







Python学习 - 基础篇
Python注释
注释的作用:
- 帮助理解代码
- 提升效率,便于他人读懂代码
- 可用于调试代码
注释的方法:
- 行开头加#
#这是单行注释
- 用三个引号(单或双均可)
'''这也是一行注释'''
"""同上"""
'''
甚至可以
多行注释
'''
"""
同
上
""""
- 特殊注释(用于python2)
#!usr/bin/env python
#👆使用所分配环境的解释器
# _*_ coding:utf-8 _*_
#👆解决不支持中文的问题
Python 变量
变量就是存储数据的容器
特性:引用某个具体的数值,并且可以改变这个引用
🌰:超市储物柜和储物小票 小票才是我们所说的小票,如果小票数字换了,可以开的柜子就变了,此时变量就变了
变量的定义
- 赋值语句: 变量=值
a=1
print(a)
#打印的不是小票a,而是小票关联的唯一标识的存储内容
#1
- 变量名1,变量名2=值1,值2
a,b=2,3
print(a,b)
#2 3
- 变量1=变量2=值
a,b=3
print(a,b)
#3 3
用变量的好处:方便维护、节省空间
⚠⚠⚠
-
一个变量只能引用一个数值
-
命名规范:字母数字下划线、见名知意、驼峰标识、非关键字、区分大小写
-
变量名使用之前一定要赋值
数据类型
数据类型:对程序处理的数据分类
为什么? 为了区分存储空间;根据不同数据类型的特性,做不同的数据处理。
数据类型:
常用数据类型:
-
Numbers(数值类型):int(二进制、八进制、十进制、十六进制)、long、float、complex
-
Bool(布尔类型):True、False
-
String(字符串):‘abc’、“abc”、‘’’
字符串’‘’、“”“字符串”“”
-
List(列表)
-
Set (集合)
-
Tuple (元组)
-
Dictory(字典)
-
None Type(空类型)
查看数据类型:print(type())
print(type(6))
#<class 'int'>
result=type('6')
print(result)
#<class 'str'>
num=10
print(type(num))
#<class 'int'>
数据类型转换

🙋补充:
动态类型/静态类型
-
静态类型:类型时编译的时候确定的,后期无法修改。 如C语言
int a=10 -
动态类型:类型时运行时进行判定的,可以进行动态修改。 如python
score="123" score=123
强类型/弱类型
-
强类型:类型比较强势,不轻易随着环境的变化而变化
"a"+i #👆会报错,不会更改任一方的类型以进行运算 -
弱类型:类型比较柔弱,不同的环境下,很容易被改变
Python是属于强类型的,动态类型语言
Python运算符
算术运算符:
#- 减法运算符
print(4-12)
#-8
#* 乘法运算符
print(2*3)
#6
#** 幂运算符
print(3**5)
#243
#/ 除法运算符
print(5/2)
#2.5 #结果变成了float
print(5/0)
#ZeroDivisionError:division by zero
#// 整除运算符
print(5//2)
#2
print(5.2//2)
#2.0 #结果直接取整数,舍去小数
#% 求模运算/求余运算符
#5/2=2(1)
print(5%2)
#1
print(10%4)
#2
#= 赋值运算符
#⚠⚠⚠
#除以0
#优先级问题
# ()使用
result=(1+2)+3/4
print(result)
#2.25
整除和求余的应用场景
求行列数
num=6 #想知道标号6的行和列数
row=num//4
col=num%4
print(1+2)
#3
print("1"+"2")
#12
print([1,2]+[3,4])
#[1,2,3,4]
复合运算符:
num=10
num+=5
print(num)
#15
#*= /= **= //= %= 同理
比较运算符:
#>
#<
#!= #不等于
#<> #python2支持 等同于!=
#>= #大于等于
#<= #小于等于
#== #等于
#is #对比唯一标识
num=10
print id(num)
#1769020
a=10
b=10
print(id(a),id(b))
#35192380 35182380
print a is b
#Ture
a=[1]
b=[1]
print a==b
#True
print a is b
#False
#链状比较运算符
num=10
print 5<num<20
#True
逻辑运算符:
not、and、or
b=True
#not 非,取反,真->假;假->真
print(b)
#True
print(not b)
#False
#and 与,并且,同真则真,一假即假
#or 或,一真则真,同假才假
⚠⚠⚠
非布尔类型的值,如果作为真假来判定,一般都是非零即真,非空即真
整个逻辑表达式的结果不一定只是True和False
print(1 or False)
#1
print(bool(1))
#True
Python 输入—输出
输入
-
Python2:
raw_input
格式:result=raw_input(“提示信息”)
功能:会等待用户输入内容,直到用户按下Enter
会将用户输入的内容当作"字符串",传递给接受的变量
# _*_ conding:utf-8 _*_ content=raw_input("请输入内容") print type(content) print content #<type 'str'> #1+1 #你所键入的内容input
格式result=input(“提示信息”)
功能:会等待用户输入直到按下Enter键,会将用户输入的内容当作代码处理
可以理解为 input=raw_input+eval
content=input("请输入内容") print type(content) print content #<type 'int'> #2content="1+1" result=eval(content)#把接收到的内容当作代码进行处理 print type(result) print result -
Python3:
input 相当于Python2中的raw_input,如果想要实现Python2中input的效果,可用eval()函数。
输出
- Python2
print语句,print xxx
- Python3
print函数
print(values,sep,end,file,flush)
values:需要输出的值,多个值用”,“进行分割
sep 分隔符, 多个值被输出出来之后,值与值之间会添加指定的分隔符
end 输出完毕之后,以指定的字符结束,默认为换行"\n"
file 表示输出的目标,默认是标准的输出(控制台),还可以是一个可写入的文件句柄
flush 表示立即输出的意思,值为Bool类型
🌰:
#Python 2
#_*_ coding:utf-8 _*_
#输出一个值
print 123
#输出一个变量
num=10
print num
#输出多个变量
num2=66
print num,num2
#格式化输出
name="sz"
age=18
#我的名字是xxx,年龄是xxx
print "我的名字是",name,"年龄是",age
print "我的名字是%s,年龄是%d"%(name,age)
print "我的名字是{0},年龄是{1}".format(name,age)
#{0}是指这个地方填入第一个值
#输出到文件中
f=open("test.txt","w")#打开文件test.txt
print >>f,"xxxxxxxxx"
#运行后,如果有文件就是把xxxxxxxxx写入文件
#如果没有文件就是新建文件并写入xxxxxxxxx
#输出不自动换行
print "1",
print "2",
print "3",
#1 2 3
#输出的各个数据,使用分隔符分割
print "a","b","c"
#a b c
print "-".join(["a","b","c"])
#a-b-c
#Python 3
#输出一个值
print(123)
#123
#输出一个变量
num=55
print(num)
#55
#输出多个变量
num2=44
print(num,num2)
#55 44
#格式化输出
name='sz'
age=18
#我的名字是xxx,年龄是xxx
print("我的名字是%s,年龄是%d"%(name,age))
print("我的名字是{0},年龄是{1}".format(name,age))
#输出到文件当中
f=open("test.txt","w")
print ("xxxxx",file=f)
#输出不自动换行
print("abc",end="")
#输出的各个数据,使用分隔符分割
print('a','b','c',sep="&&&")
#a&&&b&&&c
#flush参数的说明 对比以下情况
from time import sleep
print("请输入账号",end="")
##休眠5s
sleep(5)
print("xxx")
from time import sleep
print("请输入账号\n")
##休眠5s
sleep(5)
print("xxx")
from time import sleep
print("请输入账号")
##休眠5s
sleep(5)
print("xxx")
from time import sleep
print("请输入账号",end="",flush=True)
##休眠5s
sleep(5)
print("xxx")
补充:
占位格式符
格式:%[(name)][flags][width][.precision]typecode
使用中括号包含的部分,代表可选
解释:
(name):用于选择指定的名称对应的值
flags:
-
空:表示右对齐
