







一、模型下载
首先到modelscope网站下载模型:魔搭社区
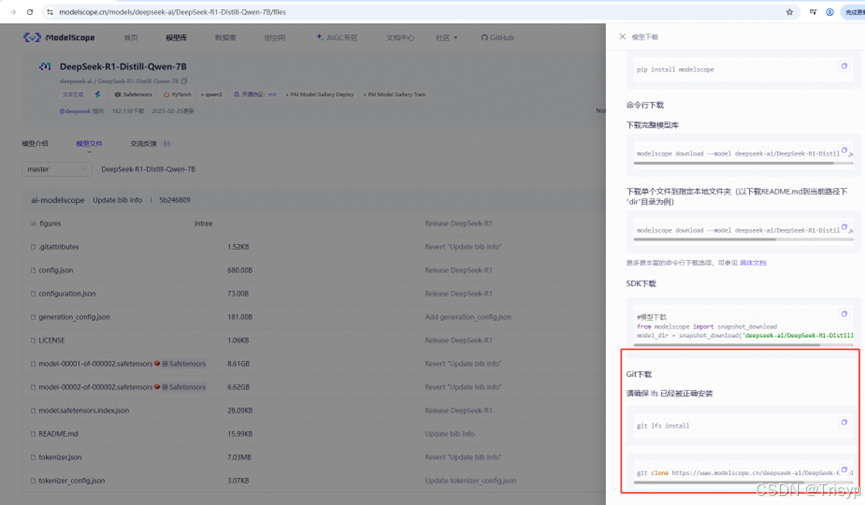
大概有十几个G,预计一个小时左右,耐心等待即可。下载完成后如下:
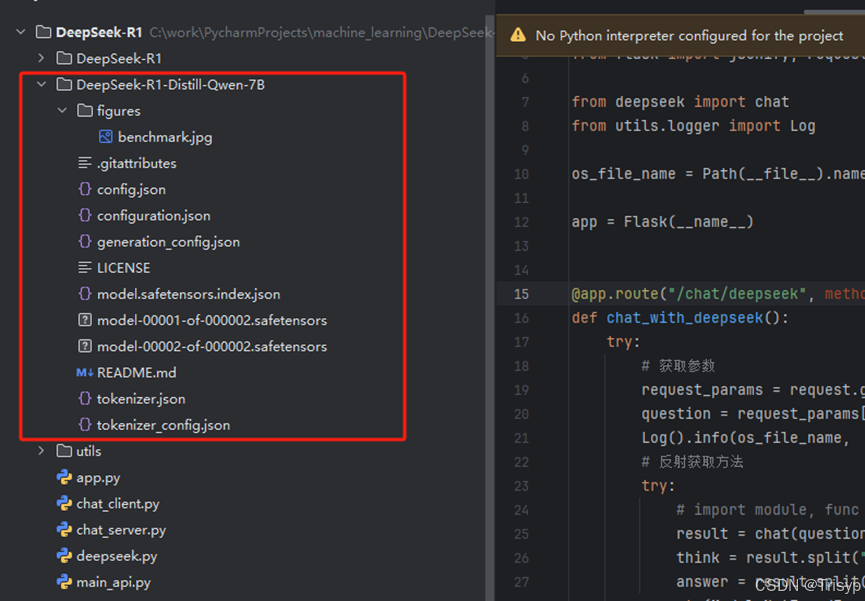
下载完成后编写代码进行调用
二、模型调用
调用流程很简单,先是指定模型路径(下载存放的位置),用transformers加载模型,然后提供提示词来调用模型,然后模型运行生成答案。代码结构如图:
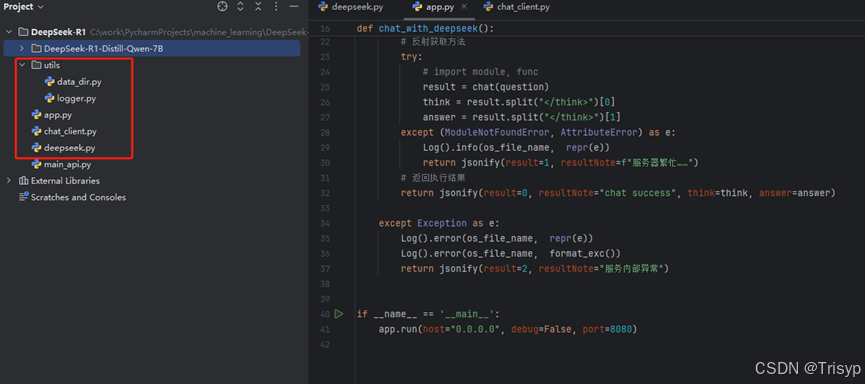
其中,
Deepseek.py是用来调用模型
app.py是为了启动服务,供聊天窗口随时调用;
chat_client.py是开发聊天窗口来随时和deepseek进行对话
1、模型加载
直接撸代码:
import torch
import time
from transformers import AutoModelForCausalLM, AutoTokenizer
from utils.data_dir import root_dir
model_name = f"{root_dir}/DeepSeek-R1-Distill-Qwen-7B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
2、模型调用
直接撸代码:
def generate_response(prompt, max_new_tokens=1024): # Format the prompt as a chat message
messages = [{"role": "user", "content": prompt}]
# Apply the chat template and tokenize the input
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# Prepare the input for the model
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 确保tokenizer中有正确的pad_token和eos_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
# 设置正确的pad_token_id和eos_token_id
model.config.pad_token_id = tokenizer.pad_token_id
model.config.eos_token_id = tokenizer.eos_token_id
generated_ids = model.generate(
**model_inputs,
max_new_tokens=max_new_tokens, # Control the length of the generated text
pad_token_id=tokenizer.pad_token_id, # 防止报填充和结束混淆错误
eos_token_id=tokenizer.eos_token_id
)
# Decode the generated IDs to text
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response
def chat(prompt):
