







运行环境
- windows11
- JDK 8
- anaconda3
- python 3.9
- Neo4j 3.5.32
- python jupyter库
- py2neo
- Visual Studio Code 2022
项目地址:
Gitee : https://gitee.com/ccuni/py2neo-neo4j-actual-combat
GitHub:https://github.com/unirithe/py2neo-neo4j-actual-combat
一、数据集说明
数据集来自 IMDB 影视网的电影、演员数据,数据并不全,仅供学习参考。
数据集参考上方的 Gitee 或 GitHub地址
-
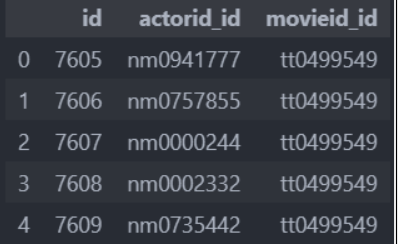
movie_act.csv 演员id到电影id的映射信息
-
-
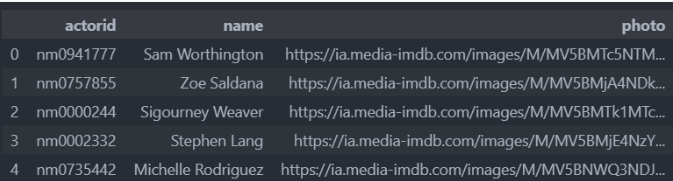
movie_actor.csv 5334个演员的信息,名称和头像
-
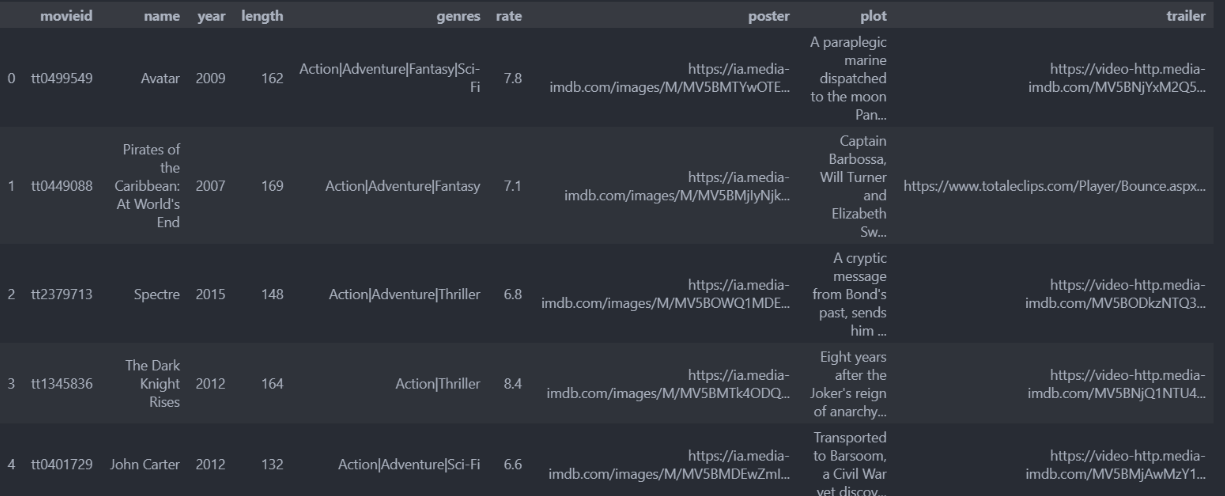
movie_moive.csv 2926部电影的详情信息
-
movie_popularity.csv 保留着62部受欢迎的电影信息
-
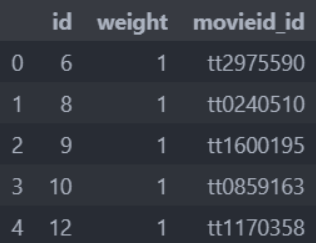
user_user.csv 不知道有啥用的id信息
二、数据预处理
这里将原先的csv数据转为 pandas的DataFrame后再转化成字典,从而能构建Node对象,插入到Neo4j中
2.1 选择受欢迎的电影
list_mid = df['popularity']['movieid_id']
# 查找受欢迎的电影信息
# Find the movies which is popularity
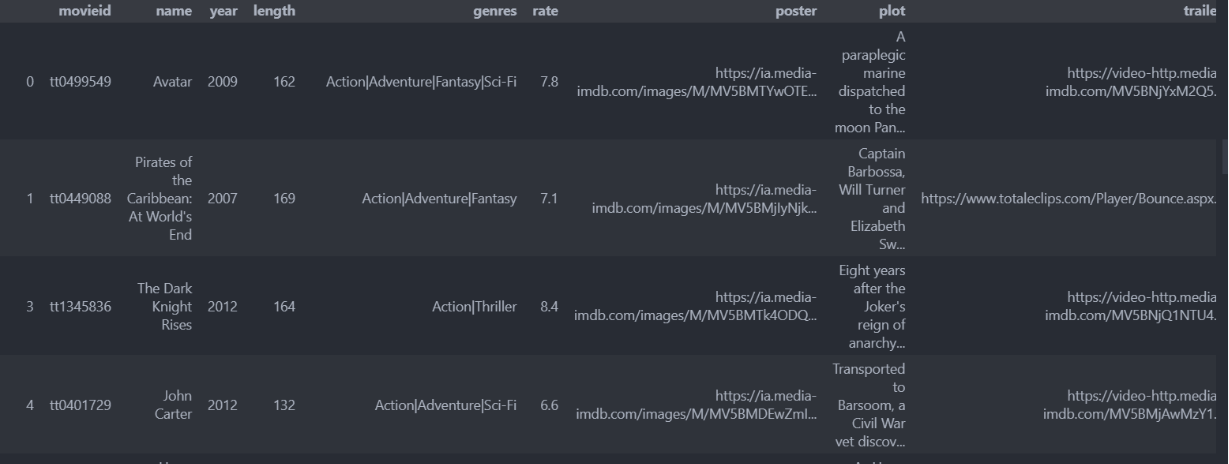
