







作者:李文凯
TuGraph计算引擎模型推理系统将基于迭代计算的图计算框架与模型推理系统相结合,推理系统可自定义推理依赖环境,图迭代计算与推理链路实现隔离。基于共享内存的跨进程通信方式,提高了推理数据交换效率,满足流图近线推理的时效性。在蚂蚁集团内部的实际应用场景中,大幅缩短了模型推理上线的链路与开发时间,用户迭代模型版本更方便快捷。
1. 图算法概述
在计算机科学中,图是一种表示实体(节点或顶点)以及实体之间关系(边)的数据结构。图模型可以天然地描述网络结构,能更清晰地表达复杂的数据关系和依赖,简化关联数据的理解和分析。在不同的场景下,图中点边具备不同的语义信息。比如在资金交易场景下,每个人可以抽象成一个点表示,人与人之间的转账关系可以抽象成一条边表示。如下图,通过图数据模型反映出各个实体之间的资金往来关系,让数据的关联分析更加直观和高效。
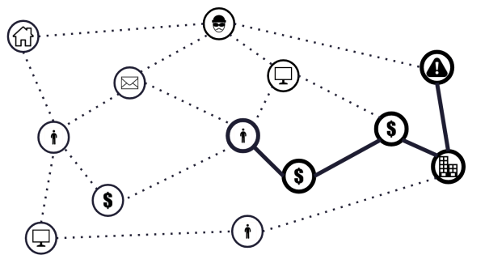
在图数据模型上可以执行多种图算法,如社区检测,最短路径匹配,环路检测算法等。通过点边上的迭代计算,探索图模型中各个实体之间的关系。探索过程不依赖于数据的线性结构,从而便于识别隐藏的模式和关联关系。在主流迭代图算法中,节点通过消息传递的方式进行通信。每次迭代,节点可以接收来自它们邻居的消息,处理这些消息,然后决定是否发送新的消息给其他节点。迭代算法中,每个节点有一个状态,每次迭代它们都有可能更新这个状态直至收敛。例如,在PageRank算法中,每个节点的状态是其PageRank值,这个值在迭代过程中会随着邻居的值的更新而更新。
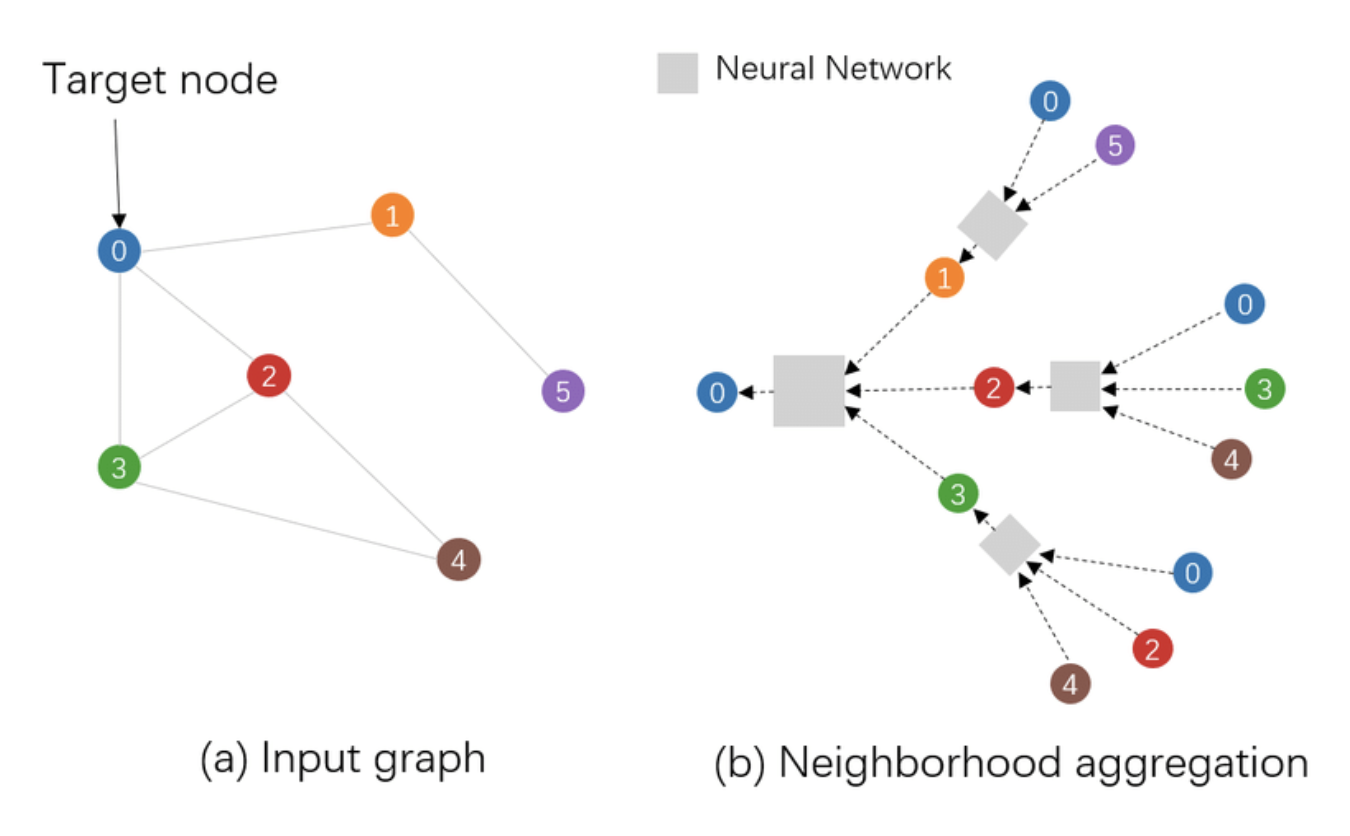
图迭代算法解决了经典的图计算问题,但随着业务需求的复杂度提升,基于迭代的图算法存在着表达能力不足、自适应性能力差、异质图处理难度大等缺点。近年来随着深度学习的研究和应用的发展,以图神经网络(Graph Neural Networks,GNNs)为代表的一类神经网络算法,被设计用来捕获图中实体(节点)和关系(边)间的复杂模式。图神经网络能够结合节点特征和图的结构来学习节点和边的表示,相比之下,传统的迭代图算法通常不会直接从原始特征中学习,而更多地专注于结构特征。依赖于深度学习的天然优势,GNNs具有更强的表示学习能力,可以自动从数据中学习复杂的模式,这使得 GNNs 能够更好地处理多任务学习和迁移学习等问题。在社交网络分析、知识图谱、生物分子网络、推荐系统以及交通网络等领域,得到广泛应用。
2. 流图推理简介
TuGraph计算引擎(TuGraph Analytics)是蚂蚁集团开源的大规模分布式实时图计算引擎(流图引擎),实现了流批一体的图计算模型,支持了丰富的图计算算法。TuGraph Analytics的流图计算能力,能处理连续输入的数据流,并支持增量的计算模式,极大得提高了数据的计算效率和实时性。TuGraph Analytics解决了业界大规模数据关联分析的实时计算问题,已广泛应用于数仓加速、金融风控、知识图谱以及社交推荐等场景。
