






作者:范志东
试想在你刚接触一个陌生的技术领域时,如果有办法以“上帝视角”看到该领域完整的历史发展轨迹,是否可以让自己的技术探索更有的放矢,胸有成竹呢?是的,你没猜错,这个玩意儿叫论文图谱。
我通过“人肉扫描”了200多篇图计算系统的论文,整理了心中理想的“图系统论文图谱”原型,大家可以“类比想象”一下当下关注技术领域的论文图谱应当如何。当然我们很清楚人肉不是终极解,所以我们需要探索如何通过技术手段实现论文图谱的自动化构建。
NOTE:秉承开源宗旨,文中整理的图系统论文图谱(包含图谱数据、论文pdf文件、可视化交互)已全部托管到GitHub仓库Awesome-Graphs,可以直接下载、体验,欢迎Star、捉虫、维护、共建。
1. 动机
“熟悉新编程语言最好的办法是模仿编码,熟悉新技术领域最好的办法是通读文献。” —— 不知名开发者
在我最初着手图计算系统的研发工作时,阅读经典的图计算系统论文是必不可少的过程。当时心中一直存在着一个愿望:“要是有整理好的图系统论文的演进轨迹图,我只需沿着主干有重点地阅读就好了。。。”。
显然,理想很丰满,现实很骨感。当时也就从Google学术上逐个捞论文自己慢慢勾勒引用关系,并没有特别好用的工具可以帮助到自己。当然,现在已经有了一些比较不错的检索和分析工具,比如Connected Papers、Semantic Scholar,甚至通过大模型赋能的论文阅读工具,如txyz、沉浸式翻译插件等。
例如Connected Papers确实做了不错的尝试,但是免费版每个月只能渲染5张图谱,而且并不能清晰地表达论文的引用(Reference)和被引用(Citation)关系,且图探索深度(2跳以内)有明显限制。
