









作者:来自 Elastic Ishleen Kaur 及 Daniela Tzvetkova

这篇博客探讨了四个特定行业的用例,展示了如何使用大型语言模型(Large Language Models - LLMs ),并重点介绍了 Elastic 的 LLM 可观测性集成如何提供有关成本、性能、可靠性,以及与 LLM 的提示与响应交互的深入洞察。
在当今以技术为中心的世界里,大型语言模型(LLMs)正改变着从金融、医疗到科研等多个行业。LLM 正逐步成为各种产品和服务的核心。例如,Google 最新的 Gemini 2.5 利用其推理能力,通过简单的提示生成可执行代码,完成视频游戏的创建。又如 Amazon Alexa 的新交互方式 —— 用户可以发送一张现场音乐活动日程的图片,Alexa 就能将详细信息添加到日历中。而 Microsoft 的 Copilot 个性化功能同样值得一提,它会记住你聊过的内容,从而了解你的喜好、不喜欢的事,以及你生活中的细节,比如你狗的名字、那个棘手的工作项目,或是什么激励你坚持锻炼。
尽管 LLM 的用途广泛,但在现实场景中部署这些复杂工具仍面临许多挑战,尤其是在管理其复杂行为方面。对于网站可靠性工程师(SRE)、DevOps 团队和 AI/ML 工程师来说,确保这些模型的可靠性、性能和合规性会带来额外的复杂性。这正是 LLM 可观测性概念变得至关重要的地方。它为模型性能提供关键洞察,确保这些先进的 AI 系统高效且符合道德地运行。
LLM 可观测性为何重要,以及 Elastic 如何简化这一过程