随着业务场景中问题复杂度的提升,基于传统的迭代图算法已无法满足业务的实际需求。例如在反洗钱场景中,利用图神经网络算法处理复杂的交易关系,能够捕获到节点的局部图结构信息。通过聚合邻接节点的特征信息,每个交易节点都可以感知到周边图网络结构的信息。类似的图神经网络等AI模型的推理逻辑,是无法基于传统的图迭代计算模式直接高效地表达的。
受上述问题启发,我们思考是否可以将TuGraph Analytics的流图计算能力与图神经网络等深度学习模型相结合,开发一套基于流图计算的模型推理系统。最终期望的推理系统具备如下能力:
- 对于图算法工程师,在图迭代计算过程中,能够方便地使用机器学习模型的推理能力。
- 对于AI算法工程师,可以通过TuGraph Analytics分布式流式计算的能力实现实时的模型推理。
众所周知,在深度学习为代表的数据科学领域,Python已经成为数据分析、模型训练和推理框架的主流开发语言,并提供了丰富的开发库和框架生态。而以Hadoop全家桶为代表的大数据计算引擎领域,基于Java语言开发的系统仍占据一席之地,当然TuGraph Analytics也在其中。这种语言差异带来的“互操作性”成本,使得相当一部分大数据和AI生态组件无法轻松地融合,这也是TuGraph Analytics支持图推理需要亟待解决的问题。

3. 系统设计
我们对业内的跨Python & Java语言的方案进行了充分的调研,通过深入对比现有的跨语言交互方案的性能与效率,最终决定将模型推理任务运行于Python原生环境中以发挥出最佳的性能。
- OONX
OONX是一个开发的生态系统,为不同的机器学习框架之间提供一个标准的模型表示格式。它使得开发人员能够在不同的框架、工具、运行时环境之间以一种标准方式交换模型,从而简化了模型的迁移和部署。
| 优点 | 缺点 |
|---|---|
| 框架互操作性 | 转换成本高 |
| 生态系统支持 | 更新滞后 |
| 优化推理 | 版本兼容性 |
| 规范化模型格式 | 性能不一致 |
- Jython
以Jython为代表的方式,主要思想是在运行的宿主虚拟机上,使用宿主语言重新编写实现。
| 优点 | 缺点 |
|---|---|
| Java集成 | 版本管理复杂 |
| 跨平台 | 支持库有限 |
| 线程 | 更新滞后 |
| - | 支持Python3有限 |
- Py4j
Py4j桥接库为代表的方式,以Socket通信模型为基础,实现Python和Java互相访问对象,方法,提供两个程序相互通信的能力。
| 优点 | 缺点 |
|---|---|
