






Oracle
1.Oracle 数据库具有以下特点:
(1)支持多用户、大事务量的事务处理
(2)数据安全性和完整性控制
(3)支持分布式数据处理
(4)可移植性
2.Oracle体系结构
Oracle不同于MySQL只有一个数据库
一个数据库可以用多个实例(多实例保证单一数据库隔离性)
表空间是数据文件(物理存储单位)的逻辑映射,方便管理
逻辑结构:
数据库–》表空间–》段–》区–》Oracle数据块
Oracle一个数据库下有多个用户,用户下面建立表,用户只能看到自己所属的表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pzbtuQGH-1682579772850)(C:\Learning Notes\Oracle学习笔记.assets\1679908320923.png)]一个实例下存在多个用户,表空间,多个用户对应一个表空间;
用户下的表存储在同一表空间的物理映射的数据文件中
数据文件可以放在多个服务器中,逻辑映射保证Oracle的性能
数据类型
1.字符型
char 固定长度的字符类型,最多存储2000个字节
varchar2 可变长度的字符类型,最多存储4000个字节
long 大文本类型,最大可以存储2个G
2.数值型
number 数值类型
eg:number(5) 表示最多可以存储到99999
number(5,2)最大可以存储到999.99
3.日期型
DATA:日期时间型,精确到秒
TIMESTAMP:精确到秒的小数点9位
4.二进制型(大数据类型)
CLOB 存储字符,最大可以存4个G
BLOB 存储图像,声音,视频等二进制数据,最大同上
select * from all_all_tables;
select * from tabs;
select userenv('language') from dual;
select * from yzler;
--创建表空间
create tablespace yzler
datafile 'c:\saveData\yzler.dbf'
size 100m
autoextend on
next 10m;
--创建用户 用户名,密码,表空间映射
create user yzler
identified by oval0928
default tablespace yzler;
--用户赋权
grant dba to yzler
表的创建和单表增删改
--创建表
create table yzler(
id number primary key,
name varchar2(30),
age number,
birthday date
)
--追加字段
alter table yzler add(
remark varchar2(10)
)
--修改字段
alter table yzler modify(
remark char(10)
)
--修改字段名
alter table yzler rename column remark2 to remark3
--删除字段
alter table yzler drop column remark2
--删除表
--drop 表名称
insert into yzler (id,name) values (1,'xiaoming');
insert into yzler (id,name) values (2,'xiaoming2');
insert into yzler values (3,'22',10,sysdate,'aa');
commit;
--修改
--日期直接进行运算,天数
update yzler set birthday=birthday-3 where id =3;
commit;
truncate与delete相关问题
truncate table yzler2;
--效率问题 truncate 效率比 delete高
--delete删除的数据可以rollback 删除的时候将数据放入到回滚段中,回滚时,将回滚段的数据再拿回来
--delete删除可能产生碎片,并且不释放空间
--truncate是先摧毁结构,在重构结构
表的排序和伪列和和常用函数
--伪列
select rowid,y.* from yzler y;
--rowid是物理地址,比主键索引更加快,索引本质就是找到rowid来查询对象
select * from yzler order by id desc;
--rownum 只是结果集序号 与主键id无关
select rownum,y.* from yzler y where id>1;
--聚合函数
select sum(age) from yzler;
--分组聚合统计(select 后一定是分组聚合的条件字段或是聚合函数)
--字符函数 dual 伪表 一行一列的表 对单行函数的补充
select length('123') from dual;
select substr('123',2,3) from dual;
--按月截取 当月的第一天
select trunc(sysdate,'mm') from dual;
--按年截取
select trunc(sysdate,'yyyy') from dual;
select trunc(sysdate,'hh') from dual;
select trunc(sysdate,'mi') from dual;
--数字转字符串
select to_char(100) from dual;
select 100 from dual;
--字符串的拼接
select 100 || '' from dual;
--nvl 空值处理
select nvl(null,999) from dual;
select nvl(12,999) from dual;
--可以用来条件转化
--eg select nvl2(null,to_char(num), '123') from ..;
select nvl2(null,2, 1) from dual;
--decode 条件判断
--都没有匹配 选择最后的缺省值(值伪奇数)
--return 4 1是条件值,(2,3) 如果匹配2 返回3
select decode(1,2,3,4) from dual;
--return 空
select decode(1,2,3,4,5) from dual;
--case when then sql1999
select name,(case id
when 1 then 'id为1'
when 2 then '2'
else '其他'
end
) from yzler;
--分析函数
--值相同,排名相同,序号跳跃 eg 1,2,2,4
--select rank() over(order by .. desc) from ..
