







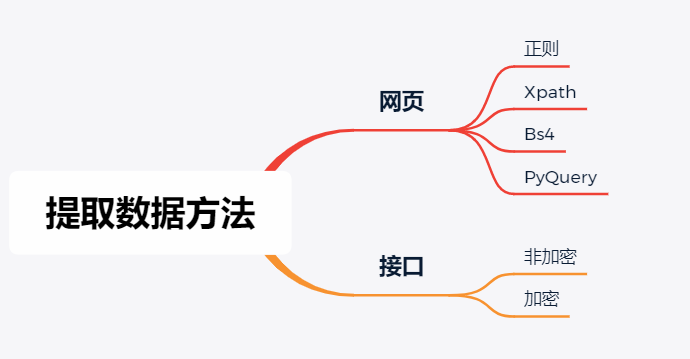
**
网页
![]()
正则表达式
正则表达式(Regular Expression):使用一种表达式的方法对字符串进行匹配的语法规则。
| 常用的元字符 | |
|---|---|
| . | 匹配除换行以外的任意字符 |
| \w | \W | 匹配字母数字或下划线 | 匹配非字母数字或下划线 |
| \s | \S | 匹配任意空白符 | 匹配非空白符 |
| \d | \D | 匹配数字 | 匹配非数字 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| a | b | 匹配字符a或b |
| () | 匹配包括内的表达式 |
| [........] | 匹配字符串组的字符 |
| [^......] | 匹配除字符串组的字符 |
| 量词 | |
|---|---|
| * | 重复零次或更多 |
| + | 重复一次或更多 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多 |
| {n,m} | 重复n到m次 |
| .* | 贪婪匹配,尽可能多的去匹配 |
| .*? | 非贪婪匹配,尽可能少的匹配 |
Python内置模块re。
| re修饰符 | |
|---|---|
| 修饰符 | 描述 |
| re.l | 使匹配对大小写不敏感 |
| re.L | 对本地化识别匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使匹配包括行内所有的字符 |
| re.U | 根据 Unicode 字符集解析字符。这个标志影响 \w、\W、\b 和 \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
| re常用方法 | |
|---|---|
| re.findall | 查找返回所有,返回list |
| re.finditer | 查找返回所有,返回一个迭代器 |
| re.search | 返回第一个结果 |
| re.match | 从第一个字符串开始匹配,没匹配到,返回None |
案例,获取2021年第四季度全国星级饭店统计调查报告发布时间。

发布时间的数据在<script></script>中,可以利用正则表达式获取。
# -*- encoding:utf-8 -*-
import re
import requests
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"referer": "https://sjfw.mct.gov.cn/site/dataservice/details?id=27170"
}
# 获取网页源代码
def get_source_code():
url = "https://sjfw.mct.gov.cn/site/dataservice/details?id=27170"
res = requests.request("GET",url=url, headers=HEADERS)
res.encoding = "utf-8"
return res.text
# 处理数据
def data_process(code):
deal = re.compile(r'<script>window.__NUXT__=.*publish_time:"(.*)",picture',re.S)
publish_time = deal.findall(code)[0]
print(publish_time)
if __name__ == '__main__':
code = get_source_code()
data_process(code)Xpath
安装第三方模块lxml
pip install lxml
导包 from lxml import etree
实例化 parse = etree.HTML(html)
| 选取节点 | |
|---|---|
| / | 从根结点获取 |
| // | 从匹配选择当前的节点选择文档中的节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选择属性 |
| 选取未知节点 | |
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型节点 |
| 最左侧 / | 表示必须树的根标签(HTML)开始定位 |
|---|---|
| 最左侧 // | 可以从任意位置进行标签的相对定位 |
| 非最左侧 / | 表示一个层级 |
| 非最左侧 // | 表示多个层级 |
| 常用方法 | |
| 获取属性内容
| <div><ul><li><a><li>....<ul></div> //div/ul/li/a/@href //div/ul/li/a/@title |
| 获取文本内容 | //div/ul/li/a/text() |
案例 获取故宫壁纸,通过Xpath获取图片标题和src

