






 本文介绍了一种两阶段机制来降低MPC在端对端联邦学习中的通信开销,通过选举小委员会并利用其提供的MPC服务聚合模型,实现了隐私保护且保持高准确性和执行效率。方法应用于智能制造物联网平台,对比了传统方法与新型框架在效率上的改进。关键技术和框架包括MPC、联邦学习、秘密共享和工业化应用案例。
本文介绍了一种两阶段机制来降低MPC在端对端联邦学习中的通信开销,通过选举小委员会并利用其提供的MPC服务聚合模型,实现了隐私保护且保持高准确性和执行效率。方法应用于智能制造物联网平台,对比了传统方法与新型框架在效率上的改进。关键技术和框架包括MPC、联邦学习、秘密共享和工业化应用案例。
方法:提出一个两阶段机制:①选举一个小委员会②通过委员会向更多的参与者提供MPC支持的模型聚合服务。
目的:解决
基于安全多方计算(MPC,Multi-Party Computation)的模型聚合以端对端的方式导致了
高通信开销和低可拓展性
的问题
结论:
已集成到智能制造的物联网平台,不会牺牲隐私、准确性、执行效率。
基于安全多方计算(MPC,Multi-Party Computation)的模型聚合以端对端的方式导致了高通信开销和低可拓展性。——>提出一个两阶段机制:①选举一个小委员会②通过委员会向更多的参与者提供MPC支持的模型聚合服务。——>已集成到智能制造的物联网平台,不会牺牲隐私、准确性、执行效率。
联邦学习仍然可能导致隐私泄露
——>隐私保护技术,如安全多方计算(MPC)、同态加密(HE)、差分隐私(DP)是与联邦学习一起工作以保护模型聚合的数据机密性的典型候选技术
——>①谷歌提出一种实用的基于MPC的联邦学习安全聚合算法②SecureBoost是一个基于垂直树的联邦学习系统,采用同态加密保护梯度③OpenMind在其联邦学习框架中结合了MPC和DP功能
——>①安全多方计算是一种密码学技术,允许多个参与方在其敏感数据集上计算联合函数。只有联合函数的输出是公开的,没有透露参与者的私人输入。
——>在典型应用中,安全多方计算的速度比完全同态加密(FHE)实现快数千倍
——>②差分隐私(DP),通过在第三方计算中加入随机噪声来保护数据隐私,但由于随机噪声会影响联邦学习模型的准确性,因此不适合联邦学习。
——>本文选择MPC
——>
缺点:MPC协议要求所有各方生成和交换私有数据的秘密共享给所有其他各方
——>导致了高通信开销,并伴随着成员列表中同意一起工作的各方数量呈指数增长,而不管他们是可信的还是不可信的。——>为了降低通信成本和提高可拓展性,本文提出基于MPC的联邦学习隐私保护框架:不是要求每个成员在所有成员列表中生成和交换秘密共享数据的条件,而是
从整个成员列表中选出联邦学习成员的子集
作为模型聚合委员会的成员。当选的委员会成员使用MPC服务来汇总所有联邦学习方的本地模型。两阶段MPC引入了一种层次结构,在这种结构中,需要用更少的秘密共享交换隐私保护(或数据机密性)模型聚合。当成员名单很大,而委员会成员的数量只是联邦学习方数量的一小部分时,这种技术就变得更加明显。
——>端对端和两阶段MPC支持的联邦学习框架都是在PyTorch上实现的,这是一个基于facebook的分布式机器学习和深度学习平台。开发了一种并行机制,使基于MPC的模型在具有大量参数的整个模型张量上进行聚合。
——>使用包含真实传感器数据集和机器学习故障标签的智能制造用例,证明了准确性和效率
相关工作:
本文为水平联邦学习
①谷歌2019年3月 张量流联邦(Tensor flow Federated,TFF)
②CrypTen是Facebook在PyTorch上构建的基于MPC的隐私保护机器学习框架