--值相同,排名相同,序号连续 eg 1,2,2,3
--select dense_rank() over(order by .. desc) from ..
--序号连续,不管值是否相同 eg 1,2,3,4
--select row_number() over(order by .. desc) from ..
--集合运算 去重后的 并集
select * from yzler where id > 1
union
select * from yzler where id<4
select * from yzler where id > 1
union all
select * from yzler where id<4
--交集
select * from yzler where id > 1
intersect
select * from yzler where id<4
--差集 也能实现分页
select * from yzler where id > 1
minus
select * from yzler where id<4
select rownum,t.* from yzler t where rownum <= 10
minus
select rownum,t.* from yzler t where rownum <= 3;
多表联查与分页查询
--多表联查
--sql1999写法
select * from yzler y1 left join yzler2 y2 on y1.id = y2.id;
--Oracle写法 左外连接 (+)放到右边
select * from yzler y1,yzler2 y2 where y1.id = y2.id(+);
-- a 表和 b 表做全连接
-- a 表和 b 表中的数据都会显示
SELECT * FROM a FULL JOIN b ON(a.bNO=b.NO);
-- a 表和 b 表做内连接
-- a 表中的 bNO 和 b 表中的 NO 都不为 null 且a.bNo=b.NO 组成一条新数据。
SELECT * FROM a INNER JOIN b ON(a.bNO=b.NO);
--子查询
--select字句的子查询必须为单行子查询
--eg select id,name,(select ...) from 表名
--分页查询 rownum 只能是小于或小于等于 跟rownum的原理有关系,逐行扫描
select rownum,t.* from yzler t where rownum < 2;
--处理方案 子查询 先生成数值
select * from (select rownum r,t.* from yzler t ) where r>=2 and r<6;
--rownum 基于排序的分页 先子排序,然后生产数值 最后在分页
行列转化
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-68gRuoiO-1682579772851)(C:\Learning Notes\Oracle学习笔记.assets\1679974235265.png)]
3.Oracle对象
Oracle独有的:物化视图,序列,同义词
1.视图
视图
1简单试图: 视图中语句只是单表查询,并且没有聚合函数
2复杂视图:视图的sql语句,有聚合函数和多表联查
--简单视图
select * from yzler where id =1;
create view view1 as select * from yzler where id =1;
--查询简单视图
select * from view1
--修改视图数据 原数据表也会一起变化 一条sql语句大小
update view1 set name='yzler' where id =1;
--create [or raplace][force] view 视图名 as sql语句
--[with check option][with read only]
--视图中sql返回数据不能有重复数据
create view view2312 as
select y1.* from yzler y1,yzler2 y2 where y1.id = y2.id(+);
--聚合统计的视图,不能修改
--多表联查的视图,只有键保留表中数据才能修改,键保留表是主键所在的表
2.物化视图
--创建手动刷新的物化视图 需要权限
create materialized view yzler as select * from yzler where id =1;
--需要手动刷新,执行下列语句
/*
begin
DBMS_MVIEM.refresh('yzler','C');
end;
*/
--自动刷新 基表发生commit操作后,自动刷新物化视图
create materialized view yzler
refresh
on commit as
select * from yzler where id =1;
--生成没有数据的物化视图,第一次需要去手动刷新
create materialized view yzler
build deferred
refresh
on commit as
select * from yzler where id =1;
--建立增量更新的物化日志
--前提1.创建物化视图,sql有几个表,建立几个物化视图日志
create materialized view log on 表名 with rowid
--前提2 创建物化视图的语句中,必须有基表的rowid
视图是为了简化开发,物化视图是为了提高效率
物化视图的作用,提高查询效率,因为,复杂视图查询多张表,物化后相当于查询一条表,相对于它占有物理空间
3.序列
创建序列后必须先完成初始化,即 序列名.nextval
序列 Oracle没有自增,目的为了取值
--创建简单序列
create sequence seq_test;
--查询序列的下一个值
select seq_test.nextval from dual;
