







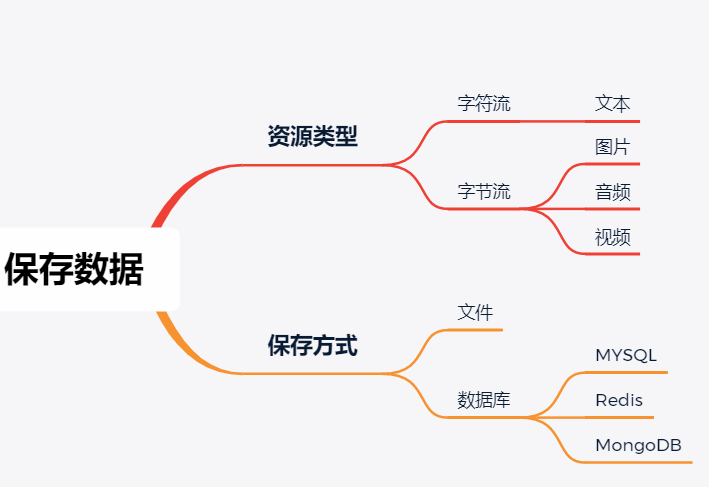
通过小案例来保存爬取的数据
**
![]()
案例1:字符流-文本 [微信读书TOP200]
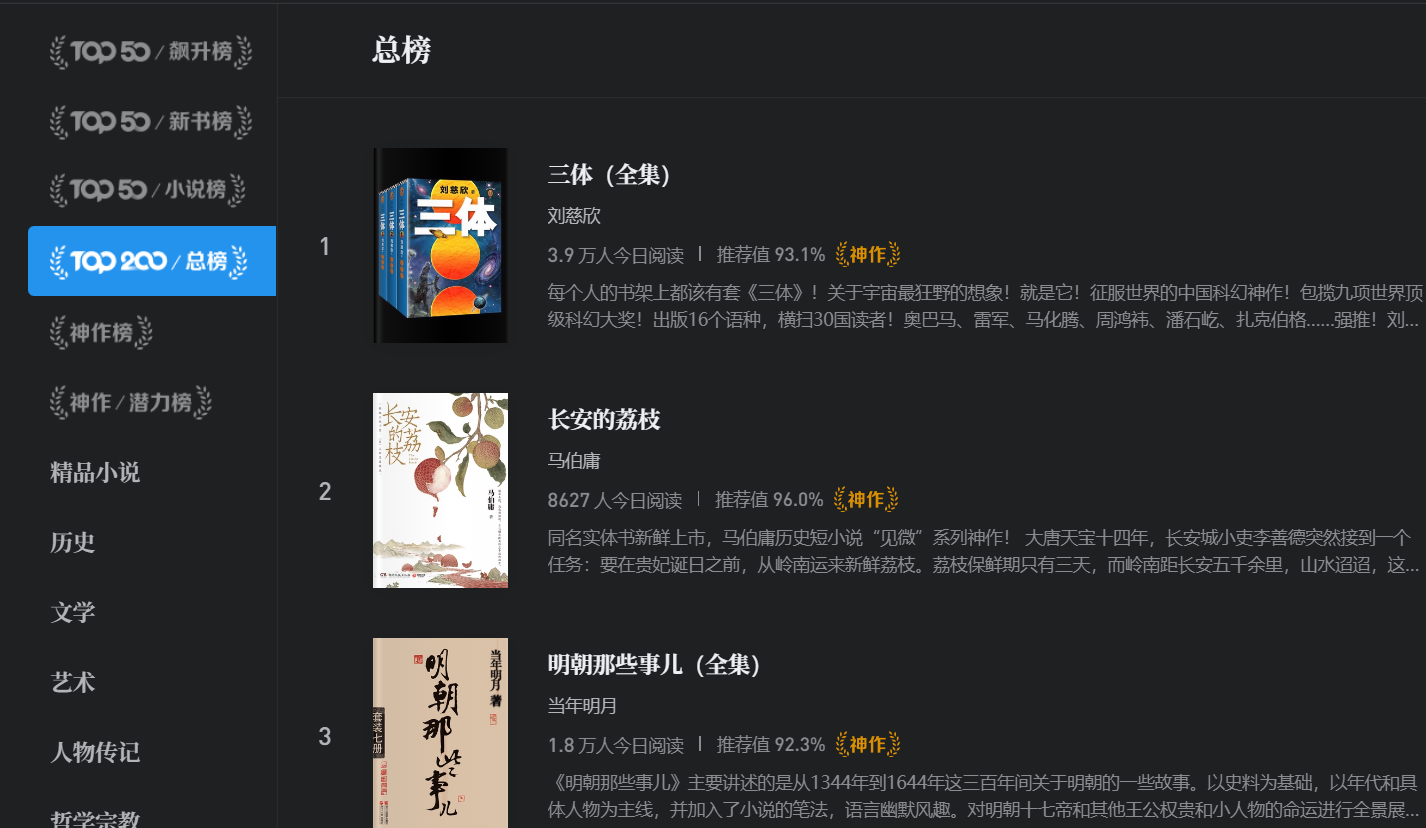
将 书名、作者、今日阅读量、推荐值、概要写入到文本文件中。
import requests
import json
import time
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"referer": "https://weread.qq.com/web/category/all"
}
def get_book_info(url,f):
res = requests.request("GET",url=url, headers=HEADERS)
data = json.loads(res.text)
for i in range(len(data["books"])):
# 书名
book_name = data["books"][i]["bookInfo"]["title"]
# 作者
author = data["books"][i]["bookInfo"]["author"]
# 今日阅读量
day_reading = data["books"][i]["readingCount"]
# 推荐值
recommend_rated = data["books"][i]["bookInfo"]["newRating"]
recommend_rate = str((recommend_rated/10))+"%"
# 概要
# summary_info = data["books"][i]["bookInfo"]["intro"]
# 剔除空格
# summary = summary_info.strip("\n").strip(" ")
f.write(f"书名:{book_name}、作者:{author}、今日阅读量:{day_reading}、推荐值:{recommend_rate}\n")
# f.write(f"概要:{summary}\n")
print("微信阅读总榜top200正在下载")
if __name__ == '__main__':
with open("WechatReading_top200.txt", mode="a", encoding="utf-8") as f:
for i in range(0,181,20):
url = f"https://weread.qq.com/web/bookListInCategory/all?maxIndex={i}&rank=1"
get_book_info(url,f)
time.sleep(1)
print("微信阅读总榜top200下载完成")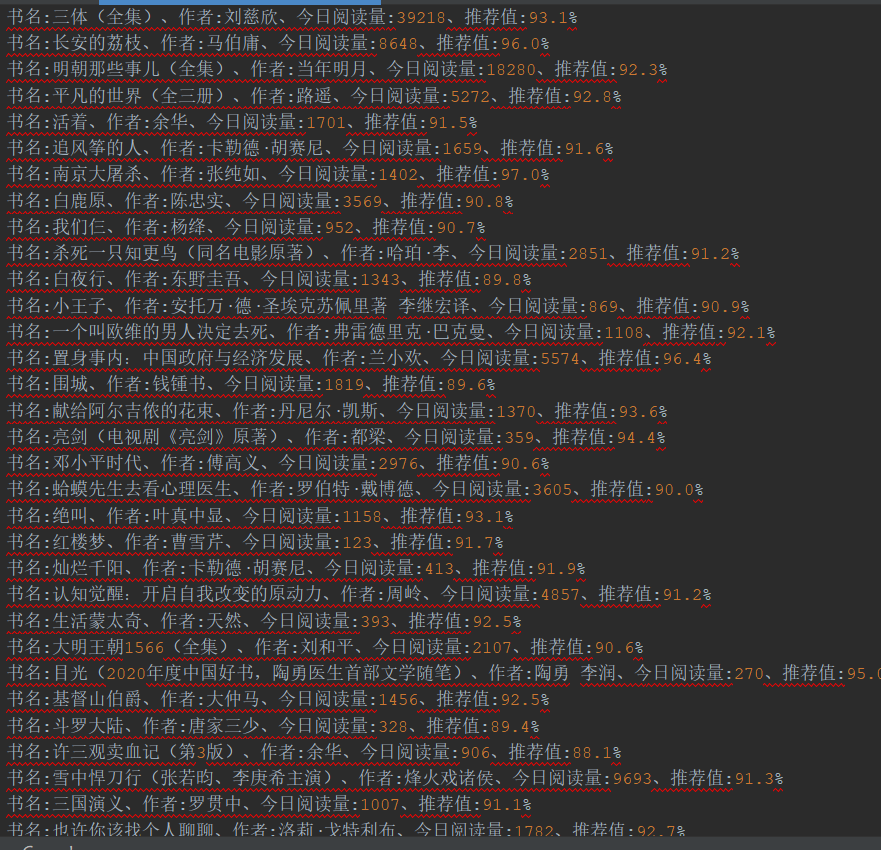
案例2:字节流-[免费版权图片]
将图片下载保存到本地。
import requests
import json
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"referer": "https://www.logosc.cn/so/"
}
def get_img_url():
url = "https://www.logosc.cn/api/so/get?page=0&pageSize=20&keywords=&category=local&isNeedTranslate=undefined"
res = requests.request("GET",url=url,headers=HEADERS)
data = json.loads(res.text)
# 定义容器存储url
url_list = []
for i in range(len(data["data"])):
img_url = data["data"][i]["small_img_path"]["url"]
url_list.append(img_url)
return url_list
def down_img(url,f):
res = requests.request("GET",url=url).content
f.write(res)
print("一张图片下载完成!")
if __name__ == '__main__':
# 获取图片url
url_list = get_img_url()
for url in url_list:
url_name = url.split("/")[-1]
with open(f"img/{url_name}",mode="wb") as f:
down_img(url,f)
print("图片下载完成!")
案例3:字节流-音频-[背景音乐]
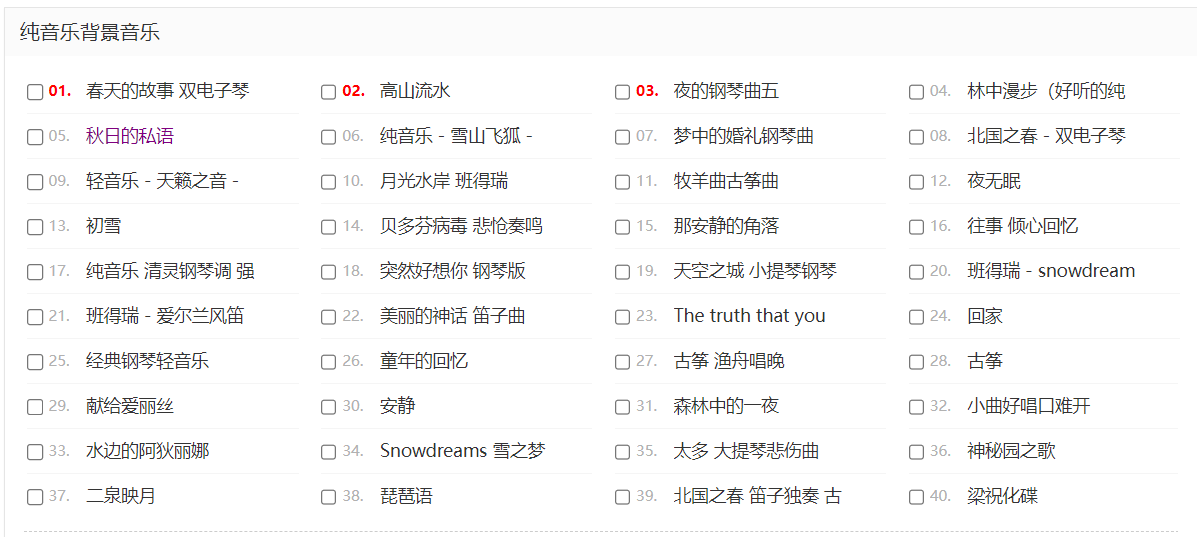
将MP3文件下载到本地。
import requests
import re
import json
import time
from lxml import etree
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
}
# 获取网页源代码
def get_source_code():
