







前言
本期笔者将用强化学习算法GRPO对模型进行微调,这里假定大家已经能够实现LoRA模型的微调,我们GRPO算法修改的参数也是Lora参数。本期依旧会介绍解释基本流程,虽然不会事无巨细,但会将GRPO算法主要技术实现讲清楚。如果对于LoRA微调不了解的可以参考笔者之前的一篇博客LoRa微调。
基本流程
本期笔者通过已经进行过LoRA微调后的模型,再对其通过deepspeed进行分布式强化学习微调优化。接下来简述基本流程:
1 加载LoRA微调后模型
2 加载数据集
3 编写环境奖励函数代码
4 编写GRPO微调代码
5 记录微调时间和GPU显存的占用率。
跟之前一期一样,笔者的环境是:
1 操作系统:Linux Ubuntu 22.04
2 GPU:两块A100 80G
基础知识
Deepspeed
DeepSpeed 是由微软研究院开发的开源深度学习优化库,专为大规模模型训练与推理设计,支持 PyTorch 和 TensorFlow 等框架。它通过一系列底层优化技术,解决了分布式训练中的内存效率、计算速度、通信开销等核心问题,让训练万亿参数模型成为可能,同时降低硬件门槛和训练成本。简单来说,我们利用它可以完成分布式训练加速。
GRPO
群体相对策略优化 (GRPO) 是一种强化学习 (RL) 算法,专门用于增强大型语言模型 (LLM) 中的推理能力。与严重依赖外部评估者(critics, 评论家)指导学习的传统 RL 方法不同,GRPO 通过评估彼此相关的响应组来优化模型。这种方法可以提高训练效率,使 GRPO 成为需要复杂问题解决和长链思维的推理任务的理想选择。
加载模型
在加载模型之前,我们需要先初始化一下Deepspeed的分布式环境。
# 初始化分布式环境
if args.local_rank != -1:
deepspeed.init_distributed(dist_backend='nccl')
torch.cuda.set_device(args.local_rank)
logger.info(f"分布式训练初始化成功: rank={args.local_rank}, world_size={torch.distributed.get_world_size()}")
然后定义一个GRPOTrainer类来加载分词器和基础模型,并在基础模型之上加载LoRA权重。
self.tokenizer = AutoTokenizer.from_pretrained(self.base_model_path)
model_kwargs = {
'torch_dtype': torch.float16 if cuda_available else torch.float32,
'use_cache': False # 训练时禁用KV缓存以节省显存
}
self.model = AutoModelForCausalLM.from_pretrained(
self.base_model_path,
**model_kwargs
)
self.model = PeftModel.from_pretrained(
self.model,
self.lora_model_path
)
至此模型加载完毕,不过Lora加载的模型参数默认是不可训练的,我们需要手动将其设置为可训练。如果是lora参数,我们将它的requires_grad属性设置为True。
注意:我们修改的参数仅仅是LoRA参数,其他参数还是冻结的。
trainable_params = []
for name, param in self.model.named_parameters():
if 'lora' in name.lower():
param.requires_grad = True
trainable_params.append(param)
当然,还需要用Deepspeed进行封装模型,保证分布式训练。
ds_args = {
"model": self.model,
"model_parameters": trainable_params,
"config": ds_config
}
model_engine, optimizer, _, _ = deepspeed.initialize(**ds_args)
self.model = model_engine
self.optimizer = optimizer
加载数据集
这里的数据集预处理代码就不展示了,笔者简单提取一部分数据集进行展示,主要包含源代码source_code和参考测试代码test_code两个属性。

接下来我们加载数据集的时候,包含 prompt 、source_code以及reference_test。
# 处理数据
train_data = []
if "data" in json_data:
logger.info(f"从数据文件中找到{len(json_data['data'])}个样本")
for item in json_data["data"]:
source_code = item.get("source_code", "")
