







Collaborative Filtering
协同过滤简述
1.思想
- 推荐算法是机器学习算法的一种。推荐算法有很多,其中协同过滤算法便是其中经典的一种。当今仍在大量使用。
- 具体来说,协同过滤的思路是通过群体的行为来找到某种相似性(用户之间的相似性或者标的物之间的相似性),通过该相似性来为用户做决策和推荐。
- 一般来说,协同过滤推荐分为三种类型:
- 基于用户(user-based)的协同过滤
- 基于项目(item-based)的协同过滤
- 基于模型(model based)的协同过滤
2.相似度的计算
相似度是衡量两个变量相关程度的指标。它通过称为相关系数的度量来衡量。它的值介于0和1之间。
在日常使用中,一般习惯于将相似度与1类比,相似度在数值上反映为0<=Similarity(X,y)<=1,越接近1,相似度越高
- 欧几里得距离
d i s t e d ( x ( i ) , x ( j ) ) = ∣ ∣ x ( i ) − x ( j ) ∣ ∣ 2 = ∑ u = 1 n ∣ x u ( i ) − x u ( j ) ∣ 2 dist_{ed}(x^{(i)},x^{(j)})=||x^{(i)}-x^{(j)}||2=\sqrt{\sum{u=1}^n |x_u^{(i)}-x_u^{(j)}|^2} disted(x(i),x(j))=∣∣x(i)−x(j)∣∣2=∑u=1n∣xu(i)−xu(j)∣2
欧氏距离是通过计算样本实际距离在度量相似度的。
欧几里得距离是数据上的直观体现,看似简单,但在处理一些受主观影响很大的评分数据时,效果则不太明显
- 皮尔逊相似度


- 夹角余弦
由上求余弦的向量公式,可得知当两个向量的夹角越小,两个向量方向越相近。当夹角为0时,两个向量方向完全重合。由此原理可以计算两个事物的相似度。

- 杰卡德相似度
两个集合A和B交集元素的个数在A、B并集中所占的比例,称为这两个集合的杰卡德系数,用符号 J(A,B) 表示。
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A,B)=\frac{|A\cap B|}{|A\cup B|} J(A,B)=∣A∪B∣∣A∩B∣
基于用户的协同过滤(user-based CF)
1.原理
基于用户的协同过滤算法是通过用户的历史行为数据发现用户对商品或内容的喜欢(如商品购买、收藏、内容评论或分享),并对这些喜好进行度量和打分。根据不同用户对相同商品或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户之间进行商品推荐。简单的说就是如果A, B两个用户都买了x, y, z三本书,并且给出了5星好评。那么A和B就属于同一类用户。可以将A看过的图书w也推荐给用户B。