- - :表示左对齐
- 空格:表示在正数左侧填充一个空格,从而与负数对齐
- 0 :表示用0填充
width:表示显示宽度
.precision:表示小数点后精度
#格式化输出
#我的名字是xxx,年龄是xxx
print("我的名字是%s,年龄是%d"%(name,age))
#%[(name)][flags][width][.precision]typecode
#[]:可以省略
#(name) 表示根据制定的名称(key),查找对应的值,格式化到字符串当中
matchscore=59
englishscore=58
#print("我的数学分数为%d,英语分数为%d"%(mathscore,englishscore))
#print("我的数学分数为%d,英语分数为%d"%(englishscore,mathscore))
#print("我的数学分数为%(ms)d,英语分数为%(es)d"%("es":englishscore,"ms":mathscore))
#width 表示占用的宽度
print("%-10d"%mathscore)
print("% d"%mathscore)
min=5
sec=8
print("%2d:%2d%(min,sec))
# 5: 8
print("%02d:0%2d%(min,sec))
#05:08 #补0是12
score=59.9
print("%.2f"%score)
#59.90
print("%i"%score)
#59
print("%d"%0x10)
#16

Python小案例
案例:采集一个人的身高,体重,年龄和性别,告诉Ta,自己的体质率是否在正常范围之内
BMI=体重(kg)/(身高*身高)(米)
体脂率=1.2*BMI+0.23*年龄-5.4-10.8*性别(男:1 女:0)
正常成年人的体脂率分别是男性15%~18%和女性25%~28%
功能分析:
- 输入 身高 体重 年龄 性别
- 处理数据 计算体脂率,
- 输出
# 输入
# 身高
# personHeight = float(input("请输入身高(m):"))
# # 体重
# personWeight = float(input("请输入体重(kg):"))
# # 年龄
# personAge = int(input("请输入年龄:"))
# # 性别
# personSex = int(input("请输入性别(男:1 女:0):"))
personHeight = input("请输入身高(m):")
personHeight = float(personHeight)
# 体重
personWeight = input("请输入体重(kg):")
personWeight = float(personWeight)
# 年龄
personAge = input("请输入年龄:")
personAge = int(personAge)
# 性别
personSex = input("请输入性别(男:1 女:0):")
personSex = int(personSex)
# 处理数据
# 计算体脂率
# BMI=体重(kg)/(身高*身高)(米)
# 体脂率=1.2*BMI+0.23*年龄-5.4-10.8*性别(男:1 女:0)
BMI = personWeight/(personHeight*personHeight)
TZL = 1.2*BMI+0.23*personAge-5.4-10.8*personSex
# 判定体脂率,是否在正常的标准范围之内
# 正常成年人的体脂率分别是男性15%\~18%和女性25%\~28%
# TZL MIN MAX
# 0.10 1 0
minNum = 15+10*(1-personSex)
maxNum = 18+10*(1-personSex)
result = minNum < TZL < maxNum
# 输出
# 告诉用户,是否正常
print("你的体脂率,是否符合标准:", result)
print("你的体脂率:", TZL)
'''请输入身高(m):1.6
请输入体重(kg):58
请输入年龄:21
请输入性别(男:1 女:0):0
你的体脂率,是否符合标准: True
你的体脂率: 26.6175'''
Python分支
if语法
单分支判断:
if 条件:
条件满足时,执行语句…
age=17
if age>=18:
print("你已经成年")
双分支判断:
if 条件:
条件满足时,执行语句…
else:
条件不满足时,执行语句…
age=17
if age>=18:
print("你已经成年")
else:
print("你还未成年")
#你还未成年
练习:
# 根据分数区间,打印出对应的级别
# 大于等于90 并且小于100
# 优秀
# 大于等于80 并且小于90
# 良好
# 大于等于60 并且小于80
# 及格
# 大于等于0 并且小于60
# 不及格
score=59
# if score>=90 and score <=100:
# print("优秀")
# if score>=80 and score <90:
# print("良好")
# if score>=60 and score<80:
# print("及格")
# if score >=0 and score<60:
# print("不及格")
# if 90 <=score <=100:
# print("优秀")
# if 80 <= score <90:
# print("良好")
# if 60<= score<80:
# print("及格")
# if 0<= score<60:
# print("不及格")
#if 嵌套
if 90 <=score<=100:
print("优秀")
else:
if 80<=score<90:
print("良好")
else:
if 60<=score<80:
print("及格")
else:
if 0<=score<60:
print("不及格")
多分支判断
if 条件:
条件满足时,执行语句…
elif 条件:
条件满足时,执行语句…
else:
以上条件都不满足时,执行语句…
if 90 <=score<=100:
print("优秀")
elif 80<=score<90:
print("良好")
elif 60<=score<80:
print("及格")
elif 0<=score<60:
print("不及格")
🌰:
优化"体脂率计算案例"
输入
部分容错处理
身高范围 0<身高<3
体重 0<体重<300
年龄 0<年龄<150
性别 是1或者0
数据处理
针对男女的判定标准,分别进行判断,而不是通过找规律计算出最大最小值,进行判断
输出
结果提示优化
男/女 先生你好 女士你好
正常/不正常 恭喜您,身体非常健康,请继续保持
请注意,您的身体偏瘦/胖
# 输入
# 身高
personHeight = float(input("请输入身高(m):"))
# 体重
personWeight = float(input("请输入体重(kg):"))
# 年龄
personAge = int(input("请输入年龄:"))
# 性别
personSex = int(input("请输入性别(男:1 女:0):"))
# 容错处理,数据有效性的验证
if not (0 < personHeight < 3 and 0 < personWeight < 300 and 0 < personAge < 150 and (personSex == 0 or personSex == 1)):
print("数据不符合标准,程序退出")
exit()
# 处理数据
# 计算体脂率
# BMI=体重(kg)/(身高*身高)(米)
# 体脂率=1.2*BMI+0.23*年龄-5.4-10.8*性别(男:1 女:0)
BMI = personWeight/(personHeight*personHeight)
TZL = 1.2*BMI+0.23*personAge-5.4-10.8*personSex
TZL /= 100
# 判定体脂率,是否在正常的标准范围之内
# 正常成年人的体脂率分别是男性15%\~18%和女性25%\~28%
# TZL MIN MAX
# 0.10 1 0
# 区分男女
# personSex 1 0
if personSex == 1:
# 判定男性标准的代码
result = 0.15 < TZL < 0.18
else:
# 判定女性标准的代码
result = 0.25 < TZL < 0.28
# minNum = 15+10*(1-personSex)
# maxNum = 18+10*(1-personSex)
# result = minNum < TZL < maxNum
# 输出
# 告诉用户,是否正常
# print("你的体脂率,是否符合标准:", result)
# print("你的体脂率:", TZL)
#问好
if personSex==1:
wenhao ="先生你好:"
minNum=0.15
maxNum=0.18
elif personSex==0:
wenhao ="女士你好:"
minNum=0.25
maxNum=0.28
#提示部分
if result:
notice="恭喜您,身体非常健康,请继续保持"
else:
if TZL>maxNum:
notice="请注意,您的身体不正常,偏胖"
else:
notice="请注意,您的身体不正常,偏瘦"
print(wenhao,notice)
Python循环
循环:周而复始,重复性的做某些事情
生活场景:一天24H 一周7天 一年四季
编程场景:想要多次重复执行某些操作的时候
想要便利一个集合的时候
- while循环
一般使用
语法:
while 条件:
条件满足时的执行代码
…
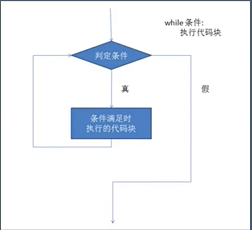
流程图示:
🌰:
打印10遍 “你真棒!”