url = "https://www.9ku.com/qingyinyue/chunyinyue.htm"
res = requests.request("GET",url=url, headers=HEADERS)
res.encoding = "utf-8"
return res.text
# 数据处理
def data_process(code):
parse = etree.HTML(code)
result = parse.xpath("//ol[@id='f1']")
for i in result:
title = i.xpath(".//li/a/text()")
url = i.xpath(".//li/a/@href")
# 通过zip合并两个列表
song_dict = dict(zip(title,url))
return song_dict
# 获取音乐下载地址
def get_music_url(ids):
url = "https://www.9ku.com/playlist.php"
param = {"ids": ids}
res = requests.request("POST",url,data=param,headers=HEADERS)
res.encoding = "utf-8"
data = json.loads(res.text)
name = data[0]["mname"]
music_url = data[0]["wma"]
# 下载背景音乐
download_background_music(music_url,name)
# 下载音乐
def download_background_music(url,name):
name = name.strip().strip("\n")
# 添加referer,否则下载失败
headers = {"referer": "https://www.9ku.com/play/381049.htm"}
res = requests.request("GET",url=url,headers=headers).content
with open(f"bgm/{name}.mp3",mode="wb") as f:
f.write(res)
print("一首音乐下载完成")
if __name__ == '__main__':
code = get_source_code()
song_dict = data_process(code)
for url in song_dict.values():
deal = re.compile(r'^/.*/(?P<ids>\d.*)\.htm$')
result = deal.search(url)
ids = result.group("ids")
get_music_url(ids)
time.sleep(1)
案例4:字节流-视频-[2022足球世界杯决赛回顾]
将视频下载到本地。
参考该博客文章 Python爬取CCTV视频_gethttpvideoinfo.do-CSDN博客文章浏览阅读4.7k次,点赞5次,收藏17次。Python爬取短视频、长视频_gethttpvideoinfo.dohttps://blog.csdn.net/Uncle_wangcode/article/details/127677768
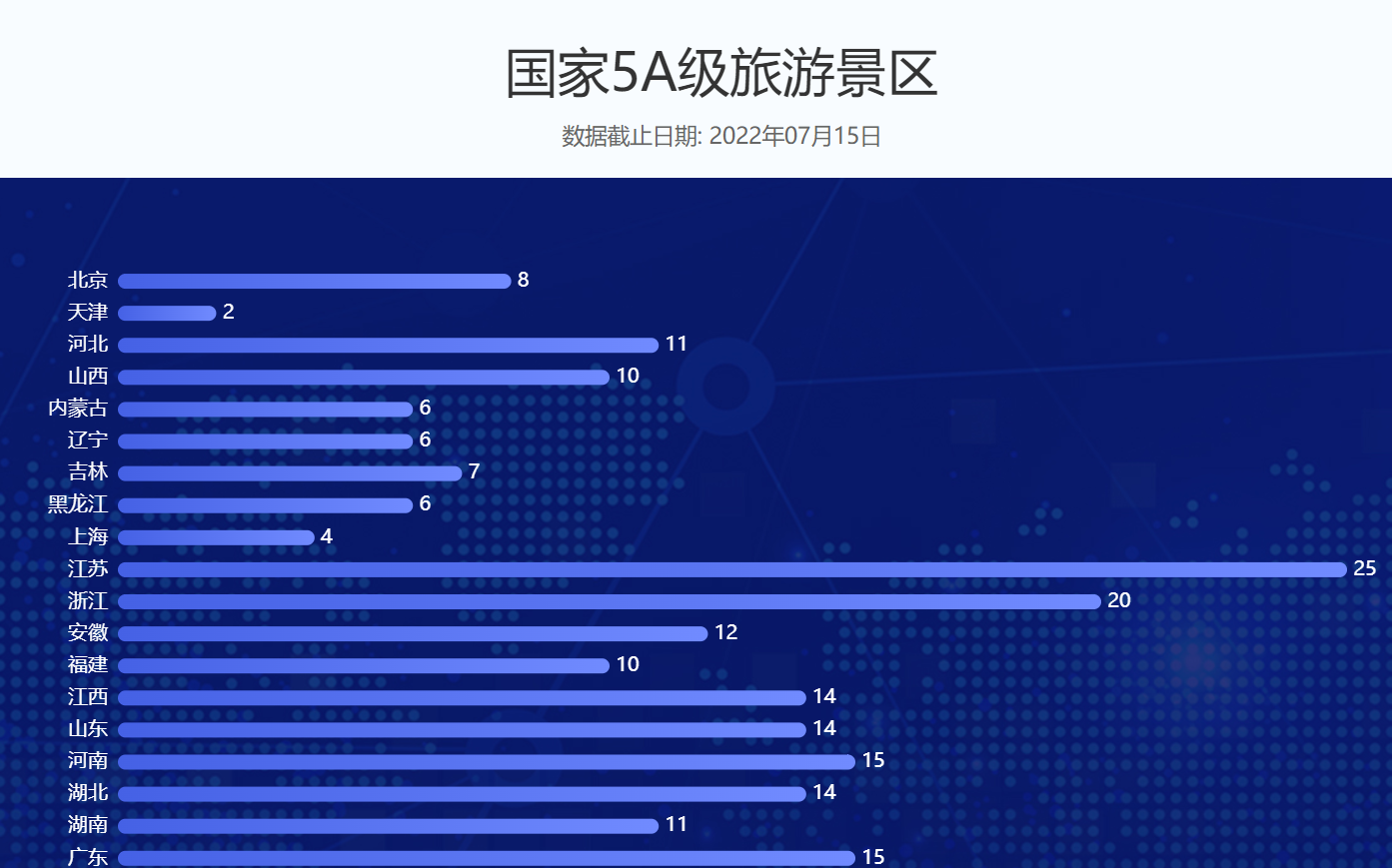
案例5:保存到MYSQL[国家旅游景区、休闲街区]
MYSQL是关系型数据库,一般来说用MYSQL作为存储,需要建立表与表之间的关系(一对一、一对多、多对多)。

数据库表设计
CREATE TABLE `province` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`province_name` varchar(10) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=32 DEFAULT CHARSET=utf8;
CREATE TABLE `category_travel` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`category_name` varchar(30) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
INSERT INTO `category_travel` VALUES (1, '国家级旅游休闲街区');
INSERT INTO `category_travel` VALUES (2, '国家5A级旅游景区');
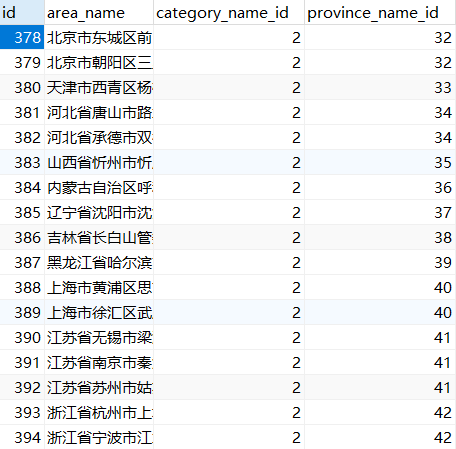
CREATE TABLE `detail` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`area_name` varchar(100) NOT NULL,
`category_name_id` bigint(20) NOT NULL,
`province_name_id` bigint(20) NOT NULL,
PRIMARY KEY (`id`),
