







*按:学习是痛快也是快乐的,数据结构零散的看过一些,但是一旦到图论就打住了,这次我准备好好看看。看到强连通分量着实是花了不少时间,尤其是Tarjan算法,真是看到绝望。网上虽然很多各种理解攻略,但是都不得要领,盖脑子笨,或者是没有学过离散数学所致。(本人非科班)后来看了大神 邋遢哥的B占视频,终于搞懂了Tarjan算法的本质。
本问将根据本人的理解介绍阐述Tarjan的算法的本质(推导过程),为了把问题说清楚,需要回顾强连通分量的概念以及强连通分量的正反DFS解法(Kosaraju)过程。
标题强连通分量的概念和理解
清华86版《数据结构》(严蔚敏 吴伟民)课本定义原文摘抄如下:

强连通理解:都有路径,就是任意两个点直接都有路径,白话就是沿着图上的箭头方向可以到达任意个点,包括自己;
强连通分量: 分量的理解就是子图,G的图的一部分;根据上文,就是在这个子图中满足两两任意可达;极大:局部的最大。这个理解如果不明确的话,会很迷惑。极大不是最大,两个含义,第一它可能不唯一;第二:两个极大可能差别很大。极大是局部的概念。强连通分量之间没有强连通分量,这个也很重要。
举例如下: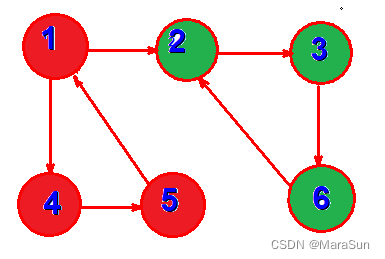
上图中的红色和绿色圆分别是两个强连通分量。
Kosaraju 算法理解
课本上没有明确算法名称,网搜后,发现这个解法名称上述所示。
解法简述如下:
后续DFS遍历,将结果放到数组中;在从最后一个节点开始逆向DFS遍历,到不能继续访问下一个节点,此时得到点集就是一个强连通分量。然后,在结果数组中,将这些点集去掉,再执行上述过程,到结果集为空,此时得到全部强连通分量。
过程和说明:
后续遍历:为啥是后续遍历,这主要是为了第二遍逆向DFS做准备的,后续遍历的结果会把有关强连通点集放到一起。如果是前序遍历,会交叉放置,这样第二次DFS的时候,汇出现偏差。
上图:前序DFS的一个可能(如果先访问2的话)结果是:
1,(2,3,6),4,5 这样从7 逆向的时候不会回到1点,从而出现错误;
如果是后续DFS, 则结果是
6,3,2, 5,4,1 这养第二遍逆向DFS的时候就会得到一个正确的结果。
综上,仔细手工重复上述过程,会发现可以采用某种方式,在每个DFS结束的时候,判断一下,应该可以得到强连通分量。笔者认为这也是Tarjan算法的来由。
类Tarjan 算法
通过分析强连通分量的定义,我们可以得出一个结论,在DFS的返回点(最后一个顶点)会遇到这个强连通分量的其实顶点,然后程序开始回退一直到起始DFS的那个顶点,而此时这个DFS过程碰到的点集必然是一个强连通分量。
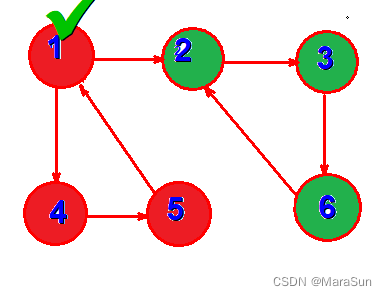
我们手工DFS一下上图(前序遍历即可)
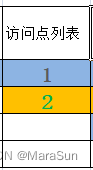
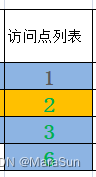
我们用一个数组或者List记录访问到的点
绿色的点集DFS过程如下
DFS(1)
DFS(2)
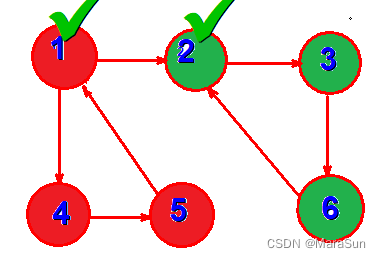
SFS(3)

DFS(4)
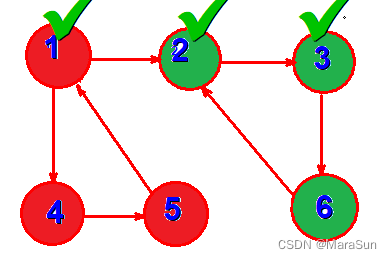
此时继续访问下一个节点,发现2 已经访问过,并且在列表中(在列表中非常关键,说明是同一个DFS系列的访问,如果不再同一个列表中,可能是另外一个DFS已经访问过),记录这个终点为 End。
开始回退,每次回退开始比较回调时的顶点是否和End 相同。回退过程,综合如下
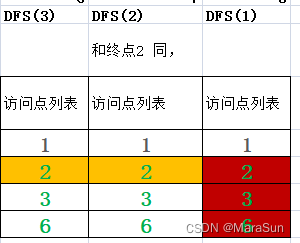
当回退到 DFS(2)时
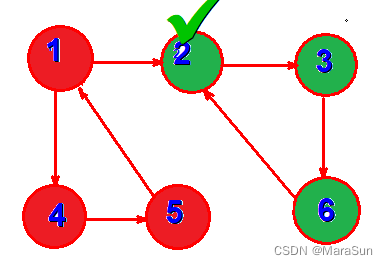
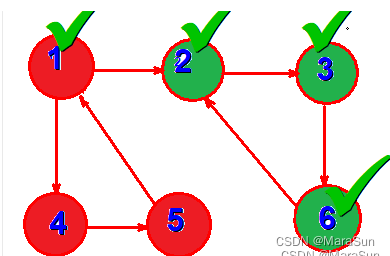
发现 顶点 2 和end 相同,此时列表中红色背景点即构成一个强连通分量。
说明:在强连通分量中,任意两个点都可以沿着箭头方向到达,这是我们想到了电势的概念,可以把边看成二极管,电流沿着二极管的方向流动,强连通分量就构成了一个回路。我们把有电流的地方染成同一种颜色,那么这些颜色一致的点集就是一个强连通分量。而染色结束点的判断就是上述黑色字体部分。染色的代码实现就可以给每个点赋以相同的值来实现,而这个过程敲好和Tarjan的low值是一致的。
根据上述算法的C#代码如下:(十字链表结构)
List<Vertex> m_SccLst = new List<Vertex>();
List<List<Vertex>> m_SccSetLst = new List<List<Vertex>>();
internal void DFS_SCC_Traverse(Vertex u, out Vertex end)
{
u.Visited = true;
m_SccLst.Add(u);