LLMs 并不是普通的软件,而是具备人类语言能力的复杂系统,比如文本生成、理解,甚至编程。但能力越强,对监管的需求也越高。模型的 “黑箱” 特性可能掩盖其决策和内容生成的方式。因此,必须实施强大的可观测性机制,以监控和排查诸如幻觉、不当内容、成本超支、错误和性能下降等问题。通过对模型的密切监控,我们可以防止意外结果,维护用户信任。
真实世界的场景
下面让我们看看企业如何在实际中利用 LLM 驱动的应用来提升生产力和用户体验,以及 Elastic 的 LLM 可观测性解决方案如何帮助监控这些模型的关键方面。
1. 面向客户支持的生成式 AI
企业越来越多地利用大型语言模型(LLMs)和生成式 AI 来提升客户支持效率,使用如 Google Vertex AI 这样的平台高效托管这些模型。随着 Google 的 Gemini 等先进 AI 模型集成到 Vertex AI,企业可以部署复杂的聊天机器人,实时处理从简单问题到复杂问题的客户咨询。这些 AI 系统能够理解并以自然语言回应,立即支持产品故障排查或订单管理等问题,从而缩短等待时间。同时,它们通过每次互动持续学习,不断提升准确性。这不仅提升了客户满意度,还让人工客服能专注于复杂任务,提高整体效率。AI 工具还可以通过实时分析、情感检测和对话摘要等功能,进一步赋能客户服务人员。
为支持上述 AI 驱动的客户支持用例,Elastic 最近推出了 LLM 可观测性集成,支持托管在 GCP Vertex AI 上的 LLM。希望监控 Google Vertex AI 上托管的 Gemini 和 Imagen 等基础模型的客户,可以通过 Elastic 的 Vertex AI 集成深入了解模型行为和性能,确保 AI 工具不仅有效而且可靠。客户可直接使用预先收集的 Vertex AI 指标以及预配置的仪表盘。
通过持续跟踪这些指标,客户能主动管理 AI 资源,优化运营,最终提升整体客户体验。
