







实验题目描述

总结一下Huffman编码的过程,可以参考wiki百科的下图:先统计词的词频作为权重
实验分析:
Huffman编码解码的过程比较固定:
- 统计文章的字符频率作为权重;
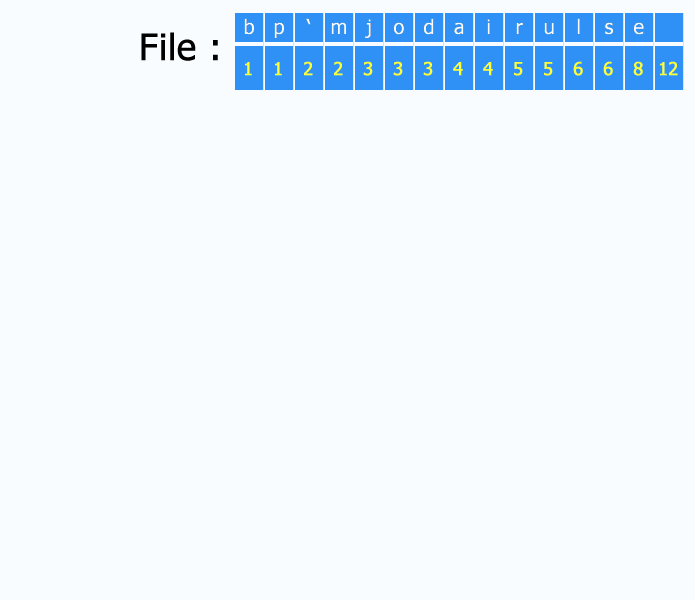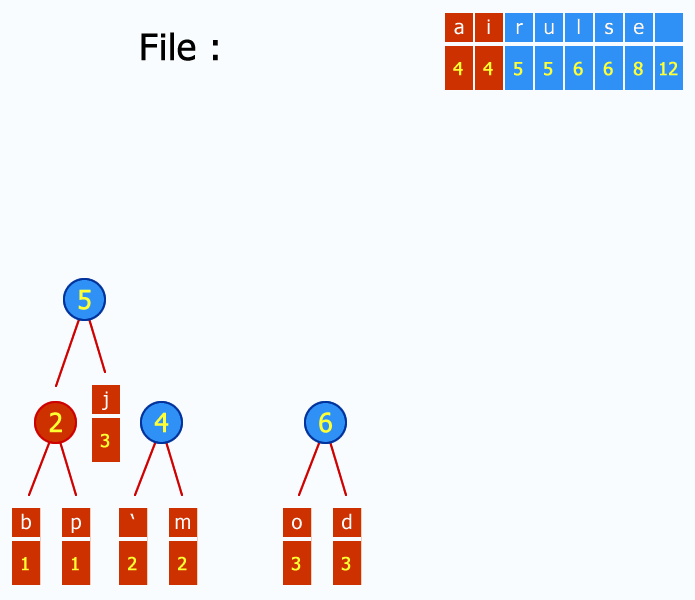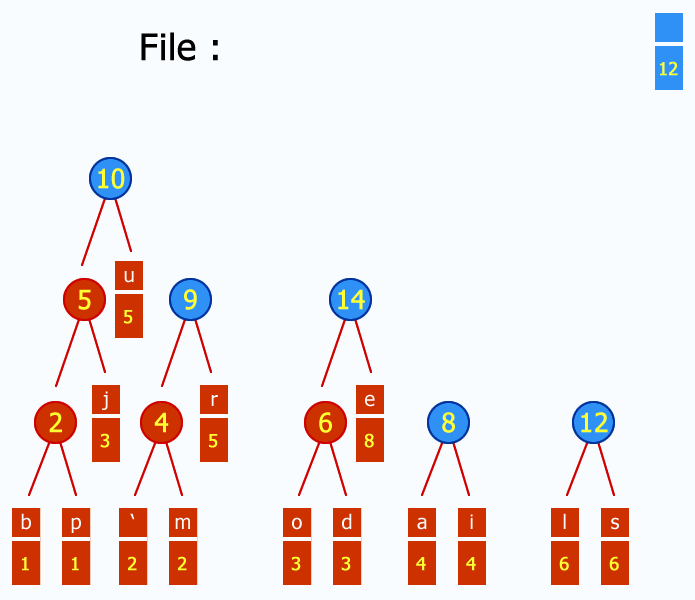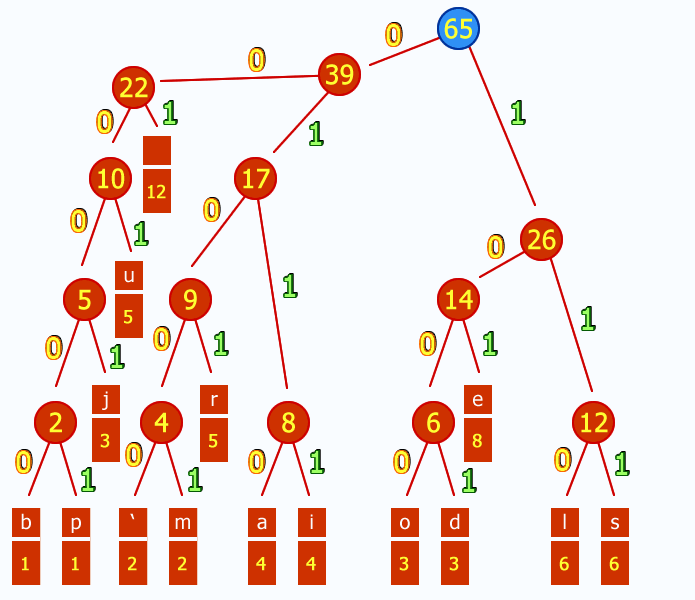
- 按照上述规则创建Huffman树,将字符放在各个叶子结点的位置;
- 对各个叶子结点进行编码获取每个字符的Huffman编码,左0右1;
- 根据Huffman编码依次解码获得叶子结点时,返回字符,依次完成解码过程;
- 计算压缩比,按照最基本的一个字符2个字节(中文字)即16位计算,再根据生成的Huffman编码进行计算压缩比是多少(未给出)
注意:中文字符用char满足不了要求,转换成宽字符wchar和wstring
实验代码:
使用方法:将文本文件和代码放在同一目录下直接输入文件名,或者使用绝对路径访问,按q退出程序
两个文件 Exp4_Huffman.h以及Exp4_Huffman.cpp
"Exp4_Huffman.h"
#include<stdio.h>
#include<Windows.h>
#include<iostream>
#include<stack>
#include<map>
#include <iomanip>
#include<fstream>
#include<iterator>
#include<string>
#include "atlbase.h"
#include "atlstr.h"
#include <comutil.h>
#pragma comment(lib, "comsuppw.lib")
using namespace std;
typedef struct {
wchar_t value;
char *code;
int weight;
int lchild, rchild, parent;
}HTNode,*HuffTree;
typedef struct {
int size = 0;
wchar_t element[10000];
int counts[10000];
}MyMap;
void Print_HuffmanTree(HuffTree HT, int n);
void Select(HuffTree HT, int n, int i, int &s1, int &s2) {
//i为第i次合并
int latest = INT_MAX;
int later = INT_MAX;
s1 = 0;
s2 = 0;
for (int j = 1; j < i; j++) {
if (HT[j].parent == 0)
{
if (HT[j].weight <= latest)
{
int tmp_index = s1;
s1 = j;
s2 = tmp_index;
int tmp_weight = latest;
latest = HT[j].weight;
later = tmp_weight;
}
else if (HT[j].weight <= later) {
s2 = j;
later = HT[j].weight;
}
}
}
//cout << "s1:" << s1 << " s2:" << s2 << endl;
return;
}
void HuffmanTree(HuffTree &HT, int *w, int n, wchar_t *element ) { //创建Huffman树
int m = 2 * n - 1;
HT = new HTNode[m + 1];
char *s = new char;
*s = '\0';
for (int i = 1; i <= m; i++) {
HT[i].weight = i <= n ? w[i] : 0;
HT[i].lchild = HT[i].rchild = HT[i].parent = 0;
HT[i].value = i <= n ? element[i] : L'$';
HT[i].code = s;
}
Print_HuffmanTree(HT,n);
for (int i = n + 1; i <= m; i++) {
int s1 = 0, s2 = 0;
Select(HT, n, i, s1, s2);
HT[i].lchild = s1;
HT[i].rchild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
HT[s1].parent = HT[s2].parent = i;