2. 动作
求人不如求己,既然没有成熟工具达到目的,那不如先手动撸一个出来。具体思路如下:
- 论文检索:通过常规的手段锚定初始论文集合,手段不限于Survey、奠基论文、公开搜索等。
- 引用分析:正向引用分析直接下载论文看Reference,找不到论文下载源/反向引用分析时,就需要借助Google学术、Semantic Scholar、ACM Digital Library、Springer Link、Research Gate等工具了。
- 主题筛选:根据论文标题、摘要、结论等信息确定论文主题,剔除与预期主题无关的论文。
- 构建图谱:保留筛选后符合预期主题的论文,记录引用关系并构图。
基于这个思路不断地迭代扩散,最终会收敛到一张完整的领域图谱。当然,这个过程其实并不轻松。。。我使用图计算系统的论文图谱的构建流程举例说明。
2.1 确定范围
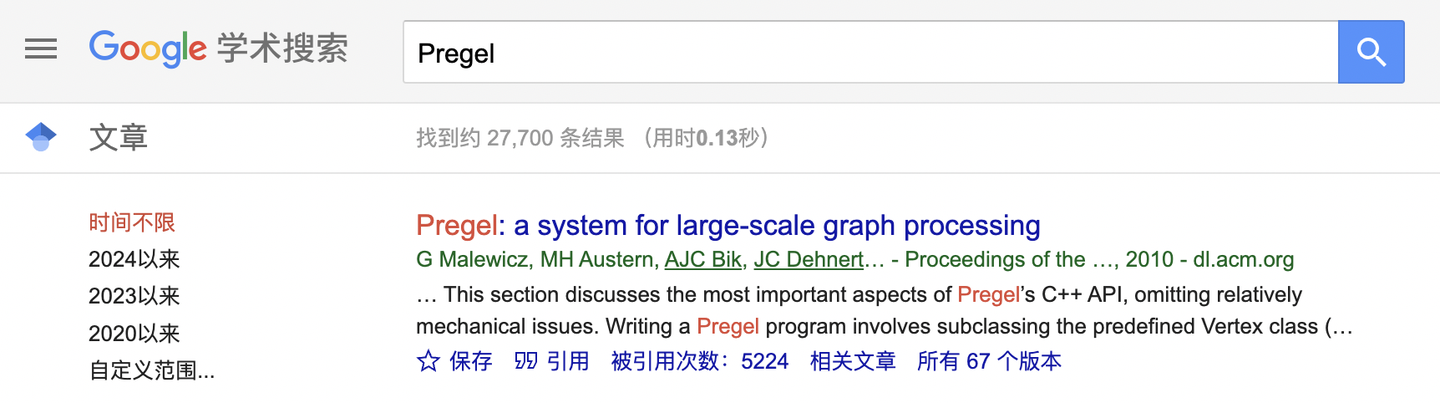
图计算系统的论文最早可以追溯到2010年Google的“后Hadoop时代三驾马车”之一的Pregel这篇论文,当然图数据库出现的更早,最早可以追溯到Neo4j的起源。简单起见,这里我们将Pregel定为图计算系统的奠基论文,论文的引用次数达数千次(可能有数据误差)。
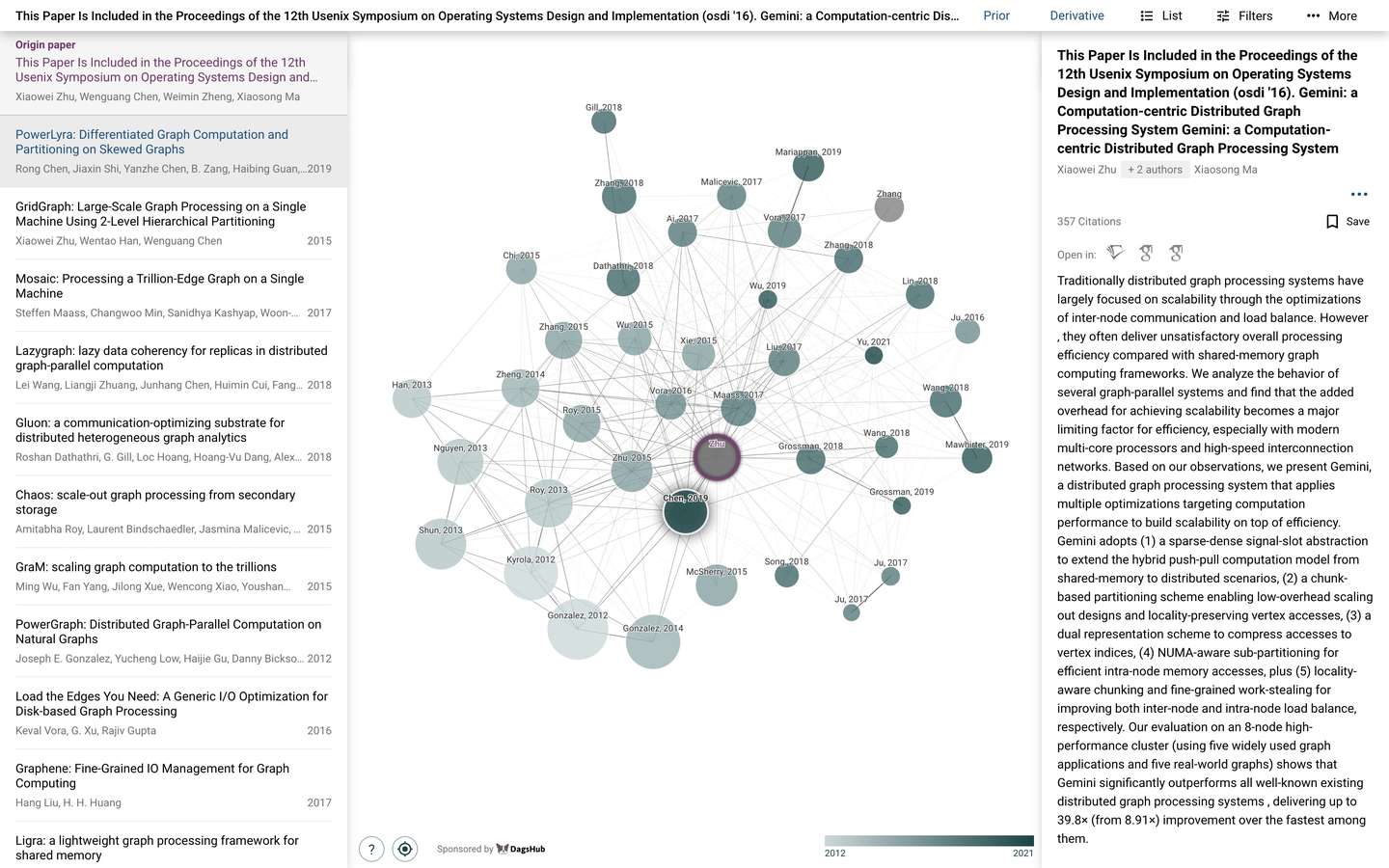
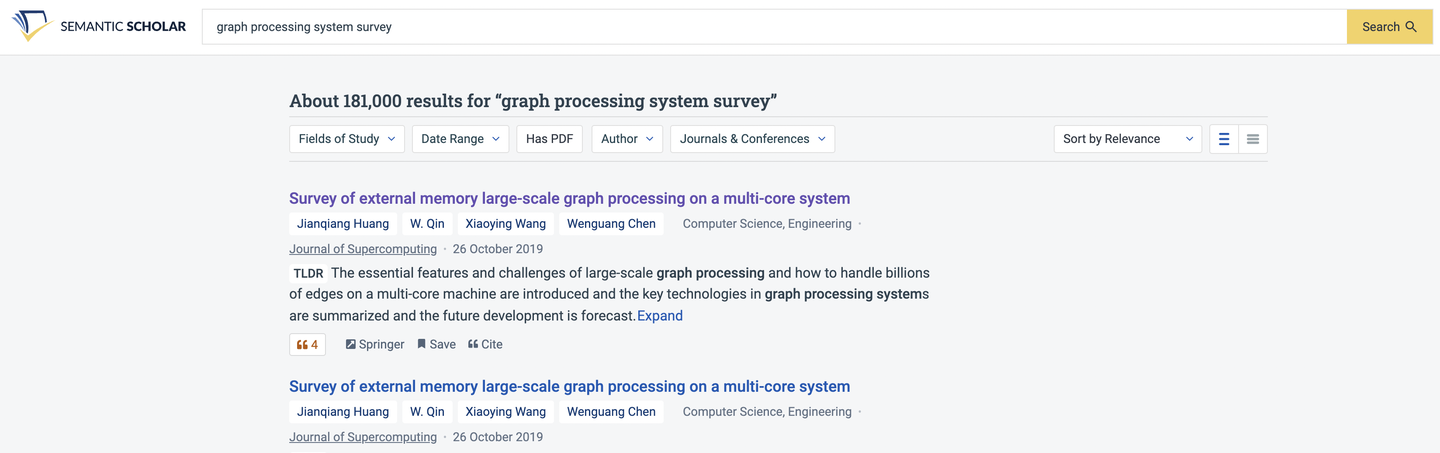
除了根据奠基论文开始之外,通过检索领域的Survey论文也能达到相似的目的。这里可能需要尝试不同的关键词并结合多种检索工具来提升检索质量,比如示例中的搜索在Semantic Scholar上结果相关性更强。