下面是 Google Vertex AI 集成提供的一些关键指标,对于使用生成式 AI 支持客户服务非常有帮助:
-
预测延迟(Prediction Latency):衡量完成预测所需时间,对实时客户交互至关重要。
-
错误率(Error Rate):跟踪预测中的错误,保证 AI 驱动客户支持的准确性和可靠性。
-
预测次数(Prediction Count):统计预测次数,有助于评估 AI 在客户交互中的使用规模。
-
模型使用率(Model Usage):监控虚拟助手和客户支持工具访问 AI 模型的频率。
-
总调用次数(Total Invocations):衡量 AI 服务的总使用次数,洞察用户参与度和对工具的依赖。
-
CPU 和内存利用率(CPU and Memory Utilization):观察资源使用情况,优化资源分配,确保 AI 工具高效运行且不过载系统。
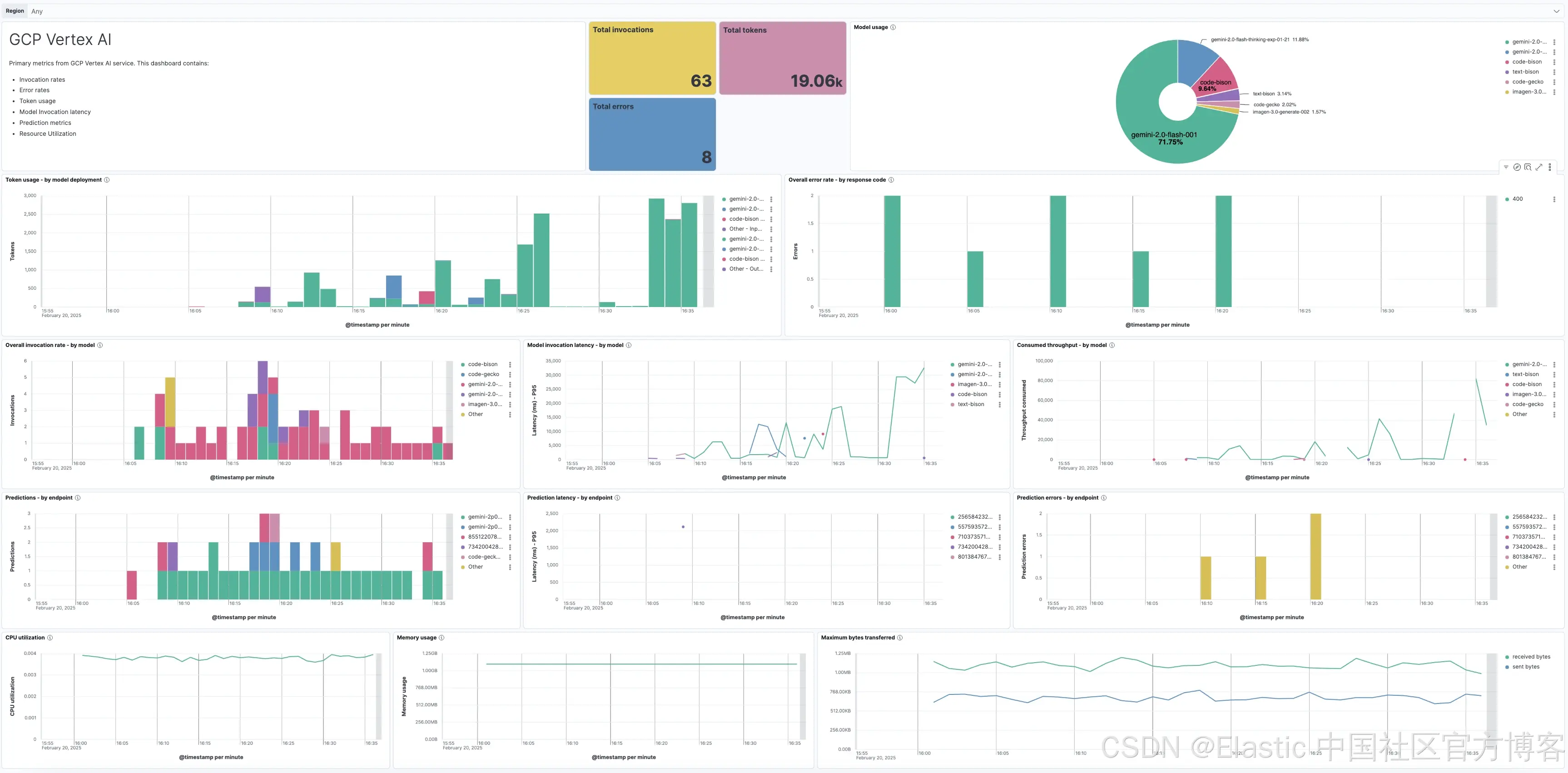
想了解更多 Elastic 的 Google Vertex AI 集成如何增强你的 LLM 可观测性,可以快速阅读这篇博客。
2. 用生成式 AI 改变医疗行业
医疗行业正在采用生成式 AI 来提升患者互动和简化运营流程。通过利用 Amazon Bedrock 等平台,医疗机构部署先进的大型语言模型(LLMs),驱动将医患对话转化为结构化医疗记录的工具,减少行政负担,让临床医生能更专注于诊断和治疗。这些 AI 驱动的解决方案提供实时洞察,支持明智决策,改善患者治疗效果。此外,面向患者的 LLM 应用还提供安全的健康记录访问,使个人能够主动管理自己的健康。
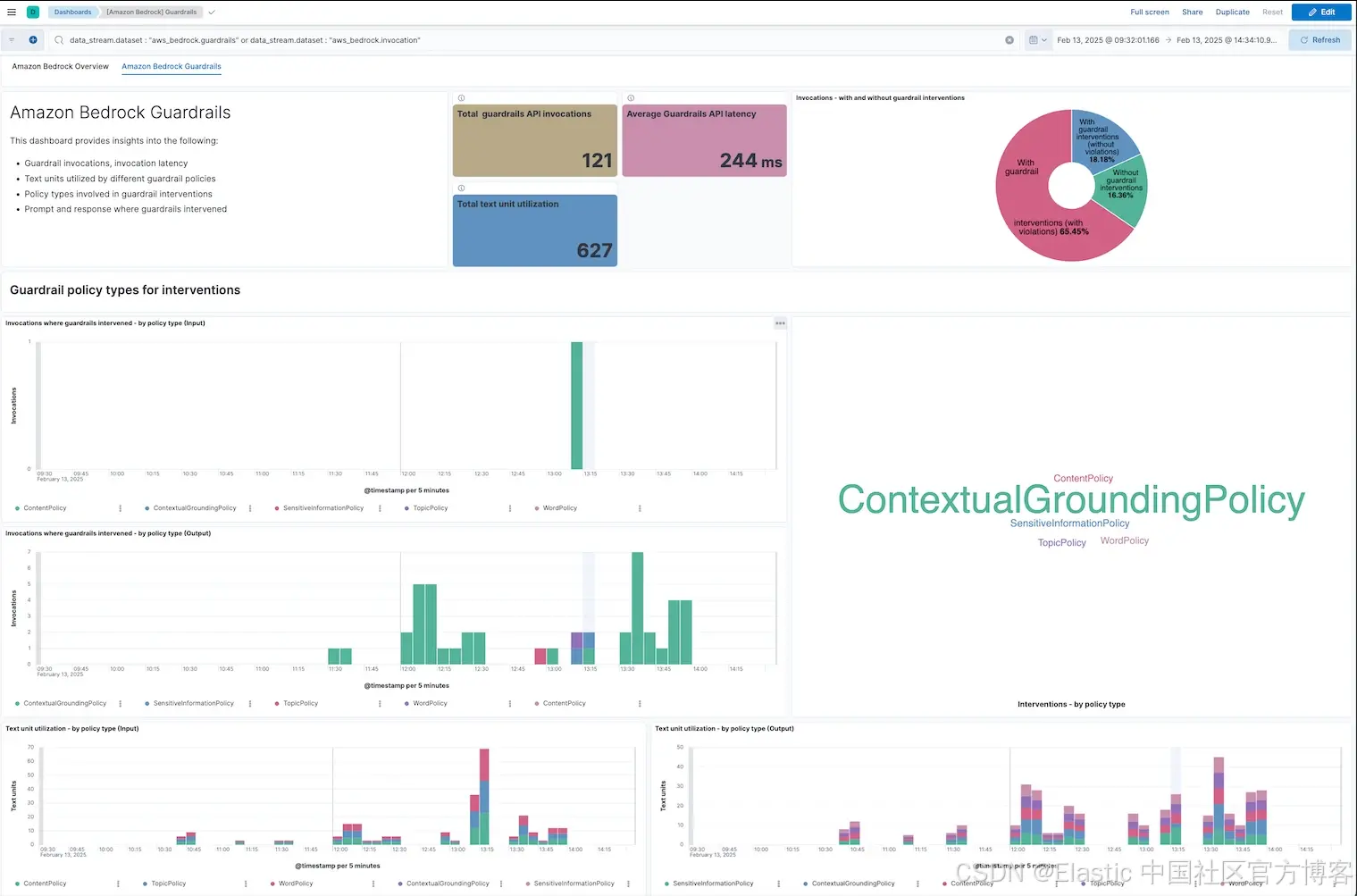