--查询当前序列的值
select seq_test.currval from dual;
--有最大值的非循环序列
create sequence seq_test2
maxvalue 10;
select seq_test1.nextval from dual;
create sequence seq_test3
increment by 10
start with 10
maxvalue 20;
select seq_test3.nextval from dual;
--Oracle默认cache=20
--cache的作用:当设置cache=20,第一次新增时,会往Oracle服务器的缓存中,存储20个整数值,例如,我们第一次新增是从1开始,就会把1到20这个20个数字存储到Oracle缓存中,当下一次新增时,直接从缓存中获取数字
create sequence seq_test4
increment by 10
start with 10
minvalue 2
maxvalue 201
cycle;
--一次循环的个数等于 maxvalue-minvalue
--一次缓存的数等于 cache值*增长值
-- 条件:一个循环的值不能小于一次缓存的数 (只限制在循环下)
select seq_test4.nextval from dual;
--修改和删除序列
--不能更改序列的 start with 参数
--alter sequence 序列名称 maxvalue 数值 cycle;
--删除序列
--drop sequence 序列名称
4.同义词
同义词就是别名 私有(当前用户才能访问)和公有
--同义词 可以理解为别名 可以为表,视图,序列创建同义词
--私有的同义词仅能供当前用户访问
create synonym t for yzler;
select * from t;
-- 也可以创建公有的同义词
-- varchar是varchar2的同义词,因此创建表的时候也能用varchar
-- eg create public synoym t2 for yzler
5.索引
--创建普通索引
--create index index_name on yzler(name);
--创建唯一索引
--create unique index 索引名称 on 表名(列名);
--创建复合索引
--create index 索引名称 on 表名(列名,列名...);
--创建反向键索引
--create index 索引名称 on 表名(列名) reserve;
--创建位图索引
--create bitmap index 索引名称 on 表名(列名);
索引 普通索引,唯一索引,复合索引,反向键索引(连续数值),位图索引(低基数列 有限个数字,不能太长)
4.Oracle编程
1.基础语法
declare
price number;
name varchar2(20);
begin
price:=123;
name:='yzler';
dbms_output.put_line('金额是'||price);
end;
--select 列名 into 变量名 返回单行数据,返回多个行记录数据用游标
declare
price number;
name1 varchar2(20);
begin
price:=123;
select name into name1 from yzler where id =4;
dbms_output.put_line('名称是'||name1 ||'金额是'||price);
end;
--属性类型(引用型 表名.列名%type)
declare
price number;
name1 yzler.name%type;
begin
price:=123;
select name into name1 from yzler where id =5;
dbms_output.put_line('名称是'||name1 ||'金额是'||price);
end;
-- 属性类型(记录型 表名%rowtype 相当于实体类,记录一行的数据)
declare
price number;
name1 yzler.name%type;
yrow yzler%rowtype;
begin
price:=123;
select * into yrow from yzler where id =4;
dbms_output.put_line('名称是'|| yrow.name ||'金额是'||price);
end;
--异常(例外)
--预定义异常,用户自定义异常
declare
price number;
name1 yzler.name%type;
begin
price:=123;
select name into name1 from yzler where id =15;
dbms_output.put_line('名称是'||name1 ||'金额是'||price);
exception
when no_data_found then
dbms_output.put_line('没有找到相关记录');
end;
2.条件判断
-- 语法 条件判断
--if 条件 then
--end if;
declare
price number;
name1 yzler.name%type;
begin
price:=123;
select name into name1 from yzler where id =1;
if price > 100 then
dbms_output.put_line('大于');
end if;
dbms_output.put_line('名称是'||name1 ||'金额是'||price);
exception
when no_data_found then
dbms_output.put_line('没有找到相关记录');
end;
--if 条件 then
--else
--end if;
declare
price number;
sorce number;