var nxtEdge = u.firstOut;
end = null;
while (nxtEdge != null)
{
var v = nxtEdge.headVex;
if (m_SccLst.Contains(v))// important ! // the v must have been visited , that it is in the list.
{
end = v;
}
if (v != null && !v.Visited)
{
DFS_SCC_Traverse(v, out end);
if (end != null)
{
if (end.Val == u.Val)
{
var idx = m_SccLst.FindIndex(vtx => (vtx.Val == u.Val));
var cnt = m_SccLst.Count - idx;
m_SccSetLst.Add(m_SccLst.GetRange(idx, cnt));
var restVtx = m_SccLst.GetRange(0, idx);
m_SccLst = new List<Vertex>();
m_SccLst.AddRange(restVtx);
}
}
else
{
m_SccLst.Remove(u);
m_SccSetLst.Add(m_SccLst);
m_SccLst = new List<Vertex>();
m_SccLst.Add(u);
}
}
nxtEdge = nxtEdge.tLink;
}
}
十字链表结构和初始化代码如下:
public class Vertex
{
public int Val;
public Edge firstOut;// in adjacent list , it is the the firstEdge; in orthogonal list ,it is the tail of an arc or edge
public Edge firstIn;// in adjacent list , it is null; in orthogonal list , it is the head of an arc or edge
public bool Visited = false;
public Vertex(int data)
{
Val = data;
}
}
public class Edge
{
public Vertex tailVex;// in adjacent list , it is the dajvex; in orthononal list ,it is the tail vertex (key or index)
public Vertex headVex;// in adjacent list , it is null; in orthononal list ,it is the head vertex (key or index)
public Edge hLink;// in adjacent list , it is next edge, in orthononal list , it is the next arc with the same head
public Edge tLink;// in adjacent list , it is null , in orthononal list , it is the next arc(edge) with the same tail
public bool visited;
int weight;
public Edge(int dat)
{
weight = dat;
}
}
调用代码
GraphClass myGraph = new GraphClass();
Create8VtxG(myGraph);
myGraph.initSCCDat(8);
Vertex end;
myGraph.DFS_SCC_Traverse(myGraph.GetVertex(0),out end);
其中 GraphClass 部分定义如下:
public class GraphClass
{
List<Vertex> VtxList = new List<Vertex>();
//used to get the SCC
int scc_index = 0;
Stack<Vertex> m_Stk = new Stack<Vertex>();
List<Vertex> m_ArticulateLst = new List<Vertex>();
List<Edge> m_BridgeLst = new List<Edge>();
public void AddVtx(Vertex vtx)
{
bool bExist = false;
foreach (Vertex itm in VtxList)
{
if (itm.Val.Equals(vtx))
