







1. 本章问题描述
假设我们已经拥有了如下的线性模型:
Y
=
β
0
+
β
1
X
1
+
⋯
+
β
p
X
p
+
ϵ
Y = \beta_0+ \beta_1X_1+ \cdots+ \beta_pX_p+\epsilon
Y=β0+β1X1+⋯+βpXp+ϵ
但并非所有的
{
X
i
}
\{X_i\}
{Xi}对于模型的预测都有帮助,保留冗余的变量不仅会增大计算量,也会导致预测效果变差以及可解释性降低。应该如何选择合适的
{
X
i
}
\{X_i\}
{Xi}使得模型的预测效果最好呢?
2. Subset Selection
2.1 BF实现思路及过程
先来一个BF算法,想要找到效果最好的
{
X
i
}
\{X_i\}
{Xi}组合,一个很自然的想法就是我把所有的组合情况都拟合一遍试试:

M
i
M_i
Mi表示从
p
p
p个指标(
X
X
X)中选择
i
i
i个指标所有的可能性里面表现的最好的那个(
C
p
i
=
>
1
C_p^i=>1
Cpi=>1)。一些其他符号的计算方法:

2.2 评价指标
我们既然要选择表现得最好的,就得设定衡量好坏的标准:
- A I C = − 2 log ℓ ( θ ^ ) + 2 d AIC = -2\log\ell(\hat\theta) + 2d AIC=−2logℓ(θ^)+2d
θ ^ \hat\theta θ^是最大似然估计, ℓ ( θ ^ ) \ell(\hat\theta) ℓ(θ^)是似然函数在最大似然估计的值, − 2 log ℓ ( θ ^ ) -2\log\ell(\hat\theta) −2logℓ(θ^)也被称为Deviance。 d d d是模型参数的数量,引入d是很重要的,因为模型越复杂一定程度上拟合效果确实会更好,所以需要正则化。AIC越小,模型就越好。
