






本文内容来自 张涛的《从零开始学Scrapy网络爬虫》
1.创建项目
- 首先创建一个项目,项目名为QQMusic
scrapy startproject QQMusic
2.使用Item封装数据
- 打开项目QQMusic中的items.py源文件。添加榜单歌曲字段,实现代码如下:
import scrapy
class QqmusicItem(scrapy.Item):
song_name = scrapy.Field() # 歌曲
album_name = scrapy.Field() # 唱片
singer_name = scrapy.Field() # 歌手
interval = scrapy.Field() #时长
3.创建Spider文件及Spider类
- 在Spider文件中新建music.py文件。在music.py中定义MusicSpider类,实现爬虫功能,代码如下:
# -*- coding:utf-8-*-
from scrapy import Request
import sys
sys.path.append('D:\\pythonProject\\scrapy\\QQMusic')
from scrapy.spiders import Spider # 导入Spider类
from QQMusic.items import QqmusicItem # 导入Item类
import json # 导入JSON库
class MusicSpider(Spider):
name = 'music'
#定义headers属性,设置用户代理(浏览器类型)
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}
def start_requests(self): # 获取初始请求
url = "https://c.y.qq.com/v8/fcg-bin/fcg_v8_toplist_cp.fcg?&topid=4"
# 生成请求对象
yield Request(url,headers=self.headers)
def parse(self, response): # 数据解析
item = QqmusicItem()
# 生成QqmusicItem对象
# 获取json格式的数据
json_text = response.text
#使用json.loads解码json数据,返回Python数据类型
# 这里的music_dict是一个字典类型
music_dict = json.loads(json_text)
# for循环遍历每首歌曲
for one_music in music_dict["songlist"]:
# 获取歌曲
item["song_name"] = one_music["data"]["songname"]
# 获取唱片
item["album_name"] = one_music["data"]["albumname"]
# 获取歌手
item["singer_name"] = one_music["data"]["singer"][0]["name"]
# 获取时长
item["interval"] = one_music["data"]["interval"]
yield item
- 首先要导入JSON库,用于解析JSON格式数据。
- 在start_request()方法中,url为访问服务器中fcg_v8_toplist_cp.fcg文件的地址。原文中查找改url是通过如下方法:

- 而我自己打开时没有找到fcg_v8_toplist_cp.fcg文件,不知道是哪里出了问题
- 在parse()方法中,首先生成QqmusicItem对象,用于保存结构化数据;然后使用JSON库中的load()方法解码获取到的JSON格式数据,返回Python的数据类型(这里是字典型);最后使用for循环遍历每首歌曲,将其保存在Item中。
4.运行爬虫
- 至此,本项目所有的功能全部实现,运行爬虫程序。
scrapy crawl music -o music.csv
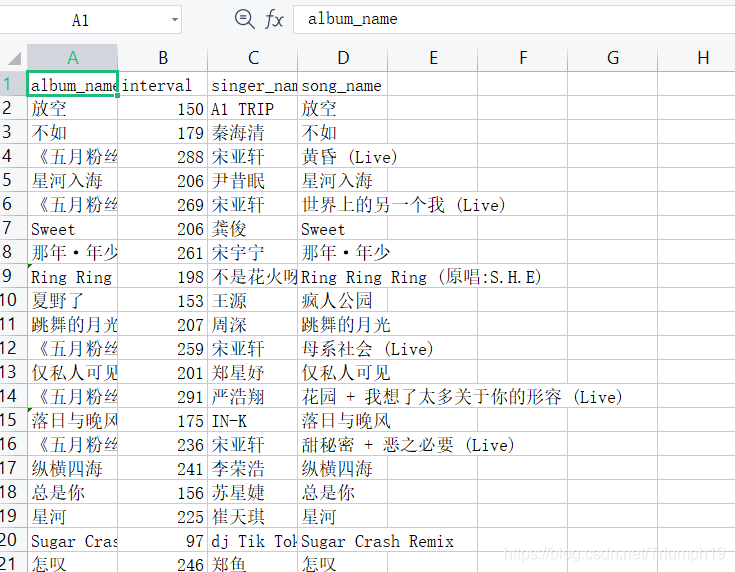
5.查看结果















 1737
1737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