当然,“道听途说”也是非常高效的方式。随便抓一个懂图计算技术的人问一下,不可能不知道Pregel、GraphLab、PowerGraph、GraphX、X-Stream等。
2.2 分析关系
不管用什么样的方式,最终总能找到图计算领域内最关键的那一批论文,接下来就是最“枯燥”的引用分析和主题筛选过程了。比如前边提到的Pregel这篇论文,直接引用数千次,这还没考虑间接引用关系。

逐个处理引用Pregel的论文,筛选出图系统的主题论文,例如PowerGraph。分析PowerGraph的38个引用,筛选出除了Pregel的另3个图系统类论文:Kineograph、GraphChi、Distributed GraphLab。

但事情到此还未结束,因为Kineograph论文本身也引用了Pregel,所以PowerGraph直接引用Pregel的信息应当被精简掉,以此简化图谱的引用信息。所以,整个图谱的生成过程类似这样:
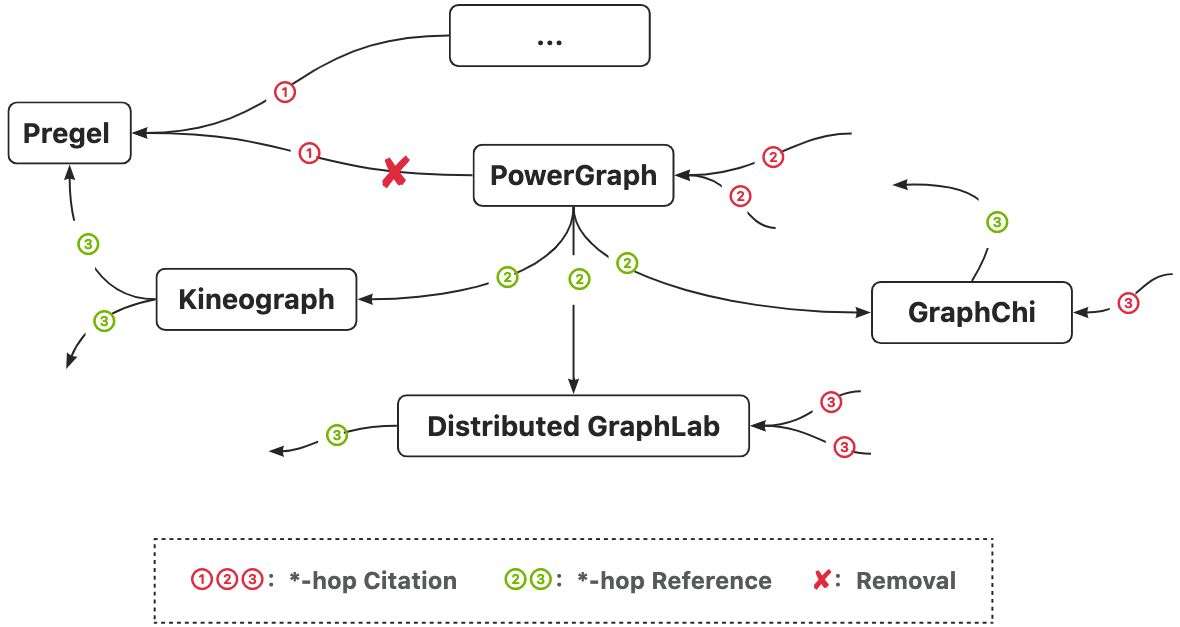
不断地重复上述过程,直到找不到新的图系统论文和引用关系为止。需要特别说明一下,后期我还补充了图数据库的节点以及论文双向引用关系,让图谱的信息更丰富一些。
3. 演示
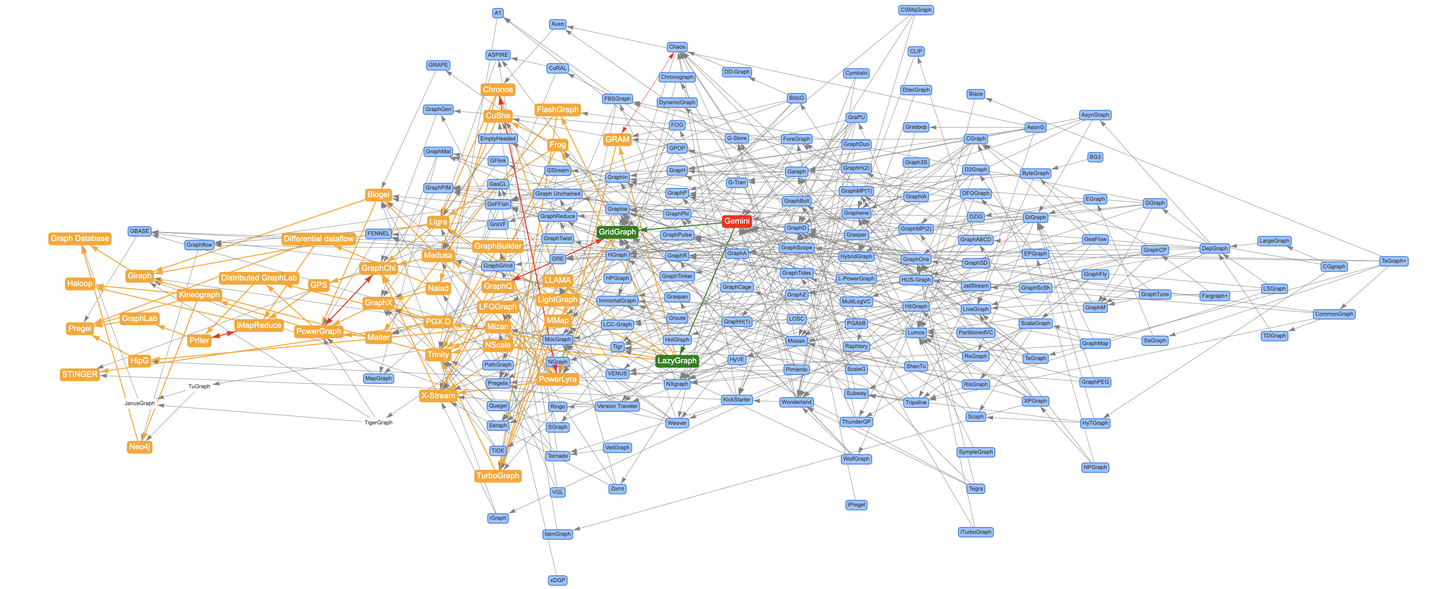
先说结论,基于上述过程,差不多扫了200多篇图系统的论文,构建了约500条引用关系才让图谱“基本”收敛(人工很难保证没有遗漏)。来看看最终效果,就说这个图谱牛不牛吧?(嗯,确实像一头牛。。。)
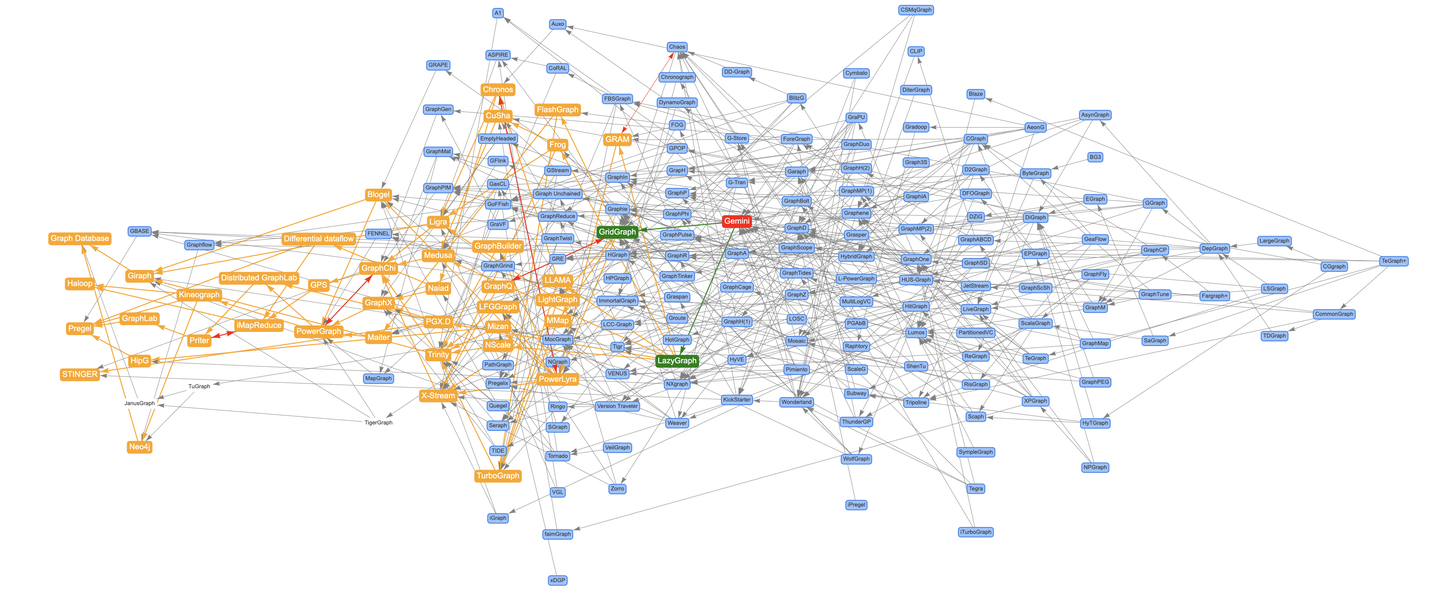