test_code = item.get("test_code", "")
if not source_code:
continue
prompt = f"请为以下Java类生成单元测试用例: ```java {source_code} ```生成的测试用例:"
train_data.append({
"prompt": prompt,
"source_code": source_code,
"reference_test": test_code
})
else:
logger.warning("未找到'data'字段,使用加载的完整数据")
train_data = json_data
编写环境代码
这里我们需要对每个生成的测试用例进行评估,返回其奖励。奖励的设置是通过不同的测试实现的,包含覆盖率测试、变异分析以及可读性测试。接下来简单介绍一下:
- 静态覆盖率变异实现方法:估算测试对源代码的覆盖程度
1 提取源代码中的方法名称
2 检查测试代码是否调用这些方法
3 计算被测试覆盖的方法比例
4 加入对断言数量的考量,每5个断言最多增加0.2的覆盖率分数
- 静态变异分析: 发现代码的缺陷
1 统计断言语句的数量和密度
2 检查边界条件测试(如null检查、等值比较、边界值测试等)
3 根据断言分数和边界条件检查综合评分
- 可读性分数:评估测试代码的清晰度和可维护性
1 分析代码长度(过短过长都不好)
2 评估注释密度和质量
3 检查命名规范
4 检查是否包含断言
我们对其设置不同的奖励权重,分别为0.4,0.3以及0.3,最后得出总奖励进行返回。
class TestGenerationEnvironment:
"""测试生成环境,用于评估生成的测试用例质量"""
def __init__(self, jacoco_path: str = None, pit_path: str = None):
self.coverage_weight = 0.4
self.mutation_weight = 0.3
self.readability_weight = 0.3
# 创建临时工作目录
self.temp_dir = tempfile.mkdtemp(prefix="test_eval_")
logger.info(f"创建临时工作目录: {self.temp_dir}")
def evaluate_test(self,
generated_test: str,
source_code: str,
reference_test: str = None) -> Tuple[float, Dict]:
"""评估生成的测试用例质量"""
logger.info("开始评估测试质量")
try:
# 静态覆盖率分析
coverage_score = self._static_coverage_analysis(generated_test, source_code)
logger.info(f"覆盖率评分: {coverage_score:.4f}")
# 静态变异分析
mutation_score = self._static_mutation_analysis(generated_test, source_code)
logger.info(f"变异测试评分: {mutation_score:.4f}")
# 计算可读性分数
readability_score = self._calculate_readability(generated_test)
logger.info(f"可读性评分: {readability_score:.4f}")
# 如果有参考测试,计算与参考测试的相似度
similarity_score = 0.0
if reference_test:
similarity_score = self._calculate_similarity(generated_test, reference_test)
logger.info(f"相似度评分: {similarity_score:.4f}")
# 计算总分
total_score = (
self.coverage_weight * coverage_score +
self.mutation_weight * mutation_score +
self.readability_weight * readability_score
)
logger.info(f"测试质量总评分: {total_score:.4f}")
# 返回总分和详细指标
return total_score, {
"coverage_score": coverage_score,
"mutation_score": mutation_score,
"readability_score": readability_score,
"similarity_score": similarity_score
}
except Exception as e:
logger.error(f"测试评估过程中出现未捕获的错误: {str(e)}")