name1 yzler.name%type;
begin
price:=123;
sorce:=80;
select name into name1 from yzler where id =1;
if sorce > 90 and sorce<=100 then
dbms_output.put_line('优秀');
elsif sorce > 60 and sorce<=90 then
dbms_output.put_line('良好');
else
dbms_output.put_line('不及格');
end if;
dbms_output.put_line('名称是'||name1 ||'金额是'||price);
exception
when no_data_found then
dbms_output.put_line('没有找到相关记录');
end;
--if 条件 then
--elsif 条件 then
--elsif 条件 then
--end if;
3.循环
--无条件循环
/*
loop
循环语句
end loop;
*/
declare
num1 number;
begin
num1:=1;
loop
num1:=num1+1;
dbms_output.put_line(num1);
if num1 > 10 then
exit;
end if;
end loop;
end;
--有条件循环
declare
num1 number;
begin
num1:=1;
while num1<=11
loop
dbms_output.put_line(num1);
num1:=num1+1;
end loop;
end;
--for 循环
declare
begin
for num1 in 1..100
loop
dbms_output.put_line('没有找到相关记录');
end loop;
end;
4.游标
游标是系统为用户开设的数据缓冲区,可以理解为结果集,分布缓存的,不会一下子提取全部数据
--游标 输出结果集
select * from t where name='33';
declare
data1 yzler%rowtype;
cursor cur is select * from t where name='33';--声明游标
begin
open cur; --打开游标
loop
fetch cur into data1; --提取游标
exit when cur%notfound; --退出游标
dbms_output.put_line('1'||data1.age||data1.remark2);
end loop;
close cur;
end;
--带参数的游标
select * from t where name='33';
declare
data1 yzler%rowtype;
cursor cur(vnum varchar2) is select * from t where name=vnum;--声明游标
begin
open cur('33'); --打开游标
loop
fetch cur into data1; --提取游标
exit when cur%notfound; --退出游标
dbms_output.put_line('1'||data1.age||data1.remark2);
end loop;
close cur;
end;
--for 循环 带参数的游标
declare
cursor cur(vnum varchar2) is select * from t where name=vnum;--声明游标
begin
for data1 in cur('33')
loop
dbms_output.put_line('1'||data1.age||data1.remark2);
end loop;
end;
5.存储函数
--存储函数
create or replace function fn_test(vid number)
return varchar2
is
vname varchar2(30);
begin
select name into vname from t where id = vid;
return vname;
end;
--单表
select fn_test(1) from dual;
-- 整张表,每一行都会去调用这个函数
select fn_test(2) from yzler;
存储过程与存储函数都可以封装一定的业务逻辑并返回结果,存在区别如下
1、存储函数中有返回值,且必须返回:而存储过程设有返回值,可以通过传出参数返回多个值。
2.存储函数可以在select语句中直接使用,而存储过程不能,过程多数是被应用程序所调用,
3、存储函数一般都是封装一个查询结果,而存储过程一般都封装一段事务代码。
自定义函数不能含有DDL语句,也不能包含INSERT/UPDATE/DELETE,否则,虽然编译和单步测试(使用pl/sql工具)能够通过,但在实际调用时会出错:ORA-14551: cannot perform a DML operation inside a query。
6.储存过程
--存储过程 不带参数的存储过程
create sequence seq_test;
create or replace procedure pro_test
(vname varchar2,vage number,vremark varchar)
is
begin
insert into yzler values(seq_test.nextval,vname,vage,sysdate,vremark);
commit;
end;
--调用不带参数的存储过程的两种方式
call pro_test('i love you',19,'demo练习');
begin
pro_test('i love you',28,'demo2练习');
end;
--存储过程 带参数的存储过程
create or replace procedure pro_test
