






卡方检验(Chi Square Test)被广泛使用,特别是在涉及医学、产品设计、工程和几乎所有研究项目的决策中。
为了理解什么是卡方检验,首先需要了解什么是假设检验,因为卡方检验是假设检验的一种。一旦知道什么是假设检验,就能够在此基础上了解许多不同种类的假设检验,例如卡方检验、t检验、Z检验、Wilcoxon检验等。
1. 什么是假设检验?
假设检验是一种统计分析方法,它查看样本并确定样本的测试结果是否可以应用于全部数据。因为样本只是整个数据集的一小部分,所以基于它们的测试结果总会存在一些不确定性。这意味着由于抽样的随机性质,任何来自样本的测试结果都可能是完全巧合。
1.1 假设检验:一个例子
如果我们想得出工厂里的手机电池的寿命数据。显然,我们是不能测试组装线上的每一部手机的,我们只抽样测试了几个。
有趣的是,不同抽样的电池平均寿命都不相同。有些时候是24.5小时,有些时候是23.7小时等。此外,每次抽样数量也不同。当生产量较低时,样本大小也会降低。
此外,均值只是一个数字,所以当比较两次抽样的均值时,我们无法知道用了多少样本得到了这个数字。因此,当电池平均寿命看起来非常好时,有可能是因为那次抽样的样本量太小造成的。反之亦然。
在这种情况下,我们如何确定电池寿命?
另外,我们如何知道本次抽样的平均值是因为随机抽样而不是实际差异而不同?
这就是我们应该使用假设检验的地方。
使用假设检验,我们将能够从样本中以一定的置信水平(例如95%,99%等),告诉我们电池是否可以续航24小时。
1.2 假设检验
上面是单样本 检验统计量公式。我们可以通过将观测(样本)均值和假设(总体)均值之间的差异除以“标准误差” 来计算检验统计量。式中, 是样本的标准偏差, 是样本大小。
在单个样本测试中,将测试统计量(例如上面的公式)与一个固定的数字(例如24小时)进行比较。然后,从这个测试统计量计算 值,并决定样本均值是否等于假设的总体均值。
根据上面的公式,测试统计量考虑到了样本数量 。因此,通过使用假设检验,我们可以考虑每次抽样样本大小的变化。
那么,什么是“双样本测试”?
在双样本测试中,将会有两个不同的样本。
例如,比较iPhone的电池寿命与三星Galaxy的电池寿命。几乎所有的假设检验都会有单样本和双样本版本。
在假设检验中有三个关键步骤,我们还没有详细介绍,它们是:
设置零假设(null hypothesis),备择假设(alternative hypothesis)和显著性水平( );
从检验统计量计算 值;
根据 值和显著性水平 拒绝或不拒绝零假设。
1.2.1 设置零假设(null hypothesis),备择假设(alternative hypothesis)和显著性水平( )
零假设
首先,它为什么被称为零假设?
零假设假定两个组之间没有关系(在双样本测试中)或总体均值与某些预定义值不同(在单样本测试中)。
因为科学家必须始终持怀疑态度并小心处理他们发现的东西。科学家不能对没有足够证据的事情感到过于兴奋并告诉每个人它有效。
它被称为“零假设”,是因为它假设实验期间观察到的任何差异仅是随机机会的结果(result of random chance)。这个零是我们的默认值。
在足够证据表明零假设不成立之前,零假设被认为是真实的。
[示例 - 如何制定零假设/备择假设]
# 单样本检验
研究问题:COVID疫苗是否能够预防感染?
H0:疫苗不会改变感染率。(然后将感染率设置为当前的常量。)
H1:感染率≠常量
# 两样本检验
H0:苹果手机和Galaxy手机的电池寿命没有差异。
H1:苹果手机和Galaxy手机的电池寿命有差异。备择假设
也称为研究假设。如果备择假设为真,则被视为惊人的发现。
注意:我们以只有一个假设为真的方式构建零假设和备择假设。
显著性水平
也称为 值,是我们可以指定的值,例如1%、5%、10%等。
将其视为偏向备择假设的程度,也可表征为在零假设实际为真时拒绝零假设的概率。
例如,如果将 设置为1%,则不偏向备择假设。但如果将 设置为10%,则容易接受备择假设,因为更容易拒绝零假设。