}
}
void Coding(HuffTree HT, int root, char **HC, stack<char>&S) { //Huffman编码
if (root != 0) {
if (HT[root].lchild == 0) {
stack<char>s;
S.push('\0');
int size = 0;
HC[root] = (char*)malloc(S.size());
//cout << "root:" << root << endl;
size = S.size();
//cout << "size:" << S.size() << endl;
for (int i = 0; i < size; i++)
{
s.push(S.top());
//cout << s.top()<<endl;
S.pop();
}
for (int i = 0; i < size; i++)
{
HC[root][i] = s.top();
S.push(s.top());
s.pop();
}
HT[root].code = HC[root];
S.pop();
}
S.push('0');
Coding(HT, HT[root].lchild, HC, S);
S.pop();
S.push('1');
Coding(HT, HT[root].rchild, HC, S);
S.pop();
}
}
void HuffmanCoding(HuffTree HT, char ** &HC, int n) {
stack<char>S;
HC = (char **)malloc(sizeof(char*)*(n + 1));
Coding(HT, 2 * n - 1, HC, S);
}
void Print_HuffmanTree(HuffTree HT,int n) {
cout << "\n*********************************HuffmanTree info************************************" << endl;
wcout.imbue(std::locale("chs"));
for (int i = 1; i <= n; i++) {
cout << "Num:" << setw(3) << i << " weight:" << setw(4) << HT[i].weight << " parent:" << setw(3) << HT[i].parent << " lchild:" << setw(3) << HT[i].lchild << " rchild:" << setw(3) << HT[i].rchild << " value:";
wcout <<setw(3)<< HT[i].value;
cout<< " Code:" << HT[i].code << endl;
}
}
void Print_HC(wchar_t **HC, int n) {
printf("****************************************HC********************************************\n");
for (int i = 1; i <= n; i++) {
cout << HC[i] << endl;
}
}
int Translate(HuffTree HT, char *Code, wchar_t *Text, int root) { //Huffman解码过程
int cur = root;
int char_num = 0;
while (*Code != '\0') {
if (cur == 0)
{
cout << "Code Error!" << endl;
return -1;
}
if (HT[cur].lchild == 0)
{
*Text = HT[cur].value;
Text++;
char_num++;
cur = root;
}
else {
if (*Code == '0')
cur = HT[cur].lchild;
else
cur = HT[cur].rchild;
Code++;
}
}
if (HT[cur].lchild == 0)
{
*Text = HT[cur].value;
Text++;
char_num++;
cur = root;
}
*Text = '\0';
return char_num;
}
wstring s2ws(const string& s) //string 转换为wstring适应中文字符
{
_bstr_t t = s.c_str();
wchar_t* pwchar = (wchar_t*)t;
wstring result = pwchar;
return result;