df_popularity_movie = df['movie'][df['movie']['movieid'].isin(list_mid)]
df_popularity_movie
# 将DataFrame格式转化为dict,到时候方便插入Neo4j
# make DataFrame to Dict, in order to insert neo4j
dict_movie = {
}
for i in range(len(df_popularity_movie)):
row = df_popularity_movie.iloc[i]
dict_movie.update({
row['movieid'] : row.to_dict()})
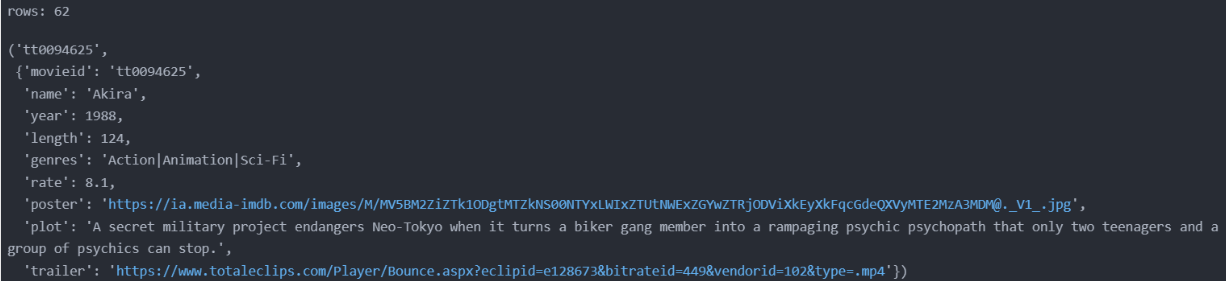
print('rows: ' , len(dict_movie))
2.2 查找每部受欢迎电影的所有演员
dict_actor_movie = {
}
for mid in df_popularity_movie['movieid']:
flag = df['actor_movie']['movieid_id'].eq(mid)
actors = df['actor_movie'][flag]['actorid_id'].to_list()
dict_actor_movie.update({
mid : actors})
print('rows: ' , len(dict_actor_movie))

2.3 查找热门电影里每个演员的信息
dict_actor = {
}
actors = set()
for ac in dict_actor_movie.values():
for actor < 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3675
3675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