(vname varchar2,vage number,vremark varchar,vid out number)
is
begin
select seq_test.nextval into vid from dual;
insert into yzler values(vid,vname,vage,sysdate,vremark);
commit;
end;
--调用传出参数的储存过程
declare
vid number;
begin
pro_test('demi',20,'123',vid);
dbms_output.put_line('id'||vid);
end;
作用:减少应用服务器和数据库之间不必要的会话
比如说一些日常后台的数据的统计,不需要用户进行交互
7.触发器
数据库触发器是一个与表相关联的、存储的PL/SQL程序。每当一个特定的数据操作语句nsert,update.delete)在指定的表上发出时,Oracle自动地执行触发器中定义的语句序列。不允许出现事务控制
应用场景
- 数据确认
- 安全性检查
- 审计,跟踪表上所作的数据操作
- 数据的备份和同步
触发器的分类
- 前置触发器
- 后置触发器
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7UEGlSJW-1682579772852)(C:\Learning Notes\Oracle学习笔记.assets\1680073008752.png)]
for each row
行级触发器 ,语句级触发器
1、 行级触发器对DML语句影响的每个行执行一次。(:NEW 和:OLD使用方法和意义,new 只出现在insert和update时,old只出现在update和delete时。在insert时new表示新插入的行数据,update时new表示要替换的新数据、old表示要被更改的原来的数据行,delete时old表示要被删除的数据。)
2、 语句级触发器对每个DML语句执行一次,如果一条INSERT语句在TABLE表中插入500行,那么这个表上的语句级触发器只执行一次,而行级的触发器就要执行500次了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QDmrMv7b-1682579772852)(C:\Learning Notes\Oracle学习笔记.assets\1680074540229.png)]
--前置触发器
create or replace trigger tri_test
before
update of age
on t
for each row
declare
begin
:new.name:= :new.age-:old.age;
end;
--后置触发器
--用于日志操作
create sequence seq_test4;
select seq_test4.nextval from dual;
--需要序列先初始化
select seq_test4.currval from dual;
create table yzler_log(
id number,
oldname varchar2(20),
newname varchar(20),
updatetime date
)
create or replace trigger trilog
after
update of name
on yzler
for each row
declare
begin
insert into yzler_log values(seq_test4.nextval,:old.name,:new.name,sysdate);
end;
update yzler set name = '后置触发器1' where id =3
select * from yzler_log;
Oracle一些问题和注意事项:
1.索引使用问题
客户化一律使用PL/SQLDev工具预先测试SQL语句的性能,观察执行计划,如果存在全表扫描,而全表扫描的表中记录超出100条,要建立相应索引或者改变查询条件,使用索引列查询,避免全表扫描。
这里要考虑索引失效的场景来避免,原文参选:(37条消息) oracle数据库中索引会失效的几种情况_oracle索引失效的几种情况_Archie_java的博客-CSDN博客
- 1. 没有 WHERE 子句
- 2. 使用 IS NULL 和 IS NOT NULL
- 3. WHERE 子句中使用函数
- 4. 使用 LIKE ‘%T’ 进行模糊查询
- 5. WHERE 子句中使用不等于操作
- 6. 等于和范围索引不会被合并使用
- 7. 比较不匹配数据类型
2.in 与 exists 的区别
exists”和“in”的效率问题,涉及到效率问题也就是sql优化:
1.若子查询结果集比较小,优先使用in。
2.若外层查询比子查询小,优先使用exists。原理是:若匹配到结果,则退出内部查询并将条件标志为true,传回全部结果资料
因为若用in,则oracle会优先查询子查询,然后匹配外层查询,原理是:in不管匹配到匹配不到都全部匹配完毕,匹配相等就返回true,就会输出一条元素.
若使用exists,则oracle会优先查询外层表,然后再与内层表匹配
也就是:”匹配原则,拿最小记录匹配大记录。也就是遍历的次数越少越好"
当B表比A表数据大时适合使用exists(),因为它没有那么遍历操作,只需要再执行一次查询就行.
如:A表有10000条记录,B表有1000000条记录,那么exists()会执行10000次去判断A表中的id是否与B表中的id相等.
如:A表有10000条记录,B表有100000000条记录,那么exists()还是执行10000次,因为它只执行A.length次,可见B表数据越多,越适合exists()发挥效果
再如:A表有10000条记录,B表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历比较,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快.