| 跨语言交互 | 网络传输 |
| 动态代理 | 部署分发难度大 |
| 支持复杂类型 | 版本难兼容 |
| API使用简易 | 运行时环境依赖复杂 |
- Web服务化
Web服务化是一种将机器学习模型部署成网络服务,调用者通过相应的api获取模型推理结果。
| 优点 | 缺点 |
|---|---|
| 扩展性好 | 性能差 |
| 简易且轻量 | 不适合计算密集型场景 |
| 社区支持 | 无状态管理 |
| 机器学习类库易集成 | 并发连接有限 |
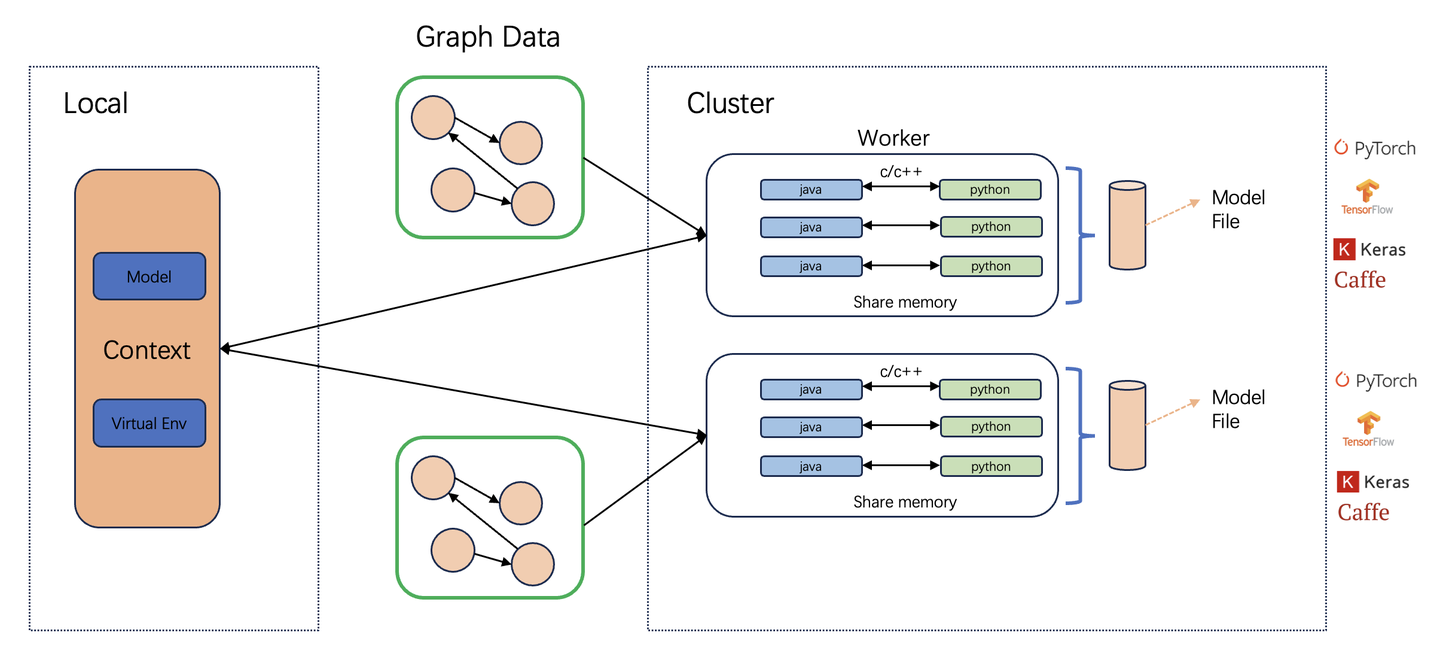
在TuGraph Analytics模型推理系统的架构设计中,核心部分是通过C++原生语言建立起来的一座桥梁,实现Python环境和Java虚拟机之间高效的数据交互和操作指令的传递。通过使用C++作为媒介语言,我们不仅能够利用其接近硬件的执行效率,确保数据交互的性能,还能够保证在两个虚拟环境之间数据交换的计算精度和稳定性。基于共享内存的设计允许Python和JVM进程各自独立运行,既保证了运行环境的安全隔离,又能实现数据的高效共享。
4. 技术原理
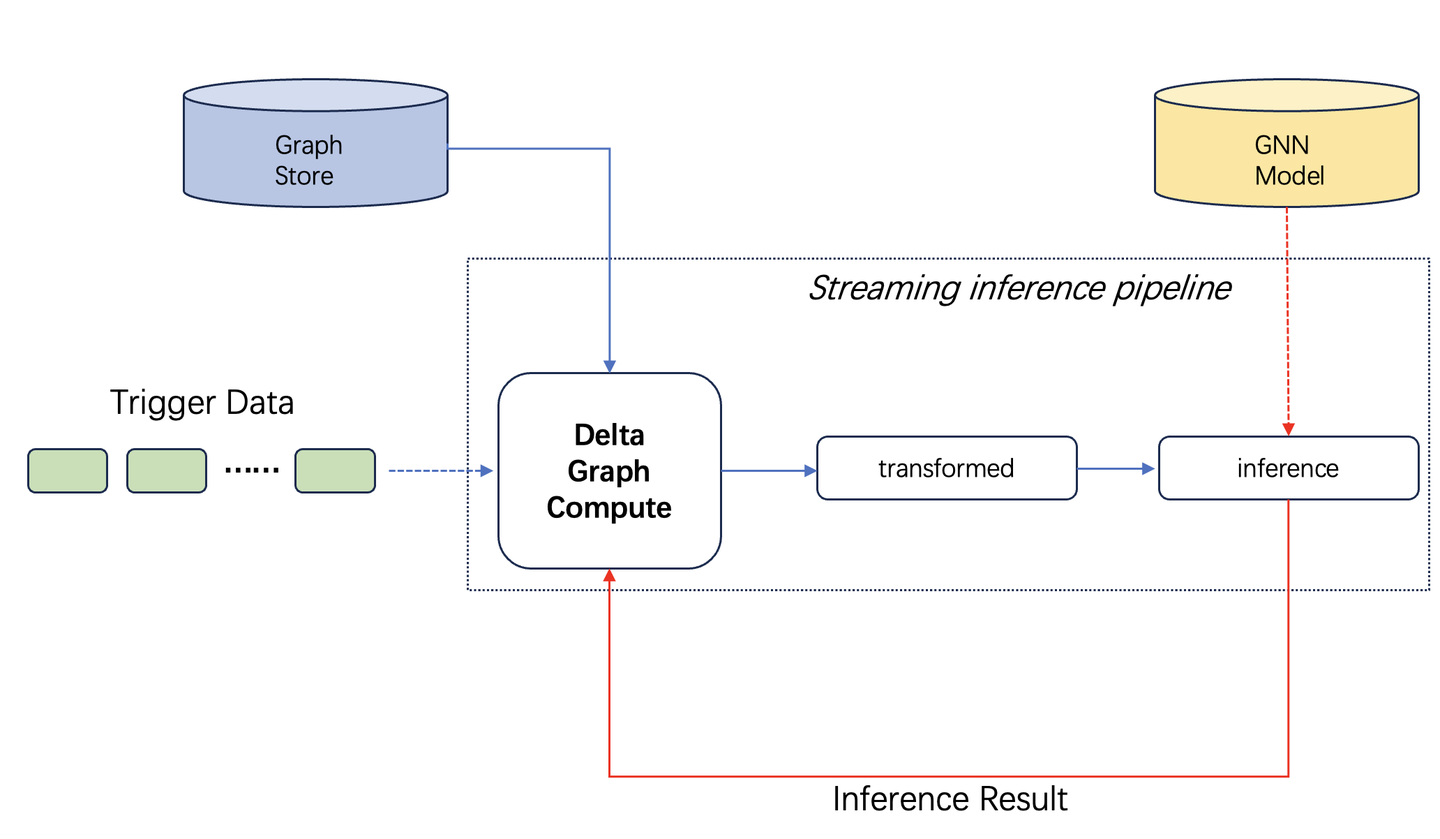
TuGraph Analytics模型推理系统工作流中,Driver端(即控制节点)发挥着至关重要的角色。该节点运行在Java虚拟机进程,是整个推理流程的控制中心。Driver端初始化了一个非常关键的组件——InferenceContext对象,InferenceContext对象被设计为模型推理流程的核心,在JVM环境中创建并负责加载和预处理用户提供的模型文件和环境依赖信息。在模型推理任务之前,InferenceContext会详细检查并准备好模型文件,确保能够正确加载到预期的执行环境中。InferenceContext也负责初始化和配置与模型推理相关的虚拟环境,确保正确的Python环境或其他必要的运行时库得以安装和配置。
如图所示,由流式数据源源不断的触发图迭代计算与模型推理工作。TuGraph计算引擎提供了DeltaGraphCompute计算接口,用户可自主定义增量图数据的处理逻辑,并更新历史的图存储(Graph Store)。通过TuGraph计算引擎模型推理系统,增量图迭代的中间计算结果,经过推理前置数据处理接口,并基于共享内存的跨进程通信方式,将处理后的数据流输入到推理进程,完成推理工作后的结果参与后续图迭代计算逻辑。下文将详细介绍各个数据接口的使用。
4.1 计算推理隔离
