







#about
大部分shanzai这篇文章、需要迭代更深细节的理解:https://www.cnblogs.com/jhding/p/5687549.html
在今天的分布式计算与存储能力达到一定规模,如果有一个学习算法与数据规模成线性关系、那就达到了商业应用的奇点。
#人脑与视觉系统的研究
人类大脑有两个结构一致的子系统、左半球跟右半球。虽然结构一样、但不仅仅为了冗灾。它们的联系与区别是什么?这两套子系统是独立的,都有独立的意识、学习、记忆(rentention)。它们有不同的功能。左半球跟逻辑计算相关,说话、写作、计算等,外部世界主要与左半球交互。右半球跟音乐、词句理解、非语言的概念、三维空间等相关。左半球是thinker,右半球是artist。
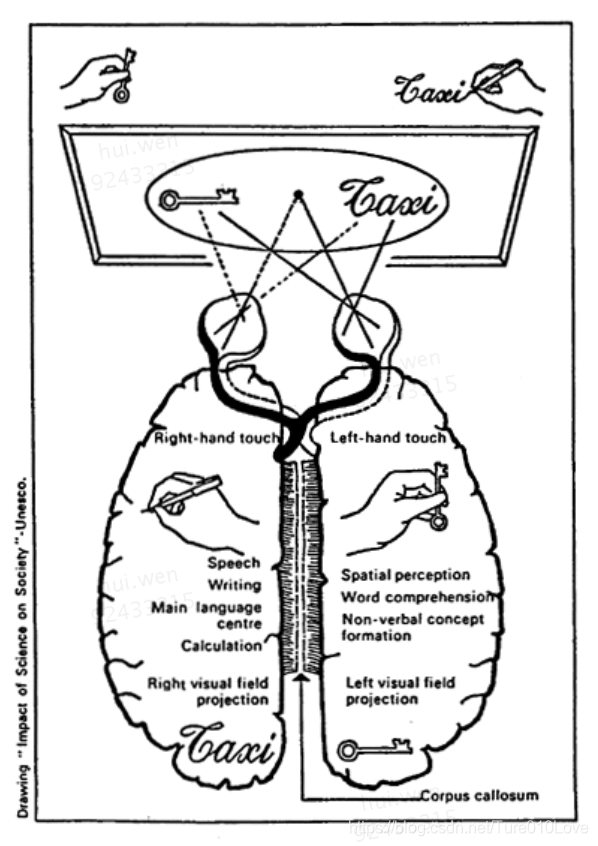
视觉系统是神经系统的一个组成部分。眼睛的视网膜Retina,将采集到的光学刺激信号complie成另一种信号传输给V1区,V1区提取边缘特征,到V2区的基本形状或目标的局部,再到高层V4的整个目标(如判定为一张人脸),以及到更高层的PFC(前额叶皮层)进行分类判断等。视觉系统是一个分级(level)的系统,从低级别信息往高级别做抽象的过程,高层的特征是低层特征的组合。视觉系统将数据经过抽象、降维、形成了更加有意义的信息。
小孩子出生后几天接受的视觉刺激直接影响视觉系统的发育。它需要早期经验的训练。
视觉系统的工作机制直接促进了计算机神经网络的发展。颁发诺贝尔奖给TorstenWiesel以及Roger Sperry时的一段介绍描述:
“To put it extremely simply, one can say that the visual cortex’s analysis of the coded message from the retina proceeds as if certain cells read the simple letters in the message and compile them into syllables that are subsequently read by other cells, which, in turn, compile the syllables into words, and these are finally read by other cells that compile words into sentences that are sent to the higher centers in the brain, where the visual impression originates and the memory of the image is stored.”