}"Exp4_Huffman.cpp"
#include"Exp4_Huffman.h"
int main() {
while (1) {
ifstream in;
cout << "\n*****************************Exp4 HuffmanTree****************************************" << endl;
while (1) {
cout << "Please Input The File Name(Exit:q):";
char input_file_name[100];
cin >> input_file_name;
if (*input_file_name == 'q')
return -1;
//cout << input_file_name << endl;
in.open(input_file_name);
if (!in)
cout << "Error:Open file failed!" << endl;
else
break;
}
istreambuf_iterator<char> begin(in);
istreambuf_iterator<char> end;
string some_str(begin, end);
//cout << some_str << endl;
wstring test4 = s2ws(some_str);//一般不用加第二个参数
//string s = " s";
//cout << s << endl;
MyMap* Count = new MyMap;
cout << "length:" << test4.length() << endl;
Count->size = 0;
for (int i = 0; i < test4.length(); i++) {
bool flag = true;
for (int j = 1; j <= Count->size; j++) {
if (test4[i] == Count->element[j])
{
Count->counts[j]++;
flag = false;
}
}
if (flag)
{
Count->size++;
Count->element[Count->size] = test4[i];
Count->counts[Count->size] = 1;
}
}
cout << "Classes Num of Char:" << Count->size <<endl;
int *w = new int[Count->size + 1];
for (int i = 1; i <= Count->size; i++)
w[i] = Count->counts[i];
HuffTree HT;
char **HC;
HuffmanTree(HT, w, Count->size, Count->element);
Print_HuffmanTree(HT, Count->size);
HuffmanCoding(HT, HC, Count->size);
Print_HuffmanTree(HT, Count->size);
//Print_HC(HC, Count->size);
cout << "\n**********************************Decoding******************************************" << endl;
//wchar_t *code[] = "11010110111011101";
while (1) {
char *code = new char[10000];
cout << "Please Input The Code(Such As 0001111,Exit:q):";
scanf("%s", code);
if (*code == 'q')
break;
for (int i = 0; code[i] != '\0'; i++) {
if (code[i] != '0'&&code[i] != '1'&&code[i] != '\0')
cout << "Input Error!" << endl;
}
//cout << "code:" << code << endl;
wchar_t *Text = new wchar_t;
int char_num = Translate(HT, code, Text, 2 * Count->size - 1);
wcout << "After Decoding Is :" << Text << endl;
}
}
}实验结果:


















 2659
2659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