#while #一定要注意,写循环的时候要考虑号循环的结束 #修改条件 #打断循环,break #num=0 #condition=True #while condition: # print("你真棒!") # num+=1 # if num==10: # condition =False num=10 #while num!=10: while num<10: print("你真棒!") num+=1
与else连用
while 条件:
条件满足时执行的代码
…
else:
条件不满足时执行的代码
…
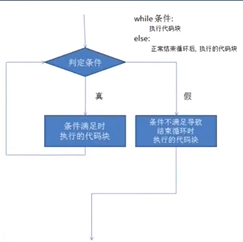
流程图示:
num=0 while num<10: num+=1 print("num:",num) else: print("整个循环,已经完美的执行完毕") '''num: 1 num: 2 num: 3 num: 4 num: 5 num: 6 num: 7 num: 8 num: 9 num: 10 整个循环,已经完美的执行完毕'''
⚠⚠⚠
- 一定要注意循环结束条件,防止死循环
- 在Python中,没有类似于其他语言的do…while循环
- for循环
使用场景 重复性的执行一些操作,更多的是遍历一个集合
一般使用
语法
for x in xxx:
循环语句
# 遍历一个集合 # 字符串,列表 notice = "把不学习的都抓起来" for c in notice: print(c) ''' 把 不 学 习 的 都 抓 起 来 ''' pets = ['大汪', '二汪', '汪汪'] for name in pets: print(name) ''' 大汪 二汪 汪汪 '''
与else的连用同while循环
🌰:
# 反转字符串
# 源字符串
# "好好学习,天天向上"
# 反转后
# "上向天天,习学好好"
notice = "好好学习,天天向上"
# 拆字
result = ""
for c in notice:
# result += c #result=result+c
result = c + result
# print(c)
print(result)
# 打印1-100之间的偶数
# 1-100的集合
# 函数 -> range
# 怎样去判定一个数值,是偶数
for num in range(1, 101):
if num % 2 == 0:
print(num)
-
Python循环打断-break&continue
循环打断对else的影响:
如果循环正常执行完毕,则会执行else部分
如果中途是因为打断而退出循环,则不会执行else部分
break:打断本次循环,跳出整个循环
continue:结束本次循环,继续执行下次循环
🌰:
for i in range(1, 11):
if i == 6:
break
print(i)
'''
1
2
3
4
5
'''
# 做一个简单的加法计算器,让用户输入两个数值,输出对应的和
# 要求
# 用户如果不退出这个程序,则输出完毕之后,继续让用户使用
# 如果中间用户输入的数据有误,则给出错误提示,并从头开始,让用户输入数值
# 1 2 >100 报错
while True:
# 1.让用户输入两个数值
num1 = float(input("请输入第一个数值:"))
num2 = float(input("请输入第二个数值:"))
if num1 > 100 or num2 >100:
print("你输入的数据有问题,请重新输入")
continue
# 2.计算两个数值的和
result = num1 + num2
# 3.输出结果
print("你计算的结果是:", result)
isQ = input("是否想要退出(q:退出,其他:不退出,继续)")
if isQ == 'q':
break
🌰: 循环内嵌套循环
打印九九乘法表
# 给定一个数值,打印出,从1到这个数值之间的所有数字
for num in range(1, 10):
# 1.各一个集合
nums = range(1, num + 1)
# 2.遍历集合
for n in nums:
# 3.在遍历的过程中,打印每一个元素
# print(n)
# x * x = x
print("%d * %d = %d" % (n, num, n * num), end="\t")
print("")#空串可以实现默认的换行
🌰 分支循环
用户输入一个三位数之,判定是否是水仙花数
while True:
# 1.准备一个3位数的数值
# 1.1 让用户输入数据
from unittest import result
num = int(input("请输入一个3位数值:"))
# 1.2 数据有效性的验证(保证数值,是三位数)
# print(num)
if not (100 <= num <= 999):
print("你输入的数据无效,直接退出程序")
exit()
print("进到这一行,就代表,数据肯定有效")
# 2.根据这个三位数 判定是否是水仙花数
# 百位的3次方 + 十位的3次方 + 个位的3次方
# = 数值本身
# 2.1 分解数值 -> 百位,十位,个位
# 123 = 1, 2, 3
# print(123 // 100)
# 1
# print(123 % 100 // 10)
# 2
baiwei = num // 100
shiwei = num % 100 // 10
gewei = num % 10
# 2.2 直接套入公式,判定是否为水仙花数
result = baiwei ** 3 + shiwei ** 3 + gewei ** 3 == num
# 3.打印结果
# 直接打印判定好的结果
if result:
print("%d,是水仙花数" % num)
else:
print("%d,不是水仙花数" % num)
猜数字
# 1.准备数据
num = 500
count = 0
while True:
# 2.数据处理
count += 1
# 2.1 让用户输入一个结果
result = input("请输入结果:")
result = int(result)
# 2.2 拿用户新输入的数值,和给定的一个数值进行比对
# 2.2.1 如果是相等 -> 给出一个正确的提示 然后结束程序
if result == num:
print("恭喜你,猜对了,答案就是%d,你总共猜了%d次" % (result, count))
# exit()
break
# else:
# 2.2.2 如果值,不相等
# 2.2.2.1 判定数值关系,给出不同的提示
# 2.2.2.1.1 如果大于 -> 你猜的数字,太大了,应该小一点
if result > num:
print("你猜的数字,太大了,应该小一点")
# 2.2.2.1.2 如果小于 -> 你猜的数字,太小了,应该大一点
else:
print("你猜的数字,太小了,应该大一点")
# 2.2.2.2 让用户继续猜
Python常用数据类型操作
-
数值
表现形式:整数(int)浮点数(float)复数(complex)
⚠ Python3的整型,可以自动调整大小,当作long类型使用

num = 18 # 十进制转二进制 print(bin(num)) # 十进制转八进制 print(oct(num)) # 十进制转十六进制 print(hex(num))常用操作
几乎适合Python运算符 算术\复合\比较\逻辑运算符
数学函数
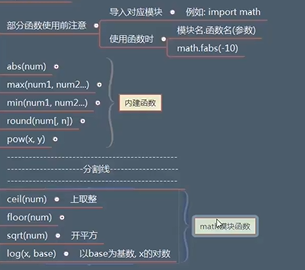
随机函数
import random from scipy import rand # random() # [0,1) # 范围之内的随机小数 print(random.random()) # choice(seq) # 从一个序列中,随机挑选一个数值 # random.choice((1,3,6,8)) seq = [1, 3, 5, 6, 8, 9] print(random.choice(seq)) # uniform(x, y) # [x, y] # 范围之内的随机小数 print(random.uniform(1,3)) # randomint(x, y) # [x, y] # 范围之内的随机整数 print(random.randint(1, 3)) # randrange(start, stop=None, step=1) # 给定区间内的一随机整数 # [start, stop) print(random.randrange(1, 14,))三角函数
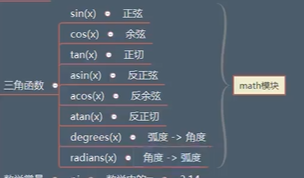
from cmath import pi import math # 正弦函数 # sin(x),x参数所接收的是一个弧度角度 # pi = 180 # 角度 / 180 * pi # hudu = 30 / 180 * pi hudu = math.degrees(30) result = math.sin(hudu) print(result)数学常量 pi 数学中的 π \pi π
-
布尔
bool : True False
拥有int类型的某一部分特性
print(True + 2) # 3 print(False +2) # 2 result = issubclass(bool, int) print(result) # True -
字符串
概念:由单个字符组成的一个集合
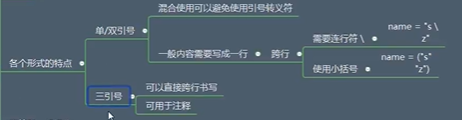
形式:
非原始字符串
# 非原始字符串 # 使用单引号包含的 # 'abc' str1 = 'aaa' print(str1, type(str1)) # 使用双引号包含的 # "abc" str2 = "abc" print(str2, type(str2)) # 使用三个单引号包含的 # '''abc''' str3 = '''abc''' print(str3, type(str3)) # 使用三个双引号包含的 # """abc""" str4 = """abc""" print(str4, type(str4))转义字符

str1 = """a\naa""" print(str1, type(str1)) str1 = """a\taa""" print(str1, type(str1)) ''' a aa <class 'str'> a aa <class 'str'> ''' name = "s"\ "z"\ "123" print(name) # sz123 name = "我是 \\n sz" print(name) # 我是 \n sz原始字符串:非原始字符串前加r
输入什么就会输出什么,不用加转义符
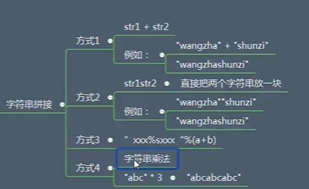
字符串的一般操作
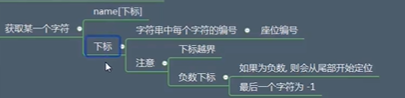
字符串切片
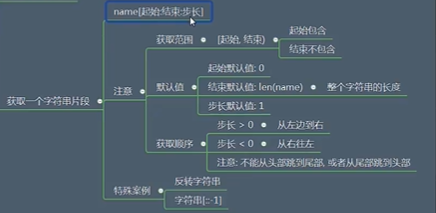
字符串函数操作
使用方式:带🚩的是内建函数,直接使用,不带的属于对象方法 对象.方法(参数)
查找计算
🚩len
find
rfilnd
index
count
转换
replace
capitalize
title
lower
upper
填充压缩
ljust
rjust
center
lstrip
rstrip
分割拼接
split
partition
rpartition
splitlines
join
判定
isalpha
isdigit
isalnum
isspace
startswith
endswith