费尽力气整理了这张图谱,现在遇到了新问题:**引用关系太多了,根本没法看!**我知道你很急,但你先别急。为了解决这个问题,我给图谱添加了一键追溯的能力。
一键追踪PowerGraph上游引用链路,直达Pregel,简直不要太直观!(此处应当Cue一下ConnectedPapers)
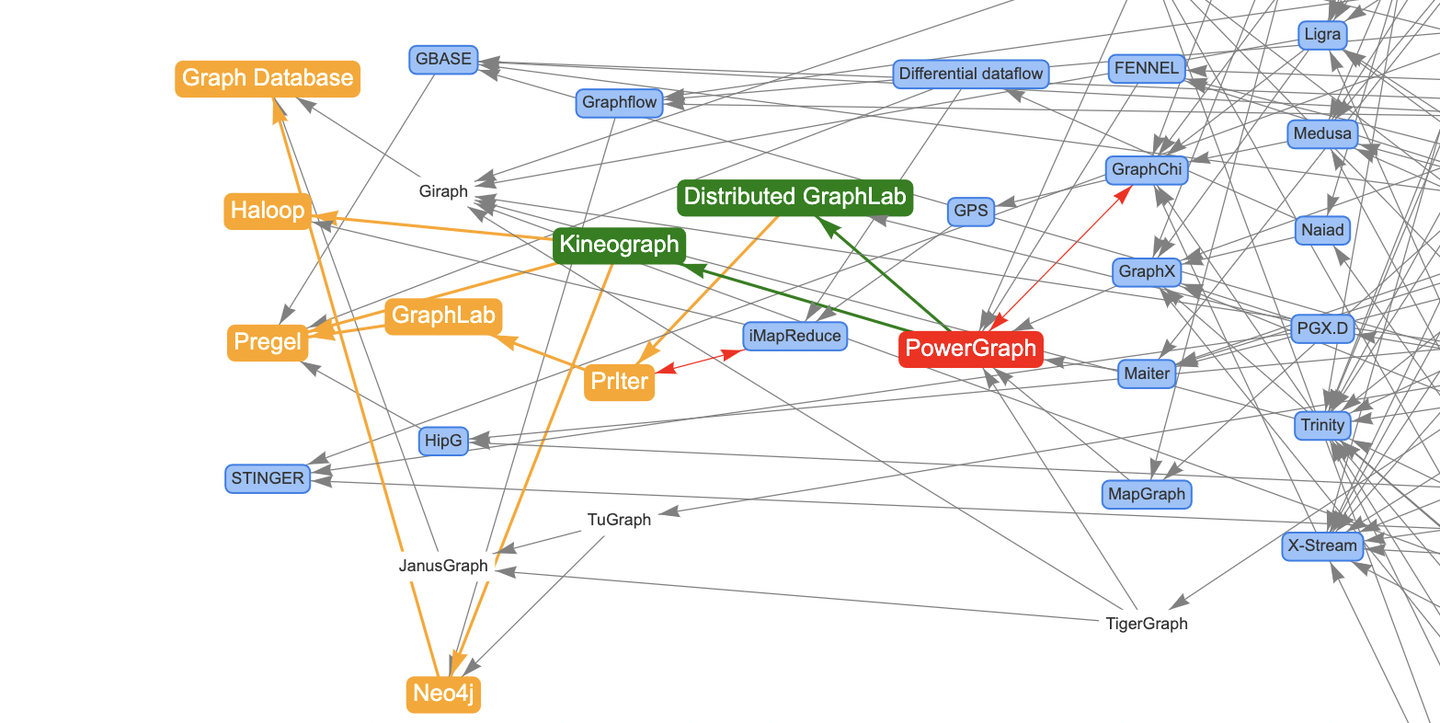
当然搜索定位功能自然是不能少的,注意红色双向边代表论文的相互引用关系。最初我对此也很费解,查了一下GraphChi和PowerGraph的论文当初是在OSDI-2012同时发表的(奇怪的知识又增加了)。
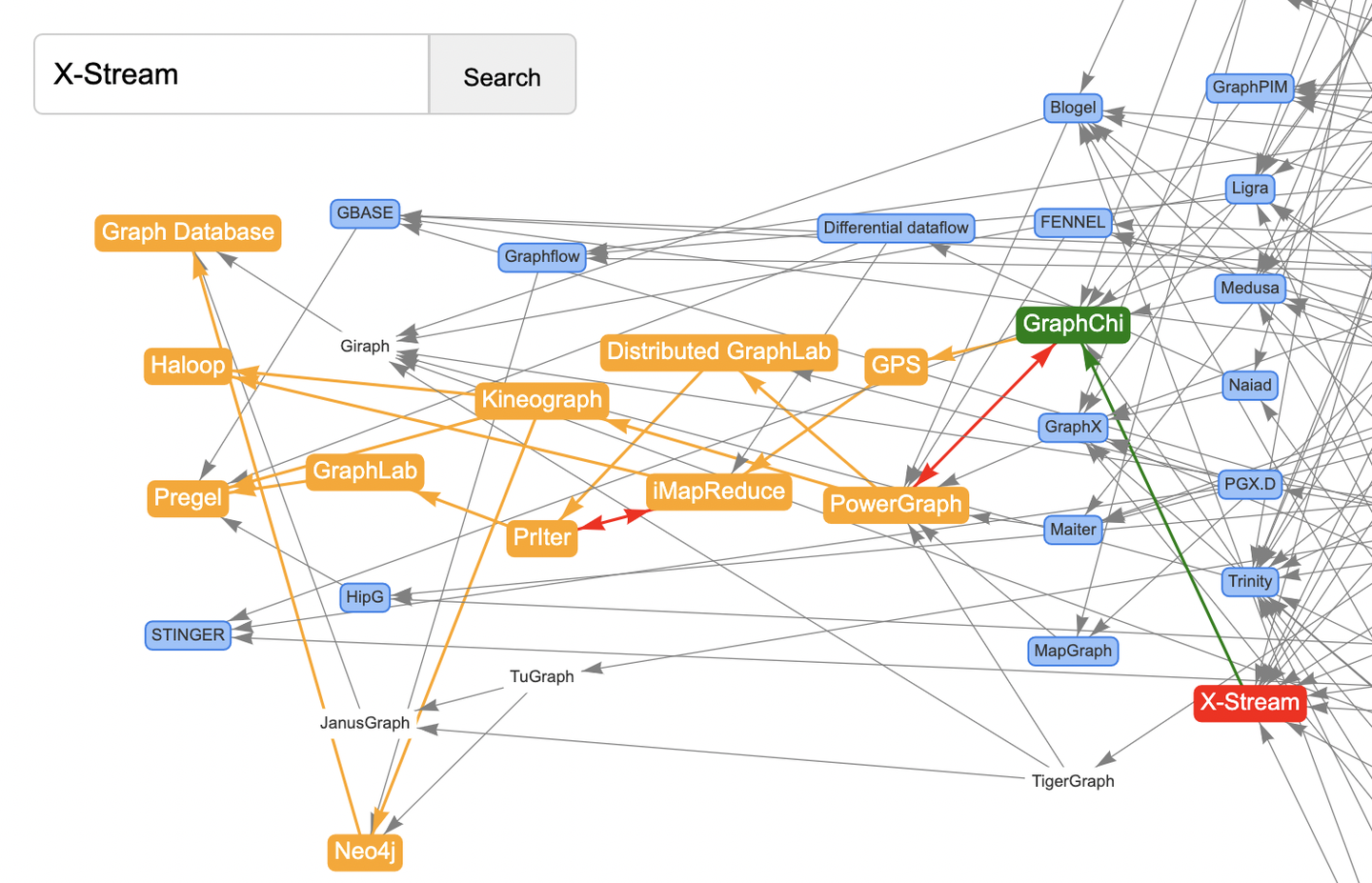
作为蚂蚁图计算团队,科研成果自然是重头戏。图计算系统论文Gemini、GridGraph、LiveGraph、ShenTu、GeaFlow、RisGraph、Chronos、ImmortalGraph、Auxo、Pimiento、DFOGraph、TeGraph、TeGraph+等赫然在列,皆可一键追踪引用关系。真正的做到了“Think Graphs Like A Graph”。
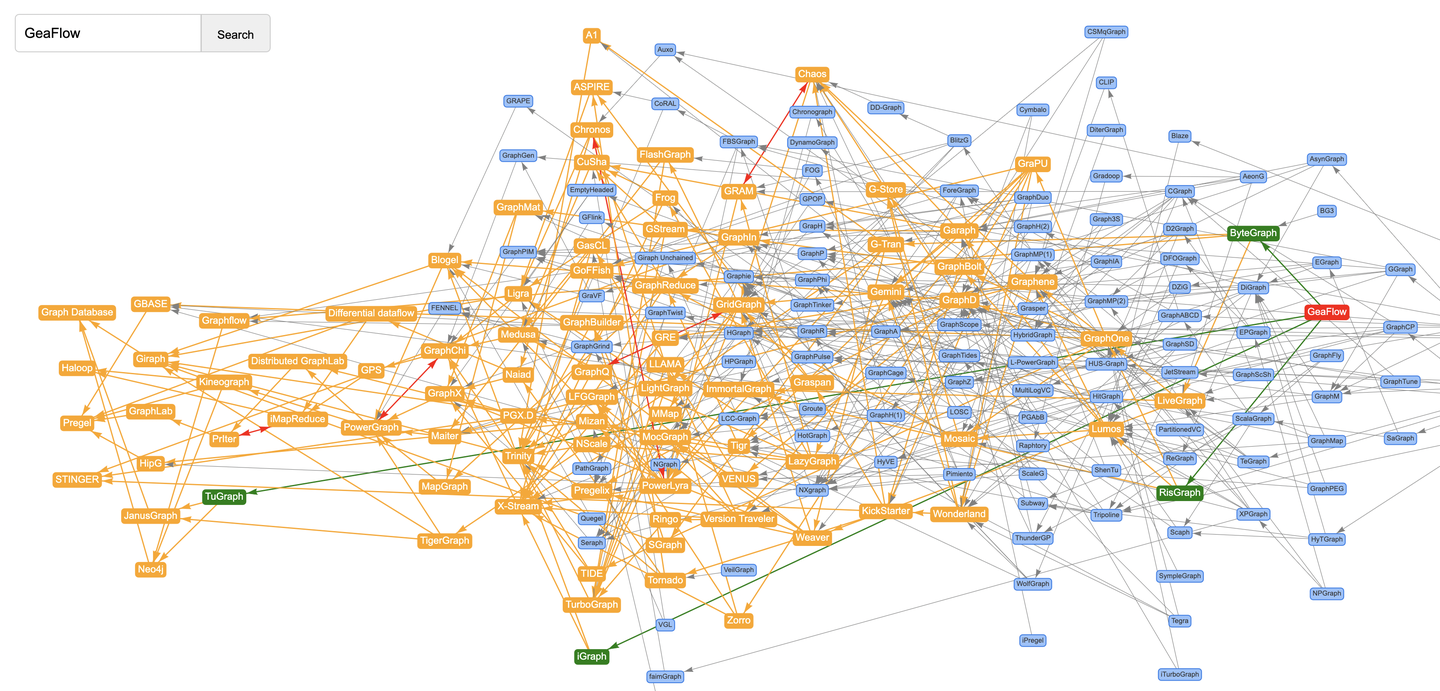
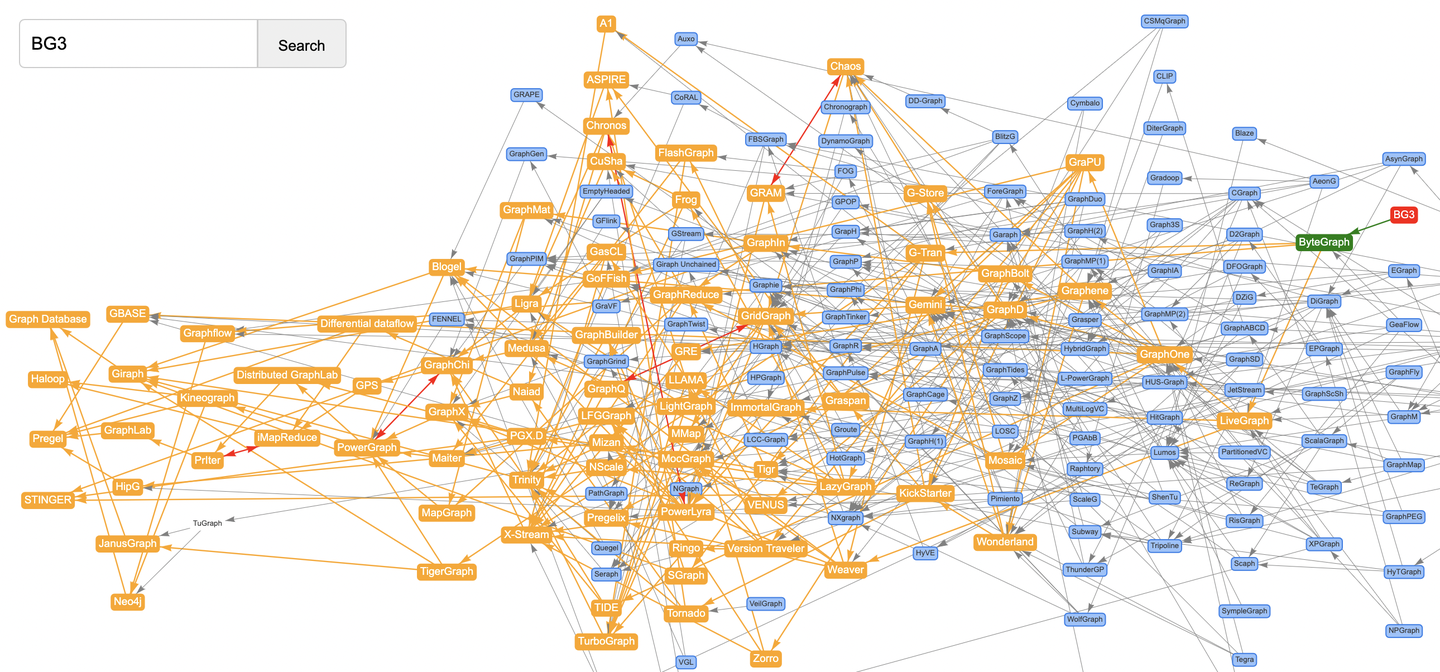
当然字节刚中的SIGMOD-2024论文BG3也不例外。
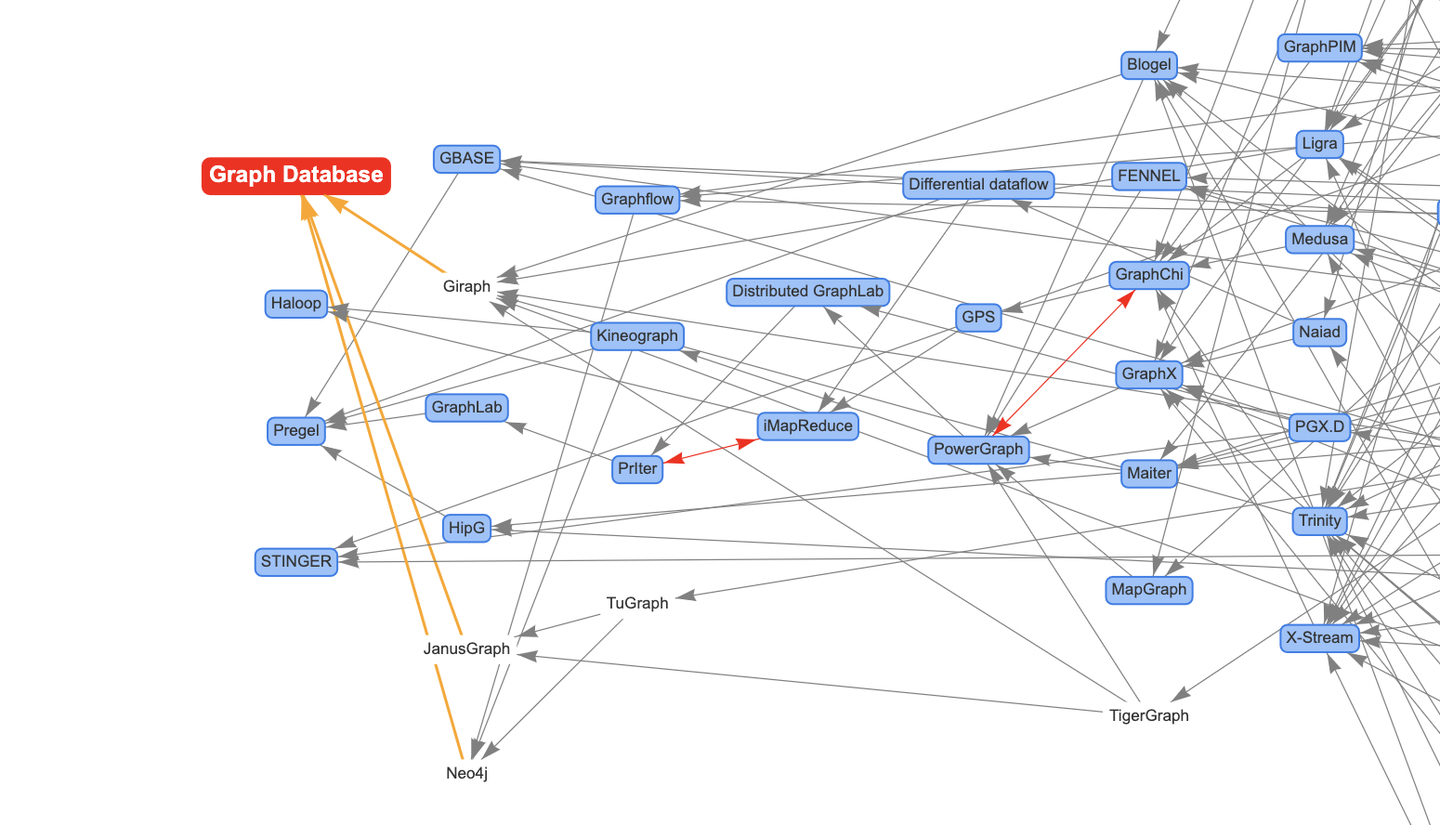
另外,还要提及一下图谱中的图数据库产品节点,包括Neo4j、TigerGraph,以及蚂蚁图数据库产品TuGraph等部分业内图计算产品。这是为了方便表达论文里引用图数据库产品的信息,我把它们全部挂载到Graph Database这个虚拟的根节点的后继链路上。