# 返回默认评分
return 0.65, {
"coverage_score": 0.6,
"mutation_score": 0.6,
"readability_score": 0.8,
"similarity_score": 0.0,
"error": str(e)
}
编写GRPO训练代码
接下来主要是GRPO训练代码,由于训练代码过长,笔者仅仅会将其中关键技术实现单独进行讲解。
优势函数计算
对于一个prompt,我们生成num_samples个样本,分别计算其奖励,计算平均奖励作为基准值(替代价值函数),然后减去平均奖励,我们就能得到每个样本的优势函数,然后对其进行标准化。
这个方式也是GRPO的一个重要创新,通过这个方法,替代了价值函数,大大降低了显存。
# 生成测试样本
try:
generated_tests = self.generate_test(prompt, num_samples=num_samples)
logger.info(f"生成{len(generated_tests)}个测试样本完成")
except Exception as e:
logger.error(f"生成测试样本失败: {str(e)}")
return {"loss": 0, "mean_reward": 0, "mean_kl_div": 0, "num_samples": 0}
# 计算奖励
try:
rewards, metrics_list = self.compute_rewards(generated_tests, source_code, reference_test)
logger.info(f"计算样本奖励完成,平均奖励: {rewards.mean().item():.4f}")
except Exception as e:
logger.error(f"计算奖励失败: {str(e)}")
return {"loss": 0, "mean_reward": 0, "mean_kl_div": 0, "num_samples": 0}
# 计算平均奖励作为基准值(替代价值函数)
value = rewards.mean()
# 计算优势函数: 优势 = 奖励 - 价值
advantages = rewards - value
# 标准化优势,减少方差
if len(advantages) > 1 and advantages.std() > 0:
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
计算序列的对数概率
在介绍重要性采样之前,我们需要先计算一下序列的对数概率,只有这样,我们才能对不同的模型进行差异性比较。通过将输入传入模型中,我们对输出进行对数化,最终得到整个序列的对数概率。
def compute_logprobs(self, model, inputs, attention_mask=None):
"""计算序列的对数概率"""
# 准备模型输入
model_inputs = {"input_ids": input_ids}
model_inputs["attention_mask"] = attention_mask
if attention_mask is None:
attention_mask = inputs.get("attention_mask", None)
# 前向传播
with torch.set_grad_enabled(model.training):
try:
outputs = model.module(**model_inputs)
logits = outputs.logits
# 计算对数概率
logits = logits[:, :-1, :] # 去掉最后一个token的预测
labels = input_ids[:, 1:] # 去掉第一个token
attention_mask = attention_mask[:, 1:]
# 计算log softmax
log_probs = F.log_softmax(logits, dim=-1)
# 获取实际token的对数概率
token_log_probs = torch.gather(
log_probs, 2, labels.unsqueeze(-1)
).squeeze(-1)
# 应用注意力掩码
token_log_probs = token_log_probs * attention_mask
# 返回序列总对数概率
return token_log_probs.sum(dim=1)
except Exception as e:
logger.error(f"计算对数概率时发生错误: {str(e)}")
# 返回一个占位符值
return torch.tensor([0.0], device=model_device, requires_grad=model.training)
重要性采样机制和比率剪裁