1.2.2 从检验统计量计算 值
我们将在后面介绍。
1.2.3 根据 值和显著性水平 拒绝或不拒绝零假设
如果 值在显著性水平范围内,能够拒绝零假设。
注意,零假设永远不会被证明是真的,我们只是未能拒绝它。
假设检验是统计学中最重要的概念之一。它在日常生活中被广泛使用,例如产品的A/B测试,药物批准,临床试验等,以帮助公司做出明智的决策。假设检验为我们提供了一个坚实的框架,以使用来自人口的较小样本做出决策。
2. 为什么要进行卡方检验?
卡方检验是一种假设检验。但是为什么要发明这种特定类型的测试?
在上面的假设检验示例中,目标是查看样本平均值是否等于某个常数(例如24小时),这是假设的总体均值(hypothetical population mean)。这个测试的名称是“t-test”,它是最简单和最流行的假设检验之一。
卡方检验用于另一种用途。它是为了看看一件事是否与另一件事有关。例如,考虑在哪里上的大学与他们能赚多少钱。
3. 卡方检验统计量的计算
让我们用数据举个例子。我们将使用卡方检验来查看某些COVID症状和ICU入院是否相关。
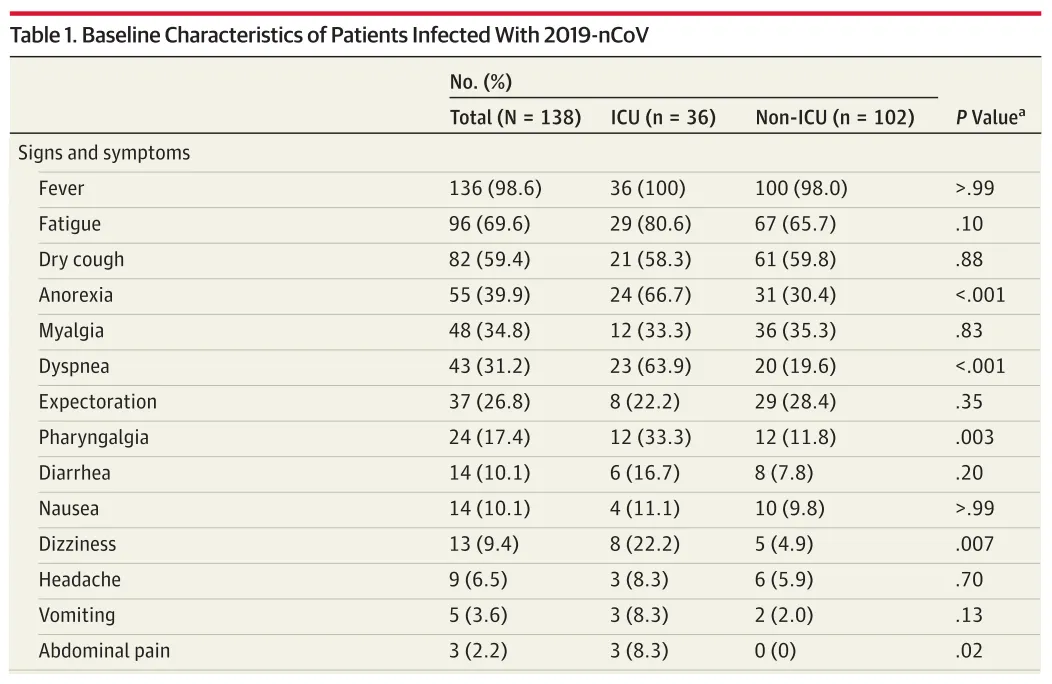
COVID症状和ICU入院数据。https://www.ncbi.nlm.nih.gov/pubmed/32031570
下表显示了多少有和没有厌食症状(anorexia)的人,在感染COVID后进入了ICU。