③OpenMind是一个开源社区,专注于开发将深度学习、联邦学习、同质加密和去中心化数据上的区块链相结合的技术
④FATE(Federated AI Technology Enabler)是由We Banks AI Group发起的另一个开源项目,旨在为构建Federated AI提供一个安全的计算框架生态系统
⑤ByteLake与联想合作,发不了一份制造业的概念证明,用于预测性维护
本文:
保护隐私、面向价值的联邦学习
基于去中心化数据
通过可视化和智能制造领域知识集成到工业互联网平台
MPC虽然已被广泛应用于隐私保护联邦学习中,但在提高性能和可拓展性方面的研究还有限
OpenMind为模型聚合提供了非常基本的MPC开销估计
谷歌为实际MPC协议提供了复杂性分析和通信开销评估
框架:
A.安全多方计算
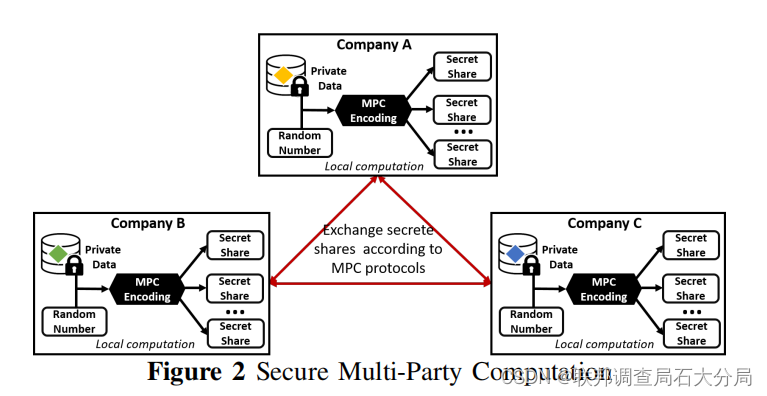
加密技术 目前主要有两种:乱码电路和秘密共享
乱码电路:基于布尔电路的密码协议,为解决流行的百万富翁问题(两个百万富翁想要知道谁更富有,但不透露它们的实际财富)
秘密共享
:用于生产系统 每个敏感数据都被分割成秘密部分,这些秘密部分结合起来产生原始数据。它们根据MPC协议相互交互,通过交换秘密共享来计算保密函数。只要大多数参与方都诚实地遵守协议,那么除计算的最终输出外,没有任何参与方会学到任何东西。由于每个计算方都在一块秘密共享上工作,只有在计算对等点的阈值被破坏时,攻击者才能从秘密共享中重建私人隐私。因此,MPC可以被看做是一种加密方法,它提供了可信方的功能,可信方可以接受私人输入,计算一个函数,并将结果返回给利益相关者,而不需要参与者之间互相信任。
联邦学习框架中,加性(Additive)和Shamir(秘密线)秘密共享MPC都用于隐私保护模型聚合
本文关注的是神经网络机器学习模型
B.端对端的MPC联邦学习
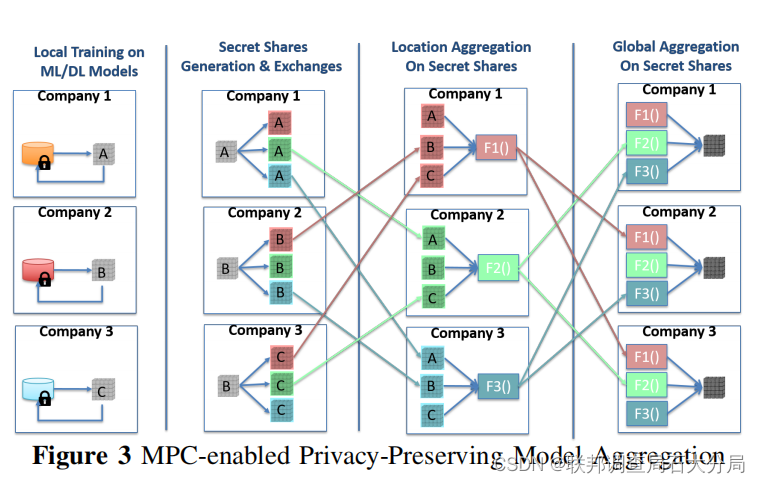
并行MPC操作可以显著降低计算和换流成本
通过计算张量的平均值来进行模型聚合
单个局部模型的张量是隐私敏感的
——>通过添加随机性,它们被分割成多个张量作为秘密共享
——>交换秘密份额后,每个参与者持有张量的一份
——>参与者对秘密份额进行局部聚合,然后进行全局聚合来抵消随机性,从而得到所有参与者张量的平均值。
C.二阶段的MPC联邦学习
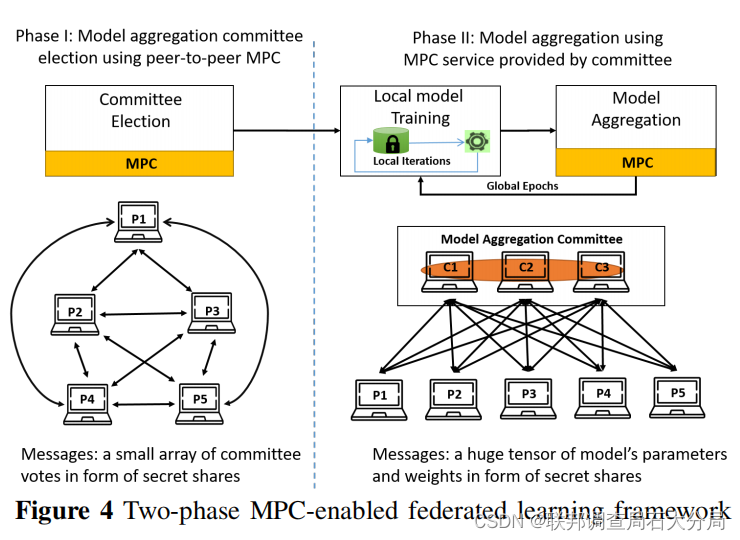
避免了大量的模型参数/权重张量的交换(在秘密共享的形式)
阶段一:使用端对端MPC来选举FL方的一个子集作为模型聚合委员会成员
阶段二:使用由委员会成员提供的MPC服务来聚合所有FL方的本地模型

D.集成联邦学习与工业物联网平台的智能制造

联邦学习可以解决集中培训机制的问题
特点如下:
①传感器/特征数据始终保存在本地
②公司在本地同时培训模型
③本地模型使用安全的MPC原型以保护
隐私
的方式进行聚合
④对模型进行迭代训练和聚合,以实现连续提高准确度
⑤联邦模型能够预测不同情况下的故障操作条件
实验设计与结果:
用例:点击故障测试
本实验中,假设所有公司都使用从传感器数据中提取的相同特征。使用PyTorch提供的神经网络(NN)模型进行故障检测。采用了简单和复杂的神经网络结构。
在简单神经网络中,只有输入层(121个特征)和输出层(2个预测结果) 大小=242
在复杂神经网络中,增加了包含60个神经元的隐藏层 规模=7380
使用Additive和Shamir秘密共享MPC协议,通过实验比较了传统的端对端和两阶段联邦学习在消息交换和执行时间方面的差异


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