在Tugraph Analytics模型推理系统的架构中,集群的工作负载分配给多个worker节点。每个worker节点上运行着两个关键进程:负责图数据迭代计算的Java进程,以及执行模型推理的Python进程。为了充分利用计算系统的资源,推理进程在没有接收到推理请求时,会进入睡眠状态。这样的设计不仅减少了系统资源的占用,而且降低了系统的整体能耗。当推理请求到达时,推理进程会被立即唤醒,接收和执行新的推理任务。借助睡眠与唤醒机制以及智能的任务调度策略,可以保证系统能够以高效、稳定、节能的方式运行,同时满足了大规模图数据处理和实时推理的需求。
在每个worker工作节点下,按照不同的推理作业级别划分基础的虚拟环境,从而保证一个wroker节点也可以支持不同推理任务,支持标准的requirements.txt管理推理依赖库。
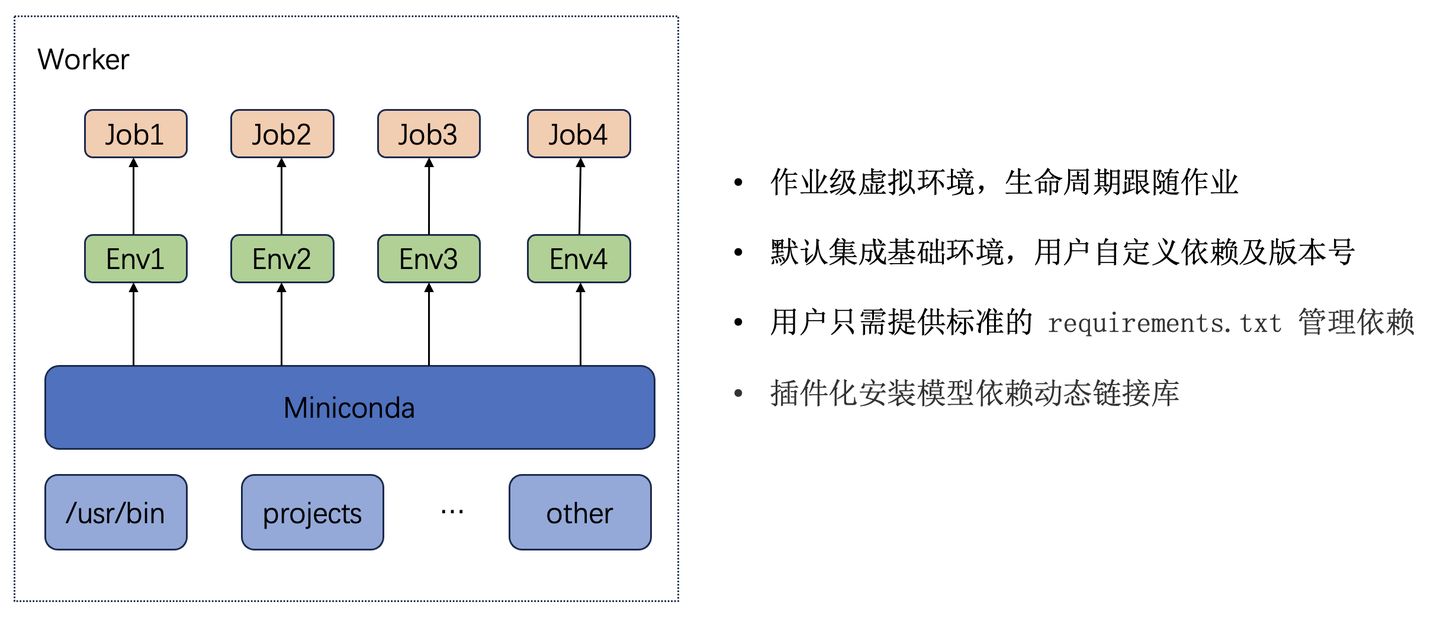
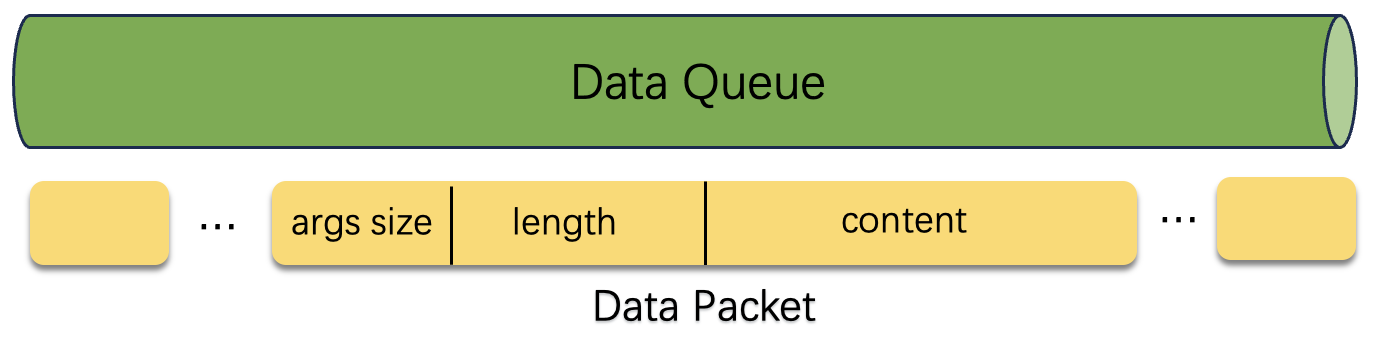
在图迭代计算进程和推理进程之间通过数据队列实现双边数据的交互,通过在数据包的头文件中插入参数个数,长度等信息,推理进程在连续若干次收到空消息包后,将自动进入睡眠状态,释放cpu等资源。图迭代计算进程调用推理接口时,推理进程将快速退出睡眠状态,接收输入数据并完成推理流程。
4.2 跨进程数据交换
对于推理数据的交换部分,底层通过C++开发共享内存管理模块,实现两个进程之间的数据交互。在推理初始化阶段,由InferenceContext对象开辟进程共享内存,Java进程负责创建并初始化推理(Python)进程,通知推理进程共享内存的地址信息,并映射到相应的进程。如图,Java进程和推理进程均采用C++作为桥梁语言,实现共享内存中数据的流动操作。
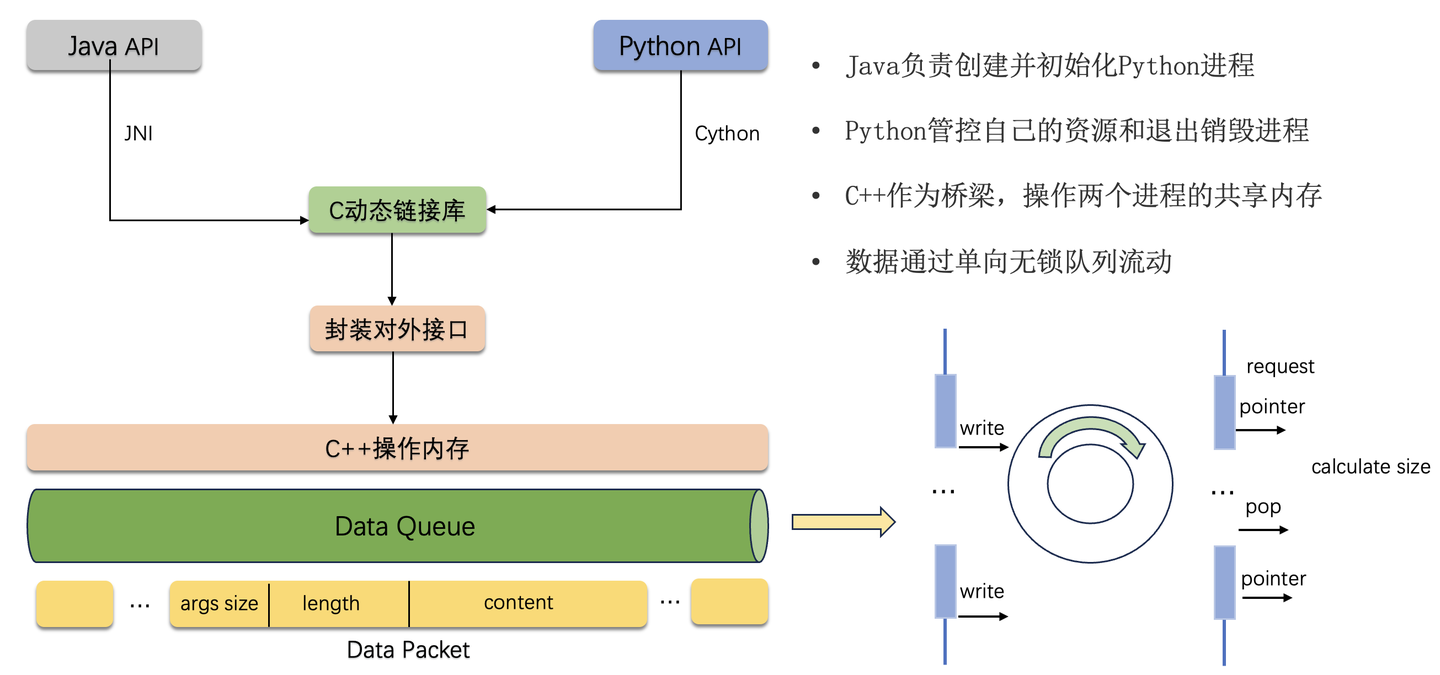
在推理系统的性能测试阶段,我们发现推理进程读写进程时,接口的调用开销不容忽视。常规的理解认为C++能够优化Python的执行效率,但前提是Python的执行内存足够复杂,优化执行内容的收益远大于接口的调用开销。然而,在我们系统设计中,共享内存的读写接口只是操作了内存地址,实现读写指针的移动。因此,接口的调用开销也是影响推理性能的关键因素,为此,我们充分调研了业界主流的方案。
| 解决方案 | 描述 |
|---|---|
| CPython | C语言实现Python及其解释器(JIT编译器) |
| ctypes | Python标准库 |
| SWIG | 开发工具,封装native程序接口 |
| Pybind11/Boost.python/Nanobind | 轻量级头文件库 |
| Cython | Python的超集,使用C语言特性,静态编译 |
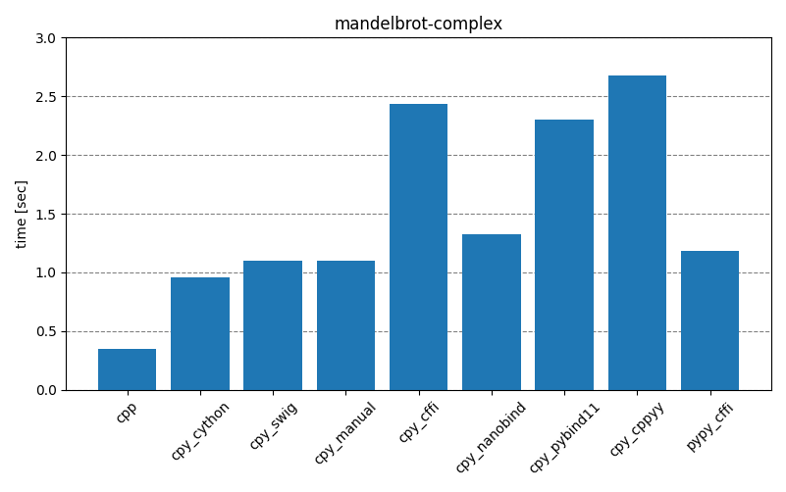