强大的可观测性对维护医疗领域生成式 AI 应用的可靠性和性能至关重要。Elastic 的 Amazon Bedrock 集成为提供者配备了监控 LLM 行为的工具,捕获关键指标如调用延迟、错误率、令牌使用和保护机制调用。预配置仪表盘能展示提示和生成文本,使团队能够核实 AI 生成输出(如医疗记录)的准确性,并检测幻觉等问题。
另外,配置了 Bedrock 保护机制(Guardrails)以过滤仇恨言论、人身攻击和其他不当内容的客户,可使用该集成监控导致保护机制触发的提示和响应,帮助开发者主动采取措施,维护安全和积极的用户体验。
使用托管在 Amazon Bedrock 上的 LLM 时,以下日志和指标对客户非常有用:
-
调用详情(Invocation Details):该集成记录调用延迟、次数和限流情况,确保生成式 AI 模型能快速准确响应患者查询或预约任务,保持流畅用户体验。
-
错误率(Error Rates):跟踪错误率确保 AI 工具(如患者查询助手或预约系统)始终提供准确可靠的结果。及时发现并解决问题,医疗机构能维护对 AI 系统的信任,防止关键患者交互中断。
-
Token 使用(Token Usage):在医疗中,跟踪令牌使用帮助识别资源密集型查询,如详细的患者记录摘要或复杂症状分析,确保模型高效运行。通过监控 token 使用,医疗机构能优化 AI 工具成本,同时保证扩展性,应对日益增长的患者交互。
-
提示和生成文本(Prompt and Completion Text):捕获提示和生成文本,帮助医疗机构分析 AI 模型如何响应具体患者查询或行政任务,确保交互有意义且符合上下文。此洞察有助于优化提示,提升 AI 理解力,确保生成的响应(如预约详情或治疗说明)达到医疗质量标准。
-