# -*- encoding:utf-8 -*-
import requests
from lxml import etree
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"referer": "https://www.dpm.org.cn/lights/royal.html"
}
# 获取网页源代码
def get_source_code():
url = "https://www.dpm.org.cn/lights/royal.html"
res = requests.request("GET",url=url, headers=HEADERS)
res.encoding = "utf-8"
return res.text
def data_process(code):
# 实例化xpath方法
parse = etree.HTML(code)
dict_pic = {}
# 定位最外层div标签
result = parse.xpath('//div[@class="pic"]')
for pic in result[0]:
for i in range(len(result)):
title = pic.xpath("//a/img/@title")[i]
url = pic.xpath("//a/img/@src")[i]
dict_pic[title] = url
return dict_pic
if __name__ == '__main__':
code = get_source_code()
print(data_process(code))
BeautifulSoup
安装第三方模块 pip install bs4
导包 from bs4 import BeautifulSoup
实例化 page = BeautifulSoup(html, "html.parser")
| 常用的定位方式 | |
| 标签定位 | find()、find_all() |
| 属性定位 | find("标签名",attrs={"属性名":"属性"}) find_all("标签名",attrs={"属性名":"属性"}) |
| 选择器定位 | select(css选择器)
|
| 提取方式 | |
| 提取标签内容 | tag.string 只可以提取到标签中直系的文本内容 tag.text 可以提取到标签中所有的文本内容 |
| 提取标签属性 | tag["attrName"] |
案例:获取必应壁纸,通过bs4-属性定位获取图片url和title
# -*- encoding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"referer": "https://bing.ee123.net/"
}
# 获取网页源代码
def get_resource_code():
url = "https://bing.ee123.net/"
res = requests.request("GET", url=url, headers=HEADERS,verify=False)
return res.text
# 处理数据
def data_process(code):
page = BeautifulSoup(code, "html.parser")
result = page.find_all("div", attrs={"id": "view_photoList"})
img_dict = {}
for i in result:
# 获取url
img = i.find('img')
url = img["src"]
# 获取图片title
title_info = i.find('h2')
title = title_info.text.split("(")[0]
img_dict[title] = url
return img_dict
if __name__ == '__main__':
code = get_resource_code()
print(data_process(code))PyQuery
安装第三方库 pip install pyquery
导包 from pyquery as PyQuery as pq
实例化 doc = pq(html)
| 常用的定位方式 | |
| css选择器定位 | 层级样式
|
| 提取方式 | |
| 提取标签内容 | tag.text() 可以提取到标签中所有的文本内容 |
| 提取标签属性 | tag.attr("标签名") |
案例:车型价位获取,通过Pyquery-css样式选择器方式定位。
# -*- encoding:utf-8 -*-
import requests
from pyquery import PyQuery as pq
HEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
INDEX = "https://car.yiche.com/"
def parse_index(url):
"""
处理首页
@param url: 首页url
@return: 返回源代码
"""
res = requests.request("GET", url=url, headers=HEADERS)
res.encoding = "utf-8"
return res.text
def car_model(html):
"""
各类车型处理
@param html:首页源代码
@return: 车型:子页面
"""
doc = pq(html)
# 提取所有品牌链接
brands = doc('.brand-list-item .item-brand')
# 创建一个空字典来存储提取的车名和URL
car_dict = {}
# 遍历每个品牌,提取车名和URL
for brand in brands.items():
car_name = brand.attr('data-name')
car_url = brand.parent().attr('href')
car_dict[car_name] = "https://car.yiche.com"+ car_url
return car_dict
def process_car(html):
"""
车型名称和价格获取
@param html:
@return: 车型:价位
"""
doc = pq(html)
brand = doc(".search-result-list-item")
car_dict = {}
for car in brand.items():
car_name = car(".cx-name").text()
car_price = car(".cx-price").text()
car_dict[car_name] = car_price
return car_dict
if __name__ == '__main__':
car_info = parse_index(INDEX)
car_dict = car_model(car_info)
tip = """
请输入要获取车型最新价格
如 奥迪
"""
# 输入要查询的车型名
car_name = input(tip)
car_url = car_dict[car_name]
# 处理该类车型,进入车型页面
car_code = parse_index(car_url)
# 处理车型页面,获取具体的车型和价格
brand_car = process_car(car_code)
f = open(f"{car_name}.text", 'w', encoding="utf-8")
if bool(brand_car):
for k, v in brand_car.items():
f.write(f"{k} -价格区间 {v}\n")
print("下载成功,见文件内容")
else:
print("未找到合适的车型")
f.close()接口
![]()
未加密
API接口
通过抓包,获取请求方法、url,请求参数、请求头,发起请求即可获取接口数据。通过json.loads()方法将字符串转为字典,通过键值对获取想要的数据。 案例:移动观象台-获取应用排行top10的应用名称、所属公司、活跃度。
# -*- encoding:utf-8 -*-
import requests
import json
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"referer": "http://mi.talkingdata.com/app-rank.html"
}
def get_app_data():
url = "http://mi.talkingdata.com/rank/active.json?date=2022-11-01&typeId=0&dateType=m&rankingStart=0&rankingSize=30"
res = requests.request("GET",url=url, headers=HEADERS)
return res.text
def get_top_10(code):
data = json.loads(code)
data_list = []
for i in range(10):
app_info = []
# app名称、所属公司、app活跃度
app_name = data[i]["appName"]
company = data[i]["company"]
activeRate = data[i]["activeRate"]
app_info.extend([app_name,company,activeRate])
data_list.append(app_info)
return data_list
if __name__ == '__main__':
code = get_app_data()
print(get_top_10(code))加密
API接口-加密
JavaScript逆向找到加密解密方式。之后的步骤如同API接口。

提取数据方法总结
-
Xpath
适用于要获取的信息在某个标签下,且各标签层次明显,通过路径找到位置,for循环遍历即可
-
Bs4
适用于要获取的信息比较分散,且通过选择器可以定位(class唯一、id唯一)
-
PyQuery
适用于要获取的信息比较分散,且通过选择器可以定位(class唯一、id唯一)
-
正则
通过(.*?)就可以处理元素失效或者定位少量信息 不适用网页代码有很多其它符号,定位失效 数据在JavaScript代码中;
-
接口返回数据
对于接口没有进行加密,通过requests构造请求即可获取数据 关注点在请求头中的参数(UA、防盗链等)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









