







论文
论文:Deep Speaker: an End-to-End Neural Speaker Embedding System
摘要
我们提出了Deep Speaker,一个神经说话人嵌入系统,它把语音映射到一个超球面上,使用余弦相似性来衡量说话人相似性。Deep Speaker产生的嵌入可以用于许多任务中,包括说话人验证、识别和聚类。我们在实验中使用ResCNN和GRU结构去提取声学特征,然后是均值池化产生话语级的说话人嵌入,训练中使用了基于余弦相似性的三元组损失。在三个不同数据集上的实验表明Deep Speaker胜过了基于DNN的ivec基准系统。我们提出的结果还表明一个使用普通话数据集训练的模型可以提升对英语说话人识别的准确度。
模型结构
本文提出测试了两种模型结构ResCNN和GRU,并且分别使用三种损失函数,softmax、triplet和softmax (pre-train) + triplet。
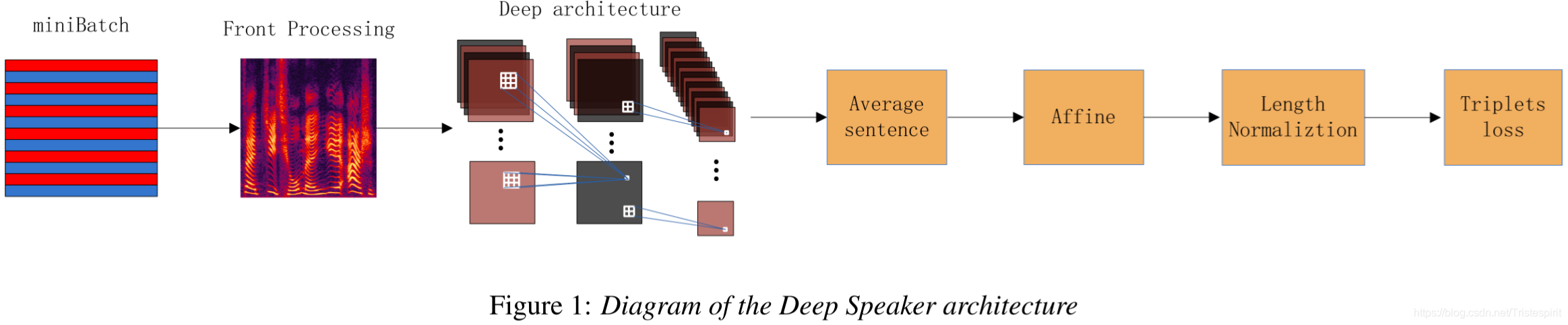
图1就是Deep Speaker的结构。本文使用两种不同的核心结构:一个ResNet style deep CNN和Deep Spech 2-style结构(几个卷积层加上GRU层)。最后的triplet loss把相同说话人嵌入的余弦相似性最大化,不同说话人嵌入的余弦相似性最小。
神经网络结构
Residual CNN
虽然深度神经网络比浅层神经网络有更大的容量,但是往往也更加难以训练。残差网络可以缓解非常深的卷积神经网络的训练,它由若干堆叠的残差块组成。每一个残差块包含了从更低层输出到更高层输入的直接连接,如图2:

这个残差块可以用下面的式子定义:

其中x和h是输入和输出,F是堆叠的非线性层的映射函数,注意x的恒等连接没有增加任何额外的参数和计算复杂度。

表1展示了提出的ResCNN结构的细节,就如图1中所描述的,残差块中包含了两个卷积核为3x3,步长1x1的卷积层(这里的步长我认为是在两个维度,如果理解错误请大佬告诉我),每个块有一个恒等结构,它是一个恒等映射。在本文的结构中3个块被堆叠在一起。当通道数增加的时候,我们使用一个单独的卷积核大小为5x5,步长为2x2的卷积层,所以频率的维度始终保持不变。我们发现说话人识别的性能对时间维度的步长并不敏感,这和另外一篇论文的研究结果相反。值得注意的是,当通道的数量增加的时候,映射路径没有像[1]中一样被使用,因为它们增加了参数的数量没有取得显著的提升。我们采用序列批归一化[2],我们使用简化的ReLU[2]作为激活函数,
![]()
GRU Network
我们也在实验中用循环神经网络提取帧层的特征,因为它们在说话人识别中的良好表现。GRU和有遗忘门的LSTM有相媲美的性能。我们决定使用GRU,因为之前的在更小的数据集上的说话人识别实验表明GRU和LSTM达到了相似的准确度对于相同数量的参数,但是GRU训练更快以及更容易收敛。

表2中是GRU的详细结构,卷积层的描述类似之前的ResCNN的结构,减少了时间和频域维度,使得GRU层的计算速度更快。在GRU之后同样是均值池化、仿射变换和长度归一化,和ResCNN一样。也在整个模型中使用序列批归一化和简化的ReLU激活函数。
说话人嵌入
帧级别的激活值被输入到一个时间均值池化层,并且没有使用输出的标准差。该层的激活值h按下面的式子计算:

其中T是语音中帧的数量。然后一个仿射变换层把话语级的表示映射为一个512维的嵌入。
我们标准化嵌入,使其拥有单位值以及在目标函数中使用pairs之间的余弦相似性。

其中xi和xj是两个嵌入。
三元组损失以及选择
三元组损失的想法来自于一篇计算机视觉的论文{3],具体信息也可以看看之前一篇博客,与之不同的是上一篇博客谈到的论文使用的是欧氏距离,而本文使用的是余弦距离,但主要都是符合一个约束:


由式5可以得到代价函数:

其中[x]+ = max(x, 0),关键是找出不符合约束式(5)的“硬”三元组,使得L靠近0。
softmax预训练
为了在早期的训练中避免局部最优值,使用semi-hard negative,使其远离positive,但是还是很困难,因为AN和AP的余弦相似性太接近了,如下式:
![]()
在开始的epochs,模型训练仅仅使用semi-hard negative样本,后面的普通训练使用hard negative。然而由于模型和数据集的可变性,合适地安排semi-hard negative样本并不简单。在semi-hard 训练阶段我们使用softmax和交叉熵损失去预训练模型。使用一个分类层去代替长度归一化层和三元组损失在图1的标准Deep Speaker结构中。
预训练的好处:
1.交叉熵损失产生比三元组损失更加稳定的收敛(猜测是因为没有被三元组损失中变量对的困难影响)。
2.虽然更大的最小批让三元组选择更快,但更小的最小批通常会产生更好的泛化性在SGD中。
设计了对比实验验证准确率(ACC)和EER,前10个epochs使用softmax预训练,后15个epochs使用三元组损失,如下图:

数据集
UIDs (including Train250k, Train50k and Eva200), XiaoDu, and MTurk(都是私有数据集)
结果
softmax预训练

使用预训练的模型的优势非常的明显。
网络结构
对于使用同一种损失函数的不同网络结构,如表5,
- softmax:GRU优于ResCNN;
- triplet:ResCNN优于GRU;
- softmax + triplet loss:GRU和ResCNN都达到了最优,后者比前者略有优,但是前者处理批的速度更快。
系统融合

两种融合方式;
- embedding fusion:把两种模型产生的embedding加在一起,然后使用长度归一化和余弦分数;
- score fusion:首先使用样本均值和样本方差标准化分数,然后把他们加到一起;
score fusion得到了更好的性能。
训练数据的数量

很显然,训练数据的大的时候,系统性能获得了提升。
注册语音的数量

这部分的实验其实在上一篇博客谈到的论文里有,当语音数量大于5时获得的提升很少,但是会增加系统的开销。
在XiaoDu上的文本相关的实验
表中分为3部分,没有标记的是在XiaoDu上训练的,有“on Train50k”的是只在Train50k上训练的,有“finetuned”标记的是先使用Train50k训练,然后使用XiaoDu微调。

在第一部分,i-vec的系统获得了最好的性能,作者猜测有两个原因,一是XiaoDu数据集对于训练一个像Deep Speaker一样的复杂深度模型太小了以及也许过拟合了。二是文本相关的说话人验证任务约束了词典和音素的可变性,所以基于因子分析的i-vec提取器能更好的覆盖小数据集的说话人可变性。
在第二部分,使用Train50k训练的模型取得了显著的性能提升,说明在文本无关数据集上训练的模型能很好的工作在文本相关的任务中。
在第三部分,三种模型的性能都得到了提升,这表明在大型文本无关的数据集上预训练能对有数据约束的文本相关场景有帮助。作者推测是因为大型的数据集能更好的覆盖样本的多样性以及使模型产生泛化性。
在MTurk上的文本无关的实验

表中数据的意义和上面的解释类似。表中数据表明Deep Speaker能够跨语言工作。使用普通话数据集训练的模型能很好的工作在英语的说话人识别中。Deep Speaker学习到的表示能很好的迁移到不同的语言中。
UIDs上的时间跨度的实验
因为人的声纹和外表一样会随着时间发生改变,所以测试了模型在时间上的鲁棒性。

“1 week”表示时间间隔小于1 week,“1 month”表示时间间隔大于1week小于1month,“3month”表示时间间隔大于1month。可以发现模型的性能随着时间跨度的增大而降低,但ResCNN仍然实现了最好的性能。
[1]He, Kaiming, Zhang, Xiangyu, Ren, Shaoqing, and Sun, Jian. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770 778, 2016.
[2]Amodei, D., Anubhai, R., Battenberg, E., Carl, C., Casper, J., Catanzaro, B., Zhu, Z. Deep-speech 2: End-to-end speech recognition in English and Mandarin.https://arxiv.org/abs/1512.02595
[3]Schroff, F., Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 815-823

















 2828
2828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