触发保护机制的提示和响应(Prompt and response where guardrails intervened):能够追踪被保护机制判定为不当的请求和响应,帮助医疗机构监控患者询问的信息内容。基于这些信息,用户可持续调整 LLM,平衡灵活且丰富的沟通,同时保障隐私保护、防止幻觉和过滤有害内容。
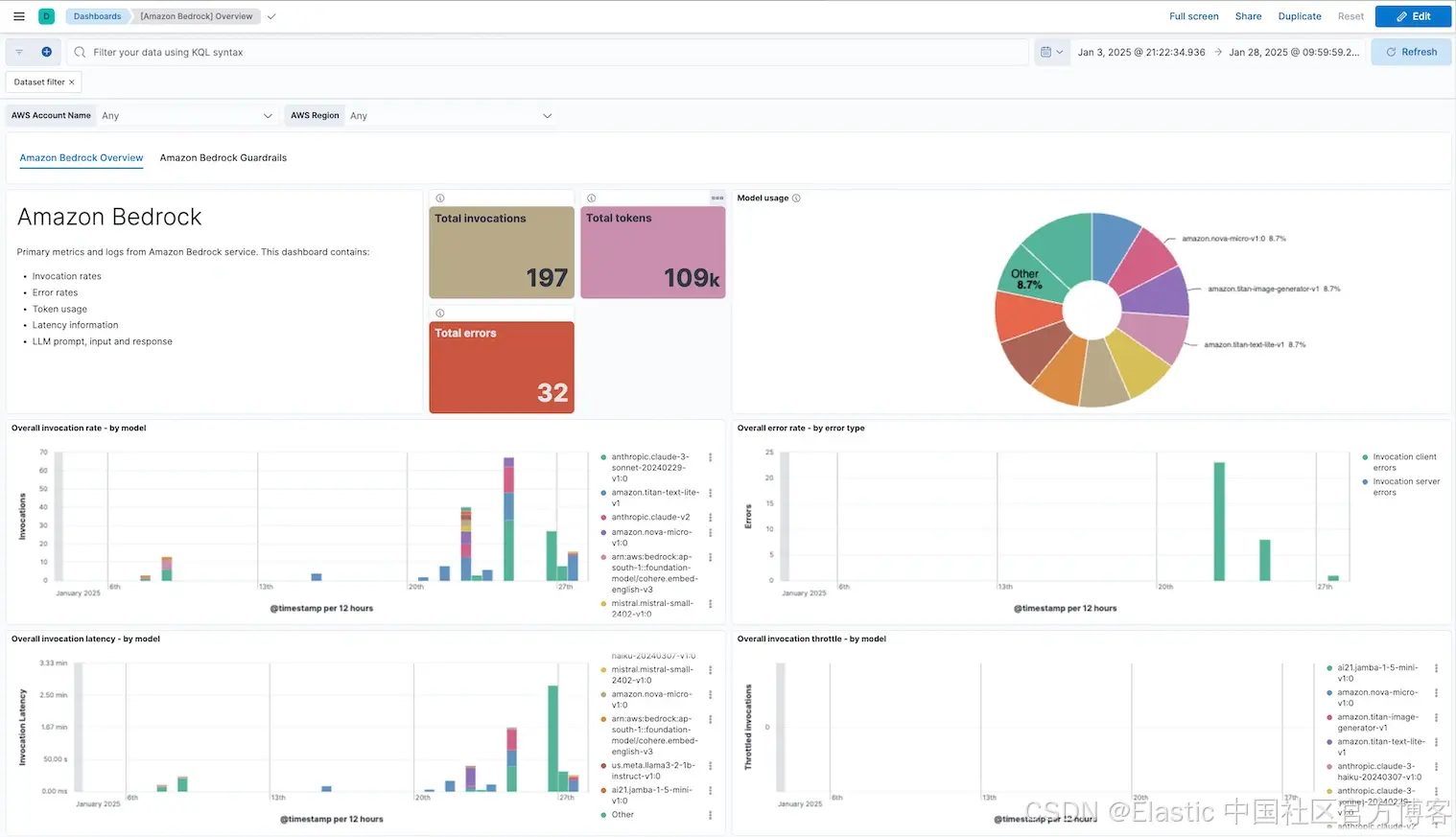
Amazon Bedrock Guardrails 开箱即用仪表盘:
想了解 Amazon Bedrock 集成,请阅读这篇博客。想深入了解该集成如何帮助实现对 Amazon Bedrock Guardrails 的可观测性,请查看这篇博客。
3. 利用 GenAI 提升电信效率
电信行业可以利用像 Azure OpenAI 这样的服务,改造客户互动、优化运营并提升服务质量。通过集成先进的生成式 AI 模型,电信公司能够在多个渠道提供高度个性化和响应迅速的客户体验。AI 驱动的虚拟助手通过自动化处理常规查询并提供准确且具上下文感知的回复,减轻了人工客服的工作负担,使他们能够专注处理复杂问题,同时提升效率和客户满意度。此外,AI 驱动的洞察帮助电信公司理解客户偏好,预测需求,提供定制化服务,从而增强客户忠诚度。在运营层面,像 Azure OpenAI 这样的 LLM 通过智能知识管理和更快访问关键信息,提升内部流程效率。
Elastic 的 LLM 可观测性集成,比如 Azure OpenAI 集成,可以让电信运营商了解 AI 性能和成本,助力数据驱动决策并提升客户参与度。它还能通过分析通话模式、预测服务需求和识别趋势,帮助电信公司高效扩展 AI 运营,同时保持高质量服务。
Azure OpenAI 可提供的一些关键指标和日志包括:
-