以上所有功能皆在Awesome-Graphs项目中,大家下载index.html文件直接打开体验即可。由于项目也是刚刚发布,数据上肯定会有一些错误和遗漏,功能上肯定还不够完美,欢迎大家勘误、补充、提Issue/PR协同更改。贡献流程非常简单,几乎不需要写代码:
- 项目只依赖前端组件vis.js,要对图谱数据进行调整,只需要修改
index.html文件中nodes和edges的定义。 - 新增图计算系统论文节点,如
{id: 'Pregel', label: 'Pregel'},。产品节点只需要标记_type属性为db即可,如{id: 'TuGraph', label: 'TuGraph', color: 'white', _type: 'db'},。 - 新增图计算系统论文/产品引用,如
{from: 'GeaFlow', to: 'TuGraph'},。双向引用需要标记为红色双向箭头格式。如{from:'GraphChi',to:'PowerGraph',color:'red',arrows:{to:{enabled:true,scaleFactor:1},from:{enabled:true,scaleFactor:1}}},表示GraphChi和PowerGraph存在互相引用(同时发表于OSDI-2012)。 - 新增论文统一放到
papers/<图系统名>.pdf路径,并按字母序修改docs/graph-system-list.md的引用链接。
另外,论文图谱中的所有论文文件可以下载的都已经上传到papers目录,对图计算系统感兴趣的同学可以直接下载阅读:完整论文列表(170/205)。