- B I C = − 2 log ℓ ( θ ^ ) + log ( n ) d BIC = -2\log\ell(\hat\theta) + \log(n)d BIC=−2logℓ(θ^)+log(n)d
2.3 实际使用的注意事项
- 与Cross Validation相结合:当我们使用不同folder得到结果并且平均后:
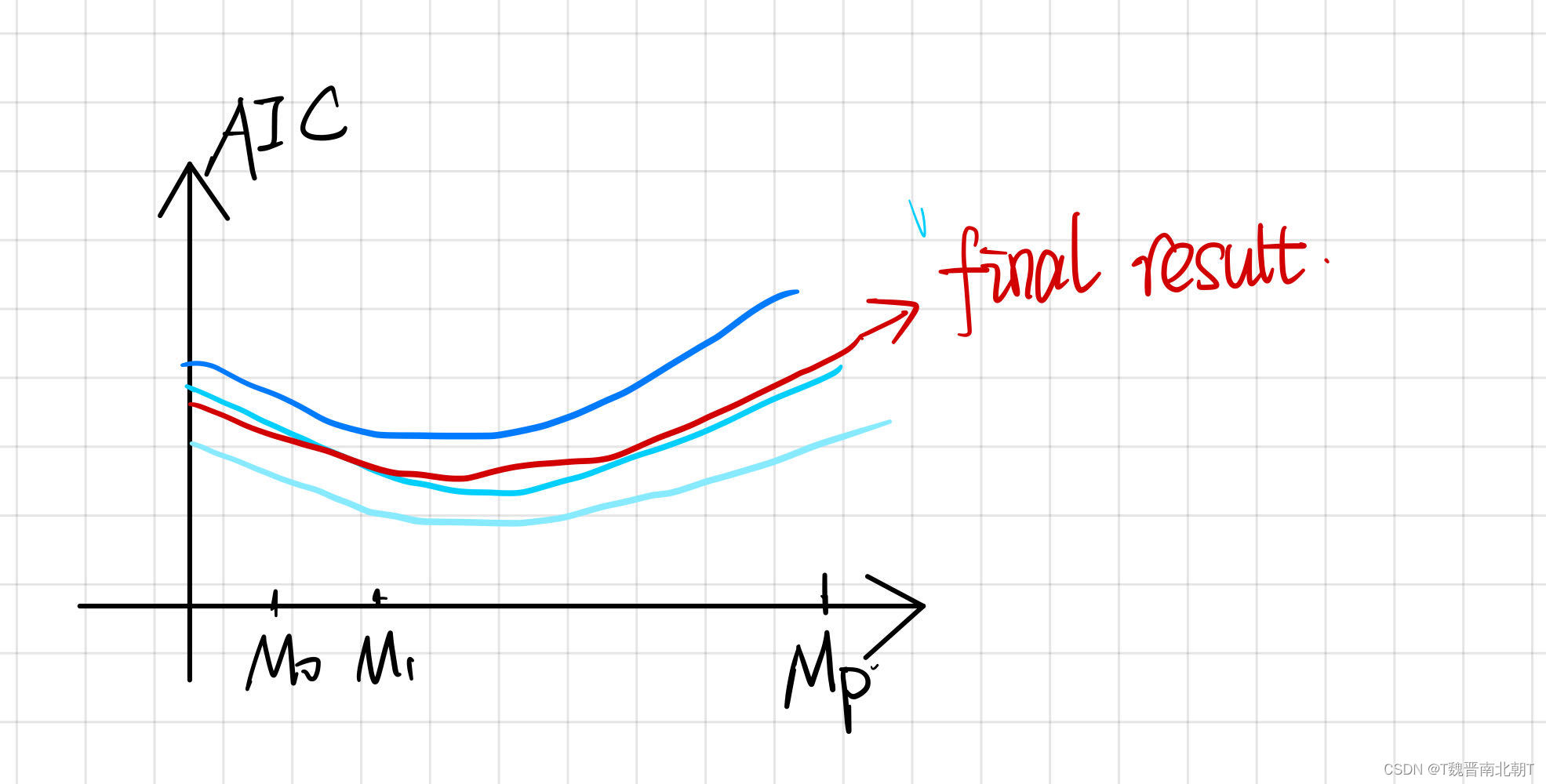
例如 M 2 M_2 M2是最好的结果,应该选取两个变量进行线性回归,但应该选取哪两个呢?
答:应该再去拿所有的数据对两两一组的标签重新进行拟合,选取效果最好的一组。 - 所有的表现都是针对训练集而言
不能认为这就是模型的测试集表现(need new data) - 我既然已经遍历了所有可能性,找到的一定就是全局最优吗?
答:如果不存在噪音 ϵ i \epsilon_i ϵi的话,一定是全局最优。但现实是不一定,且噪音越大,效果越差
2.4 BF的改进:Forward Stepwise Selection
直接讲不同点:不再列举所有可能性,从选取第一个标签开始,我直接选择当前拟合最好的那个。第二步选择的时候,我令其中一个标签是我上一步选好的结果。(每一步都选局部最优)这样比较的模型数量就变为:
∑
k
=
0
p
−
1
=
1
+
p
(
p
+
1
)
2
\sum_{k=0}^{p-1}=1+\frac{p(p+1)}{2}
∑k=0p−1=1+2p(p+1)个,大大减少。

存在对应的Backward,不过没啥改善,也没有更快。