start_time = time.time()
response = generate_response(prompt)
end_time = time.time()
print(f"Time taken for prompt:'{prompt}...{end_time - start_time: .2f}' seconds")
print(f"answer:'{response}")
return response3、服务启动
直接撸代码:
#!/user/bin/env python3
# -*- coding: utf-8 -*-
from pathlib import Path
from traceback import format_exc
from flask import jsonify, request, Flask
from deepseek import chat
from utils.logger import Log
os_file_name = Path(__file__).name
app = Flask(__name__)
@app.route("/chat/deepseek", methods=["POST"])
def chat_with_deepseek():
try:
# 获取参数
request_params = request.get_json(force=True)
question = request_params["question"]
Log().info(os_file_name, f"问题: {question}")
# 反射获取方法
try:
# import module, func
result = chat(question)
think = result.split("</think>")[0]
answer = result.split("</think>")[1]
except (ModuleNotFoundError, AttributeError) as e:
Log().info(os_file_name, repr(e))
return jsonify(result=1, resultNote=f"服务器繁忙……")
# 返回执行结果
return jsonify(result=0, resultNote="chat success", think=think, answer=answer)
except Exception as e:
Log().error(os_file_name, repr(e))
Log().error(os_file_name, format_exc())
return jsonify(result=2, resultNote="服务内部异常")
if __name__ == '__main__':
app.run(host="0.0.0.0", debug=False, port=8080)
4、聊天窗口
直接撸代码:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Author: 人海中的海盗
# 在线聊天客户端
import tkinter
import tkinter.font as tkFont
import time
import requests
global clientSock
class ClientUI:
# 初始化类的相关属性的构造函数
def __init__(self):
self.root = tkinter.Tk()