{
bExist = true;
break;
}
}
if (!bExist)
{
VtxList.Add(vtx);
}
}
public void initSCCDat(int len)
{
DFN = new int[len + 1];
Low = new int[len + 1];
scc_index = 0;
}
public Vertex GetVertex(int index)
{
return VtxList[index];
}
public void AddEdge(int from, int to)
{
Vertex vFrom;
Vertex vTo;
from--; to--;
vFrom = VtxList[from];
vTo = VtxList[to];
var newEdge = new Edge(0);
newEdge.tailVex = vFrom;
newEdge.headVex = vTo;
// set the value of head vex
if (vFrom.firstOut == null)
{
vFrom.firstOut = newEdge;
}
else
{
Edge nxtEdge;
nxtEdge = vFrom.firstOut;
while (nxtEdge.tLink != null)
{
nxtEdge = nxtEdge.tLink;
}
nxtEdge.tLink = newEdge;
}
// set the value of head vex
if (vTo.firstIn == null)
{
vTo.firstIn = newEdge;
}
else
{
Edge nxtEdge;
nxtEdge = vTo.firstIn;
while (nxtEdge.hLink != null)
{
nxtEdge = nxtEdge.hLink;
}
nxtEdge.hLink = newEdge;
}
}
internal void DFS_SCC_Traverse(Vertex u, out Vertex end){
// 见前文
}
}
创建Sample 代码:
public void Create8VtxG(GraphClass G)
{
Vertex[] v = new Vertex[8];
for(int i = 0; i < 8; i++)
{
v[i] = new Vertex(i+1);
G.AddVtx(v[i]);
}
G.AddEdge(1, 2);
G.AddEdge(2, 3);
G.AddEdge(3, 4);
G.AddEdge(4, 8);
G.AddEdge(8, 2);
G.AddEdge(1, 5);
G.AddEdge(5, 6);
G.AddEdge(6, 7);
G.AddEdge(7, 1);
}
参考图如下:
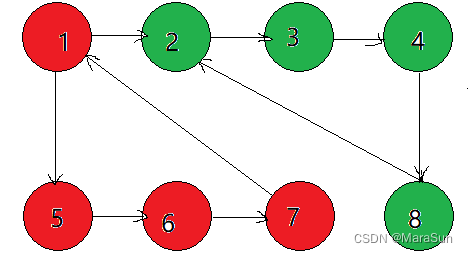
标题Tarjan算法的物理解释
Tarjan算法的描述如下:
(来自百度)
Tarjan算法是基于对图深度优先搜索的算法,每个强连通分量为搜索树中的一棵子树。搜索时,把当前搜索树中未处理的节点加入一个堆栈,回溯时可以判断栈顶到栈中的节点是否为一个强连通分量。
定义DFN(u)为节点u搜索的次序编号(时间戳),Low(u)为u或u的子树能够追溯到的最早的栈中节点的次序号。
当DFN(u)=Low(u)时,以u为根的搜索子树上所有节点是一个强连通分量。
上面的描述颇为费解,原因在于上面只是具体做法,并没有结实本质是啥。下面逐一分析。
DFN(u): 时间戳的概念,这个其实就是一个序号,用来指示每一步DFS的编号,换言之,用来区分每一步的DFN,这个值只要是唯一的就可以,之所以搞成序列是因为这个更自然,并且在以后求割点的过程中可以根据得小球的割点。
Low(u):这个值是最困惑的,它可以理解成我们上文提到的染色值,这个值其实就是DFN值的子集。
其定义的理解:
第一:是一个序号值(DFN值);
第二:等于它的某个祖先节点的DFN值(所以它的值是比较小的);
第三:这个祖先是在访问点集里面
第四:这个祖先是这个点集面最靠前的那个点。
本文中:它的值就是上图中顶点2 的DFN值。
第五:当DFN(u)=Low(u)时 即回退到最早的那点的时候,此时点集中(栈中),从u点开始并包括u点到栈顶的所有点构成一个强连通分量。
说明:对于一个没有回边的单点,上面的条件一样是满足的,这个单点也是一个强连通分量(其实这是认为规定的,因为单点不存在路径。)。
不知道说清楚没有
maraSun 与BJFWDQ
疫情和防疫进行中
疫情不知道是否在中国是否已经可以结束了
但是防疫却是如火如荼,各种防疫措施和设备如雨后春笋…















 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