KEY `detail_category_name_id_c2480191_fk_category_travel_id` (`category_name_id`),
KEY `detail_province_name_id_8eae059e_fk_province_id` (`province_name_id`),
CONSTRAINT `detail_category_name_id_c2480191_fk_category_travel_id` FOREIGN KEY (`category_name_id`) REFERENCES `category_travel` (`id`),
CONSTRAINT `detail_province_name_id_8eae059e_fk_province_id` FOREIGN KEY (`province_name_id`) REFERENCES `province` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=378 DEFAULT CHARSET=utf8;# -*- encoding:utf-8 -*-
import requests
import pymysql
from pyquery import PyQuery as pq
HEADERS = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Cookie': '_trs_uv=lb3j060h_4419_f53p; yfx_c_g_u_id_10001331=_ck22113018554519555678636775235; yfx_f_l_v_t_10001331=f_t_1669805745954__r_t_1669805745954__v_t_1669805745954__r_c_0',
'Pragma': 'no-cache',
'Referer': 'https://sjfw.mct.gov.cn/site/dataservice/rural?type=10',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
class Get_data():
def __init__(self,url):
self.url = url
def get_index_code(self):
# 获取网页源代码
res = requests.request("GET", url=self.url, headers=HEADERS)
res.encoding = "utf-8"
self.text = res.text
def deal_method(self):
# 静态数据处理方式,这里通过Pyquery方法
doc = pq(self.text)
self.doc = doc
def get_city_and_count(self):
# 获取城市和数量
self.deal_method()
city_list = []
city = self.doc.find("div .n")
for _city in city.items():
city_list.append(_city.text())
self.city_list = city_list[1:]
def deal_count(self):
# 数据二次处理,返回 城市:数量
city_dict = {}
for name in self.city_list:
# 剔除)
name = name.strip("个)")
deal_ = name.split("(")
city_name = deal_[0]
count = deal_[1]
city_dict[city_name] = count
self.city_dict = city_dict
def get_area(self):
# 获取具体的地区
self.deal_method()
area_name = []
name = self.doc.find("div .span")
for _name in name.items():
area_name.append(_name.text())
self.area_name = area_name
def deal_city_area(self):
# 处理数据,具体地区分类
result_list = []
# 获取具体地区数据
info_list = self.area_name
# 具体数量
count_list = []
for count in self.city_dict.values():
count_list.append(count)
# print(count_list)
# 具体二次数量处理
count_list_two = [0, ]
_count = 0
for i in count_list:
_count = _count + int(i)
count_list_two.append(_count)
# print(count_list_two)
index_count = len(count_list_two) - 1
for i in range(index_count):
first = count_list_two[i]
end = count_list_two[i + 1]
result = info_list[first:end]