# -------------字符串函数查找操作----------------- # len # 作用 # 计算字符串的字符个数 # 语法 # len(name) # 参数 # 字符串 # 返回值 # 整数 # 字符个数 # name = "我是sz\n" # num = len(name) # print(num) # 5 # find # 作用 # 查找子串索引(下标)位置 # 语法 # find(sub, start=0, end=len(str)) # 参数 # 参数1-sub # 需要检索的字符串 # 参数2-start # 检索的起始位置 可省略,默认0 # 参数2-end # 检索的结束位置 可省略,默认len(str) # 返回值 # 找到了 # 指定索引 # 整型 # 找不到 # -1 # 注意 # 从左到右进行查找 # 找到后立即停止 # [start, end) from unittest import result name = "wo shi sz" # num = name.find("s") # print(num) # # 3 # num = name.find("sz") # print(num) # #7 # num = name.find("s", 4) # print(num) # # 7 # num = name.find("s", 4, 7) # print(num) # # -1 # rfind # 功能使用,同find # 区别 # 从右往左进行查找 # num = name.rfind("s") # print(num) # # 7 # index # 作用 # 获取子串索引位置 # 语法 # find(sub, start=0, end=len(str)) # 参数 # 参数1-sub # 需要检索的字符串 # 参数2-start # 检索的起始位置 可省略,默认0 # 参数2-end # 检索的结束位置 可省略,默认len(str) # 返回值 # 找到了 # 指定索引 # 整型 # 找不到 # 异常 # 注意 # 从左到右进行查找 # 找到后立即停止 # [start, end) # num = name.index("s") # print(num) # # 3 # rindex # 功能使用,同find # 区别 # 从右往左进行查找 # num = name.rindex("s") # print(num) # # 7 # count # 作用 # 计算某个字符串的出现个数 # 语法 # count(sub, start=0, end=len(str)) # 参数 # 参数1-sub # 需要检索的字符串 # 参数2-start # 检索的起始位置 可省略,默认0 # 参数2-end # 检索的结束位置 可省略,默认len(str) # 返回值 # 子字符串出现的个数 # 整型 # print(name.count('s')) # 2 # -------------字符串函数转换操作----------------- # replace # 作用 # 使用给定的新字符串,替换原字符串中的旧字符串 # 语法 # replace(old, new[, count]) # 参数 # 参数1-old # 需要被替换掉的旧字符串 # 参数2-new # 替换后的新字符串 # 参数3-count # 替换掉个数 # 可省略,表示替换全部 # 返回值 # 替换后的结果字符串 # 注意 # 并不会修改原字符串本身 # print(name.replace("s", "z")) # print(name) # print(name.replace("s", "z", 1)) # print(name) # # wo zhi zz # # wo shi sz # # wo zhi sz # # wo shi sz # capitalize # 作用 # 将字符串首字母变为大写 # 语法 # capitalize() # 参数 # 无 # 返回值 # 首字符大写后的新字符串 # 注意 # 并不会修改原字符串本身 # print(name.capitalize()) # print(name) # # Wo shi sz # # wo shi sz # title # 作用 # 将字符串的每个单词首字母大写 # 语法 # title() # 参数 # 无 # 返回值 # 每个单词首字符大写后的新字符串 # 注意 # 并不会修改原字符串本身 # name = 'wo shi-sz+szz-qq%yy' # print(name.title()) # print(name) # Wo Shi-Sz+Szz-Qq%Yy # # wo shi-sz+szz-qq%yy # lower # 作用 # 将字符串每个字符都变为小写 # 语法 # lower() # 参数 # 无 # 返回值 # 全部变为小写后的字符串 # 注意 # 并不会修改原字符串本身 # print(name.lower()) # print(name) # # wo shi sz # # wo shi sz # upper # 作用 # 将字符串每个字符都变为大写 # 语法 # upper() # 参数 # 无 # 返回值 # 全部变为大写后的字符串 # 注意 # 并不会修改原字符串本身 # print(name.upper()) # print(name) # # WO SHI SZ # # wo shi sz # -------------字符串函数填充压缩操作----------------- # ljust # 作用 # 根据指定字符(1个),将原字符串填充够指定长度 # l # 表示原字符串靠左 # 语法 # ljust(width, fillchar) # 参数 # 参数1-width # 指定字符串的长度 # 参数2-fillchar # 如果原字符串 < 指定长度时 # 填充过去的字符 # 返回值 # 填充完毕的结果字符串 # 注意 # 不会修改原字符串 # 填充字符的长度位1 # 只有原字符串长度 < 指定结果长度时才会填充 # name = "abc" # print(name.ljust(6, "x")) # print(name) # # abcxxx # # abc # name = 'acdf' # print(name.ljust(2, 'x')) # print(name) # # acdf # # acdf # rjust # 作用 # 根据指定字符(1个),将原字符串填充够指定长度 # l # 表示原字符串靠右 # 语法 # rjust(width, fillchar) # 参数 # 参数1-width # 指定字符串的长度 # 参数2-fillchar # 如果原字符串 < 指定长度时 # 填充过去的字符 # 返回值 # 填充完毕的结果字符串 # 注意 # 不会修改原字符串 # 填充字符的长度位1 # 只有原字符串长度 < 指定结果长度时才会填充 # name = "abcdefg" # print(name.rjust(16, "x")) # print(name) # # xxxxxxxxxabcdefg # # abcdefg # center # 作用 # 根据指定字符(1个),将原字符串填充够指定长度 # l # 表示原字符串居中 # 语法 # center(width, fillchar) # 参数 # 参数1-width # 指定字符串的长度 # 参数2-fillchar # 如果原字符串 < 指定长度时 # 填充过去的字符 # 返回值 # 填充完毕的结果字符串 # 注意 # 不会修改原字符串 # 填充字符的长度位1 # 只有原字符串长度 < 指定结果长度时才会填充 # name = 'abcde' # print(name.center(15, 'x')) # print(name) # print(name.center(16, 'x')) # print(name) # # xxxxxabcdexxxxx # # abcde # # xxxxxabcdexxxxxx # # abcde # lstrip # 作用 # 移除所有原字符串指定字符(默认为空白字符) # l # 表示仅仅只移除左侧 # 语法 # lstrip(chars) # 参数 # 参数-chars # 需要移除的字符串 # 表现形式为字符串 # "abc" # 表示,"a"|"b"|"c" # 返回值 # 移除完毕的结果字符串 # 注意 # 不会修改原字符串 name = " wo shi sz " # print(name.strip()) # print(name) # # wo shi sz # # wo shi sz # print("|" + name.lstrip() + "|") # print("|" + name + "|") # |wo shi sz | # | wo shi sz | name = 'wowoooo' # print("|" + name.lstrip('wo') + "|") # print("|" + name + "|") # # || # # |wowoooo| # rstrip # 作用 # 移除所有原字符串指定字符(默认为空白字符) # r # 表示仅仅只移除右侧 # 语法 # rstrip(chars) # 参数 # 参数-chars # 需要移除的字符串 # 表现形式为字符串 # "abc" # 表示,"a"|"b"|"c" # 返回值 # 移除完毕的结果字符串 # 注意 # 不会修改原字符串 # name = "wowowowa" # print(name.rstrip("wo")) # print(name) # # wowowowa # # wowowowa # -------------字符串函数分割拼接操作----------------- # split # 作用 # 将一个大的字符串分割成及格字符串 # 语法 # split(sep, maxsplit) # 参数 # 参数1-sep # 分隔符 # 参数2-maxsplit # 最大的分割次数 # 可省略,有多少分割多少 # 返回值 # 分割后的子字符串组成的列表 # list 列表类型 # 注意 # 并不会修改原字符串本身 info = "sz-18-180-0558-1234567" # result = info.split("-") # print(result) # print(info) # # ['sz', '18', '180', '0558', '1234567'] # # sz-18-180-0558-1234567 # result = info.split("-", 3) # print(result) # print(info) # # ['sz', '18', '180', '0558-1234567'] # # sz-18-180-0558-1234567 # partition # 作用 # 根据指定的分隔符,返回(分隔符左侧的内容,分隔符,分隔符右侧内容) # 语法 # partition(sep) # 参数 # 参数-sep # 分隔符 # 返回值 # 如果查找到分隔符 # (分隔符左侧内容,分隔符,分隔符右侧内容) # tuple 类型 # 如果没有查找到分隔符 # (原字符串, "", "") # tuple 类型 # 注意 # 并不会修改原字符串本身 # 从左侧开始查找分隔符 # result = info.partition("-") # print(result) # print(info) # # ('sz', '-', '18-180-0558-1234567') # # sz-18-180-0558-1234567 # result = info.partition('|') # print(result) # print(info) # # ('sz-18-180-0558-1234567', '', '') # # sz-18-180-0558-1234567 # rpartition # 作用 # 根据指定的分隔符,返回(分隔符左侧的内容,分隔符,分隔符右侧内容) # r # 表示从哟测开始查找分隔符 # 语法 # rartition(sep) # 参数 # 参数-sep # 分隔符 # 返回值 # 如果查找到分隔符 # (分隔符左侧内容,分隔符,分隔符右侧内容) # tuple 类型 # 如果没有查找到分隔符 # (原字符串, "", "") # tuple 类型 # 注意 # 并不会修改原字符串本身 # 从右侧开始查找分隔符 # result = info.rpartition('-') # print(result) # print(info) # # ('sz-18-180-0558', '-', '1234567') # # sz-18-180-0558-1234567 # splitlines # 作用 # 根据换行符(\r, \n),将字符串拆成多个元素,保存到列表中 # 语法 # splitlines(keepends) # 参数 # 参数-keepends # 是否保留换行符 # bool 类型 # 返回值 # 被换行符分割的多个字符串,作为元素组成的列表 # list 类型 # 注意 # 并不会修改原字符串本身 name = 'wo \n shi \r sz' # result = name.splitlines() # print(result) # print(name) # # ['wo ', ' shi ', ' sz'] # # wo # # szi # result = name.splitlines(True) # print(result) # print(name) # # ['wo \n', ' shi \r', ' sz'] # # wo # # szi # join # 作用 # 根据指定字符串,将给定的可迭代对象,进行拼接,得到拼接后的字符串 # 语法 # join(iterable) # 参数 # iterable # 可迭代的对象 # 字符串 # 元组 # 列表 # ... # 返回值 # 拼接好的新字符串 # 注意 # 并不会修改原字符串本身 # items = ["sz", "18", "shanghai"] # result = '-'.join(items) # print(result) # print(items) # # sz-18-shanghai # # ['sz', '18', 'shanghai'] # -------------字符串函数分割拼接操作----------------- # isalpha # 作用 # 字符串中是否所有的字符都是字母 # 不包含数字,特殊符号,标点符号等 # 至少有一个字符 # 语法 # isalpha() # 参数 # 无 # 返回值 # 是否全是字母 # bool 类型 # name = "sz" # print(name.isalpha()) # # True # name = " zs" # isdigit # 作用 # 字符串中是否所有的字符都是数字 # 不包含字母,特殊符号,标点符号等 # 至少有一个字符 # 语法 # isdigit() # 参数 # 无 # 返回值 # 是否全是数字 # bool 类型 # name = "12" # print(name.isdigit()) # # True # isalnum # 作用 # 字符串中是否所有的字符都是字母或数字 # 不包含特殊符号,标点符号等 # 至少有一个字符 # 语法 # isalnum() # 参数 # 无 # 返回值 # 是否全是字母 # bool 类型 # ispace # 作用 # 字符串中是否所有的字符都是空白符 # 包含空格,缩进,换行等不可见转义文字 # 至少有一个字符 # 语法 # isspace() # 参数 # 无 # 返回值 # 是否全是字母 # bool 类型 # startswith # 作用 # 判定一个字符串是否以某个前缀开头 # 语法 # startswith(prefix, start=0, end=len(str)) # 参数 # 参数1-prefix # 需要判定的前缀字符串 # 参数2-start # 判定起始位置 # 参数3-end # 判定结束位置 # 返回值 # 是否以指定前缀开头 # bool 类型 name = "2018-02-02: 某某.xls" # print(name.startswith("20")) # # True # print(name.startswith('20', 1, 4)) # # False # endswith # 作用 # 判定一个字符串是否以某个后缀开头 # 语法 # startswith(suffix, start=0, end=len(str)) # 参数 # 参数1-suffix # 需要判定的后缀字符串 # 参数2-start # 判定起始位置 # 参数3-end # 判定结束位置 # 返回值 # 是否以指定前缀开头 # bool 类型 # print(name.endswith(".xls")) # # True # 补充 # in # 判定一个字符串,是否被另一个字符串包含 # not in # 判定一个字符串,是否不被另一个字符串包含 print("sz" in " wo shi szz") print("sz" not in " wo shi szz") # True # False -
列表
概念: 有序可变的元素集合
定义:
方式1 [元素1,元素2…]
如: nums = [1, 2, 3, 4, 5
方式2
列表生成式
nums = range(99) print(nums)列表推导式

nums = [1, 3, 5, 7] resultlist = [num + 1 for num in nums] print(resultlist) # [2, 4, 6, 8] nums = [1, 2, 3, 4, 5] resultlist = [num ** 2 for num in nums if num % 2 != 0] print(resultlist) # [1, 9, 25]列表的嵌套 列表中的元素还可以是列表
⚠:注意和c语言中数组的区别:是否可以存放不同的数据类型
int nums[] = [1, 2, 3, 4]nums = ['a', 1, ['a', 'b', 'c']]常用操作
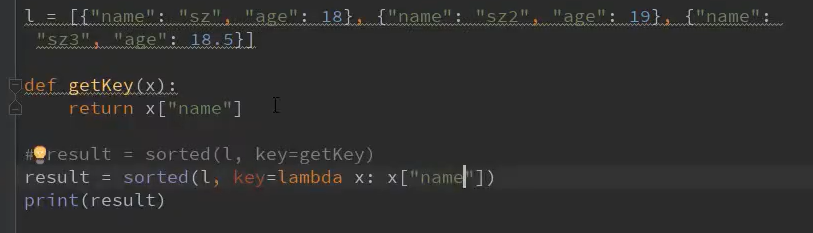
# --------------------------------增加操作-------------------------------------- # 增 # append # 作用 # 往列表中,增加一个新的元素 # 在列表的最后 # 语法 # l.append(object) # 参数 # object # 想要添加的元素 # 返回值 # None # 注意 # 会直接修改列表 # # nums = [1, 2, 3, 4] # print(nums) # print(nums.append(5)) # print(nums) # # [1, 2, 3, 4] # # None # # [1, 2, 3, 4, 5] # insert # 作用 # 往列表中,增加一个新的元素 # 在指定索引前面 # 语法 # l.insert(index,object) # 参数 # index # 索引,到时会插入到这个索引之前 # object # 想要添加的元素 # 返回值 # None # 注意 # 会直接修改列表 from audioop import reverse import collections import enum from operator import index from os import remove import re from typing import Iterable from unittest import result from sklearn.utils import resample from sqlalchemy import values # nums = [1, 2, 3, 4] # print(nums) # print(nums.insert(0, 5)) # # print(nums) # # [1, 2, 3, 4] # # None # # [5, 1, 2, 3, 4] # extend # 作用 # 往列表中,扩展一个可迭代序列 # 语法 # l.extend(interable) # 参数 # iterable # 可迭代集合 # 字符串 # 列表 # 元组 # ... # 返回值 # None # 注意 # 会直接修改列表 # 和append的区别 # extend可以算是两个集合的拼接 # append是吧一个元素加到另一个元素中去 # nums1 = [1, 2, 3, 4] # nums2 = ['a', 'b', 'c'] # print(nums1.extend(nums2)) # print(nums1) # # None # # [1, 2, 3, 4, 'a', 'b', 'c'] # nums1 = [1, 2, 3, 4] # nums2 = ['abbv', 'b', 'c'] # print(nums1.extend(nums2)) # print(nums1) # # None # # [1, 2, 3, 4, 'abbv', 'b', 'c'] # # nums1 = [1, 2, 3, 4] # nums2 = ['abbv', 'b', 'c'] # print(nums1.append(nums2)) # print(nums1) # # None # # [1, 2, 3, 4, ['abbv', 'b', 'c']] # --------------------------------删除操作-------------------------------------- # 删 # del语句 # 作用 # 可以删除一个指定元素(对象) # 语法 # del 指定元素 # 注意 # 可以删除整个列表 # 删除一个变量 # 也可以删除某个元素 # nums = [1, 2, 3, 4, 5] # del nums[1] # print(nums) # [1, 3, 4, 5] # num = 66 # del num # print(num) # # 发生异常: NameError # # name 'num' is not defined # pop # 作用 # 移除并返回列表中指定索引的值 # 语法 # l.pop(index=-1) # 参数 # index # 需要被删除返回的元素索引 # 默认为-1 # 返回值 # 被删除的元素 # 注意 # 会直接修改原数组 # 注意索引越界 # nums = [1, 2, 3, 4, 5] # result = nums.pop(3) # print(nums) # remove # 作用 # 移除列表中指定索引的元素 # 语法 # l.remove(object) # 参数 # object # 需要被删除的元素 # 返回值 # None # 注意 # 会直接修改原数组 # 如果元素不存在 会报错 # 如果存在多个元素 只会删一个 # nums = [1, 2, 3, 4, 5] # result = nums.remove(2) # print(result) # print(nums) # # None # # [1, 3, 4, 5] # 改 # names[index] = 666 # 当想操作列表中某个元素时,一定是通过下标来索引 # nums = [1, 2, 3, 4, 5] # nums[2] = 6 # print(nums) # # [1, 2, 6, 4, 5] # --------------------------------查询操作-------------------------------------- # 