








 超级会员免费看
超级会员免费看

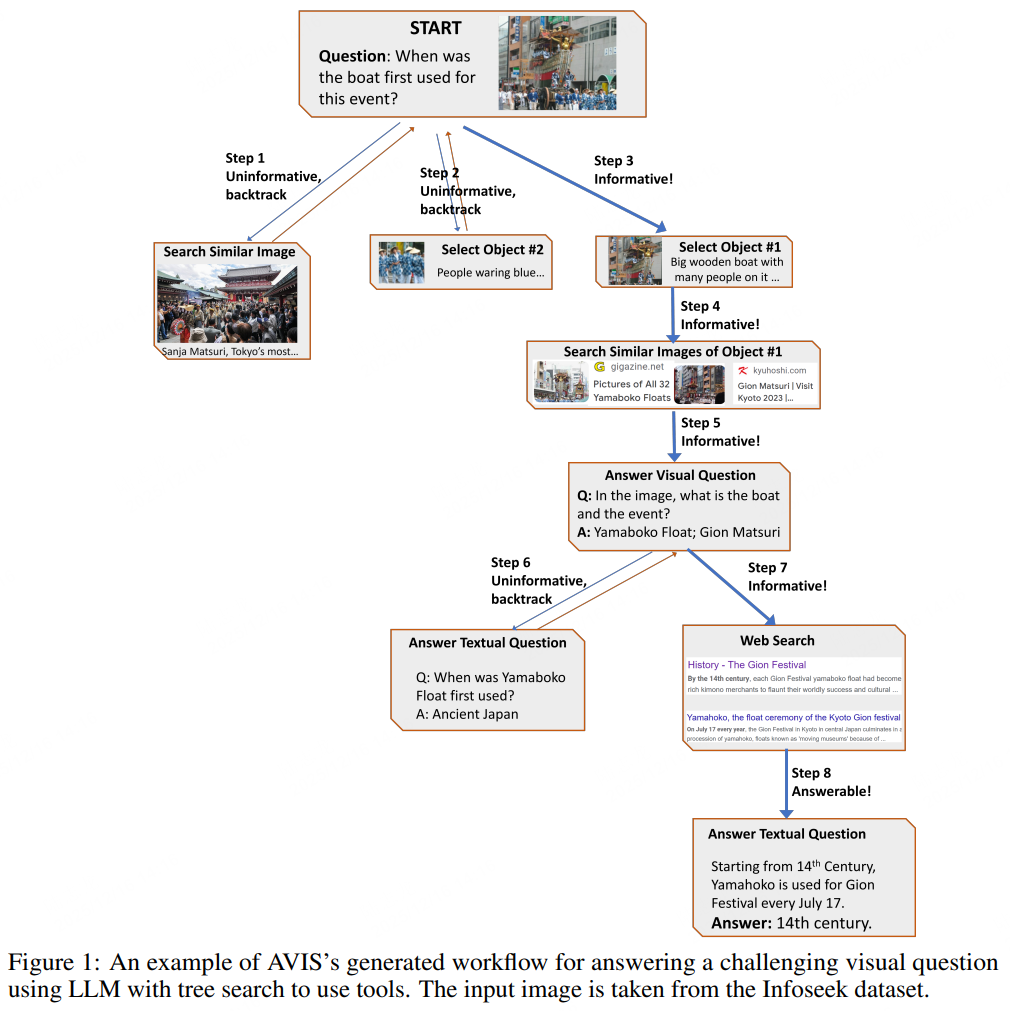
一、文章主要内容总结
本文提出了一种名为AVIS的自主视觉信息检索问答框架,旨在解决需要外部知识的视觉问答(VQA)任务(如“图中建筑纪念的是什么事件?”)。该框架核心是利用大型语言模型(LLM)作为智能体,通过动态决策和树搜索策略调用外部工具,逐步获取回答所需的关键知识,最终实现对复杂视觉问题的精准应答。
- 核心挑战:现有视觉语言模型(VLMs)在需要细粒度信息、外部知识或图像元数据比对的任务(如Infoseek、OK-VQA数据集)中表现不佳,原因包括缺乏细粒度训练目标、推理能力受限、无法关联大规模图像 corpus 等。
- 系统架构:
- 规划器(Planner):基于当前状态、人类决策转换图和工作记忆,动态选择下一个调用的工具及查询内容。
- 推理器(Reasoner):分析工具输出,提取关键信息,并判断是否需要继续检索、回溯或直接输出最终答案。
- 工作记忆(Working Memory):全程存储工具调用结果和关键信息,为决策提供上下文支持。
- 工具集:涵盖计算机视觉工具(目标检测、OCR、图像描述、VQA模型

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1782
1782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