如图所示,我们对比了多种Python调用C链接库的方案,性能是第一要素,因此选择Cython作为推理进程和底层内存交互的工具。Cython是一个编程语言,是Python语言的一个超集,它将/C++的静态类型系统融合在了Python中,允许开发者可以在Python代码中直接使用C语言的特性,从而提高程序的执行效率。Cython将Python源代码翻译为C或C++代码,然后将其编译为二进制代码,能够显著提高数值计算和循环场景的代码执行性能。
4.3 推理接口设计
上文介绍了采用Cython作为推理进程内存管理的链接工具,如下为TuGraph Analytics模型推理系统的内存管理接口设计,提供了初始化,读和写三个接口。
- 初始化接口:负责共享内存地址的映射和读指针的初始化。
- 读接口:数据bytes的长度作为输入参数,直接在内存端上移动相应长度返回数据段,并移动到读指针。
- 写接口:将bytes和bytes长度写入到共享内存,并移动至写指针。
@cython.final
cdef class InferIpc:
cdef MmapIPC * ipc_bridge;
cdef uint8_t* read_ptr;
def __cinit__(self, r, w):
self.ipc_bridge = new MmapIPC(r, w)
self.read_ptr = self.ipc_bridge.getReadBufferPtr()
cpdef inline bytes readBytes(self, bytesSize):
if bytesSize == 0:
return b""
cdef int readSize
cdef int len_ = bytesSize
with nogil:
readSize = self.ipc_bridge.readBytes(len_)
if readSize == 0:
return b""
cdef unsigned char * binary_data = self.read_ptr
return binary_data[:len_]
cpdef inline bool writeBytes(self, bytesBuf, length):
cdef bool writeFlag
cdef int len_ = length
cdef char* buf_ = bytesBuf
with nogil:
writeFlag = self.ipc_bridge.writeBytes(buf_, len_)
return writeFlag
def __dealloc__(self):
del self.ipc_bridge
如下为用户实现推理的Java接口,同其它图迭代计算接口一样,需要推理的时候直接调用该接口,将图迭代的中间结果inputs发送到推理进程并返回模型结果。
public interface GraphInferContext<OUT> extends Closeable {