错误计数:提供失败请求和未完成事务的重要洞察,帮助电信运营商主动发现并解决 AI 应用中的问题。
-
提示输入和完成文本:捕获提供给 AI 系统的查询和对应的 AI 生成输出,便于分析客户问题、监控响应质量以及优化 AI 训练数据集。
-
响应延迟:衡量 AI 模型生成响应所需时间,确保虚拟助手和自动化系统对客户查询快速高效地作出回复。
-
Token 使用量:追踪 AI 模型处理的输入和输出 token 数量,帮助洞察资源消耗和成本效益,协助电信运营商监控 AI 使用模式、优化配置及有效扩展资源。
-
内容过滤结果:在 Azure OpenAI 中,这对处理客户提供的敏感输入至关重要,确保合规、安全和负责任的 AI 使用。该功能实时识别并标记潜在不当或有害的查询和回复,帮助电信运营商谨慎准确地应对敏感话题。
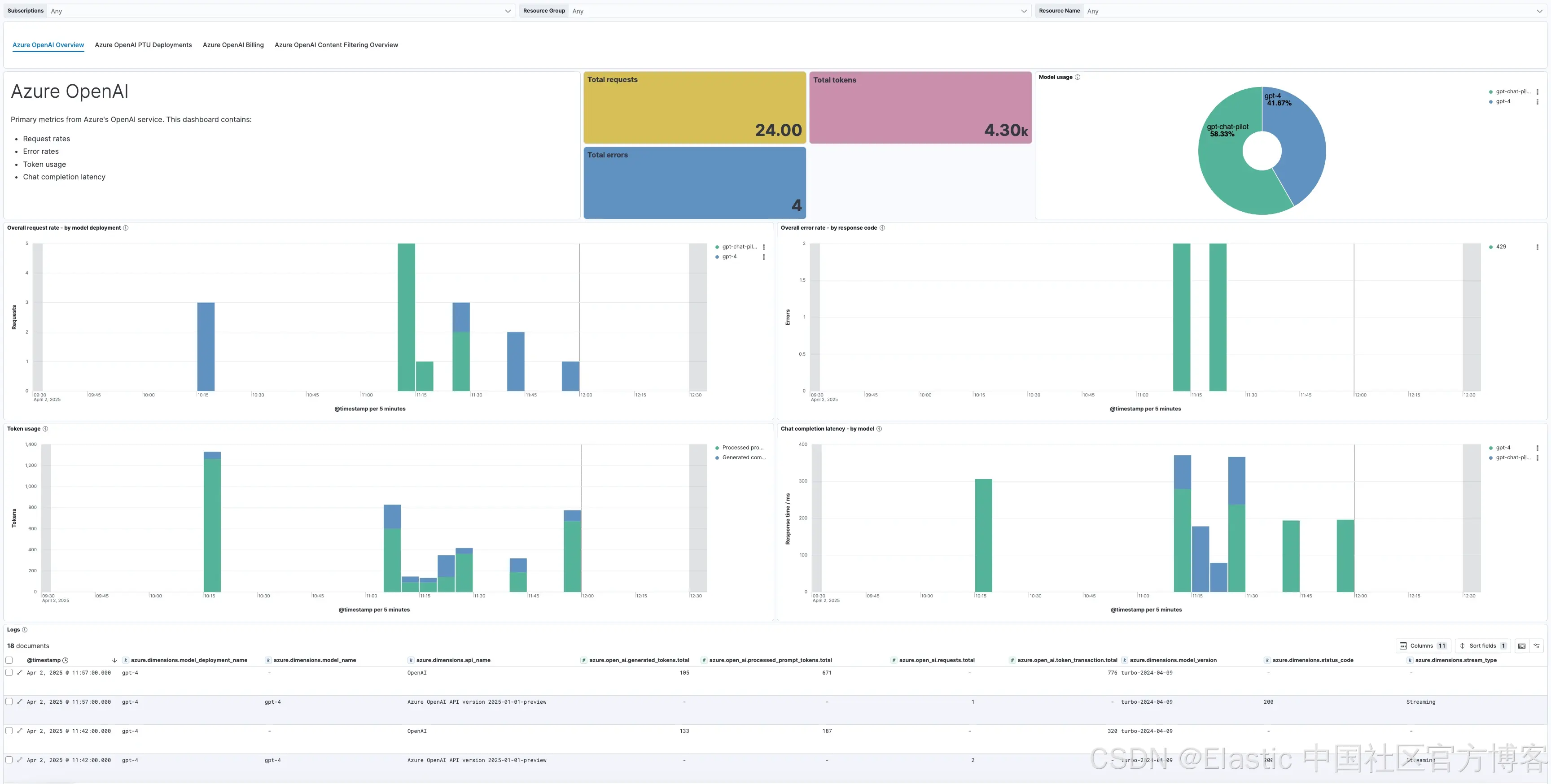
Azure OpenAI 内容过滤 开箱即用仪表盘:
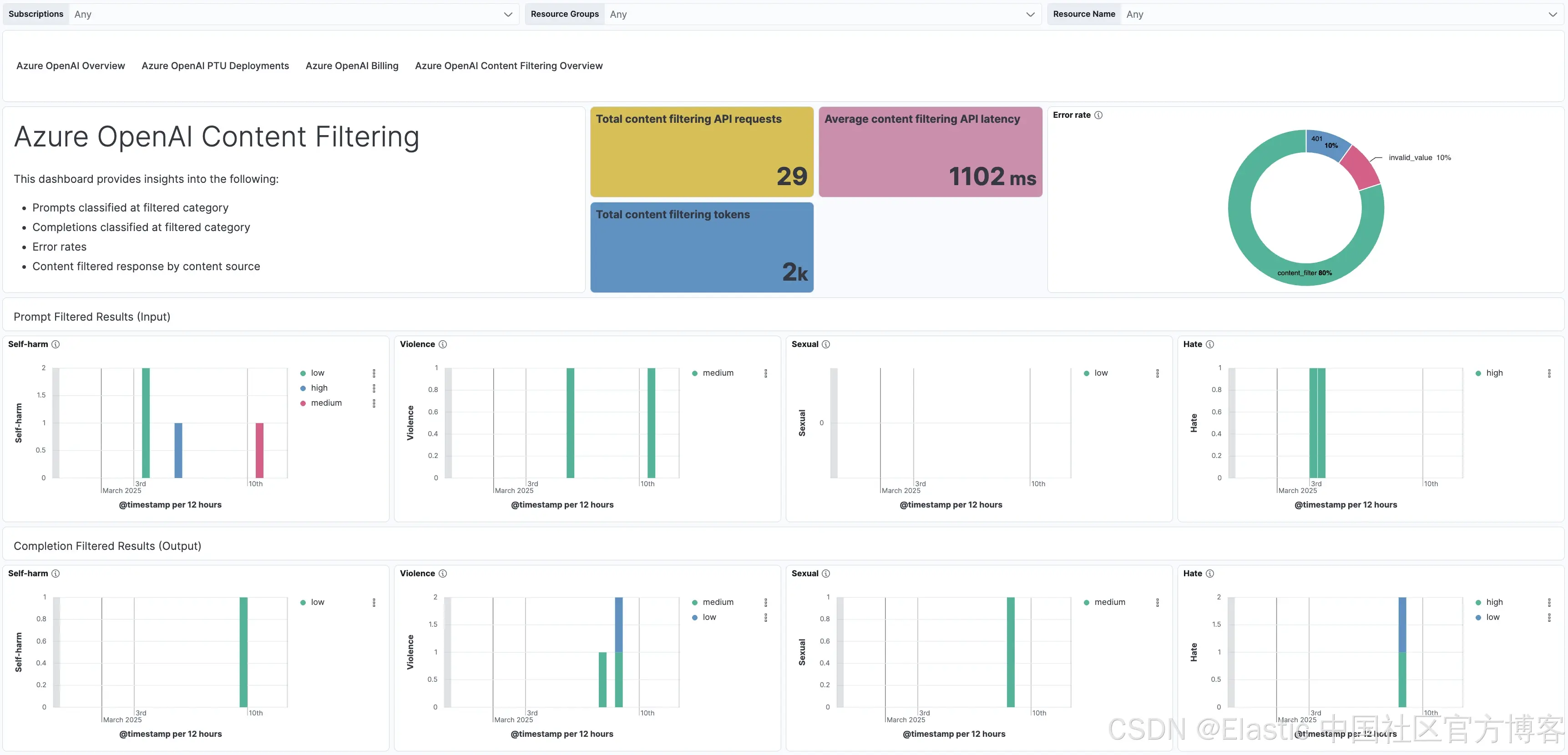
你可以通过这两篇博客了解更多关于 Elastic 的 Azure OpenAI 集成 —— 第 1 部分 和 第 2 部分。
4. 用于生成式 AI 应用的 OpenAI 集成
随着 AI 驱动的解决方案成为现代工作流程的重要组成部分,OpenAI 的先进模型(包括语言模型如 GPT-4o 和 GPT-3.5 Turbo、图像生成模型如 DALL·E、以及音频处理模型如 Whisper)推动虚拟助手、内容创作和语音转文本系统等应用的创新。随着复杂性和规模的增长,确保这些模型表现可靠、成本高效且符合道德规范至关重要。Elastic 的 OpenAI 集成提供了强大的解决方案,通过深入可视化模型行为,支持无缝且负责任的 AI 部署。