获取某个元素 # items[index] # 注意负索引 # nums = range(10) # print(nums[5]) # # 5 # 获取元素的索引 # index() # nums = [3, 4, 5, 6, 7, 5, 8, 9] # idx = nums.index(5, 3) # 指定区间从索引3开始 # print(idx) # # 5 # # 5 # 获取指定元素个数 # count() # c = nums.count(5) # print(c) # # 2 # 获取多个元素 # 切片 # items[start:end:stop] # nums = [3, 4, 5, 6, 5, 7, 55, 5, 8, 9] # # pic = nums[1:4:] # # print(pic) # # [4, 5, 6] # pic = nums[::-1] # print(pic) # # [9, 8, 5, 55, 7, 5, 6, 5, 4, 3] # --------------------------------列表的遍历操作-------------------------------------- # 方式1 # 根据元素进行遍历 # for item in list: # print(item) values = ["a", "b", "a", "d"] # for v in values: # print(v) # print(values.index(v)) # #a # #0 # #b # #1 # #a # #0 # #d # #3 # CurrentIndex = 0 # for v in values: # print(v) # print(values.index(v, CurrentIndex)) # CurrentIndex += 1 # # a # # 0 # # b # # 1 # # a # # 2 # # d # # 3 # 方式2 # 根据索引遍历 # for index in range(len(list)) # print(index,list[index]) values = ['a', 'b', 'c', 'd', 'e'] # 1.造一个索引列表 # indexs = [0, 1, 2, 3, 4] # 2.遍历整个的索引列表,每一个索引 ,索引->指定元素 # for index in indexs: # print(index, values[index]) # # 0 a # # 1 b # # 2 c # # 3 d # # 4 e # count = len(values) # print(count) # for index in range(count): # print(index, values[index]) # # 5 # # 0 a # # 1 b # # 2 c # # 3 d # # 4 e # 方式3 枚举方法产生 # 1. 先根据列表,创建一个枚举对象 # print(list(enumerate(values))) # # [(0, 'a'), (1, 'b'), (2, 'c'), (3, 'd'), (4, 'e')] # 遍历整个的枚举对象(枚举对象,可以直接被遍历) # for idx, val in enumerate(values): # for tupleValue in enumerate(values): # print(tupleValue) # (0, 'a') # (1, 'b') # (2, 'c') # (3, 'd') # (4, 'e') # print(tupleValue[0]) # print(tupleValue[1]) # # 0 # # a # # 1 # # b # # 2 # # c # # 3 # # d # # 4 # for idx, val in enumerate(values): # print(idx) # print(val) # for idx, val in enumerate(values,3):#枚举对象从索引3开始 # print(idx) # print(val) # 方式4 # 使用迭代器进行遍历 # iterL = iter(list) # for item in iterL: # print(item) # --------------------------------额外操作-------------------------------------- # 判定 # 元素 in 列表 # 元素 not in 列表 # values = [1, 2, 3, 4, 5] # print(1 in values) # print(1 not in values) # # True # # False # 比较 # cmp() # 内建函数 # 如果比较的是列表,则针对每个元素,从左到右一一比较 # 左 > 右 1 # 左 == 右 0 # 左 < 右 -1 # Python3.x 不支持 # 比较运算符 # == # > # < # 针对每一个元素从左到右比较 # reslt = cmp("aa", "ab") # print result # result = [2, 3, 4] == [2, 3, 3] # print(result) # # False # 排序 # 方式1 内建函数 # 可以对所有可迭代对象进行排序 # 语法: sorted(iterable, key=None, reverse=False) # 参数: # key 排序关键字 # 值为一个函数,此函数只有一个参数并且返回一个值用来进行比较 # reverse # 控制升序降序 # 默认False 升序 # 返回值 # 一个已经排好序的列表 # 列表类型 s = 'abcdgge' # result = sorted(s) # print(result) # # ['a', 'b', 'c', 'd', 'e', 'g', 'g'] # result = sorted(s, reverse=True) # print(result) # # ['g', 'g', 'e', 'd', 'c', 'b', 'a'] s = [("sz", 18), ("szz", 16), ("szl", 17), ("sza", 15)] # result = sorted(s) # print(result) # # [('sz', 18), ('sza', 15), ('szl', 17), ('szz', 16)] # def getKey(x): # return x[1] # result = sorted(s, key=getKey, reverse=True) # print(result) # # [('sz', 18), ('szl', 17), ('szz', 16), ('sza', 15)] # 方式2 列表的对象方法 # 语法: listsort(key=None, reverse=False) # 参数: # key 排序关键字 # 值为一个函数,此函数只有一个参数并且返回一个值用来进行比较 # reverse # 控制升序降序 # 默认False 升序 # l = [1, 2, 3, 5, 3, 7] # result = sorted(l) # print(result, l) # result = l.sort() # print(result, l) # # [1, 2, 3, 3, 5, 7] [1, 2, 3, 5, 3, 7] # # None [1, 2, 3, 3, 5, 7] # 乱序 # 可以随机打乱一个列表 # 导入random模块 # import random # random.shulffle(list) # import random # l = [1, 2, 3, 4, 5] # res = random.shuffle(l) # print(res, l) # # None [1, 2, 3, 4, 5] # 反转 # l.reverse() # res = l.reverse() # print(res, l) # 切片反转 # l[::-1] -
字典
概念: 无序的,可变键值对集合
定义:
方式1 {key1: value, key2:value, … }
例如:{‘name’:sz, “age”:18}
方式2 fromkeys(S, v =None)
静态方法 类和方法都可以
# d = dict.fromkeys("abc") # print(d) # # {'a': None, 'b': None, 'c': None} d = dict.fromkeys("abc", 666) print(d) # {'a': 666, 'b': 666, 'c': 666}类调用
dict.fromkeys(“abc”, 666)
此处的dict, 是指字典类型
对象调用
dic.fromkeys(‘abc’,666)
此处的dic,是实例化的字典对象
d = dict.fromkeys("abc", 666) print(d) # {'a': 666, 'b': 666, 'c': 666} d = {1: 2, 2: 3}.fromkeys("abc", 666) print(d) # {'a': 666, 'b': 666, 'c': 666} # {'a': 666, 'b': 666, 'c': 666}⚠⚠⚠
key 不能重复 如果重复,后值会把前值覆盖
key 必须是任意不可变类型
可变: 列表 字典 可变集合 …
不可变: 数值 布尔 字符串 元组 …
原因
Python的字典,采用哈希(hash)的方式实现
简单存储过程
初始化一个表格,用来存放所有的值
这个表格成为哈希表
暂且可以理解为列表
存储一个键值对的时候
根据给定的key,通过某些操作,得到一个再哈希表中的索引位置
把key通过哈希函数转换为一个整型数组,成为哈希值
将该数字对数组长度进行取余,取余结果就当作数组的下标
如果产生了哈希冲突
比如,两个不同的key,计算出来的索引是同一个
则采用开发寻址法 通过探测函数查找下一个空位
根据索引位置,存储给定的值
简答查找过程
再次使用哈希函数将key转换为对应的列表索引,并定位到列表的位置获取value
存在意义
可以通过key,访问对应的值 使这种访问更具有意义
查询效率得到很大提升 可想象"汉字字典"的使用方式
常用操作