select * from A where not exists(select * from B where A.id = B.id);
select * from A where exists(select * from B where A.id = B.id);
详细步骤(使用exists):
1,首先执行外查询select * from A,然后从外查询的数据取出一条数据传给内查询。
2,内查询执行select * from B,外查询传入的数据和内查询获得数据根据where后面的条件做匹对,如果存在数据满足A.id=B.id则返回true,如果一条都不满足则返回false。
3,内查询返回true,则外查询的这行数据保留,反之内查询返回false则外查询的这行数据不显示。外查询的所有数据逐行查询匹对。
not exists和exists的用法相反,就不继续啰嗦了。
3.Order By 和Group By 和Distinct的使用 (cpu)
当存在嵌套查询时,内层不需要做order by处理,不要加 Order By 子句(除非是为了得到rownum的需要);
如果没有分组(标志是使用分组函数,如Sum()/Avg()等)处理,也没有distinct 要求,不要使用Group by;
如果能够通过Where条件过滤得到唯一要查询的结果,禁止使用宽泛条件+Distinct来得到要查询的结果;如果查询结果在不使用Distinct时已经是唯一不重复结果,禁止再使用Distinct;
4.!= 、 <>、^= 三个符号都表示“不等于”的意思,在逻辑上没有本质区别
但是要主义的是三个符号在表达“不等于”含义的同时,隐含一个“不为空 is not null”的前提,所以使用时null会被过滤掉
5.SQL 分类:
SQL 语句主要可以划分为以下 3 个类别。
**DDL(Data Definition Languages)语句:**数据定义语言,这些语句定义了不同的数据段、数据库、表、列、索引等数据库对象的定义。常用的语句关键字主要包括 create、drop、alter等。
**DML(Data Manipulation Language)语句:**数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性,常用的语句关键字主要包括 insert、delete、udpate 和select 等。(增添改查)
**DCL(Data Control Language)语句:**数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括 grant、revoke 等。
6.开发注意事项
各位技术人员:
禁止在存储过程中用下面的方式把常量赋值给变量!!!!要直接使用v_item:=‘HRSH’;
select ‘HRSH’ into v_item from dual; 改为:v_item:=‘HRSH’
select sysdate into v_thisdate from dual; 改为:v_thisdate:=sysdate;
原则:能不查库的就坚决不要查询数据库;
Oracle的基本数据类型
char,varchar2,long
number
date,timestamp
clob ,blob
知识点:
sql语句查询中exists中为什么要用select 1?
如果有查询结果,查询结果就会全部被1替代(当不需要知道结果是什么,只需要知道有没有结果的时候会这样用),可以提高语句的运行效率,在大数据量的情况下,提升效果非常明显
INSTR用法
INSTR方法的格式为:INSTR(源字符串, 要查找的字符串, 从第几个字符开始(默认为1), 要找到第几个匹配的序号(默认为1))
返回找到的位置,如果找不到则返回0.
例如:INSTR(‘CORPORATE FLOOR’,‘OR’, 3, 2)中,源字符串为’CORPORATE FLOOR’, 在字符串中查找’OR’,从第三个字符位置开始查找"OR",取第三个字后第2个匹配项的位置。
默认查找顺序为从左到右。当起始位置为负数的时候,从右边开始查找。
所以SELECT INSTR(‘CORPORATE FLOOR’, ‘OR’, -1, 1) “aaa” FROM DUAL的显示结果是
Instring
——————
14
为什么是14而不是13,因为oracle这里第一个位置是1而不像java是0
与like模糊查询的比较
instr(title,‘手册’)>0 相当于 title like ‘%手册%’
instr(title,‘手册’)=1 相当于 title like ‘手册%’
instr(title,‘手册’)=0 相当于 title not like ‘%手册%’
转载:oracle中instr函数用法 与 like模糊查询的比较 - 1024搜-程序员专属的搜索引擎 (1024sou.com)
分析函数over
Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是对于每个组返回多行,而聚合函数对于每个组只返回一行。
1、分析函数和聚合函数的不同之处:
分析函数和聚合函数很多是同名的,意思也一样,只是聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。简单的说就是聚合函数返回统计结果,分析函数返回明细加统计结果。
lag和lead函数
lag和lead函数,用于取出数据的前n行的数据和后n行的数据,当然要和over(order by)一起组合
lag和lead函数,用于取出数据的前n行的数据和后n行的数据,当然要和over(order by)一起组合
lead(col_name,num,flag)
col_name是列名;num是取向下第几个值;flag是一个标志,也就是如果向下第几个值是空值的话就取flag;
例如lead(login_time,1,null)这个是向下取一个值,如果这个值为空则按空算,当然也可以用其他值替换。
lag(col_name,num,flag)
和lead类似,col_name是列名;num是取向上第几个值;flag是一个标志,也就是如果向上第几个值是空值的话就取flag;
例如lag(login_time,1,null)这个是向上取一个值,如果这个值为空则按空算,当然也可以用其他值替换。
group by是分组函数,partition by是分区函数(像sum()等是聚合函数),注意区分。
over函数的写法:
over(partition by cno order by degree )
先对cno 中相同的进行分区,在cno 中相同的情况下对degree 进行排序
Oracle中“execute immediate”是什么意思?