OUT infer(Object... inputs);
}
5. 最佳实践
我们以PageRank任务结合群组打分模型推理流程为例,演示具体的操作流程。
5.1 数据处理
定义推理数据前后置处理逻辑如下:
import abc
import json
import sys
import os
import torch
class MyInference(TransFormFunction):
def __init__(self):
super().__init__(2)
def transform_pre(self, *args):
return args[0], args[1]
def transform_post(self, *args):
return args[0]
5.2 图迭代推理
定义图迭代计算结合推理逻辑如下:
public static class PRVertexCentricComputeFunction implements
IncVertexCentricComputeFunction<Integer, Integer, Integer, Integer> {
private IncGraphComputeContext<Integer, Integer, Integer, Integer> graphContext;
private IncGraphInferContext<String> inferContext;
@Override
public void init(IncGraphComputeContext<Integer, Integer, Integer, Integer> graphContext) {
this.graphContext = graphContext;
this.inferContext = (IncGraphInferContext<String>) graphContext;
}
@Override
public void evolve(Integer vertexId,
TemporaryGraph<Integer, Integer, Integer> temporaryGraph) {
long lastVersionId = 0L;
IVertex<Integer, Integer> vertex = temporaryGraph.getVertex();
HistoricalGraph<Integer, Integer, Integer> historicalGraph = graphContext
.getHistoricalGraph();
if (vertex == null) {
vertex = historicalGraph.getSnapShot(lastVersionId).vertex().get();