#模拟神经元的神经网络
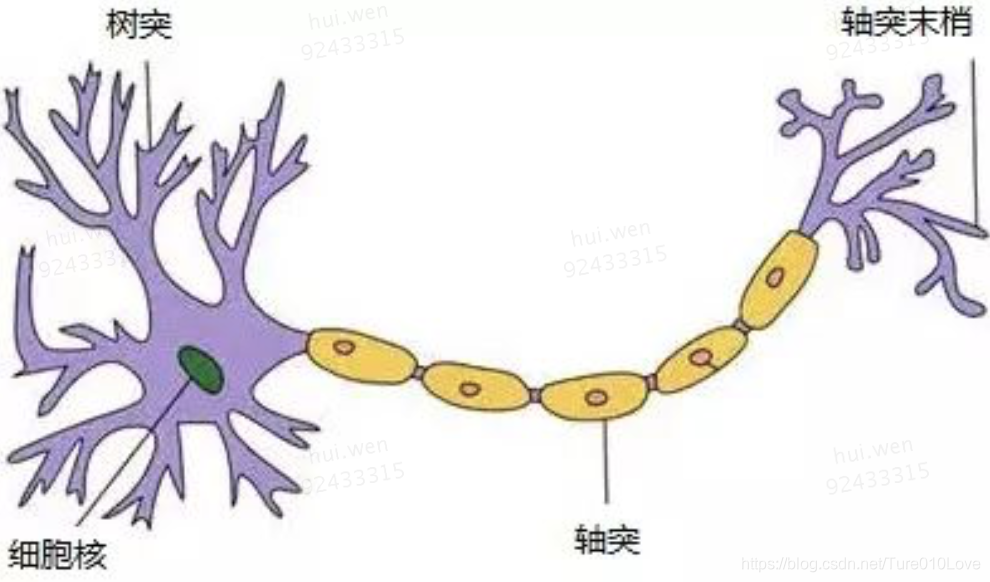
以下是神经元的结构:有很多树突、感知信息,细胞核是控制中心。通过轴突、传输至轴突末梢,给其它神经元。输入与输出都是多端的。
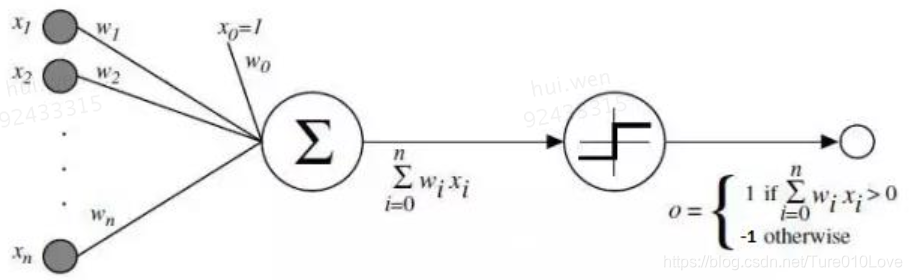
单层神经网络(1956):跟据神经元的结构,模拟创造的结构。感知多个输入变量x,多个变量加权、判断是否达到阈值来决定输出。存在异域XOR问题。
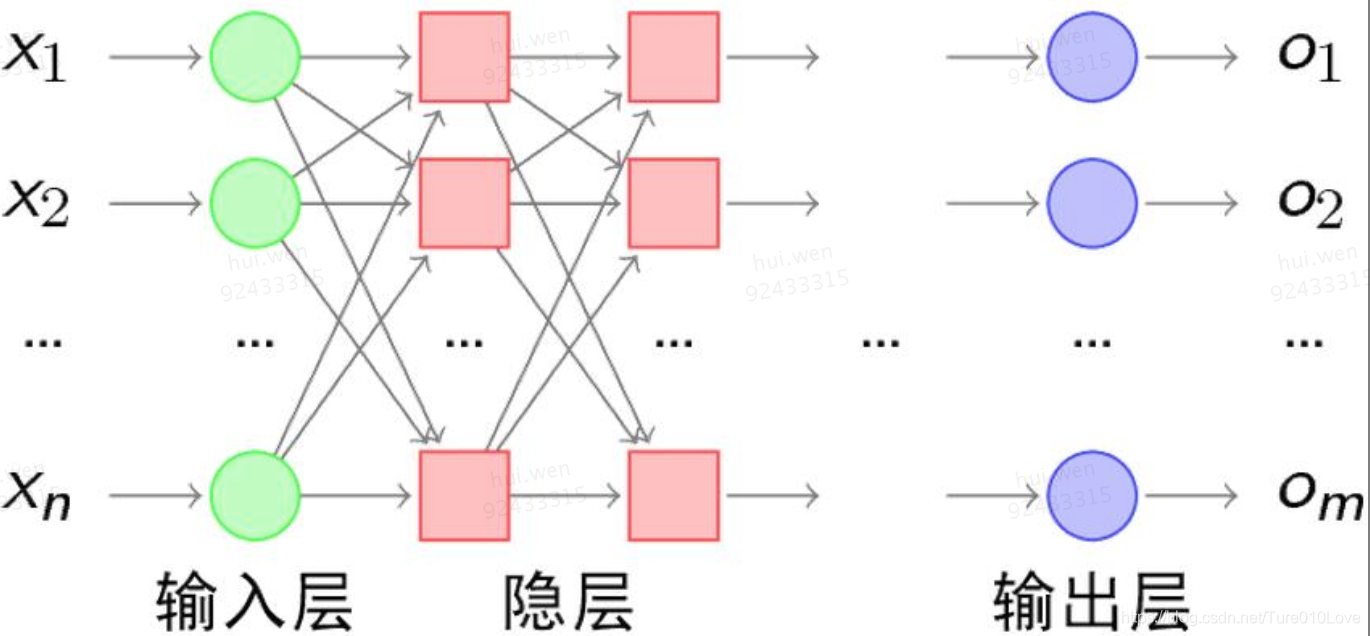
多层神经网络(1969):既然一条直线无法解决分类问题,当然就会有人想到用弯曲的折线来分类样本,因此在单层感知机的输入层和输出层之间加入隐藏层,就构成了多层感知机,目的是通过凸域能够正确分类样本。折线越多、越能切割任意形状。
隐藏层的权值怎么训练?对于各隐层的节点来说,它们并不存在期望输出,所以也无法通过感知机的学习规则来训练多层感知机。
反向传播算法(1982):既然我们无法直接得到隐层的权值,能否先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值呢?BP算法就是采用这样的思想设计出来的算法,它的基本思想:学习过程由信号的正向传播与误差的反向传播两个过程组成。
结合了BP算法的神经网络称为BP神经网络,BP神经网路模型中采用反向传播算法所带来的问题是:基于局部梯度下降对权值进行调整容易出现梯度弥散(Gradient Diffusion)现象,根源在于非凸目标代价函数导致求解陷入局部最优,而不是全局最优。而且,随着网络层数的增多,这种情况会越来越严重。这一问题的产生制约了神经网络的发展。