execute immediate 是用于在 存储过程里面. 动态的执行 SQL 语句。
EXECUTE IMMEDIATE 一般用于 执行动态 SQL
例如:
SQL> BEGIN
2 EXECUTE IMMEDIATE ( 'SELECT * FROM test_dysql WHERE id=1' );
3 END;
在Oracle中,汉字占2个字节
在不同的数据库,因为字符集的不同,LENGTHB得到的值可能会不一样。如ZHS16GBK采用两个byte位来定义一个汉字。而在UTF8,采用3个byte。
length --返回以字符为单位的长度.
SQL>select length('安庆') from dual;
2
SQL>select lengthb('安庆') from dual;
4
lengthb --返回以字节为单位的长度.
GOTO
goto
属于plsql控制语句,用于程序控制非条件跳至指定标签<<???>>。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CY1AiDKE-1682579772853)(C:\Learning Notes\Foundation框架.assets\1681885741996.png)]
Oracle的Replace函数与translate函数详解与比较
replace 字符串级别的代替
如:SELECT REPLACE('accd','cd','ef') from dual; -->
aefd
translate 字符级别的代替
如:select translate('acdd','cd','ef') from dual;
-->aeff
replace:语法:REPLACE(char,search_string[,replacement_string])
解释:replace中,每个search_string都被replacement_string所代替
select replace('acdd','cd','ef') from dual; --> aefd
如果replacement_string为空或为null,那么所有的search_string都被移除
select replace('acdd','cd','') from dual; --> ad
如果search_string 为null,那么就返回原来的char
select replace('acdd','ef') from dual; -->acdd
select replace('acdd','','') from dual; -->acdd(也是两者都为空的情况)
translate:语法:TRANSLATE('char','from_string','to_string')
TRANSLATE(列/字符串,'要转换的字符串','转换成什么');
①正常转换
SELECT TRANSLATE('ABCDEFGH','AB','**') FROM DUAL;
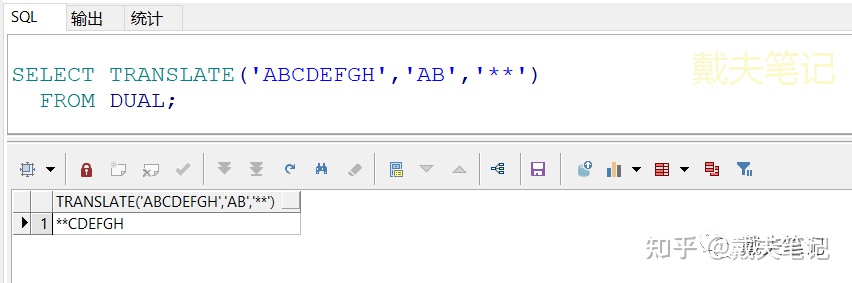
②当“要转换的字符串”不在对象(列/字符串)里面时,不会报错,原封不动输出。
SELECT TRANSLATE('ABCDEFGH','IJ','KL') FROM DUAL