}
if (vertex != null) {
List<IEdge<Integer, Integer>> newEs = temporaryGraph.getEdges();
List<IEdge<Integer, Integer>> oldEs = historicalGraph.getSnapShot(lastVersionId)
.edges().getOutEdges();
if (newEs != null) {
for (IEdge<Integer, Integer> edge : newEs) {
graphContext.sendMessage(edge.getTargetId(), vertexId);
}
}
if (oldEs != null) {
for (IEdge<Integer, Integer> edge : oldEs) {
graphContext.sendMessage(edge.getTargetId(), vertexId);
}
}
}
}
@Override
public void compute(Integer vertexId, Iterator<Integer> messageIterator) {
int max = 0;
while (messageIterator.hasNext()) {
int value = messageIterator.next();
max = max > value ? max : value;
}
IVertex<Integer, Integer> vertex = graphContext.getTemporaryGraph().getVertex();
IVertex<Integer, Integer> historyVertex = graphContext.getHistoricalGraph().getSnapShot(0).vertex().get();
if (vertex != null && max < vertex.getValue()) {
max = vertex.getValue();
}
if (historyVertex != null && max < historyVertex.getValue()) {
max = historyVertex.getValue();
}
graphContext.getTemporaryGraph().updateVertexValue(max);
}
@Override
public void finish(Integer vertexId, MutableGraph<Integer, Integer, Integer> mutableGraph) {