3. Shrinkage Methods
与其说我手动去测试需要哪些
{
X
}
\{X\}
{X},不如改变他们的权重,让求解得到的权重部分为0,就相当于间接完成了选择。在之前的计算中
β
i
\beta_i
βi是通过求解如下问题获得的:
min
R
S
S
\begin{equation} \min RSS \end{equation}
minRSS
如今在后面引入Shrinkage Penalty使得
β
j
→
0
\beta_j\to0
βj→0
min
R
S
S
+
P
e
n
a
l
t
y
\min RSS +Penalty
minRSS+Penalty
3.1 引入后的求解变化
-
- Non-standarization without intercept(最简单的情况)
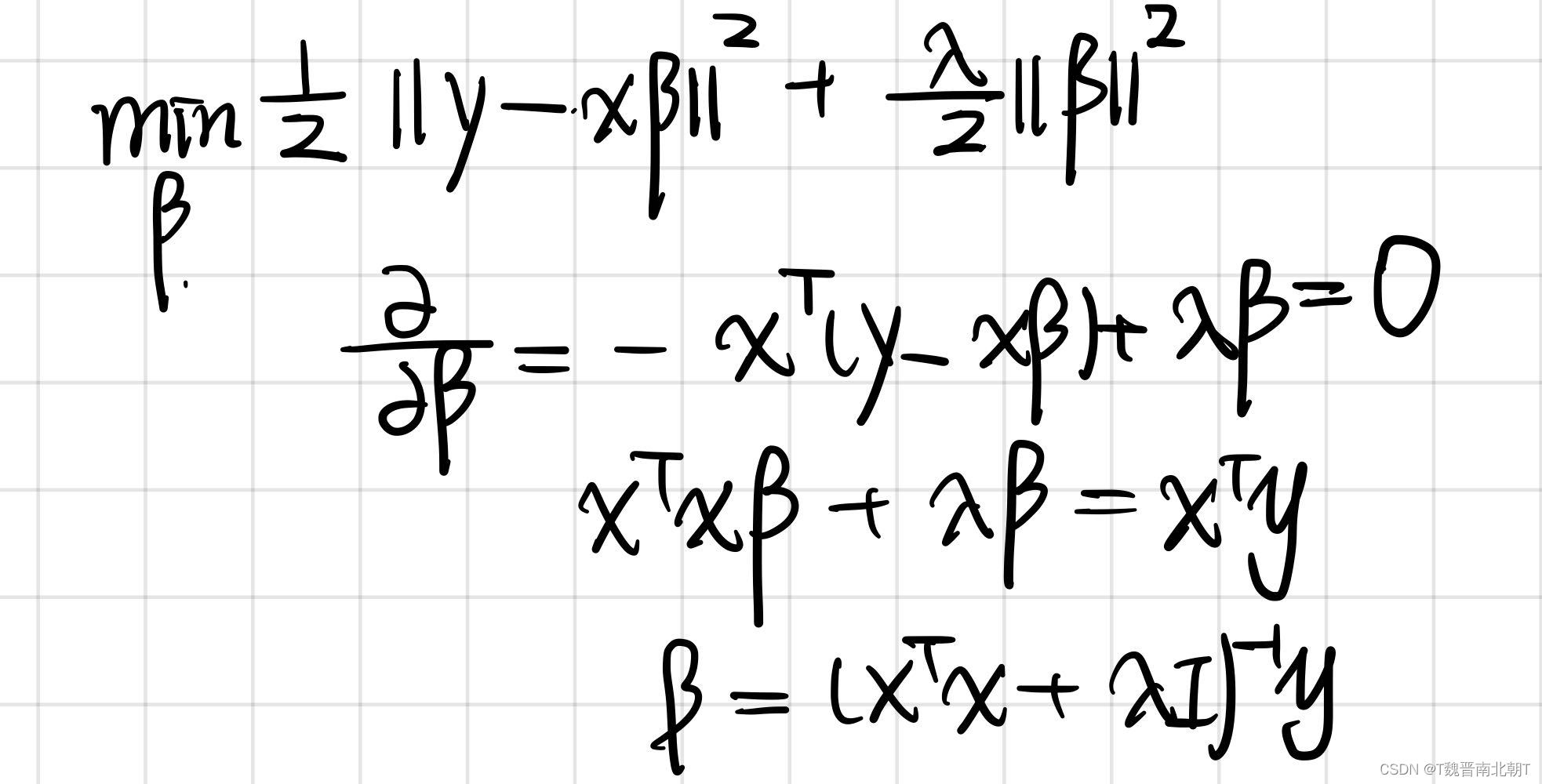
- Non-standarization without intercept(最简单的情况)
-
- Non-standarization with intercept

- Non-standarization with intercept
-
- Standarization

可以发现,在第二步中, β 0 ≠ y ˉ \beta_0\ne\bar{y} β0=yˉ,但是在标准化以后,就保证了 β i = y ˉ \beta_i=\bar{y} βi=yˉ和 β i \beta_i βi不依赖于 λ \lambda λ。
- Standarization
3.2 为什么有效(Lasso)
我们都知道有L0,L1,L2等等正则化项,并且也知道L1正则化项能使得系数矩阵稀疏(很多系数为0),但是为什么呢?