利用 OpenAI Usage API,Elastic 的集成通过直观的预配置仪表盘提供可操作的洞察,使站点可靠性工程师(SRE)和 DevOps 团队能够监控性能并优化 OpenAI 多样化模型组合的资源使用。这种统一的可观测性方法帮助组织追踪关键指标,识别低效,维护高质量的 AI 驱动体验。以下是 Elastic OpenAI 集成帮助实现有效监管的关键指标:
-
请求延迟(Request Latency):衡量 OpenAI 模型处理请求所需时间,确保实时应用如聊天机器人或转录服务的响应性能。
-
调用频率(Invocation Rates):跟踪模型间 API 调用频率,洞察使用模式,识别高需求工作负载。
-
Token 使用(Token Usage):监控输入和输出令牌(如提示、完成、缓存令牌),优化成本并微调提示以提高资源利用率。
-
错误计数(Error Counts):捕捉失败请求或未完成事务,帮助主动解决问题,保持应用可靠性。
-
图像生成指标(Image Generation Metrics):跟踪 DALL·E 等模型的调用率和输出尺寸,评估图像应用的成本和使用趋势。
-
音频转录指标(Audio Transcription Metrics):监控 Whisper 等音频模型的调用频率和转录秒数,支持语音转文本工作流的成本优化。
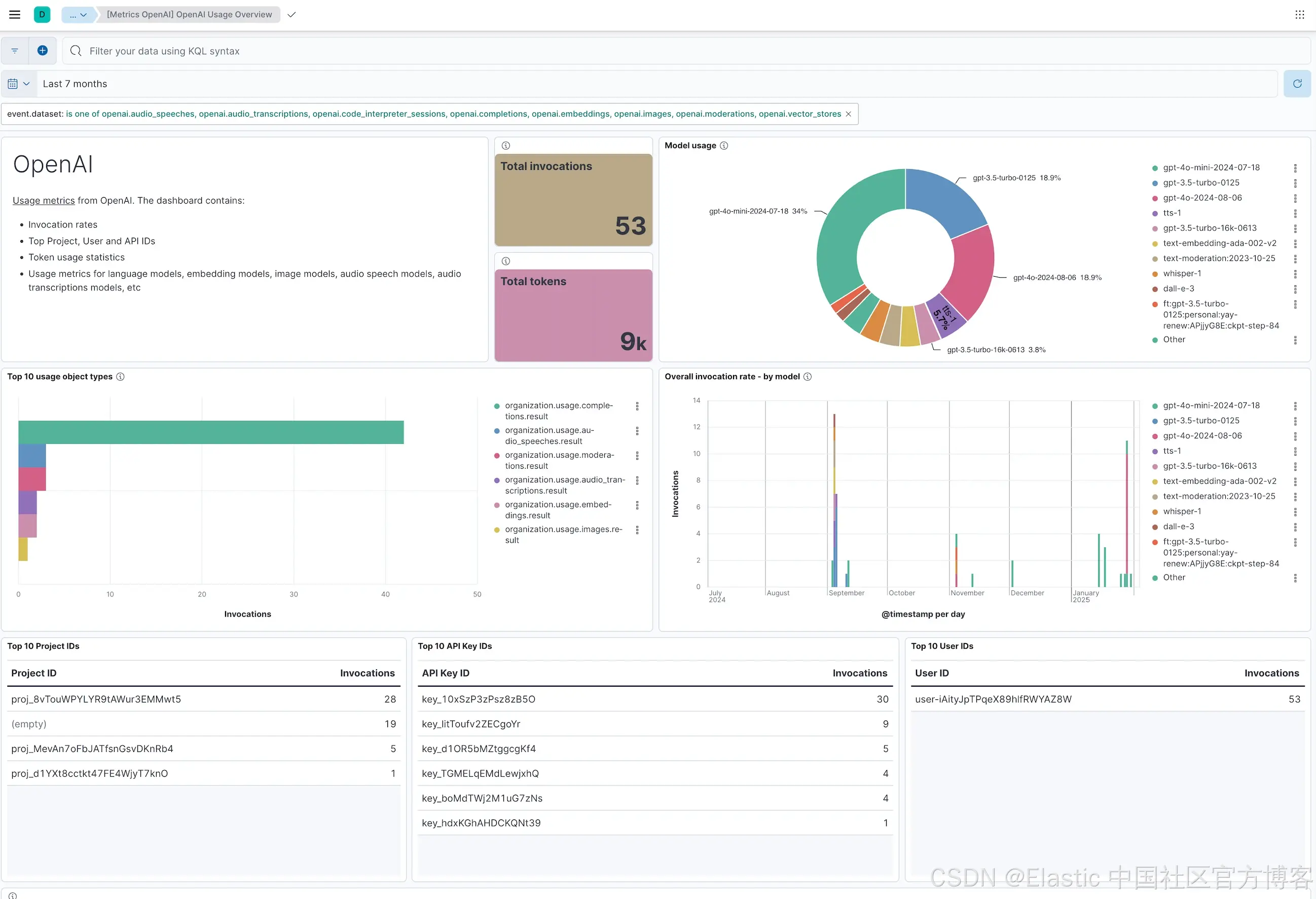
你可以通过这篇博客了解更多关于 Elastic 的 OpenAI 集成。
可操作的 LLM 可观测性