self.root.title('Python客户端-deepseek咨询')
# 窗口 4个frame面板布局
self.frame = [tkinter.Frame(), tkinter.Frame(), tkinter.Frame(), tkinter.Frame()]
# 滚动条
self.chatTextScrollBar = tkinter.Scrollbar(self.frame[0])
self.chatTextScrollBar.pack(side=tkinter.RIGHT, fill=tkinter.Y)
# 显示Text,绑定滚动条
ft = tkFont.Font(family='Fixdsys', size=11)
self.chatText = tkinter.Listbox(self.frame[0], width=70, height=18, font=ft)
self.chatText['yscrollcommand'] = self.chatTextScrollBar.set
self.chatText.pack(expand=1, fill=tkinter.BOTH)
self.chatTextScrollBar['command'] = self.chatText.yview()
self.frame[0].pack(expand=1, fill=tkinter.BOTH)
# 分开消息显示和消息输入
label = tkinter.Label(self.frame[1], height=2)
label.pack(fill=tkinter.BOTH)
self.frame[1].pack(expand=1, fill=tkinter.BOTH)
# 输入消息的滚动条
self.inputTextScrollBar = tkinter.Scrollbar(self.frame[2])
self.inputTextScrollBar.pack(side=tkinter.RIGHT, fill=tkinter.Y)
ft = tkFont.Font(family='Fixdsys', size=11)
self.inputText = tkinter.Text(self.frame[2], width=70, height=8, font=ft)
self.inputText['yscrollcommand'] = self.inputTextScrollBar.set
self.inputText.pack(expand=1, fill=tkinter.BOTH)
self.inputTextScrollBar['command'] = self.chatText.yview()
self.frame[2].pack(expand=1, fill=tkinter.BOTH)
# 发送按钮
self.sendButton = tkinter.Button(self.frame[3], text='发送', width=10, command=self.receive_message)
self.sendButton.pack(expand=1, side=tkinter.BOTTOM and tkinter.RIGHT, padx=25, pady=5)
# 关闭按钮
self.closeButton = tkinter.Button(self.frame[3], text='关闭', width=10, command=self.close)