IVertex<Integer, Integer> vertex = graphContext.getTemporaryGraph().getVertex();
List<IEdge<Integer, Integer>> edges = graphContext.getTemporaryGraph().getEdges();
if (vertex != null) {
mutableGraph.addVertex(0, vertex);
graphContext.collect(vertex);
} else {
LOGGER.info("not found vertex {} in temporaryGraph ", vertexId);
}
if (edges != null) {
edges.stream().forEach(edge -> {
mutableGraph.addEdge(0, edge);
});
}
List<String> inferInput = new ArrayList<>();
inferInput.add(String.valueOf(vertexId));
inferInput.add("param2");
String infer = this.inferContext.infer(inferInput.toArray(new Object[]{0}));
}
}
5.3 创建作业
在Console作业管理平台创建一个HLA任务,上传图迭代计算jar包,模型文件和依赖管理文件。
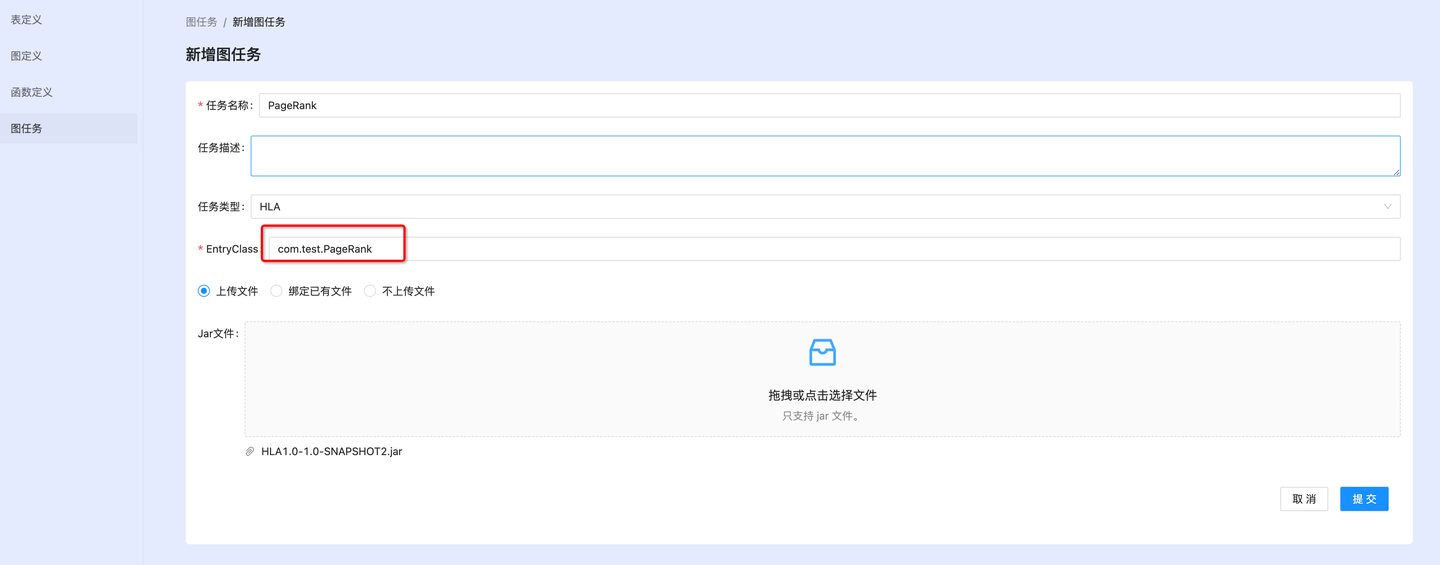
5.4 配置参数
配置相关参数,启动运行作业即可。
"geaflow.infer.env.enable":"true",
// 初始化虚拟环境等待时间
"geaflow.infer.env.init.timeout.sec":120,
// 是否接收日志
"geaflow.infer.env.suppress.log.enable":"true"
6. 总结
通过将AI模型推理引入TuGraph Analytics流图计算系统,让我们能够对图数据进行深度地分析和预测。利用最新的机器学习和深度学习技术,TuGraph Analytics图计算引擎不仅可以对图数据进行分类和回归分析,还可以预测未来趋势,从而在多个维度上提供决策支持。
希望通过以上的介绍,可以让大家对TuGraph Analytics模型推理系统有个比较清晰的了解,非常欢迎大家加入我们社区(https://github.com/TuGraph-family/tugraph-analytics),一起构建图数据上的智能化分析能力!















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