2.实现步骤
- 计算用户之间的相似度
- 建立物品-用户倒排表
- 建立用户相似度矩阵
- 计算用户相似度
- 针对目标用户u,找到其最相似的k个用户,产生N个推荐
倒排法
因为很多用户其实完全没有共同喜好的,也就是分子会为0。这么多无意义的计算会给我们增加很大的开销,所以我们应该先做一个预处理,把有关联的用户筛选出来,只计算这些有关联的用户的兴趣相似度。倒排法有效的为我们解决了这个问题:
- 首先将用户–物品表转化为物品–用户表(倒排表)
- 根据倒排表画出相似度矩阵(比如倒排表第一行说明AB BC AC有关联,就在矩阵中置1,第二行说明AC有关联,又加1变为了2)
矩阵中为0的我们就不需要去计算它们的兴趣相似度了。
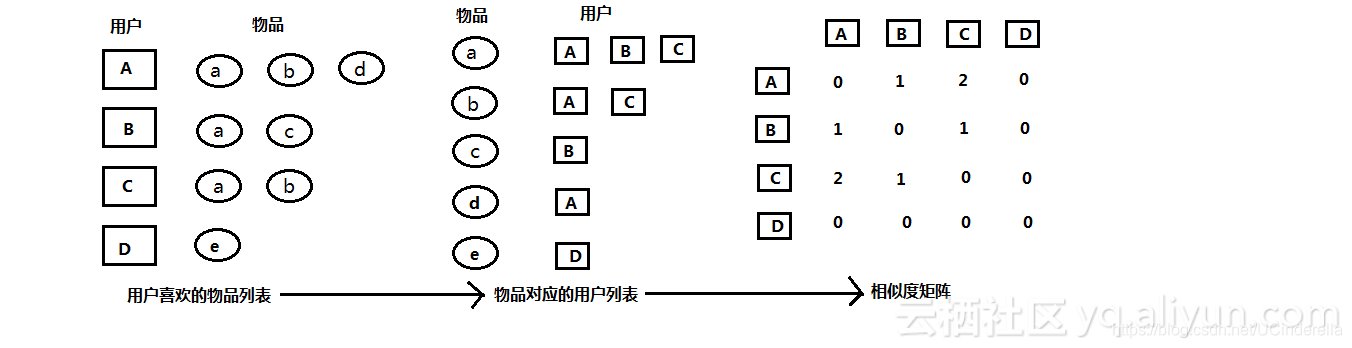
3.python代码
from operator import *
import math
#例子中的数据相当于是一个用户字典{A:(a,b,d),B:(a,c),C:(b,e),D:(c,d,e)}
#我们这样存储原始输入数据
dic={'A':('a','b','d'),'B':('a','c'),'C':('b','e'),'D':('c','d','e')}#简单粗暴,记得加''
#计算用户兴趣相似度
def Usersim(dicc):
#把用户-商品字典转成商品-用户字典(如图中箭头指示那样)
item_user=dict()
for u,items in dicc.items():
for i in items:#文中的例子是不带评分的,所以用的是元组而不是嵌套字典。
if i not in item_user.keys():
item_user[i]=set()#i键所对应的值是一个集合(不重复)。
item_user[i].add(u)#向集合中添加用户。
C=dict()#感觉用数组更好一些,真实数据集是数字编号,但这里是字符,这边还用字典。
N=dict()
for item,users in item_user.items():
for u in users:
if u not in N.keys():
N[u]=0 #书中没有这一步,但是字典没有初始值不可以直接相加吧
N[u]+=1 #每个商品下用户出现一次就加一次,就是计算每个用户一共购买的商品个数。
#但是这个值也可以从最开始的用户表中获得。
#比如: for u in dic.keys():
# N[u]=len(dic[u])
for v in users:
if u==v:
continue
if (u,v) not in C.keys():#同上,没有初始值不能+=
C[u,v]=0
C[u,v]+=1 #这里我不清楚书中是不是用的嵌套字典,感觉有点迷糊。所以我这样用的字典。
#到这里倒排阵就建立好了,下面是计算相似度。
W=dict()
for co_user,cuv in C.items():
W[co_user]=cuv / math.sqrt(N[co_user[0]]*N[co_user[1]])
return W
def Recommend(user,dicc,W2,K):
rvi=1 #这里都是1,实际中可能每个用户就不一样了。就像每个人都喜欢beautiful girl,但有的喜欢可爱的多一些,有的喜欢御姐多一些。
rank=dict()
related_user=[]
interacted_items=dicc[user]
for co_user,item in W2.items():
if co_user[0]==user:
related_user.append((co_user[1],item))#先建立一个和待推荐用户兴趣相关的所有的用户列表。
for v,wuv in sorted(related_user,key=itemgetter(1),reverse=True)[0:K]:
#找到K个相关用户以及对应兴趣相似度,按兴趣相似度从大到小排列。itemgetter要导包。
for i in dicc[v]:
if i in interacted_items:
continue #书中少了continue这一步吧?
if i not in rank.keys():#如果不写要报错,是不是有更好的方法?
rank[i]=0
rank[i]+=wuv*rvi
return rank
if __name__=='__main__':
W3=Usersim(dic)
Last_Rank=Recommend('A',dic,W3,2)
print(Last_Rank)
基于商品的协同过滤 (item-based CF)
1.原理
基于物品的协同过滤算法与基于用户的协同过滤算法很像,将商品和用户互换。通过计算不同用户对不同物品的评分获得物品间的关系。基于物品间的关系对用户进行相似物品的推荐。这里的评分代表用户对商品的态度和偏好。简单来说就是如果用户A同时购买了商品1和商品2,那么说明商品1和商品2的相关度较高。当用户B也购买了商品1时,可以推断他也有购买商品2的需求。