result_list.append(result)
# result_dict[name] = result
continue
self.result_list = result_list
def city_and_area(self):
# 获取城市+具体地区数量
result_dict = {}
name_list = []
for name in self.city_dict.keys():
name_list.append(name)
for i in range(len(name_list)):
name = name_list[i]
city_area = self.result_list[i]
result_dict[name] = city_area
self.result_dict = result_dict
def connect_db(self):
# 连接数据库
connect = pymysql.connect(
host="localhost",
port=3306,
user='root',
password='rootroot',
database='test2'
)
return connect
def main(self):
# 获取网页源代码
self.get_index_code()
# 获取具体地区
self.get_area()
# 获取城市数量
self.get_city_and_count()
# 数据二次处理
self.deal_count()
# 处理数据,具体地区分类
self.deal_city_area()
# 获取城市+具体地区数量
self.city_and_area()
# 查询语句
def select(name):
# 先查询id
select_sql = f"""
select id from province where province_name = '{name}'
"""
return select_sql
# 插入语句
def add(name, category_id, province_id):
insert_sql = f"""
insert into detail(area_name, category_name_id, province_name_id) values ('{name}', {category_id}, {province_id})
"""
return insert_sql
if __name__ == '__main__':
# 将省份写入数据库
test = Get_data(url="https://sjfw.mct.gov.cn/site/dataservice/rural?type=138")
test.get_index_code()
test.get_area()
test.get_city_and_count()
test.deal_count()
print(test.city_dict)
city_name = []
for name in test.city_dict.keys():
city_name.append(name)
print(city_name)
try:
# 连接数据库
connect = test.connect_db()
# 创建游标
cursor = connect.cursor()
_sql = """
insert into province (province_name) values (%s)
"""
result = cursor.executemany(_sql, city_name)
print(f"成功添加{result}条数据")
# 提交事务
connect.commit()
# 关闭连接
connect.close()
except Exception as e:
print(e)
if __name__ == '__main__':
# 国家级旅游休闲街区url-https://sjfw.mct.gov.cn/site/dataservice/rural?type=138
# 国家级5A旅游景区url-https://sjfw.mct.gov.cn/site/dataservice/rural?type=10
test = Get_data(url="https://sjfw.mct.gov.cn/site/dataservice/rural?type=10")
test.main()
print(test.result_dict)
for city, area in test.result_dict.items():
print(city, area)
try:
# 连接数据库
connect = test.connect_db()
# 创建游标
cursor = connect.cursor()
_sql = select(city)
# 执行查询语句
cursor.execute(_sql)
result = cursor.fetchone()
province_id = result[0]
# 执行插入语句
for i in range(len(area)):
# 国家级旅游休闲街区 2
# 国家级5A旅游景区 1
add_sql = add(area[i], 1, province_id)
insert_result = cursor.execute(add_sql)