让我们在这里停一下,试着猜一下这些数字是否相关。
直觉告诉我们,它们似乎是相关的。因为在总共36个进入ICU的人中,有24人(67%)患有厌食症。
然而,也有患有厌食症的人(总共55人)没有进入ICU(31人,总厌食症的56%)。
那么,我们如何确定它们是否相关呢?
我们可以使用卡方检验来确定。步骤如下:
第一步:根据给定数据创建表格,也称为“条件表”或“观察O”;
第二步:为每个数据点计算“期望值E”;
第三步:计算 ;
第四步:通过添加第3步中的值来获取 (卡方);
第五步:获取你的“自由度”;
第六步:计算 值,或查找卡方概率表中的检验统计量。第一步:根据给定数据创建表格,也称为“条件表”(Contingency Table)或“观察O”(Observation O)

第二步:为每个数据点计算期望值
在卡方检验中,为每个数据点计算期望值。
在概率论和统计学中,一个离散性随机变量的期望值(或数学期望,亦简称期望,物理学中称为期待值)是试验中每次可能的结果乘以其结果概率的总和。换句话说,期望值像是随机试验在同样的机会下重复多次,所有那些可能状态平均的结果,便基本上等同“期望值”所期望的数。期望值可能与每一个结果都不相等。换句话说,期望值是该变量输出值的加权平均。期望值并不一定包含于其分布值域,也并不一定等于值域平均值。(https://zh.wikipedia.org/wiki/期望值)
例如,掷一枚公平的六面骰子,其每次“点数”的期望值是3.5,计算如下:

不过,3.5虽是“点数”的期望值,但却不属于可能结果中的任一个,没有可能掷出此点数。
按如下方法计算期望值。

忽略实际观察值

相反,根据总数比例计算期望值
忽略实际计数,使用“总计”列和行ICU(36),非ICU(102),厌食症(55)和非厌食症(83)来按比例计算期望值。
在这个例子中,通过简单地按比例计算总数,你可以得出单元格ICU,厌食症的期望值如下:在36个ICU患者中,预计有36 *(55/138)名患有厌食症的患者。
为什么要计算期望值E表?
因为,如果实际观察值,例如[ICU,厌食症]的24与期望值(36 * 55/138 = 14.35)有很大的不同,那么厌食症和ICU之间可能会有一些关联。另一方面,当观察结果类似于预期时,无论是ICU还是非ICU,患有厌食症的患者的比例都将相同。那么,厌食症对ICU入院可能没有太大的影响。
得到观察值(O表)与期望值(E表)。

第三步:计算
公式为卡方检验中使用的卡方统计量, :自由度, :观测值, :期望值。
这个公式是什么意思?为什么这个公式是卡方检验的检验统计量?
卡方检验统计量基本上是观测值和期望值之间差异的平方和的标准化。它是标准化的,因为它像任何典型的标准化一样将平方差除以期望值。基本上,这个检验统计量告诉我们观察值偏离了期望值多少。
但是,我们为什么要使用卡方分布来计算检验统计量的 值呢?
我们为什么相信检验统计量会遵循卡方分布?
原因在这里。
当 是独立的标准正态变量时,那么这些随机变量的平方和 ,
遵循均值为 ,标准差为 的卡方分布。
等等,我们的观测数(24、12、31、71等)是独立的标准正态变量吗?
如果它们遵循正态分布,它们可以。因为正态分布中的任何点 都可以用公式 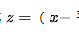 (平均值)/标准差 转换为标准正态分布 (z) 。
(平均值)/标准差 转换为标准正态分布 (z) 。
那么,我们的观察数(24、12、31、71等)是否遵循正态分布?
根据中心极限定理(Central Limit Theorem,CLT),如果从一个群体中取样足够大(样本大小大于30通常被认为足够保持CLT),即使群体不是正态分布,样本的平均值也将是正态分布的。
那么,我们的观察结果(24、12、31、71等)似乎不是其他数字的平均值,它们就是数据本身。如果是这样,为什么我们认为这将遵循正态分布呢?
如果我们可以将数据点显示为均值会怎样?
让我们看看我们的列联表。

