







K-means
聚类
无监督学习:
训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础
聚类分析
是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。聚类旨在发现有用的对象簇(cluster)。
K-means应用的则为基于原型的簇。

基于原型的
簇是对象的集合,其中每个对象到定义该簇的原型的距离比其他簇的原型距离更近,如(b)所示的原型即为中心点,在一个簇中的数据到其中心点比到另一个簇的中心点更近。这是一种常见的基于中心的簇,最常用的K-Means就是这样的一种簇类型。这样的簇趋向于球形。

K-means算法原理
kmeans算法又名k均值算法。其算法思想大致为:
先从样本集中随机选取 k 个样本作为簇中心,并计算所有样本与这 k 个“簇中心”的距离,对于每一个样本,将其划分到与其距离最近的“簇中心”所在的簇中,对于新的簇计算各个簇的新的“簇中心”。
根据以上描述,我们大致可以猜测到实现kmeans算法的主要三点:
(1)簇个数 k 的选择
(2)各个样本点到“簇中心”的距离
(3)根据新划分的簇,更新“簇中心”
选择K个点作为初始质心 repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心 until 簇不发生变化或达到最大迭代次数
算法要点
-
k 值的选择
k 的选择一般是按照实际需求进行决定,或在实现算法时直接给定 k 值。 -
距离的度量
(1)有序属性距离度量(离散属性 {1,2,3} 或连续属性):

(2)无序属性距离度量(比如{飞机,火车,轮船}):
VDM(Value Difference Metric):
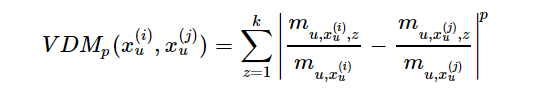
(3)混合属性距离度量,即为有序与无序的结合:

数据集为连续属性,因此代码中主要以欧式距离进行距离的度量计算。 -
更新“簇中心”
对于划分好的各个簇,计算各个簇中的样本点均值,将其均值作为新的簇中心。

算法实现(python)
伪代码
输入:训练数据集 D=x(1),x(2),…,x(m) ,聚类簇数 k ;
过程:函数 kMeans(D,k,maxIter) .
1:从 D 中随机选择 k 个样本作为初始“簇中心”向量: μ(1),μ(2),…,μ(k) :
2:repeat
3: 令 Ci=∅(1≤i≤k)
4: for j=1,2,…,m do
5: 计算样本 x(j) 与各“簇中心”向量 μ(i)(1≤i≤k) 的欧式距离
6: 根据距离最近的“簇中心”向量确定 x(j) 的簇标记: λj=argmini∈{1,2,…,k}dji
7: 将样本 x(j) 划入相应的簇: Cλj=Cλj⋃{x(j)} ;
8: end for
9: for i=1,2,…,k do
10: 计算新“簇中心”向量: (μ(i))′=1|Ci|∑x∈Cix ;
11: if (μ(i))′=μ(i) then
12: 将当前“簇中心”向量 μ(i) 更新为 (μ(i))′
13: else
14: 保持当前均值向量不变
15: end if
16: end for
17: else
18:until 当前“簇中心”向量均未更新
输出:簇划分 C=C1,C2,…,CK
(借鉴)
import numpy as np
import matplotlib.pyplot as plt
# 两点距离
def distance(e1, e2):
return np.sqrt((e1[0]-e2[0])**2+(e1[1]-e2[1])**2)
# 集合中心
def means(arr):
return np.array([np.mean([e[0] for e in arr]), np.mean([e[1] for e in arr])])
# arr中距离a最远的元素,用于初始化聚类中心
def farthest(k_arr, arr):
f = [0, 0]
max_d = 0
for e in arr:
d = 0
for i in range(k_arr.__len__()):
d = d + np.sqrt(distance(k_arr[i], e))
if d > max_d:
max_d = d
f = e
return f
# arr中距离a最近的元素,用于聚类
def closest(a, arr):
c = arr[1]
min_d = distance(a, arr[1])
arr = arr[1:]
for e in arr:
d = distance(a, e)
if d < min_d:
min_d = d
c = e
return c
if __name__=="__main__":
## 生成二维随机坐标(如果有数据集就更好)
arr = np.random.randint(100, size=(100, 1, 2))[:, 0, :]
## 初始化聚类中心和聚类容器
m = 5
r = np.random.randint(arr.__len__() - 1)
k_arr = np.array([arr[r]])
cla_arr = [[]]
for i in range(m-1):
k = farthest(k_arr, arr)
k_arr = np.concatenate([k_arr, np.array([k])])
cla_arr.append([])
## 迭代聚类
n = 20
cla_temp = cla_arr
for i in range(n): # 迭代n次
for e in arr: # 把集合里每一个元素聚到最近的类
ki = 0 # 假定距离第一个中心最近
min_d = distance(e, k_arr[ki])
for j in range(1, k_arr.__len__()):
if distance(e, k_arr[j]) < min_d: # 找到更近的聚类中心
min_d = distance(e, k_arr[j])
ki = j
cla_temp[ki].append(e)
# 迭代更新聚类中心
for k in range(k_arr.__len__()):
if n - 1 == i:
break
k_arr[k] = means(cla_temp[k])
cla_temp[k] = []
## 可视化展示
col = ['HotPink', 'Aqua', 'Chartreuse', 'yellow', 'LightSalmon']
for i in range(m):
plt.scatter(k_arr[i][0], k_arr[i][1], linewidth=10, color=col[i])
plt.scatter([e[0] for e in cla_temp[i]], [e[1] for e in cla_temp[i]], color=col[i])
plt.show()
结果:
















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