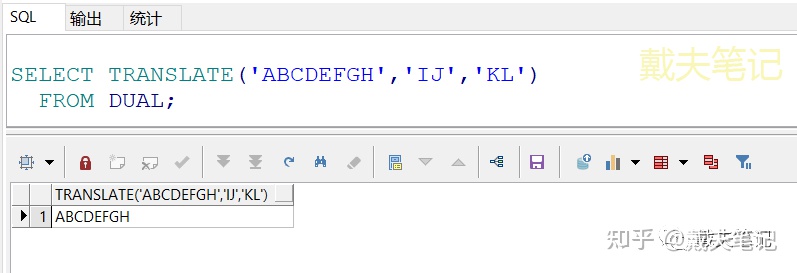
③当“要转换的字符串”多于“转换成什么”时,多出来的部分是没有替换效果的。
SELECT TRANSLATE('ABCDEFGH','ABC','*') FROM DUAL;
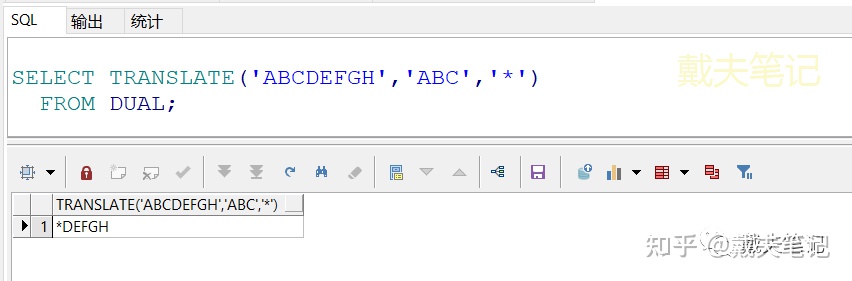
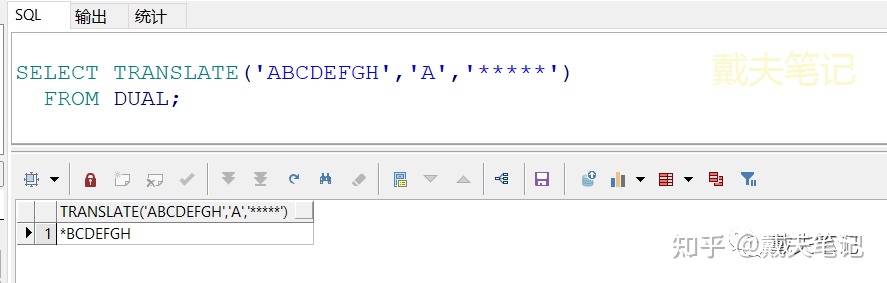
④当“要转化的字符串”小于“转换成什么”时,少的部分不会自动填补。
SELECT TRANSLATE('ABCDEFGH','A','*****') FROM DUAL;
te(‘acdd’,‘cd’,‘ef’) from dual;
–>aeff
replace:语法:REPLACE(char,search_string[,replacement_string])
解释:replace中,每个search_string都被replacement_string所代替
select replace(‘acdd’,‘cd’,‘ef’) from dual; --> aefd
如果replacement_string为空或为null,那么所有的search_string都被移除
select replace(‘acdd’,‘cd’,‘’) from dual; --> ad
如果search_string 为null,那么就返回原来的char
select replace(‘acdd’,‘ef’) from dual; -->acdd
select replace(‘acdd’,‘’,‘’) from dual; -->acdd(也是两者都为空的情况)
translate:语法:TRANSLATE(‘char’,‘from_string’,‘to_string’)
TRANSLATE(列/字符串,‘要转换的字符串’,‘转换成什么’);
①正常转换
```
SELECT TRANSLATE('ABCDEFGH','AB','**') FROM DUAL;
```
[外链图片转存中...(img-fJoYIvAc-1682579772853)]
②当“要转换的字符串”不在对象(列/字符串)里面时,不会报错,原封不动输出。
```
SELECT TRANSLATE('ABCDEFGH','IJ','KL') FROM DUAL
```
[外链图片转存中...(img-wV2eJOak-1682579772854)]
③当“要转换的字符串”多于“转换成什么”时,多出来的部分是没有替换效果的。
```
SELECT TRANSLATE('ABCDEFGH','ABC','*') FROM DUAL;
```
[外链图片转存中...(img-MFP2yMei-1682579772854)]
④当“要转化的字符串”小于“转换成什么”时,少的部分不会自动填补。
```
SELECT TRANSLATE('ABCDEFGH','A','*****') FROM DUAL;
```
[外链图片转存中...(img-VEq9HBF3-1682579772855)]















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









