都不错。
2.常见图表类型
- 折线图: 简单直观,反应变化趋势。
- 散点图: 反应要素之间的关系,支持更高维度的数据可视化,不同颜色不同大小表示分类信息。
- 柱状图: 进行不同类别的对比。
- 饼图: 用来展示不同类别数据的占比。
- 直方图: 一般用来统计不同区间的数据分布。
- 漏斗图: 可以用来展示每个阶段前进到下一阶段的人有多少,凸显人的转化率、淘汰率。
二、数据集Breast Cancer Wisconsin (Diagnostic)
下面第三章会使用这个数据集进行可视化实战,因此先进行一个简单的介绍。
1.数据集简介
Breast Cancer Wisconsin (Diagnostic) 数据集是一个广泛应用在乳腺癌诊断识别领域的医学数据资源,其可通过访问以下链接获取:https://archive.ics.uci.edu/dataset/17/breast+cancer+wisconsin+diagnostic 。此集合由威斯康星大学Wolberg教授与Mangasarian教授合作构建,源自对乳腺肿瘤细胞核图像的数字化分析及特征提取过程。
该数据集内含有的每一份样本均提供了从乳腺肿块细胞核图像计算得出的30项特征参数,这些参数主要涵盖了细胞核尺寸、形态以及结构质地等多个方面,旨在辅助医生判断肿块性质,即区分肿块是恶性(乳腺癌,标记为1)还是良性(非癌性,标记为0)。
部分关键特征包括:
- 平均半径(Radius):衡量细胞核中心至边缘各点的平均距离。
- 纹理特征(Texture):反映灰度值的标准偏差,体现细胞核纹理特性。
- 周长(Perimeter):细胞核外部轮廓线的总长度。
- 面积(Area):细胞核占据的空间区域大小。
- 边界光滑度(Smoothness):量化细胞核边界局部变化的程度。
- 紧凑度(Compactness):通过计算周长的平方除以面积再减去1得到的数值,表征形状紧凑程度。
- 对称性(Symmetry):用于测定细胞核相对其几何中心的对称性指标。
- 分形维数(Fractal Dimension):描述细胞核边界的复杂性属性。
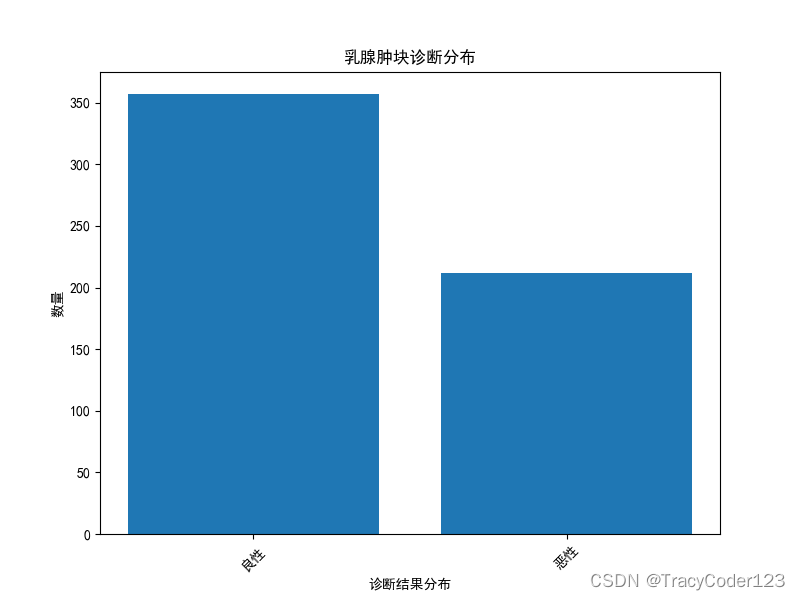
整个数据集共包含569例样本记录,其中212例被诊断为恶性乳腺癌,余下的357例则为良性乳腺肿瘤。这一数据集因其丰富的特征信息和实际病例覆盖范围,常作为开发和验证乳腺癌诊断算法的重要基准。
2.数据集解析
Breast Cancer Wisconsin (Diagnostic) 数据集的各个列详尽地记录了从乳腺肿块细胞核图像中提炼出的各项特征参数。具体解读如下:
- 第1列为样本ID(ID Number):作为每一个样本的独特标识,主要用于数据管理和追踪,尽管在直接的分析与建模过程中并非核心变量。
- 第2列为诊断类别(Diagnosis):该列明确指出了每个样本的诊断状态,区分乳腺肿块为良性(非癌性)或恶性(癌性)。其中,良性肿瘤标注为“B”,恶性乳腺癌则标记为“M”。
- 3 至 32 列:特征1至特征30(Features 1 through 30)涵盖了从乳腺细胞核图像中提取的多种量化属性。根据不同的数据集版本和特征提取技术,这些特征可能涉及细胞核的各种维度,诸如尺寸、形态、结构细节及边界特性等。典型特征包括但不限于细胞核的平均半径、纹理粗糙度、周长尺寸、面积大小、边界平滑度、形态紧凑度、对称性指标以及分形维度等。
每一特征列内的数值数据代表了相应样本在该特定特征上的量化测量值,比如细胞核平均半径的具体数值或者纹理灰度的标准偏差统计量。
三、使用可视化工具对数据进行可视化
1.针对第2列绘制条形图
数据集的第2列为诊断类别(Diagnosis),该列明确指出了每个样本的诊断状态,区分乳腺肿块为良性(非癌性)或恶性(癌性)。其中,良性肿瘤标注为“B”,恶性乳腺癌则标记为“M”。现在,来对这一列进行分析,观察良性和恶性的样本数量。
- 代码如下:
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('./breast+cancer+wisconsin+diagnostic/wdbc.data', header=None)