# -----------字典的常用操作------- # 增 # dic[key] = value # 当key在原字典中不存在时,即为新增操作 d = {'name': 'sz', 'age': 18} # print(d, type(d), id(d)) # d['height'] = 180 # print(d) # print(d, type(d), id(d)) # # {'name': 'sz', 'age': 18} <class 'dict'> 1642027190312 # # {'name': 'sz', 'age': 18, 'height': 180} # # {'name': 'sz', 'age': 18, 'height': 180} <class 'dict'> 1642027190312 # 删 # del dic[key] # key必须存在,否则KeyError # del d['age'] # print(d) # # {'name': 'sz'} # dic.pop(key[,default]) # 删除指定的键值对,并返回对应的值 # 如果key,不存在,那么直接返回给定的default值 # 不作删除动作 # 如果没有给定默认值,则报错 # v = d.pop("age") # print(v, d) # # 18 {'name': 'sz'} # v = d.pop("age1", 666) # print(v, d) # # 666 {'name': 'sz', 'age': 18} # dic.pipitem() # 删除按升序排序后的第一个键值对,并以元组的方式返回该键值对 # 如果字典为空,则报错 result = d.popitem() print(result, d) # ('age', 18) {'name': 'sz'} # dic.clear() # 删除字典内所有键值对 # 返回None # 注意,字典对象本身存在,只不过内容被清空 # 注意与del的区别 #del全删,执行后对象也被删除 print(d.clear()) print(d) # None # {} # 改 # 值改值,不改key # 修改单个键值对 # dict[key] = value # 直接设置,如果key不存在,则新增,存在则修改 d = {'name': 'sz', 'age': 18} # print(d) # d['age'] = 20 # print(d) # # {'name': 'sz', 'age': 18} # # {'name': 'sz', 'age': 20} # 批量修改键值对 # oldDic.update(newDic) # 根据新的字典,批量更新旧字典中的键值对 # 如果就字典没有对应的key,则新增键值对 # d.update({"age": 666, 'address': '上海'}) # print(d) # # {'name': 'sz', 'age': 666, 'address': '上海'} # 查 # 获取单个值 # 方式1 # dic[key] # 如果key,不存在,会报错 # print(d['age']) # # 18 # 方式2 # dic.get(key, default) # 如果不存在对应的key,则取给定的默认值default # 如果没有默认值,则为None # 但不会报错 # 但是,原字典不会增加这个键值对 # 方式3 # dic.setdefault(key,default) # 获取指定key对应的值 # 如果key不存在,则设置给定默认值,并返回该值 # 如果默认值没设定 # 则使用None代替 d = {'name': 'sz', 'age': 18, 0: '666'} v = d.setdefault('age1', 666) print(v, d) # 666 {'name': 'sz', 'age': 18, 0: '666', 'age1': 666} # 获取所有的值 # dic.values() print(d.values()) # 获取所有的键 # dic.key() print(d.keys()) # 获取字典的键值对 # dic.items() print(d.items()) # dict_values(['sz', 18, '666', 666]) # dict_keys(['name', 'age', 0, 'age1']) # dict_items([('name', 'sz'), ('age', 18), (0, '666'), ('age1', 666)]) # 遍历 # 先遍历所有的key, 根据指定的key,获取对应的值 d = {'name': 'sz', 'age': 18, 'address': '上海'} # 1. 先获取所有的key keys = d.keys() # 2. 遍历所有的key for key in keys: print(key) print(d[key]) # name # sz # age # 18 # address # 上海 # 直接遍历所有的键值对 # 1.获取所有的键值对 kys = d.items() print(kys) # dict_items([('name', 'sz'), ('age', 18), ('address', '上海')]) # 2.直接遍历 for k, v in kys: print(k, v) # 计算 # len(info) # 键值对的个数 # 判定 # x in dic # 判定dic中的key,是否存在 -
元组
概念: 有序的不可变的元素集合
和列表的区别是,元组元素不能修改
定义: 一个元素的写法 (666,)
多个元素的写法(1,2,3)
多个对象,以逗号隔开,默认为元组 tuple 1,2,3,“sz”
从列表转换为元组 tuple(seq) 内建函数
补充: 元组嵌套 (1, 2, (“a”, “b”))
常用操作:
查:
t = (1, 2, 3, 4, 5) # 查 # 获取单个元素 # tuple[index] # index 为索引 # 可以为负 print(t[-1]) # 获取多个元素 # 切片 # tuple[start: end: stop] print(t[0:3]) print(t[::-1]) # 5 # (1, 2, 3) # (5, 4, 3, 2, 1)额外操作
# 获取 # tuple.count(item) # 统计元组中指定元素的个数 # tuple.index(item) # 获取元组中指定元素的索引 # len(tup) # 返回元组中元素的个数 # max(tup) # 返回元组中元素最大的值 # min(tup) # 返回元组中元素最小的值 from base64 import b16decode from unittest import result t = (1, 2, 3, 4, 5) c = t.count(12) print(c) # 0 idx = t.index(2) print(idx) # 1 length = len(t) print(length) # 5 maxNum = max(t) minNum = min(t) print(maxNum, minNum) # 5 1 # 判定 # 元素 in 元组 # 元素 not in 元组 print(11 in t) print(11 not in t) # False # True # 比较 # cmp() # 内建函数 # 如果比较的是列表,则针对每个元素,从左到右一一比较 # 左 > 右 1 # 左 == 右 0 # 左 < 右 -1 # Python3.x 不支持 # result = cmp((1, 2), (1, 2)) # print result # # 0 # 比较运算符 # == # > # < # 针对每一个元素从左到右比较 result = (1, 2) > (3, 4) print(result) # False # 拼接 # 乘法 # (元素1, 元素2, ...) * int 类型数值 print((1, 2) * 3) # (1, 2, 1, 2, 1, 2) # 加法 # (元素1, 元素2) + (元素a, 元素b) print((2, 3) + (1, 2)) # (2, 3, 1, 2) #拆包 # a, b = (10, 20) # print(a, b) # # 10, 20 a, b = 10, 2 print(a, b) # 10, 2 -
集合
概念: 无序的,不可随机访问的,不可重复的元素集合
与数学中的集合的概念类似,可以对其进行交并差补等逻辑运算
分为可变集合和非可变集合
set 为可变集合
# 集合的定义 # 可变集合 from numpy import iterable s = {1, 2, 3} print(s, type(s)) # {1, 2, 3} <class 'set'> # s = set(iterable) s2 = set('abc') print(s2, type(s2)) # {'c', 'b', 'a'} <class 'set'> s3 = set({'name': 'sz', 'age': 18}) print(s3, type(s3)) # {'name', 'age'} <class 'set'> s = set(x for x in range(0, 10)) print(s, type(s)) # {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} <class 'set'> # s = {推导式} s = {x for x in range(0, 20)} print(s, type(s)) # {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19} <class 'set'> xxxxxxxxxx ## 集合的定义# 可变集合from numpy import iterables = {1, 2, 3}print(s, type(s))# {1, 2, 3} <class 'set'># s = set(iterable)s2 = set('abc')print(s2, type(s2))# {'c', 'b', 'a'} <class 'set'>s3 = set({'name': 'sz', 'age': 18})print(s3, type(s3))# {'name', 'age'} <class 'set'>s = set(x for x in range(0, 10))print(s, type(s))# {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} <class 'set'># s = {推导式}s = {x for x in range(0, 20)}print(s, type(s))# {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19} <class 'set'>frozenset 不可变集合 创建好之后,无法增删改
fs = frozenset(iterable)
其中iterable可以是字符串\列表\元组\字典等
但是为dic时,只会获取key作为set的元素
集合推导式: s = frozenset(x**2 for x in range(1, 10) if x % 2 == 0)
# 不可变集合的定义 fs = frozenset('set') print(fs, type(fs)) # frozenset({'t', 'e', 's'}) <class 'frozenset'> fs = frozenset({'name': 'sz', 'age': 10}) print(fs, type(fs)) # frozenset({'age', 'name'}) <class 'frozenset'> s = frozenset(x**2 for x in range(1, 10) if x % 2 == 0) print(s, type(s)) # frozenset({16, 64, 4, 36}) <class 'frozenset'>⚠⚠⚠
-
创建一个空集合时, 需要使用set()或者frozenset()时,不能使用{}, 会被识别为字典
-
集合中的元素,必须是可哈希的值
如果一个对象在自己的生命周期中有一哈希值(hash value) 是不可改变的,那么它就是可哈希(hashable)的
暂时理解为不可变类型
-
如果集合中的元素值出现重复,则会被合并为1个
常用操作
单一集合操作