self.closeButton.pack(expand=1, side=tkinter.RIGHT, padx=25, pady=5)
self.frame[3].pack(expand=1, fill=tkinter.BOTH)
self.buffer = 1024
def close(self):
self.root.destroy()
# 接收消息
def receive_message(self):
message = self.inputText.get('1.0', tkinter.END)
if message.strip() == "":
self.chatText.insert(tkinter.END, '请输入问题后再发送……\n')
return -1
theTime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
self.chatText.insert(tkinter.END, '客观' + theTime + '问:\n' + message + '\n')
json_q = {"question": message.strip()}
try:
response = requests.post(url="http://171.1.9.1:8080/chat/deepseek", json=json_q, timeout=300)
result = response.json()
if result["result"] == 0:
self.flag = True
self.server_msg = f'{result["answer"]} \n 所以经过我的思考,{result["answer"]}'
the_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
self.chatText.insert(tkinter.END, f'deep seek {the_time} 回答:{self.server_msg}\n')
self.chatText.see(tkinter.END)
else:
self.flag = False
self.chatText.insert(tkinter.END, '服务器繁忙\n')
except Exception as e:
self.chatText.insert(tkinter.END, f'服务器发生异常:{str(e)}\n')
if __name__ == '__main__':
client = ClientUI()
client.root.mainloop()
PS:
有个错误(pad_toekn_id to eos_token_id)要记录一下,如果踩坑的可以借鉴:
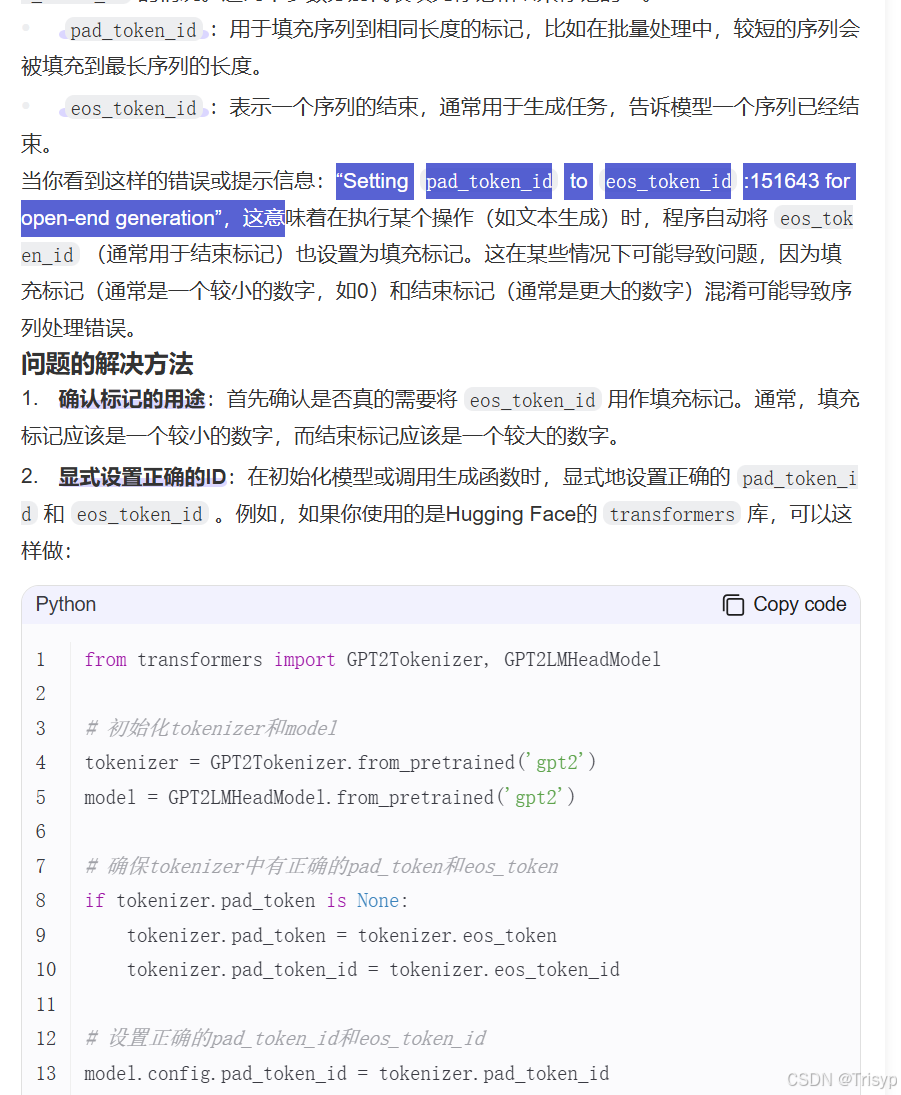
解决办法我已经放到代码里面了,就是在model.generate函数中指定pad_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id。
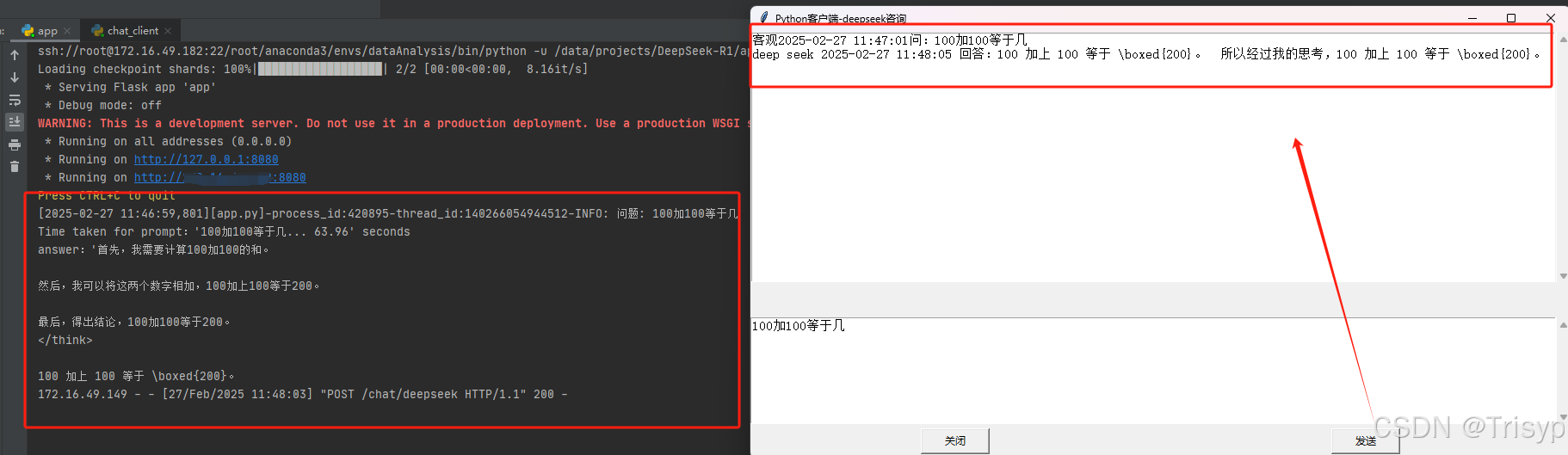
最后我们看下运行效果(我只有一张4090显卡,7B的模型带不起来,调用一次起码一分钟):



















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