# 提交事务
connect.commit()
# 关闭连接
connect.close()
except Exception as e:
print(e)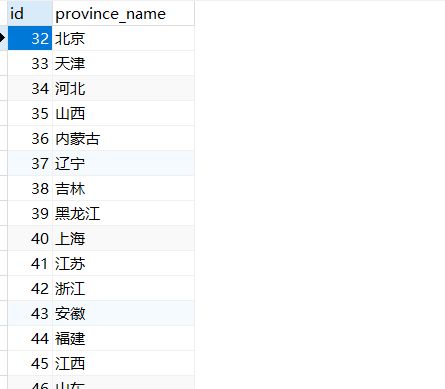
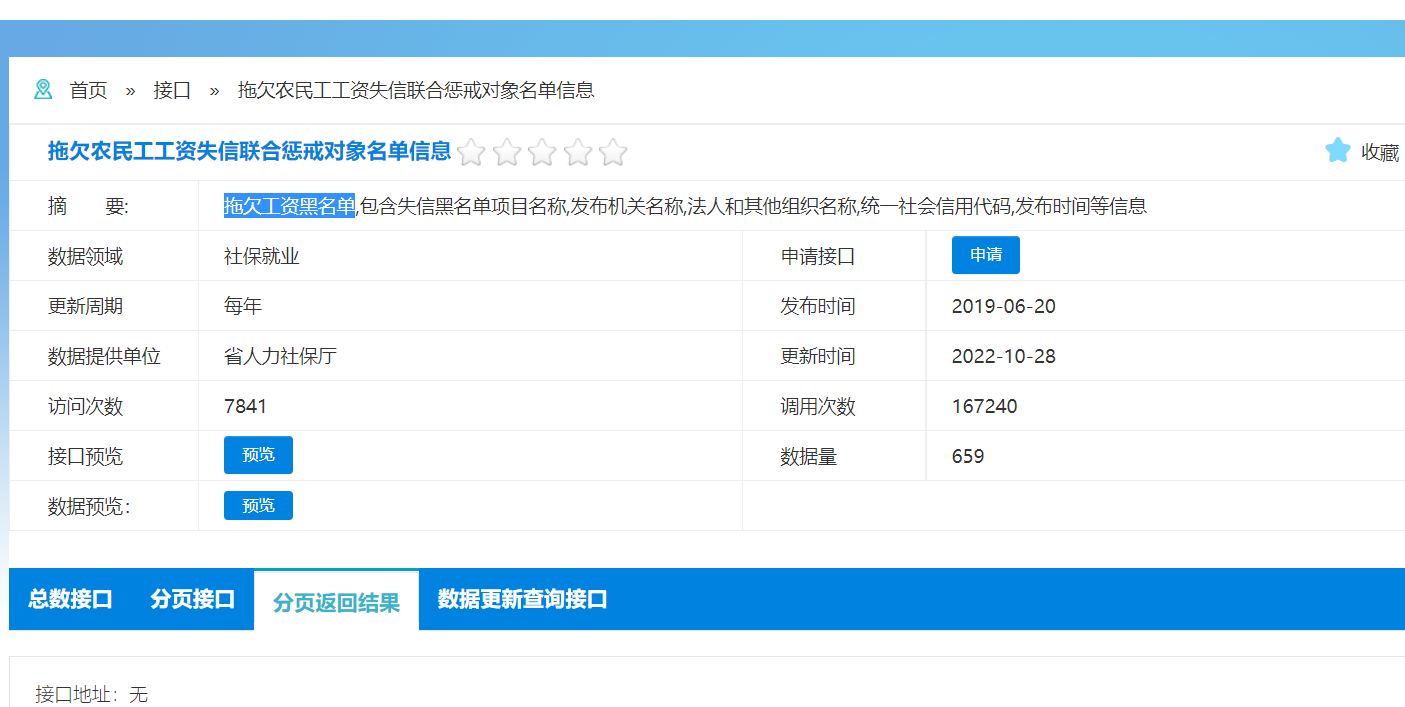
案例6:保存到Redis-[浙江省拖欠工资黑名单企业信息]
将浙江省拖欠工资黑名单的企业数据写入Redis。(主体单位、信用代码、法人、认定时间、原因)
# -*- encoding:utf-8 -*-
import requests
import json
import time
import redis
def get_info(url):
res = requests.request("GET",url=url)
data = json.loads(res.text)
for i in range(len(data["data"])):
info_dict = {}
# 认定单位统一社会信用代码
rdd = data["data"][i]["RDDWTYSHXYDM"]
# 认定时间
rd_time = data["data"][i]["RDSJ"]
# 主体单位
company = data["data"][i]["AAB004"]
# 法人
person_name = data["data"][i]["AAB013"]
# 列入名单事由
reason = data["data"][i]["ABB012"]
info_dict["主体单位"] = company
info_dict["信用代码"] = rdd
info_dict["法人"] = person_name
info_dict["认定时间"] = rd_time
info_dict["原因"] = reason
# 写入Redis
r = connect_db()
result = r.hset("defaultinfo",company, json.dumps(info_dict))
if result > 0:
print("一条数据插入成功")
# 连接redis数据库
def connect_db():
pool = redis.ConnectionPool(host="127.0.0.1", port=6379)
r = redis.Redis(connection_pool=pool)
return r
if __name__ == '__main__':
for i in range(1,4):
url = f"http://data.zjzwfw.gov.cn/jdop_front/interfaces/cata_5994/get_data.do?pageNum={i}&pageSize=200&appsecret="
get_info(url)
time.sleep(1)
print("数据插入完成")该接口申请来源于http://data.zjzwfw.gov.cn/jdop_front/detail/api.do?iid=5995 需要自己申请获取appsecret
案例7:保存到MongoDB-[PDD商品信息]
首页各栏目下的商品数据抓取保存到MongoDB数据库中
-
商品名称
-
现价
-
原价
-
已拼件数
-
图片URL
import requests
import json
import time
from pymongo import MongoClient
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36',
'Referer': 'https://www.pinduoduo.com/',
'Cookie': 'api_uid=CkqllWOpB9u+SQBmYdAzAg==',
}
# 数据库初始化
def get_db(database,user=None,pwd=None):
client = MongoClient(host="localhost",port=27017)
db = client[database]
# 有账号密码即验证
if user:
db.authenticate(user,pwd)
return db
# 插入语句
def insert_data_many(collection, data):
db = get_db("PDDGoods")
result = db[collection].insert_many(data)
return result
def get_good(url):
res = requests.request("GET",url=url,headers=HEADERS)
data = json.loads(res.text)
goods_list = []
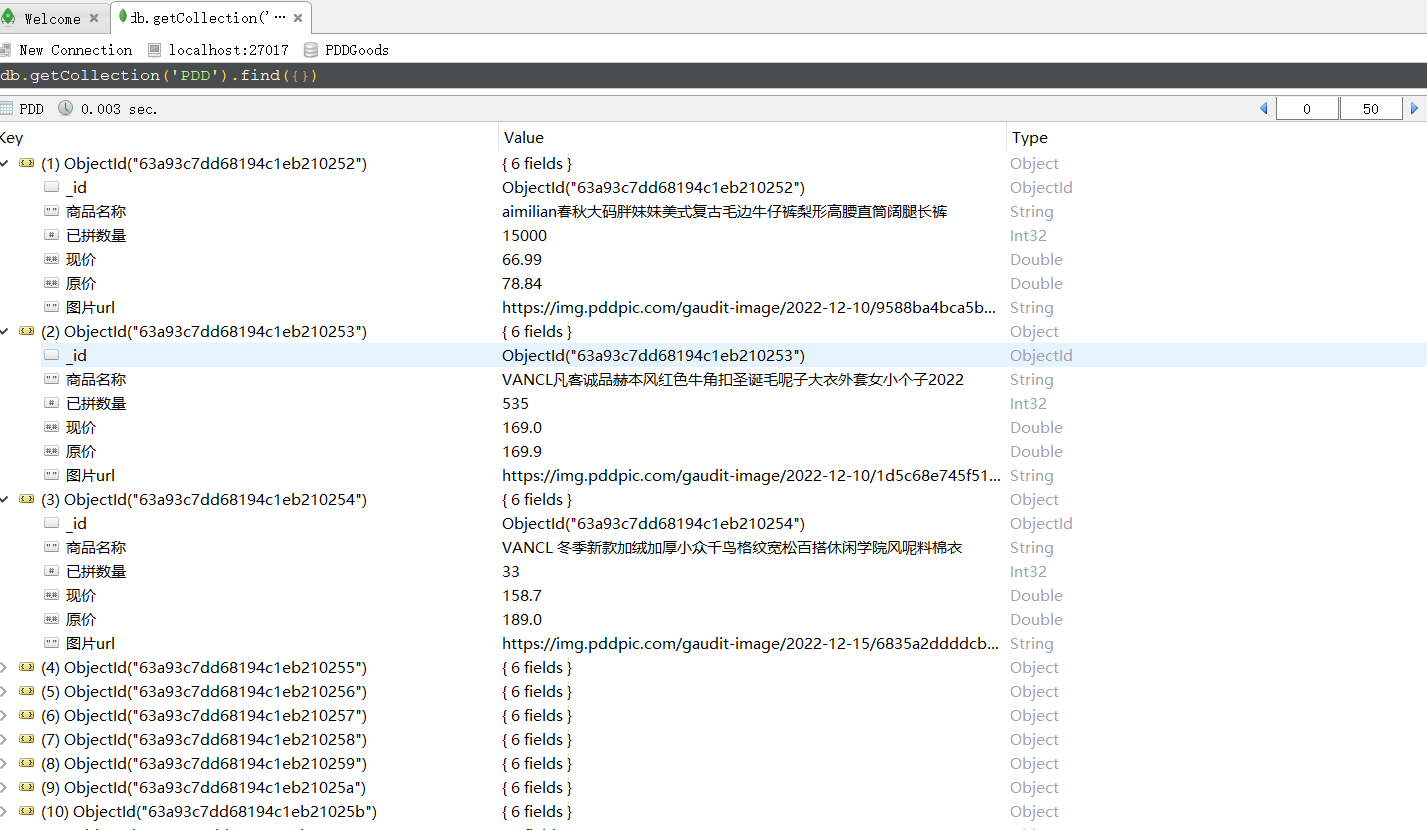
for i in range(len(data["result"])):
goods_dict = {}
# 商品名称
goods_name = data["result"][i]["goods_name"]
# 已拼数量
sales = data["result"][i]["sales"]
# 现价
price = data["result"][i]["group_price"]