# 提取第二列(索引从0开始,因此是第1列)
diagnosis = data[1]
# 统计良性('B')和恶性('M')样本的数量
benign_count = diagnosis.value_counts()['B']
malignant_count = diagnosis.value_counts()['M']
# 创建数据系列
labels = ['良性', '恶性']
counts = [benign_count, malignant_count]
# 设置字体,从而正确支持中文
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制条形图
plt.figure(figsize=(8, 6))
plt.bar(labels, counts)
plt.xlabel('诊断结果分布')
plt.ylabel('数量')
plt.title('乳腺肿块诊断分布')
plt.xticks(rotation=45)
# 显示图形
plt.show()
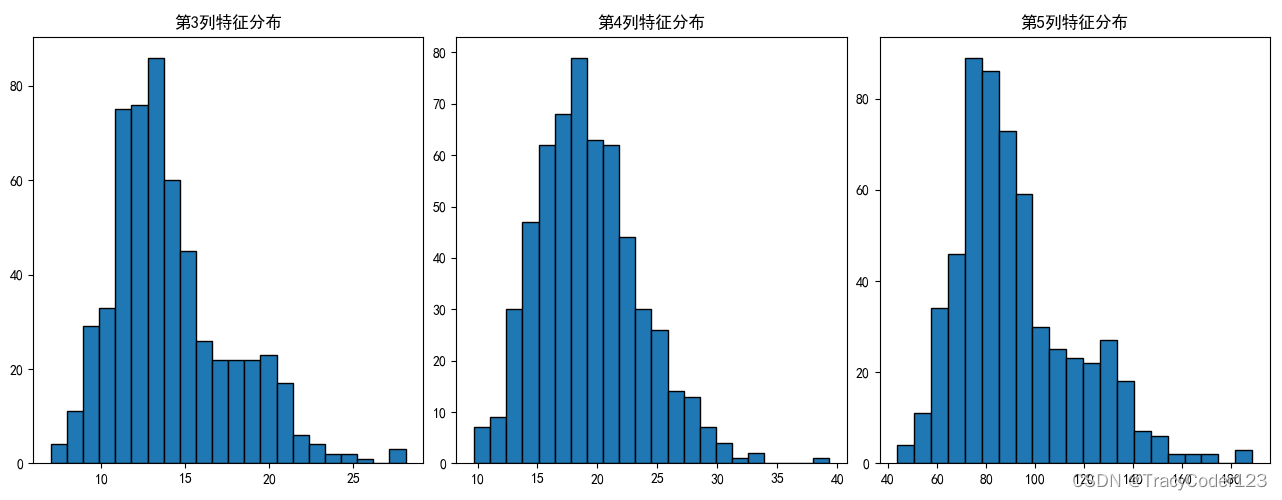
2.针对第3-5列绘制直方图
这三列特征分别代表的是肿瘤的某个测量值,我们可以逐一绘制它们的分布情况:
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('./breast+cancer+wisconsin+diagnostic/wdbc.data', header=None)
# 设置字体,从而正确支持中文
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 提取第3、4、5列的数据
column3 = data[2]
column4 = data[3]
column5 = data[4]
# 分别绘制直方图
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
# 第3列直方图
axs[0].set_title('第3列特征分布')
axs[0].hist(column3, bins='auto',edgecolor='black')
# 第4列直方图
axs[1].set_title('第4列特征分布')
axs[1].hist(column4, bins='auto',edgecolor='black')
# 第5列直方图
axs[2].set_title('第5列特征分布')
axs[2].hist(column5, bins='auto',edgecolor='black')
# 显示图形
plt.tight_layout()
plt.show()
3.针对第6-15列绘制特征相关性热力图
热力图能反应特征之间的相关性,第6-15列绘制特征相关性热力图绘制代码如下:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
data = pd.read_csv('./breast+cancer+wisconsin+diagnostic/wdbc.data', header=None)
# 设置字体,从而正确支持中文
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 只关注第6至第15列(索引从0开始,所以是5至14列)
subset_df = data.iloc[:, 5:15]
# 计算相关系数矩阵
corr_matrix = subset_df.corr()
# 创建并显示热力图
plt.figure(figsize=(12, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', linewidths=.5)
plt.title('Breast Cancer Wisconsin (Diagnostic) 数据集 - 第6至第15列特征相关性热力图')
plt.show()





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











