









作者:来自 Elastic Panagiotis Bailis

Elasticsearch 拥有大量新功能,帮助你为你的使用场景构建最佳搜索解决方案。深入阅读我们的示例笔记本了解更多内容,开始免费云试用,或立即在本地机器上体验 Elastic。
在我们之前的博客文章中,我们介绍了全新设计的检索器框架,它支持构建复杂的排序管道。我们还探讨了 Reciprocal Rank Fusion ( RRF )检索器如何通过合并来自不同查询的结果实现混合搜索。虽然 RRF 易于实现,但它有一个显著的限制:它仅关注相对排名,忽略了实际得分。这使得微调和优化变得具有挑战性。
认识一下 linear retriever!
在这篇文章中,我们介绍了最新的混合搜索支持组件 —— linear retriever!与 rrf 不同,linear retriever 会对所有命中某个文档的查询计算加权和。这种方法既保留了每个文档在结果集中的相对重要性,又允许精确控制每个查询对最终得分的影响。因此,它为微调混合搜索提供了一种更直观、更灵活的方式。
定义一个 linear retriever,其最终得分将按如下方式计算:

就是这么简单:
GET linear_retriever_blog/_search
{
"retriever": {
"linear": {
"retrievers": [
{
"retriever": {
"knn": {
...
}
},
"weight": 5
},
{
"retriever": {
"standard": {
...
}
},
"weight": 1.5
},
]
}
}
}注意它有多简单直观吧?(而且和 rrf 非常相似!)这个配置允许你精确控制每种查询类型对最终排序的贡献,而 rrf 只依赖相对排名。
但仍然有一个注意事项:knn 的分数可能会被严格限制,这取决于所使用的相似度度量方式。例如,对于余弦相似度或单位归一化向量的点积,分数始终在 [0, 1] 范围内。相比之下, bm25 的分数则更不可预测,而且没有明确定义的边界。
分数缩放: kNN vs BM25
混合搜索的一个挑战在于,不同的检索器产生的分数位于不同的尺度上。比如,考虑下面这个场景:
查询 A 的分数:
| doc1 | doc2 | doc3 | doc4 | |
|---|---|---|---|---|
| knn | 0.347 | 0.35 | 0.348 | 0.346 |
| bm25 | 100 | 1.5 | 1 | 0.5 |
查询 B 的分数:
| doc1 | doc2 | doc3 | doc4 | |
|---|---|---|---|---|
| knn | 0.347 | 0.35 | 0.348 | 0.346 |
| bm25 | 0.63 | 0.01 | 0.3 | 0.4 |
你可以从上面看到差异:kNN 的分数范围在 0 到 1 之间,而 bm25 的分数可能变化很大。这种差异使得为组合结果设置静态的最优权重变得棘手。
归一化来帮忙:MinMax 归一化器
为了解决这个问题,我们引入了一个可选的 minmax 归一化器,它会使用以下公式将每个查询的分数独立缩放到 [0, 1] 范围内:
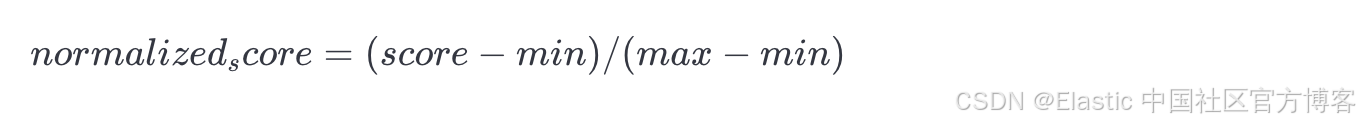
这会保留每个文档在某个查询结果集中的相对重要性,从而更容易将来自不同 retriever 的分数组合在一起。通过归一化后,分数变成:
查询 A 的分数:
| doc1 | doc2 | doc3 | doc4 | |
|---|---|---|---|---|
| knn | 0.347 | 0.35 | 0.348 | 0.346 |
| bm25 | 1.00 | 0.01 | 0.005 | 0.000 |
查询 B 的分数:
| doc1 | doc2 | doc3 | doc4 | |
|---|---|---|---|---|
| knn | 0.347 | 0.35 | 0.348 | 0.346 |
| bm25 | 1.00 | 0.000 | 0.465 | 0.645 |
所有分数现在都在 [0, 1] 范围内,优化加权和变得更加简单,因为我们现在捕捉的是结果相对于查询的重要性,而不是绝对分数,并且保持了查询之间的一致性。
举个例子!
现在我们通过一个例子展示上述内容,以及线性检索器如何解决 rrf 的一些缺点。RRF 仅依赖相对排名,不考虑实际分数差异。例如,给定这些分数:
| doc1 | doc2 | doc3 | doc4 | |
|---|---|---|---|---|
| knn | 0.347 | 0.35 | 0.348 | 0.346 |
| bm25 | 100 | 1.5 | 1 | 0.5 |
| rrf score | 0.03226 | 0.03252 | 0.03200 | 0.03125 |
rrf 会将文档排名为:
doc2>doc1>doc3>doc4然而,doc1 的 bm25 分数明显高于其他文档,rrf 无法捕捉到这一点,因为它只关注相对排名。线性检索器结合归一化,能正确考虑分数及其差异,产生更有意义的排名:
| doc1 | doc2 | doc3 | doc4 | |
|---|---|---|---|---|
| knn | 0.347 | 0.35 | 0.348 | 0.346 |
| bm25 | 1 | 0.01 | 0.005 | 0 |
如上所示,doc1 在 bm25 上的高排名和分数得到了正确的考虑并反映在最终分数中。此外,所有分数现在都在 [0, 1] 范围内,这样我们可以更直观地比较和组合它们(甚至构建离线优化流程)。
综合起来
为了充分利用带归一化的线性检索器,搜索请求将如下所示:
GET linear_retriever_blog/_search
{
"retriever": {
"linear": {
"retrievers": [
{
"retriever": {
"knn": {
...
}
},
"weight": 5
},
{
"retriever": {
"standard": {
...
}
},
"weight": 1.5,
"normalizer": "minmax"
},
]
}
}
}这种方法结合了两者的优点:它保留了线性检索器的灵活性和直观评分,同时通过 MinMax 归一化确保分数尺度一致。
和我们所有的检索器一样,线性检索器可以集成到任何层级的分层检索树中,支持可解释性、匹配高亮、字段折叠等功能。
什么时候选择线性检索器以及它为何重要
线性检索器:
-
利用实际分数而不仅仅是排名,保持相对重要性。
-
允许通过不同查询的加权贡献进行微调。
-
使用归一化增强一致性,使混合搜索更稳健、更可预测。
结论
线性检索器已经在 Elasticsearch Serverless、8.18 和 9.0 版本中提供!更多示例和配置参数也可在我们的文档中找到。试试看它如何提升你的混合搜索体验 —— 期待你的反馈。搜索愉快!
原文:Hybrid search revisited: introducing the linear retriever! - Elasticsearch Labs


















 1610
1610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









