







KMP方法作为一种更快速的字符串匹配方法,其加速的效果暂且按下不表,这里记录一下它背后的原理:核心思想是减少不必要的匹配,手段是利用上次匹配失败得到的已知信息。
对于传统的BF法,我们将pattern N从前到后与文本M依次进行匹配的情况如下:
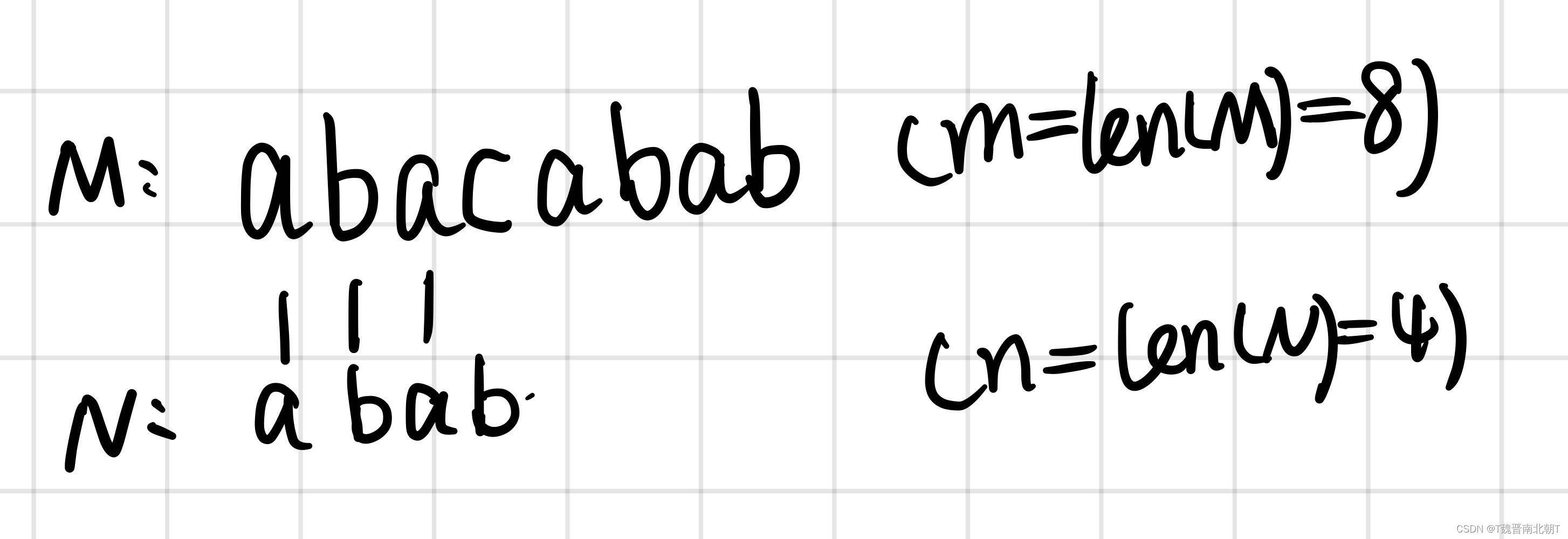
可以发现在匹配第4个字母时,M和N出现了不同,导致最终的匹配不成功,匹配的长度为3,记partial_match_length = 3。按道理来说我们应该将N向后移动一个单位,检查下面的匹配情况:
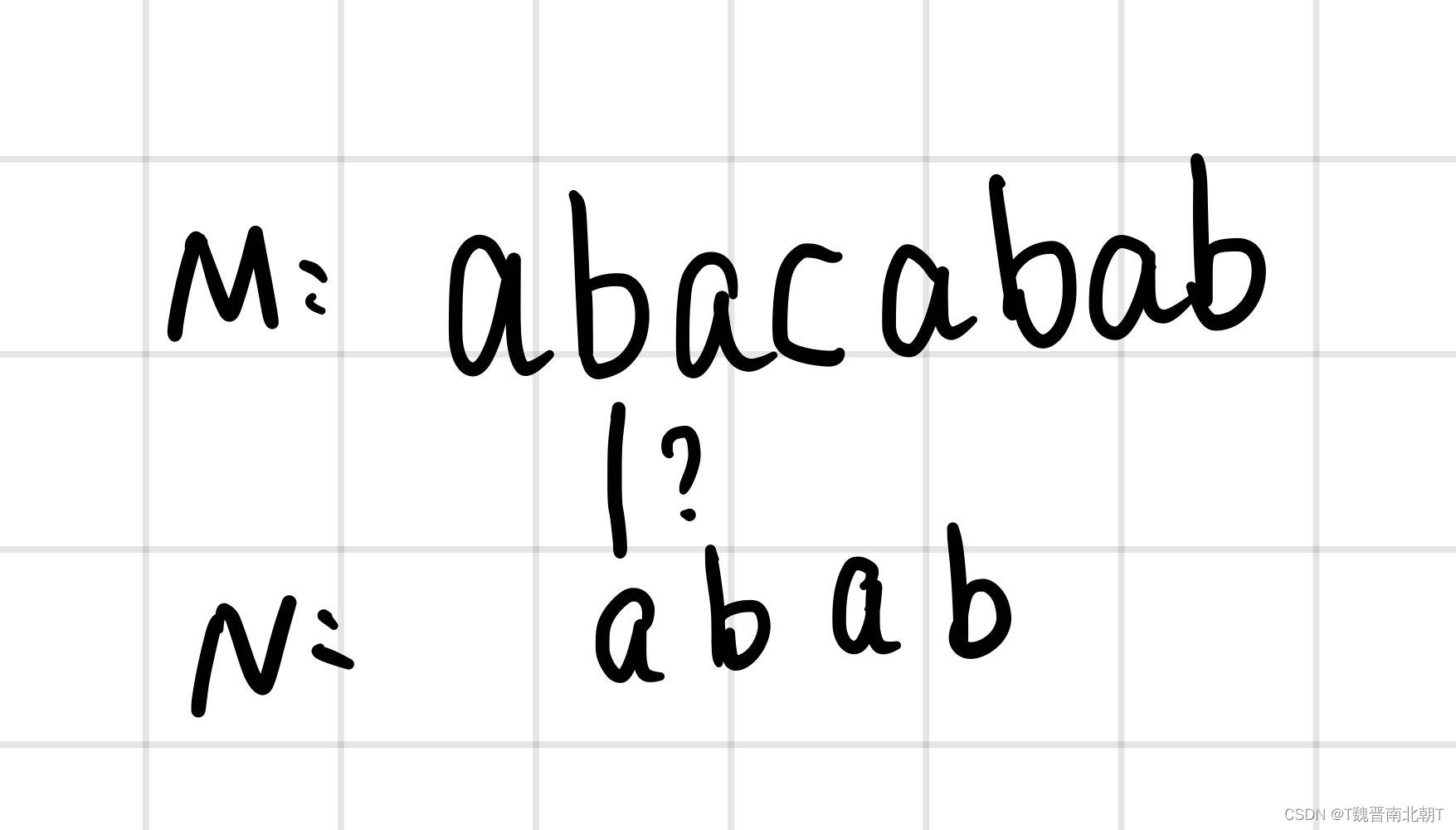
但是转念一想,不对啊,我明明已经知道,M和N的前3个字母是一样的,就算M的第一个字母被抬走了,但我是知道第2,3个字母的,我为什么要假装不知道,重新再一个一个比较呢?于是为了利用起来我们提到的信息,我们引入KMP。
1. 你说利用就利用啊?
好了,既然强调了一遍我们已知道前3个字母,M和N是相同的。按照BF法,我移动后应该必然要进行的一步比较是:比较M的第2,3个字母和N的第1,2个字母是否相等,再换一种说法,比较N的第2,3个字母和N的第1,2个字母是否相等。(重要的事情再强调一遍,已知M和N的前3个字母相同)这一个小小的替换不得了,没有M的事情了,这里的判断只取决于N的性质了(当然,match_length是二者共同影响)。
这就相当于我们利用刚才说的信息给BF做比较前先做了一个判断,如果得到了否的结果,我们直接跳过,不需要把展开了,是不是听起来就快了一些?
2. 到底该怎么利用呢?