答:我们总能选取足够大的L1系数
λ
\lambda
λ,实现Subset Selection。
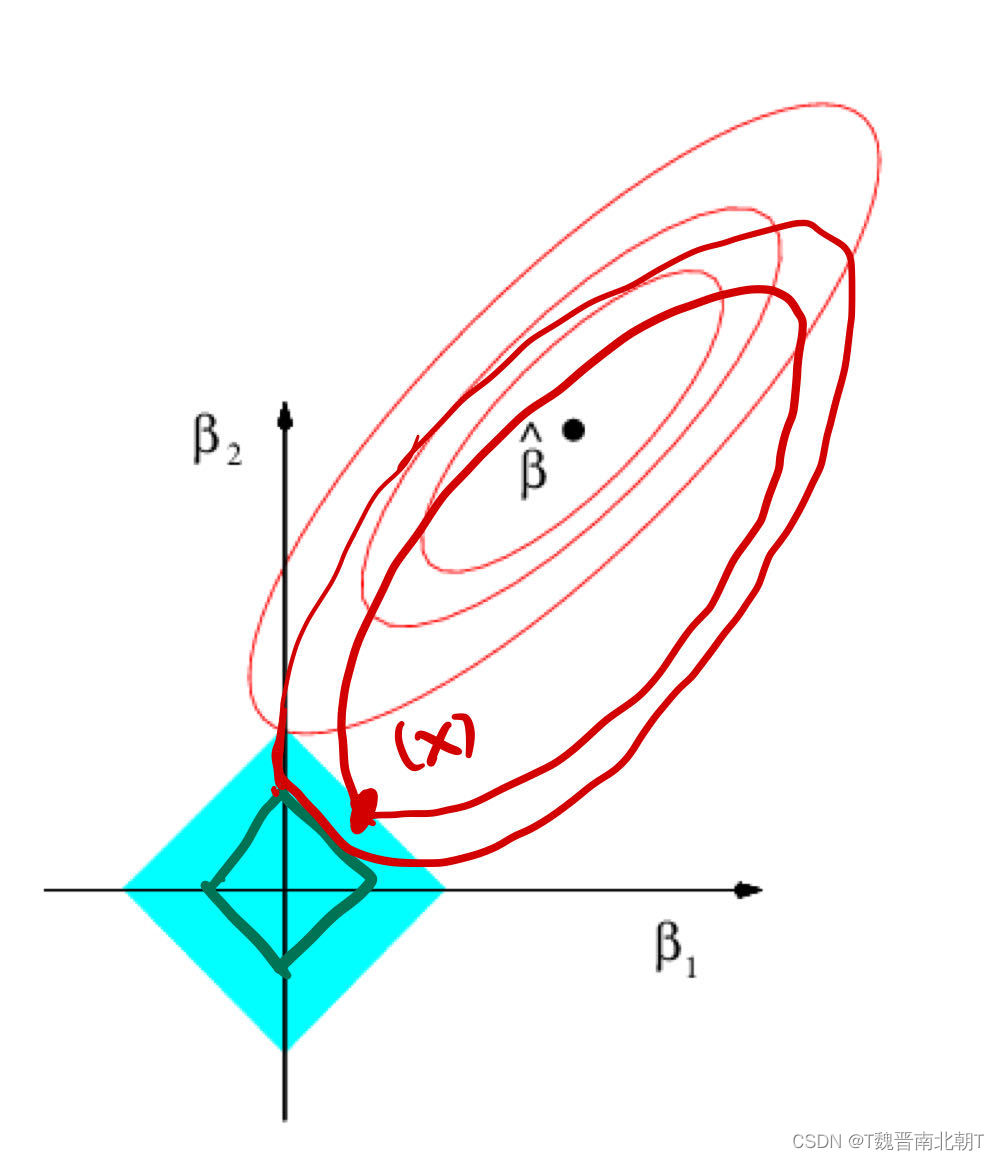
当红色椭圆和蓝色方形相交于坐标轴时,就实现了我们selection的目标,但是如果没有相交于坐标轴的话,我们可以增大
λ
\lambda
λ来减小矩形的面积,让他们调整之后重新相交于坐标轴。我们知道一定是有解的,至于为什么在坐标轴上一定有解,嗯,是个好问题,亟待你去发现。
3.3 实现时的注意事项
- 如果是结合k-folder使用,如k=5,n=1000,我对800个样本进行回归,按照如上公式找到的
λ
\lambda
λ其实是不适用于其他样本数的模型的。为了消除这种影响,要对目标函数除以n:
1 800 ∑ i = 1 800 ( y i − x i T β ) 2 + λ ∑ j β j 2 \frac{1}{800}\sum_{i=1}^{800}(y_i-x_i^T\beta)^2+\lambda\sum_j\beta_j^2 8001i=1∑800(yi−xiTβ)2+λj∑βj2 - 标准化以后得到的回归模型如何面对新的数据?
答:面对新的数据时,会有新的均值和标准差,用起来不好操作而且当新的数据只有一个时,无法进行标准化。因此,需要将模型转换回标准化之前的变量名:
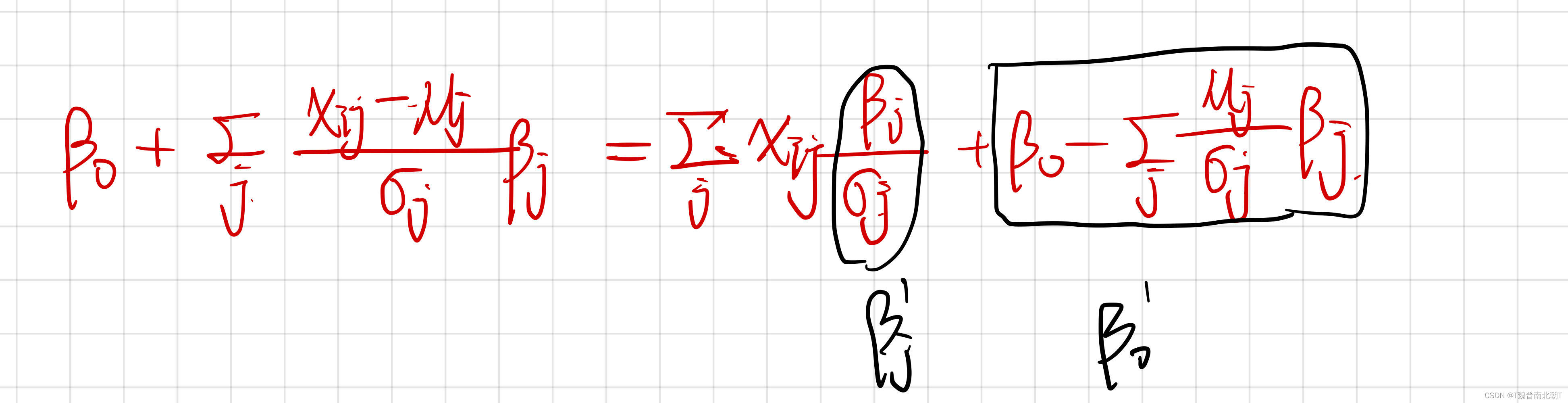
- 求解过程比较复杂,可以参考矩阵优化算法中方法适当优化
主要是求逆的过程可以进行适当分解,详情参加6.1。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