4. 畅想
最后,还是和大家聊一下上述工作如何实现工具自动化的思路。我总结了以下几个挑战点:
- 论文数据:目前没有统一的地方可以免费获取公开、实时、完整的论文数据,即便arXiv上已经维护了不少最新的论文数据(尤其是AI领域的论文),且提供开放API访问能力,但依然存在大量的论文数据库分散不开放的问题。当然,我们可以尝试先从arXiv开始逐步做起,这部分有不少数据工程上的困难。
- 引用分析:解析论文引用关系本身就需要大量的计算资源,包括pdf文件解析、引用关系文本理解等,这里使用传统文本技术基本上可以做到。使用大模型对结果质量会有提升,但成本和开销会更高。
- 主题理解:前边论述过,单纯机械地分析文章的引用关系并不能带来直观有效的分析结果,而且会产生图数据爆炸的问题,因此需要根据用户意图针对性的筛选出符合预期的论文和引用数据。这里就得用到大模型技术实现论文主题理解了,基于论文的标题、摘要和结论的文本理解与分析,以识别论文主题是否符合用户查询意图。
- 存储成本:大量的论文主题与引用关系数据,天然适合使用图数据库进行存储和分析。百亿内边规模可以考虑TuGraph数据库,规模更大的话就需要考虑分布式图数据库或者TuGraph计算引擎了。
- 产品服务:无论是用离线方式,还是实时方式构建论文图谱,最终还是需要提供高效的图服务和产品能力让用户开箱即用。
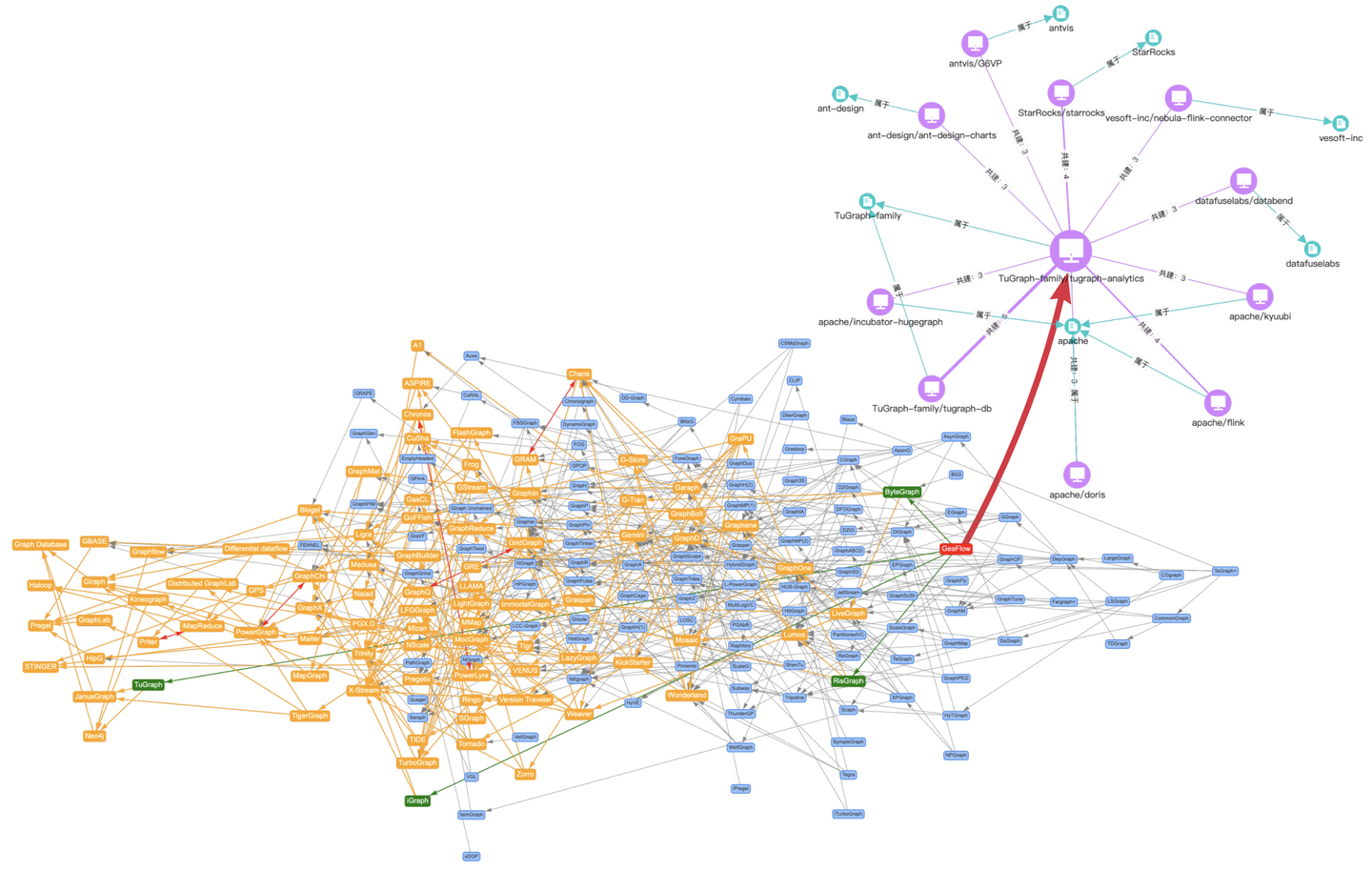
说到论文图谱产品化,大家应该还记得前不久我们刚发布的开源图谱关系洞察产品OSGraph。它将GitHub Archive数据格式化为图数据,通过TuGraph提供图谱分析能力,最终使用AntV前端技术完成可视化分析。