不难发现啊,partial_match_length相当于告诉我截取个片段,接下来只需要考虑这个P。
P = N[0:3] 而比较一下P[:2]和P[1:]是否相等并不难,这里我们比较前k个和后k个是否相等,而k=partial_match_length - 移动步数x。如此循环往复,就可以一定程度上加快N向右移动的速度,但我们还是不满意,难道一定要一步一步的向右吗,能不能把条件调换一下,我想要移动到第一个能匹配的位置,我应该移动几步呢?
回到刚才的思路,移动后,第一个满足P[:k]=P[-k:]的步数就是我们想要的咯,再换句话说,移动步数x越大,k越小,P[:k]就应该越短,所以,第一个满足P[:k]=P[-k:]的也是最长的P[:k],所以我们只需要对所有可能的P,提前计算出满足P[:k]=P[-k:]的k并存起来就好!
3. 回到实例来看看
描述起来可能比较抽象,让我们再一次回到刚才的例子中,完成了第一轮的比较,我知道二者前三个公共元素相同,为了加快匹配速度,我应该将N向后移动几个单位呢?
partial_match_length = 3, k所有的可能性为0, 1, 2,
所以我们要从最长的k开始考虑:
- P[:2]=P[-2:]:True
- ..
运气不错,一次就成功了,我们需要向后一步,当然这个例子举的不好,所以只能搞成这样,如果N长一些,效果会好很多,我们这里定义的k更容易理解,和官方的版本略有出入,如果想看更正式的版本可以参考:















 8648
8648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