重要性采样是一种统计技术,它允许我们使用一个分布(称为提议分布)的样本来估计另一个分布(目标分布)的期望值。这意味着我们可以使用旧策略生成的样本来训练和更新当前策略。
首先我们计算当前策略与旧策略之间的概率比率,取两者对数概率的差值再对其进行指数化。然后将这个比率现在在一个范围内,防止过大的更新步长导致训练不稳定,最后计算优化目标,取两者的最小值。简单来讲,**重要性采样就是放大常选择动作的正向贡献以及负向贡献,缩小不常选择动作的贡献。**代码如下:
# 计算当前策略的对数概率
current_log_prob = self.compute_logprobs(self.model, inputs)
# 计算旧策略的对数概率
with torch.no_grad():
old_log_prob = self.compute_logprobs(self.old_model, inputs)
# 计算重要性采样比率
ratio = torch.exp(current_log_prob - old_log_prob.detach())
# 比率剪裁
clipped_ratio = torch.clamp(ratio, 1 - self.cliprange, 1 + self.cliprange)
policy_loss = -torch.min(ratio * advantage, clipped_ratio * advantage).mean()
KL散度约束
为了防止模型策略变化过大,GRPO引入KL散度约束,这里我们需要一直不变的参考模型作为基准,每次用它进行约束模型策略的变化。实际的计算其实很简单,我们将其对数概率相减就能得到KL散度。
def calculate_kl_divergence(self, model_inputs):
"""计算当前策略与参考策略之间的KL散度"""
# 计算参考模型的对数概率
with torch.no_grad():
if self.ref_model is None:
# 如果参考模型不可用,使用当前模型的复制
ref_log_probs = self.compute_logprobs(self.model, model_inputs).detach()
else:
# 确保参考模型在评估模式并在正确的设备上
self.ref_model.eval()
ref_log_probs = self.compute_logprobs(self.ref_model, model_inputs)
# 计算当前模型的对数概率(保留梯度)
current_log_probs = self.compute_logprobs(self.model, model_inputs)
# 确保两个张量在同一设备上
if current_log_probs.device != ref_log_probs.device:
ref_log_probs = ref_log_probs.to(current_log_probs.device)
# KL散度计算
kl = current_log_probs - ref_log_probs.detach()
kl_mean = kl.mean()
return kl_mean
更新模型参数
最后我们将策略损失和KL散度约束相加组成损失函数,对其进行反向传播更新模型参数即可。并且更新旧策略。
# 总损失
loss = policy_loss + self.beta * kl_div
# 反向传播
try:
self.model.backward(loss)
self.model.step()
except RuntimeError as e:
logger.error(f"反向传播错误: {str(e)}")
continue
# 累加统计信息
total_loss += loss.item()
total_reward += reward.item()
total_kl_div += kl_div.item()
total_samples += 1
# 更新旧策略
if total_samples > 0:
logger.info("更新旧策略")
self.create_old_model_copy()
训练模型
由于笔者已经配置好了deepspeed的配置文件,所以命令行命令可以特别简单。
deepspeed --num_gpus=2 train_grpo.py --zs=1
本期笔者微调的模型是qwen-7B的模型,不过微调的显存消耗特别大。
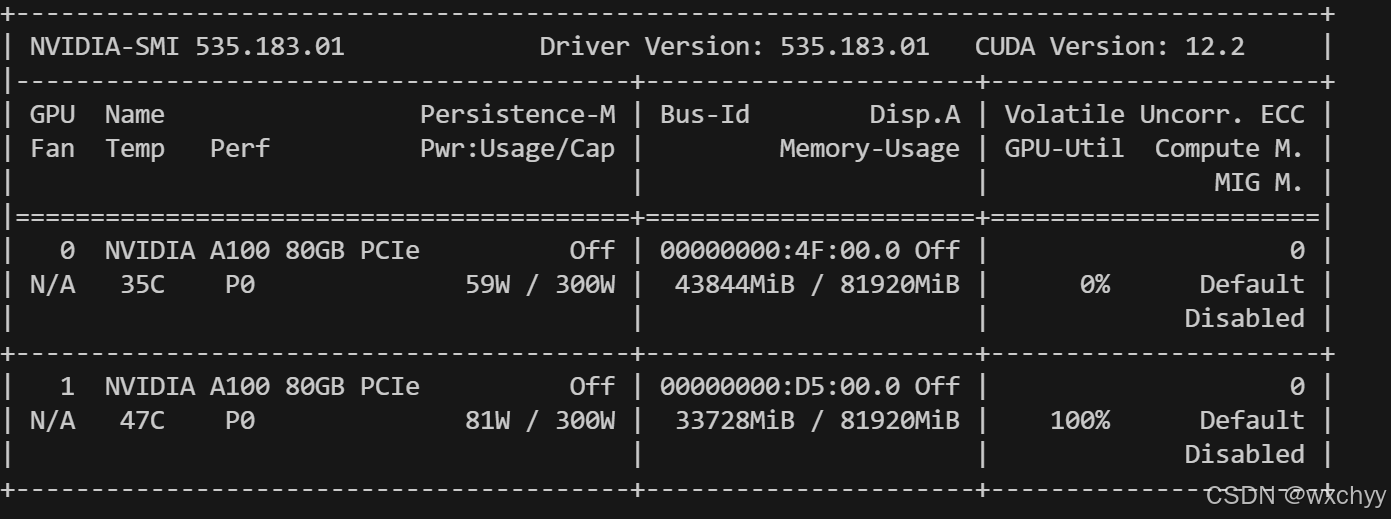
训练过程:

总结
本期主要介绍了GRPO中核心的一些技术实现,不过由于篇幅原因,代码中删除了很多基础的配置以及一些异常处理过程。
写在文末
有疑问的友友,欢迎在评论区交流,笔者看到会及时回复。
请大家一定一定要关注!!!
请大家一定一定要关注!!!
请大家一定一定要关注!!!
友友们,你们的支持是我持续更新的动力~


















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