price = price / 100
# 原价
origin_price = data["result"][i]["group_price_origin"]
origin_price = origin_price / 100
# 图片url
img_url = data["result"][i]["thumb_url"]
goods_dict["商品名称"] = goods_name
goods_dict["已拼数量"] = sales
goods_dict["现价"] = price
goods_dict["原价"] = origin_price
goods_dict["图片url"] = img_url
goods_list.append(goods_dict)
return goods_list
if __name__ == '__main__':
url_list = [
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_13396&page=1&size=100&anti_content=0aqAfx5e-wCEgaiRE2x4IXOCbv8wUFfTDBvoM33ADFATzeA_-URglUF3RWIeRpM1hIMexDFflWUF8_UshOYHQMKSNqVCzm6-bAd1E-xIkB1-EB3ZD-2VD-2HIBeheB2OE-sIdv9Cyng3XQDexPHXqOGz_oqWWlHXMnqgovniTadnXt2nh_7sqobV_CEBhCez4O92mxXH2dIYgayswaG4Mf_ajlpo0nGig8nYWzXYwTyo0j4W6jys6PqOjXvJslpOKXjseaYZU9hXY_ay0X9TE7CxGpgSUqSFCknZ9f7ZaVpqbIP9-AooPtPZ1qTRBt5GsQKt0n5NLTdNbC9yL9tOrpNOCLZvdbCfewzX-35DQ7FncBKa999nSVjI0RFf8yK',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_13394&page=1&size=100&anti_content=0aqWfxUkMwVePqxyXVKt_FKccGEGqNojqoPYgO1YTu5oWpNEQ8XvnxdvDpNqhtXYtP_CTkQdDj10VyNliVN1PyOpeJn0Pxn0uyXpuyXYexj0uJXUe2N9yQGV9D64lMuJflf-kMzZuazRmr3zkF3leSL1SKB4ZHZTQQYqbOzvgPd09Jy0tazV9fMfcets7eMMVIl2Td3IWB1_ALkfCIMxhkLxMetBcbWPmbRlVK3MAM14hL1qAS3MVHlBddVAxFD7lVkVt24uBfDe-gMzgh0wF_2Iy7gI7zswPBYzj32wgzl_6qxdkD1C3_kOE-_5S-gVB-TZz-DC-F6y_KSD2XPKvpXK1YFSQq_Unw5vk7X8xZmCE-EHrJ9990Ry69nGy9ItTv',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_14351&page=1&size=100&anti_content=0aqWtxUkM_VefqavnNKGpFKccXEXqNojqofYsO1Ywu5oWdNET8n4lxv4AYv-nYFx2xi2Fi_H7FQgdar8gqFgejnUvYnYuyOYujngeangPvlYuqlgfxlgeYl9ZKufIKk0Vb-zMk7BHt73ToMz8EM30dIMRKkG65s9bJTXqi7N9c_ngdwnr2799IeMzVHzt5kD0KbBZdF1fDStS-S-h5m61oH6kO1DPZrZTULL0UFk6DSGH5StMCSDqKbkxp2S6zKeGBS9ffGae-15v7kv0yl6ZsBHZe_11ezswEQESFBs_v3fCPB_-MM4-BMxhktGWe_9Dk2B7k1R7vA_GhuKssV5tXqGbOYnKcGiBuqmMlOiWzin4O09agfe637Xy9IGw4',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_13397&page=1&size=100&anti_content=0aqWfxUkM_VegaXokq3-zBWew-Y2LnLa8YMqeYM02eIBpv-2uz7RoH-3WzL2k-3tDE3wtpESfRHS3BCMLIC-1RCKORa3oRTnKuBSZjO6cPMZZe7ZVkM3Ve715eB_KDMhKkM3FeBxIeB1Ve20wb_d6TXNqk7k-e7u-dFRRkEkWmFfQImLZFKDPw0YuboGjma4jgall9YOse9415k74cvMf-KtUV7sQpFZIuMW7W7LfODMROkMq-KW6hgRTHKtQ_FkIuIhtuMkRAHtUZSsP6ukBZVK7u9VVH257Mf_k-wGwyDgw7hsZBM-Zv_2u3WWwv_sdFZNuzB7DmRv7mB3FF13Zg21FgzkMS3k_jgI3qVd52Nu-ldn1nduX_EnM3UmTE-vr-yVwg98