2.实现步骤
- 计算物品之间的相似度
- 遍历训练数据,统计喜欢每个物品的用户数
- 建立物品相似度矩阵
- 得到矩阵后,利用公式计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户推荐
-
K表示找到相似的物品数。N表示为用户推荐的物品数 。
-
利用公式计算用户u对物品 j 的感兴趣程度p(u, j)
-
然后根据感兴趣程度由高到低确定N个推荐给用户u的物品。
3.python代码
from math import sqrt
import operator
import numpy as np
#1.构建用户-->物品倒排
def LoadData(basis_data):
data = {}
for line in basis_data:
user,score,item = line.split(",")
data.setdefault(user,{})
data[user][item] = score
print("物品倒排:\n",data)
return data
#2.构建物品与物品的共(同)现矩阵
def similarity(one_data):
#构造物品的共现矩阵
N = {} #喜欢物品i的总人数
C = {} #喜欢物品i也喜欢物品j的人数
for user,item in one_data.items():
for i,score in item.items():
N.setdefault(i,0)
N[i] += 1
C.setdefault(i,{})
for j,scores in item.items():
if j not in i:
C[i].setdefault(j,0)
C[i][j] += 1
print("构造的共现矩阵为:\n{}\n{}".format(N,C))
#计算物品与物品的相似矩阵
W = {}
for i,item in C.items():
W.setdefault(i,{})
for j,item2 in item.items():
W[i].setdefault(j,0)
W[i][j] = C[i][j]/sqrt(N[i]*N[j])
print("构造的相似矩阵为:\n",W)
return W
#3.根据用户的历史记录,给用户推荐物品
def recommandList(data,W,user,k,N):
rank={};
for i,score in data[user].items():#获得用户user历史记录,如A用户的历史记录为{'a': '1', 'b': '1', 'd': '1'}
for j,w in sorted(W[i].items(),key=operator.itemgetter(1),reverse=True)[0:k]:#获得与物品i相似的k个物品
if j not in data[user].keys():#该相似的物品不在用户user的记录里
rank.setdefault(j,0)
rank[j]+=float(score) * w
sort_data = sorted(rank.items(),key=operator.itemgetter(1),reverse=True)[0:N]
print("推荐为:\n",sort_data)
return sort_data
#主函数
if __name__=='__main__':
#A死侍 B钢铁侠 C美国队长 D黑豹 E蜘蛛侠
#1代表喜欢
user_item_data = ['A,1,a', 'A,1,b', 'A,1,d', 'B,1,b', 'B,1,c', 'B,1,e', 'C,1,c', 'C,1,d', 'D,1,b', 'D,1,c', 'D,1,d','E,1,a', 'E,1,d']
data = LoadData(user_item_data)
W = similarity(data)
#为用户A推荐2部电影
recommandList(data,W,"A",3,2)
基于模型的协同过滤 (model based CF)
原理
-
基于模型的协同过滤作为目前最主流的协同过滤类型,其相关算法可以写一本书了,这里主要是对其思想做有一个归类概括。问题是这样的,m个物品,m个用户的数据,只有部分用户和部分数据之间是有评分数据的,其它部分评分是空白,此时我们要用已有的部分稀疏数据来预测那些空白的物品和数据之间的评分关系,找到最高评分的物品推荐给用户。
-
对于这个问题,用机器学习的思想来建模解决,主流的方法可以分为:用关联算法,聚类算法,分类算法,回归算法,矩阵分解,神经网络,图模型以及隐语义模型来解决。














 3429
3429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