试想这里我们给TuGraph多加一个arXiv的数据源,结合上述的NLP技术,是不是就可以实现对OSGraph底层数据的直接扩充,进而实现“开源图谱+论文图谱”的无缝融合?相信这又是一个振奋人心的故事,期待您的参与和共建!
5. 资料
- Awesome-Graphs: https://github.com/TuGraph-family/Awesome-Graphs
- 完整论文列表: https://github.com/TuGraph-family/Awesome-Graphs/blob/master/docs/graph-system-list.md
- TuGraph数据库: https://github.com/TuGraph-family/tugraph-db
- TuGraph计算引擎: https://github.com/TuGraph-family/tugraph-analytics
- OSGraph: https://osgraph.com/
- arXiv: https://arxiv.org/
- Google学术: https://scholar.google.com/
- Connected Papers: https://www.connectedpapers.com/
- Semantic Scholar: https://www.semanticscholar.org/
- ACM Digital Library: https://dl.acm.org/
- Springer Link: https://link.springer.com/
- Research Gate: https://www.researchgate.net/search/publication
- txyz: https://txyz.ai/
- 沉浸式翻译插件: https://immersivetranslate.com/
- Neo4j的起源: https://www.forbes.com/sites/alastairdryburgh/2017/03/22/growth-stories-the-magical-power-of-a-name/#49b4ebe56db9
- Pregel: https://15799.courses.cs.cmu.edu/fall2013/static/papers/p135-malewicz.pdf
- PowerGraph: https://www.usenix.org/system/files/conference/osdi12/osdi12-final-167.pdf
- Kineograph: http://www.istc-cc.cmu.edu/publications/papers/2012/euro065-cheng.pdf
- GraphChi: https://www.usenix.org/system/files/conference/osdi12/osdi12-final-126.pdf
- Distributed GraphLab: https://arxiv.org/pdf/1204.6078















 4569
4569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