TAqyYR-f8yX',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_13398&page=1&size=100&anti_content=0aqWfxUkMwVe9qydXyKt_FKccG7GqNojqoPYgO1YTu5oWpN7Q8XEnxdEWtXEnw5CTkQdDj10VyNliVN1gacpdqnYuynpTxnGejXp7dnYuqn0Pxn0uYX9ZKuPU3lkYMezf-kzuZDFWRm73zkF3lKmL1SKt9w0UTrorxea_igaA29YN2D9_ZVkMtcdBsMKISVzs4TFxIWMh_AzDPQnsYQ8gx2aiOUxnA6wqgSXYcvapyjlpcCdNg3KaUFfFX04Yy0gsTPpFxGGXIgDMST54ZaceVacDqPt608q5hPIXVf5_N8qUGjUYPYnFitXeNPX98IXgoGGROVzhdgsTGZF3DCSLtEFSgmeLOo7qG02Te9WpiHf_i9t5FE',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_13400&page=1&size=100&anti_content=0aqWtxUkM_VefabQkz-GInAVbzG_F-twm6zoS33Wm-Ww7kWpMFRsQF-3RCIkRdS1Fff2Fi_H7FQ0dar80qFdfJnYvyOdwynYwJndwycAwJlYfynUsylXfa46Za5-ZOcuvLOYGaOkGofiN8oqOYtpAwJjdlwy9VP61jCEIYVBLtVDG2SeGy9B09YOzDKn0T_zP9OGnZt0vilNObOydujlcuYl-TwNTefNCE_vuUtYs3zusilYOrEzP0QG9G3xc09wON92274sinp5YGZ7ZKyfV1uXptnXpO541qiNVK5GSt4bKhlOFYiKNqnYklpY4n4dfnIYlXqqYIfzU-2-v0aB6CF1xmHH8duxcUIqrAwN9f09X1wmpnow4K1g',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_14282&page=1&size=100&anti_content=0aqWfxUkMwVe9q8dXOKt_FKccGEGqNojqoPYgO1YTu5oWpNEQ8XvnxdvDpdxnt__SyBpjBcDTbnQ0oeQt_nYuxnYuxXpPycG9aXYTxXATJnYPyXUgyn0_a4BZa5JSyyR3jeMz-kqsLwr3cC-kMpFLZoIMWVK2gln08vosU2Gyp2yg0QasK2tB2MeIjTe7D5IW2edf4pB1LD3fjkKMiImt3SmtDVbWywbhhUK34pMk8IbfLDSf8oIW4udTwqsA9IQTXTz9ZlpgOOqKwIDA4Pt64j504jHPVKuQmttb5Kq9MfGYmtXo7QXUX8pyKxUaVa0DKa_NOoLq2D3TTz95ggf-eqmMnOiWzSoED29T9wpMy9Gy9ItTv',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_14283&page=1&size=100&anti_content=0aqWtxUkM_Ve6araE62ckB_Fhg4DxQUnOl3jMk6Xq0ka1UgutDjUm6fbwxH28ndfNl1j5r6Geantj5Sn13MkX2wq5V1Gp58ycuoXqsEGNUnpqSl2qGi3TxuseYNJB_ib8_iZUEsC3w3lT0OeTQwlUeYnUGJnXeynUgYndu8nAgjl0nJnU98ldwq4MZa5l57I_6d7t-k7uZ7FWRmE37kF3QKmL1SKG9_0Uw3orxeapigaA29YN2D9pZVkMGcv6BMKISV7B4wFxIWMhpA7DtoDMqhk8qMKQPcgWXHKLQwF3MAIh4WM1qAHLSVSBggu16ZVe7W9wVI24WMt_k-wHvyDgwvhB1gMB17_2wbWRvz_BdFZnwE687kRFWk6kOS1kZP2tV6zk5-3kAjgGjqVZI2yg-GdpacIA_Cqm5lOA7EJjHs9Vn9y_irBUR-t8ys',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_14348&page=1&size=100&anti_content=0aqWfxUeMwVEQ_YdXFKt_FKccG7GqNojqoPYgO1YTu5oWpN7Q8XknxdkDpg1g1iZU7kC3T3nQ0OEQlTXUDJX0uJX0XxXpuYOp98y0dyXYuqX0EjnGEPD64PWs28uzn5eze-PdAsoMiRvzelpItRIeL2VFEbylUNNMPsox9sTaXi98OsKP4e5mv4ZeMf1KfUTdslDSZIFSAM5mL1OmMWOeM4ZHA65tRQUFfleSDIVScIuSDR1KfYwZ6P_EEBsSKBPtVTSf5zzfTfjAtVgv6VDZsZD-FwdW0O-vuTdegpg-iO-B7I68vMmfLdEZbwE21dEeDz7ie2cXKf_V_4xYZeCq7UnOez7krtkVOX9XzomGak1_Ack',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_14349&page=1&size=100&anti_content=0aqWfxUeMwVE9qYyXaKt_FKccG7GqNojqoPYgO1YTu5oWpN7Q8Xknxdkmp_KHYXFct5v6yBpjBcDTbnQ0oEQt_nUgxXpdjXYXyXU9yOGgxXA9JnYPyXUgynpdy0BZa50Gr1s_vze-EzO-CFRRe7eWmFflImLZFKDPT0GuVoGjma4jgann9YOsE9415ez4cdMf-KtUVzsl_FZIuMWzWzLfODMROeMq-KW6hgRQHKtlwFeIuIhtuMeRAHtUZSsPgueMZVKzu9VVH25zMfwe-TGTyDgTzhsZBM-Zdw2u3WWTdwspFZNuvBzDmRdzmB3FF13Zg21FgveMS3ewjgI3qVT54TFZtptov7XM3UmQ7-JinxVTg9Fmscmqi9t5Fk',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_14352&page=1&size=100&anti_content=0aqWtxUkM_Ve9qJvnOKGpFKccXEXqNojqoPYgO1Ywu5oWdNET8nflxvfWG4fGGpeSyBdjBcDwblT0oeTG_nXuyl0vJn04ynUu8ldwxy0uJnUwqndwJl0wPD64G7WnCNdIYnH4xFINUJYDfGYn-tj0Cznj0w49uDS-iWHQ9EKM2KKBAVHw9vn0QxzIVanisvu4aKqgFldyJqY5Y_lYv8jYn8vi0aiVUxiAs_qnSnd-zadyJQYcAvunbK9USGyn24Ya9gsePdyxGXnIsDBUw54-acPFacGqPGSXJq45PIuFX55b8qdT8UYPYlFjXnPatnVqHnyoXXQKZ7QvBdw94--_m-kkDvsIEIH8duxcUIqfNYfwP09gZgmh9ow4K1f',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_14353&page=1&size=100&anti_content=0aqAfxUeMwCE9qJyXCKt_FKccG7GqNojqoPYgO1YTmZoApN7Q8X5nxd5WqqjtGZjXwZWTeQdkj10CyNliCN1PJnYmyOG4qnGgyXU_JXUgjj0mJXUTqXpTycp9Xk64GABEMrfseMvVkqvRpr3-u-3hTFL1oIB_VKV9QnYqNovo9Gdp9yy0lavC9tMf-Etj_EMzCIl2Ed3t_B1qe3e3DKMxIDLxMDtzVbAbpbRhCK3BwM1qIb1qeS38OIlBmdCux-kB4Vea444OBfkE-sMv9c0wKw2kbzgkkzswgsY-332wgvl_6xxdee1o3weODM__SMgTBMTwvMkW--6d_HSt2BPPqt45tG_KHjvYfhE8Yjsp9RWEg29tsQDEaoT4K15',
'https://apiv2.pinduoduo.com/api/gindex/tf/query_tf_goods_info?tf_id=TFRQ0v00000Y_14394&page=1&size=100&anti_content=0aqAfa5e-wCEPx8yXSSt_USOOG7GxNhjxhPqgHKqTmZhApN7Q8XYnadYDGdin__at_mjBfiV57YW3T3nQ0HEQlTn5goX59aHpTyHq9jnqPxnidjn0XJX598npPo4-VoZGCxhWeVE-v-e_sDwD3hWFv-pULZh1-ACEfBln4BYQfZ2DNT2dX0QTnI2k49-E-jTSzeZkk4Eys2p-KbkKfJeS-R1DB3MIBeCSkJwbZh5b34p-e81SfrkMf8h1k4myEwxBzB2VeL2Z4SgfxEFFZd4u7_S2swbBSwEzKegv6Crfv7gsBwgafWDfwFLViFe-xAFBPAgz9kvBBzFFYzTDpt4wSgTZ-YGGzSl0zaz6NFbqDBvFR2dKNG09928J6jQLdMDTY'
]
for url in url_list:
# 获取商品信息
good_list = get_good(url)
# 添加到MongoDB数据库
insert_data_many("PDD",good_list)
time.sleep(1)

| 资源类型 | |
| 字符流 | 文本文字 文本文字(字体混淆) |
| 字节流 | 图片 音频 视频
|
| 保存方式 | |
| 本地文本文件 | 文字、图片、音频、视频 |
| 数据库 | MYSQL Redis MongoDB |















 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