深度学习(2006):Hinton在世界顶级学术期刊《科学》上的一篇论文[1]中提出了两个观点:(1)多层人工神经网络模型有很强的特征学习能力,深度学习模型学习得到的特征数据对原始数据有更本质的代表性,这将大大便于分类和可视化问题;(2)对于深度神经网络很难训练达到最优的问题,可以采用逐层训练方法解决。将上层训练好的结果作为下层训练过程中的初始化参数。在这一文献中深度模型的训练过程中逐层初始化采用无监督学习方式。
论文提出的"逐层pretraining、fine-tuning微调",解决了反向传播算法Gradient Diffusion的问题。只要满足数据量够大、计算能力够强、初始权重够好这三个条件,反向传播就能找到好的解决方案。该算法与训练集在时间与空间复杂度上呈线性关系。 线性关系,意味着具备商业化的能力。
Pretraining helps generalization because it ensures that most of the information in the weights comes from modeling the images. The very limited information in the labels is used only to slightly adjust the weights found by pretraining. It has been obvious since the 1980s that back propagation through deep autoencoders would be very effective for nonlinear dimensionality reduction, provided that computers were fast enough, data sets were big enough, and the initial weights were close enough to a good solution. All three conditions are now satisfied. Unlike nonparametric methods (15, 16),autoencoders give mappings in both directions between the data and code spaces, and they can be applied to very large data sets because both the pretraining and the fine-tuning scale linearly in time and space with the number of training cases.

#参考资料
https://www.cnblogs.com/jhding/p/5687549.html
https://www.nobelprize.org/prizes/medicine/1981/press-release/
http://www.cs.toronto.edu/~hinton/science.pdf
=>更多文章请参考:《中国互联网业务研发体系架构指南》
=>更多行业权威架构案例及领域标准、技术趋势请关注微信公众号 '软件真理与光':















 1646
1646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