你能在这里看到伯努利试验的暗示吗?
是的,因为每个变量(厌食症和ICU)只有两种可能的结果,“成功”和“失败”。
从二项分布的角度来看,患者的总数为 ,每个比率(ICU成功的36/138,厌食症成功的55/138)都将是 。
当二项分布中的 越来越大时, 将遵循平均值为 ,标准偏差为 的正态分布。
这被称为二项分布的正态近似(Normal Approximation to Binomial Distributions)。
对于足够大的 ,具有 次试验和成功概率 的二项分布越来越接近于正态分布。正态分布将具有与二项分布相同的平均值 和标准偏差 。
下面,让我们联系起来。
现在我们知道样本是从正态分布中取出的。然后,(观察值-期望值)值也将遵循正态分布,因为 是一个常数。然后使用卡方分布用于检验统计量是有道理的,因为卡方分布是 个标准正态分布的平方和。
卡方检验通常忽略了这个正态分布的假设,但这个假设是卡方检验成立的原因。
第四步:将步骤3中的值相加,即可得到 (卡方)

卡方检验统计量:
第五步:获取“自由度”
每个分布都有参数。例如,正态分布的参数是平均值和标准差。二项分布的参数是 和 等。
卡方分布有什么参数?
它有自由度, 。
“自由度”是什么意思?它是如何工作的?它是否意味着我有多少自由度?这是一个奇怪而令人困惑的名字...
为了给你一个容易记住的例子,假设有三个随机变量 、 和 ,它们的平均值为15。
在这种情况下,这三个随机变量中有多少个实际上是随机的?
只有两个。
为什么?假设 和 有变化的自由度。但是,为了使它们的平均值为15, 必须是 。因此, 没有自由度来变化。
现在让我们将这个概念应用到卡方的自由度上。
你可以将自由度视为用于计算检验统计量的独立信息片段的数量。
在我们的情况下,我们有一个 的列联表。我们知道样本的总数。在这种情况下,df是1。为什么?因为在 的表中,一旦你知道一个数字,给定总数,表中的其他单元格就被设置了。
让我们将这个概念转化为一个公式。
对于具有 行和 列的列联表,计算卡方检验自由度的公式如下:
自由度 = (# of rows - 1)×(# of columns - 1)
这是一个合理的概括吗?我相信这是这样的。
那为什么我们需要考虑自由度?
因为自由度会影响卡方分布的形状。因此,它会影响关于是否拒绝零假设的决策。
第六步:计算P值,或从卡方概率表中查找检验统计量
最后一步是计算 值。许多 值计算器都可以在网上找到。一个很好的例子是:https://www.di-mgt.com.au/chisquare-calculator.html

或者使用Python,只需几行代码即可计算 值。
from scipy.stats import chi2_contingency
table = [[24, 12], [31, 71]]
alpha = 0.05
test_statistic, p_value, dof, expected = chi2_contingency(table)
if p_value <= alpha:
print('Variables are not independent (reject H0)')
else:
print('Variables are independent (fail to reject H0)')大家可能在学校里学习了卡方概率表。此表中的值不是 值。它们是卡方分布的检验统计量,基于不同的自由度和置信度 。我们需要将计算出的检验统计量与该表中的数字进行比较。

注意,卡方检验对样本量特别敏感。观察左下角(20 df / 的7.434)和右上角(1 df / 的7.879)。它们的检验统计量是可比较的。这意味着,在样本量足够大的情况下,即使连接看起来不显着,也可能出现统计显着性。
至此,我们只是手动计算了卡方检验统计量。
在此步骤之后,我们将遵循假设检验的标准步骤,即根据 值和显着性水平 拒绝或未能拒绝零假设。
这个步骤只有两种可能的结果。
值小于 。我们可以拒绝零假设。
值大于 。在这种情况下,我们无法拒绝零假设。
了解更多 值内容,请阅读https://towardsdatascience.com/how-to-interpret-p-value-with-covid-19-data-edc19e8483b,后面我们会介绍这篇文章。
4. 结论
最后,祝学习愉快!
本文来源:
https://medium.com/intuitionmath/chi-square-test-intuition-examples-and-step-by-step-calculation-de45c873abd1
来源:我得学城;
「完」
版权声明:本号内容部分来自互联网,转载请注明原文链接和作者,如有侵权或出处有误请和我们联系。
更多相关知识请回复:“ 月光宝盒 ”;
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