Elastic 的 LLM 可观测性集成让用户通过可操作的洞察和实时告警,主动掌控 AI 运营。例如,设置一个令牌数(token count)的预定义阈值,当使用量超过该限制时,Elastic 会自动触发告警,通过邮件、Slack 或其他首选渠道通知站点可靠性工程师(SRE)或 DevOps 团队。
这确保团队能及时发现潜在的成本超支或资源密集型查询,迅速调整模型配置或扩展资源,保持运营效率。
下面示例中,规则设置为当 token_count 超过 500 时提醒用户。
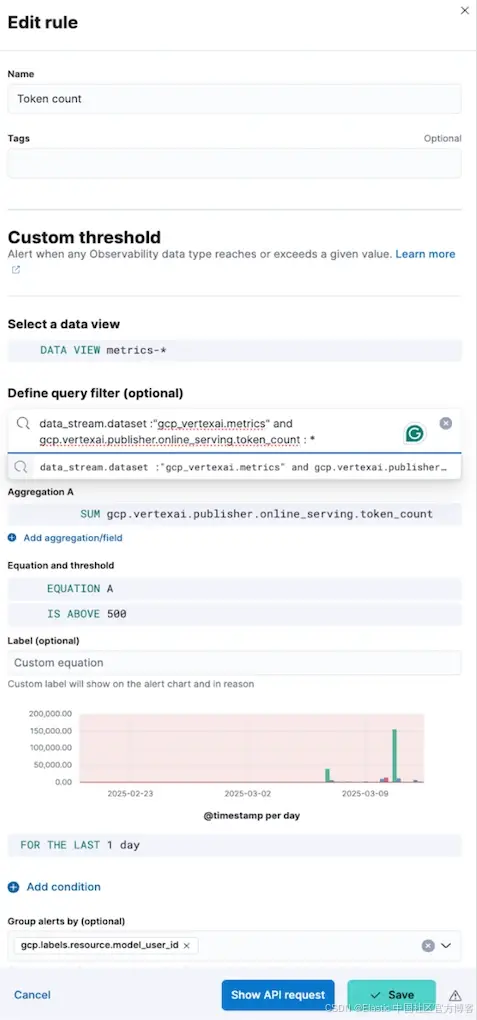
当 token 数超过阈值时,会触发告警,如下所示:

另一个例子是跟踪调用峰值,比如当预测次数或 API 调用数超过预定义的服务等级目标(Service Level Objective - SLO)时。例如,如果托管在 Bedrock AI 上的模型由于客户交互量激增而突然调用激增,Elastic 可以提醒团队调查潜在异常或相应扩展基础设施。这些主动措施有助于保持 LLM 驱动应用的可靠性和成本效益。
通过提供预配置的仪表板和可定制的告警,Elastic 确保组织能够实时响应关键事件,使其 AI 系统保持在成本、性能目标及内容安全和可靠性标准范围内。
总结
大型语言模型(LLM)正在改变各个行业,但其复杂性需要有效的可观测性来保证可靠性和安全使用。Elastic 的 LLM 可观测性集成提供了全面的解决方案,使企业能够监控性能、管理资源,并应对诸如幻觉和内容安全等挑战。随着 LLM 在各行业中变得日益重要,Elastic 提供的强大可观测性工具确保这些 AI 驱动的创新保持可靠、具成本效益,并符合伦理和安全标准。


















 1618
1618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









