




每个公司想要进行数据分析或数据挖掘,收集日志、ETL都是第一步的,今天就讲一下如何实时地(准实时,每分钟分析一次)收集日志,处理日志,把处理后的记录存入Hive中,并附上完整实战代码
1. 整体架构
思考一下,正常情况下我们会如何收集并分析日志呢?
首先,业务日志会通过Nginx(或者其他方式,我们是使用Nginx写入日志)每分钟写入到磁盘中,现在我们想要使用Spark分析日志,就需要先将磁盘中的文件上传到HDFS上,然后Spark处理,最后存入Hive表中,如图所示:
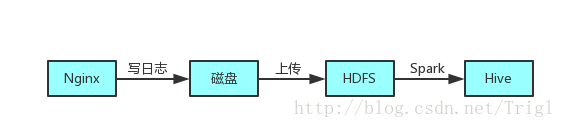
我们之前就是使用这种方式每天分析一次日志,但是这样有几个缺点:
首先我们的日志是通过Nginx每分钟存成一个文件,这样一天的文件数很多,不利于后续的分析任务,所以先要把一天的所有日志文件合并起来
合并起来以后需要把该文件从磁盘传到Hdfs上,但是我们的日志服务器并不在Hadoop集群内,所以没办法直接传到Hdfs上,需要首先把文件从日志服务器传输到Hadoop集群所在的服务器,然后再上传到Hdfs
最后也是最重要的,滞后一天分析数据已经不能满足我们新的业务需求了,最好能控制在一个小时的滞后时间
可以看出来我们以前收集分析日志的方式还是比较原始的,而且比较耗时,很多时间浪费在了网络传输上面,如果日志量大的话还有丢失数据的可能性,所以在此基础上改进了一下架构:
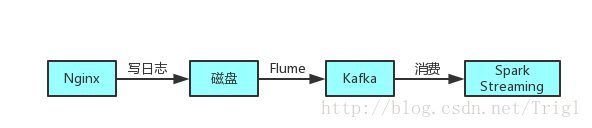
整个过程就是,Flume会实时监控写入日志的磁盘,只要有新的日志写入,Flume就会将日志以消息的形式传递给Kafka,然后Spark Streaming实时消费消息传入Hive
那么Flume是什么呢,它为什么可以监控一个磁盘文件呢?简而言之,Flume是用来收集、汇聚并且移动大量日志文件的开源框架,所以很适合这种实时收集日志并且传递日志的场景
Kafka是一个消息系统,Flume收集的日志可以移动到Kafka消息队列中,然后就可以被多处消费了,而且可以保证不丢失数据
通过这套架构,收集到的日志可以及时被Flume发现传到Kafka,通过Kafka我们可以把日志用到各个地方,同一份日志可以存入Hdfs中,也可以离线进行分析,还可以实时计算,而且可以保证安全性,基本可以达到实时的要求
整个流程已经清晰了,下面各个突破,我们开始动手实现整套系统
2. 实战演练
2.1 安装Kafka
下载安装Kafka以及一些基本命令请传送到这里: Kafka安装与简介
安装好以后新建名为launcher_click的topic:
bin/kafka-topics.sh --create --zookeeper hxf:2181,cfg:2181,jqs:2181,jxf:2181,sxtb:2181 --replication-factor 2 --partitions 2 --topic launcher_click查看一下该topic:
bin/kafka-topics.sh --describe --zookeeper hxf:2181,cfg:2181 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 155
155








 到【灌水乐园】发言
到【灌水乐园】发言







