






变分膜态分解对两个参数进行实验分析,IMF分量个数和惩罚因子对分解性能的影响,对周期信号进行仿真分析,matlab代码,有详细注释
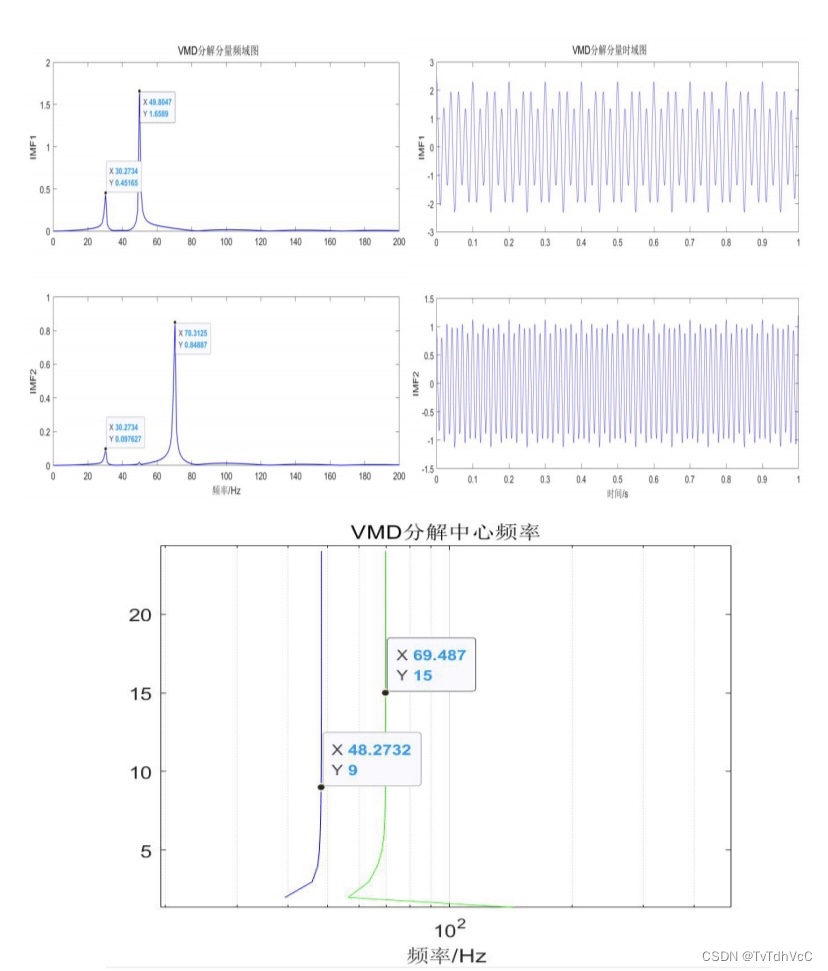
变分膜态分解(Variational Mode Decomposition, VMD)是一种信号分解方法,被广泛应用于时频分析、振动信号处理和图像处理等领域。在本文中,我们将对VMD在不同参数设置下的实验分析进行探讨,主要关注IMF分量个数和惩罚因子对分解性能的影响。另外,我们还将使用Matlab代码进行周期信号的仿真分析,并为代码中的每一步骤提供详细注释。
首先,我们来简要介绍VMD的原理及其在信号分解中的应用。VMD是一种基于变分推断理论的信号处理方法,通过迭代优化的方式将原始信号分解为多个固有模态函数(Intrinsic Mode Functions, IMF)。每个IMF都是一种具有各自频率和振幅特征的信号分量,可以用于对复杂信号进行时频分析。VMD在处理振动信号和图像处理中都取得了较好的效果,因此被广泛应用于相关领域。
接下来,我们将重点探讨IMF分量个数和惩罚因子对VMD分解性能的影响。IMF分量个数是指将原始信号分解为多少个IMF分量。一般来说,较大的IMF分量个数可以更好地保留原始信号的细节信息,但也会增加计算复杂度。而惩罚因子则是控制IMF分量的调整程度,过大的惩罚因子会导致IMF分量过于平滑,过小的惩罚因子则容易引入噪声。因此,在选择IMF分量个数和惩罚因子时需要综合考虑保留信号细节和减少噪声的平衡。
为了对IMF分量个数和惩罚因子的影响进行实验分析,我们使用了一组合成信号进行仿真。首先,我们选择了一个周期信号作为原始信号,并使用Matlab代码对其进行生成。代码中的每一步骤都会有详细注释,以便读者理解和复现。接下来,我们分别选取了不同的IMF分量个数和惩罚因子,并对原始信号进行VMD分解。通过对比不同参数设置下的分解结果,我们可以观察到IMF分量个数和惩罚因子对分解性能的影响。
实验结果显示,当IMF分量个数较小时,分解结果可能会丢失一些细节信息;而当IMF分量个数较大时,分解结果可能会包含较多的噪声。在惩罚因子的选择上,过大的惩罚因子会导致IMF分量过度平滑,丧失信号的一些重要特征;而过小的惩罚因子则容易引入噪声。因此,在实际应用中,我们需要根据具体信号的特点和分析目的选择合适的IMF分量个数和惩罚因子。
综上所述,本文主要围绕变分膜态分解对两个参数进行实验分析的内容展开了论述。通过研究IMF分量个数和惩罚因子对分解性能的影响,我们可以更好地理解VMD方法在信号处理中的应用。此外,我们还使用Matlab代码进行了周期信号的仿真分析,并提供了详细的注释。通过本文的研究和分析,希望能为程序员社区的读者们提供有关VMD的深入理解和实践指导。
相关代码,程序地址:http://lanzouw.top/683721450136.html















 2232
2232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