#---------可变集合------- # 增 import re from unittest import result s = {1, 2, 3} s.add(4) print(s, type(s)) # {1, 2, 3, 4} <class 'set'> # s.add([1, 2]) # 发生异常: TypeError # unhashable type: 'list' # 删 # s.remove(element) # 指定删除set对象中的一个元素 # 如果集合中没有这个元素,则返回一个错误 s = {1, 2, 3} # result = s.remove(1) # print(result, s) # # None {2, 3} # s.discard(element) # 指定删除集合中的一个元素 # 若没有这个元素,则do nothing result = s.discard(12) print(result, s) # None {2, 3} # s.pop(element) # 随机删除并返回一个集合中的元素 # 若集合为空,则返回一个错误 result = s.pop() print(result, s) # s.clear() # 清空一个集合中的所有元素 result = s.clear() print(result, s) # 删除整个集合用del语句可变集合和不可变集合的查询都可以用
-
for in
-
迭代器
#可变集合和不可变集合的查询都可以用 #1. for in #2. 迭代器 s = (1, 2, 3) # for v in s: # print(v) # # 1 # # 2 # # 3 # 1. 生成一个迭代器 its = iter(s) # # 2. 使用这个迭代器去访问(next(), for in ) # print(next(its)) for v in its: print(v)集合之间的操作
交集
# intersection(Iterable) # 字符串 # 只判定字符串中的非数字 # 列表 # 元组 # 字典 # 值判定 key # 集合 # ... # 逻辑与'&' # Itersection_update(_) # 交集计算完后,会再次赋值给对象 # 会改变原对象 # 所以,只适用于可交集合 # s1 = {1, 2, 3, 4, 5} from hashlib import sha3_224 s1 = frozenset([1, 2, 3, 4, 5]) s2 = {4, 5, 6} result = s1.intersection(s2) print(result, type(result)) result = s1 & s2 print(result, type(result)) result = s1.intersection_update(s2) print(s1, s2) # 发生异常: AttributeError # 'frozenset' object has no attribute 'intersection_update' result = s2.intersection_update(s1) print(s1, s2) # frozenset({1, 2, 3, 4, 5}) {4, 5}并集
# 并集 # union() # 返回并集 # 逻辑或 '|' # 返回并集 # update() # 更新并集 s1 = {1, 2, 3} s2 = {3, 4, 5} result = s1.union(s2) result = s1 | s2 print(result, s1) result = s1.update(s2)差集
# 差集 # difference() # 算术运算符 '-' # difference_update()判定
# 判定 # isdisjoint()两个集合不相交 # issuperset()一个集合包含另一个集合 # issubset()一个集合包含于另个一个集合 s1 = {1, 2} s2 = {3, 4, 5} print(s1.isdisjoint(s2)) # Ture⚠⚠⚠
可变与不可变集合回合运算,返回结果类型以运算符左侧为主
-
-
时间日历
Python程序有很多方式处理日期和时间,转换日期格式是一个常见的功能
常用操作
time模块
🚩提供了处理时间和表示之间转换的功能
获取当前时间戳
概念: 从0时区的1970年1月1日0时0分0秒,到所给定日期时间的秒数
浮点数
获取方式 import time
time.time()
import time from unittest import result result = time.time() years = result / (24 * 60 * 60 * 365) + 1970 print(years) print(result) # 2022.3106321751288 # 1649668096.2748625获取时间元组
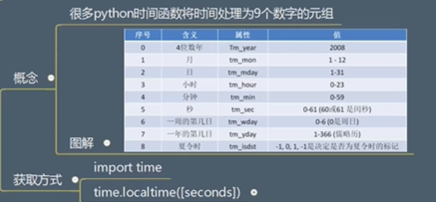
获取格式化时间
# 获取格式化时间 # 秒 -> 可读时间 # import time # time.ctime([seconds]) # seconds # 可选时间戳 # 默认当前时间戳 t = time.time() result = time.ctime(t) print(result) # Mon Apr 11 17:15:30 2022 # 时间元组 -> 可读时间 # import time # time.asctime({p_tuple}) # p_tuple # 可选的时间元组 # 默认当前时间元组 time_tuple = time.localtime() result = time.asctime(time_tuple) print(result)格式化日期字符串 <–> 时间戳
# 时间元组 -> 格式化日期 # time.strftime(格式化字符串,时间元组) # 例如 # time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) result = time.strftime("%y-%m-%d %H: %M: %S ", time.localtime()) print(result) #格式化日期 -> 时间元组 # time.strptime(日期字符串,格式符字符串) # time.mktime(时间元组)获取当前CPU时间
time.clock() 浮点数的秒数
可用来统计一段程序代码的执行耗时
休眠n秒
推迟线程的进行,可简单理解为,让程序暂停
time.sleep(secs)
calender模块
🚩提供与日历相关的功能,比如:为给定的月份或年份打印文本日历的功能
获取某月日历
import calender
calender.month(2022, 4)
import calendar print(calendar.month(2022, 6))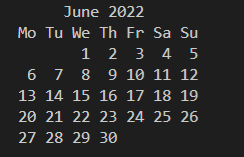
datetime模块
🚩 Python处理日期和时间的标准库
这个模块里面有datetime类,此外常用的还有date类,以及timel类
可以做一些计算之类的操作
获取当天日期
import datetime print(datetime.datetime.now()) print(datetime.datetime.today()) import datetime t = datetime.datetime.now() print(type(t)) print(t.year) print(t.month) print(t.hour) print(t.second)计算n天之后的日期
import datetime t = datetime.datetime.today() result = t + datetime.timedelta(days=7) print(result) # 2022-04-18 17:41:01.348227获取两个日期时间的时间差
import datetime first = datetime.datetime(2022, 4, 2, 12, 00, 00) print(first, type(first)) second = datetime.datetime(2022, 4, 11, 17, 00, 00) print(second, type(second)) delta = second - first print(delta, type(delta)) print(delta.total_seconds()) # 2022-04-02 12:00:00 <class 'datetime.datetime'> # 2022-04-11 17:00:00 <class 'datetime.datetime'> # 9 days, 5:00:00 <class 'datetime.timedelta'> # 795600.0 -
访问集合的方式-迭代器
迭代就是按照某种顺序诸葛访问集合中的每一项
可迭代对象
判定依据: 能作用于for in
判定方法: import collections
isinstance(obj,collection.Iterable)
迭代器
可以记录遍历位置的对象
从第一个元素开始往后通过next()函数,进行遍历
只能往后,不能往前
判定依据:能做用于next()函数
判定方法:import collections
isinstance(obj,collection.Iterator)
⚠ 迭代器也是可迭代对象,也可以作用于for in
为什么会产生迭代器?
-
仅仅在迭代到某个元素时才处理该元素
在此之前,元素可以不存在
在此之后,元素可以被销毁
特别适合遍历一些巨大的或是无限的集合 如:“斐波那契数列”
-
提供了一个统一的访问集合的接口
可以把所有的可迭代对象,转换成迭代器进行使用
iter(Iterable)
iter(str)
iter(list)
iter(tuple)
iter(dict)
…
迭代器简单使用
使用next()函数,从迭代器中取出下一个对象,从第1个元素开始
因为迭代器比较常用,所以在Python中,可以直接作用于for in
内部会自动调用迭代器对象的next()
会自动处理迭代完毕的错误
⚠⚠⚠ 如果取出完毕,再继续取,则会报错 StopIteration
迭代器一般不能多次迭代
-
Python函数
函数的概念
写一段代码实现某个小功能,然后把这些代码集中到一块,起一个名字,下一次就可以根据这个名字使用这个代码块
作用: 方便代码的重用
分解任务,简化程序逻辑
使代码更加模块化
函数分类:内建函数
三方函数
自定义函数
函数的基本使用
简单定义
def 函数():
函数体
函数的调用
函数名()
函数的参数
单个参数
场景: 需要动态调整函数体中某一个处理信息,则可以 以参数的形式接收相关数据
定义:def 函数名(参数名称):
函数体 函数体中,可以直接以变量的方式使用该参数
函数的调用:参数名(参数值)
形参和实参的概念: 上述函数定义中,“参数名称”即为形参
在调用函数的时候, 传递的真实数据 即为实参
多个参数
def mySum(num1, num2): print(num1 + num2) mySum(4, 5) # 9定义
def 函数名(参数名称1,函数名称2):
函数体 函数体中,可以直接以变量的方式使用所有参数
调用
方式1 函数名(参数1,参数,参数2,参数3…) 形参和实参一一对应
方式2 函数名(参数名称1=参数1, 参数名称n =参数n…) 可以指明形参名称 称为"关键字参数" 不需要严格按照顺序
不定长参数
场景: 如果函数体中,需要处理的数据,不确定长度
则可以以不定长参数的方式接收数据
方式1
定义 def 函数名(*args) 元组
函数体 函数体中,可以直接以元组变量的方式使用该参数
使用 函数名(参数1,参数2,参数3…)
def mySum(*t): print(t, type(t)) result = 0 for v in t: print(v) result += v print(result) mySum(4, 5, 6, 7) # (4, 5, 6, 7) <class 'tuple'> # 4 # 5 # 6 # 7 # 22方式2
定义 def 函数名(**dic) 字典
函数体 函数体中,可以直接以字典变量的方式使用该参数
使用 函数名(参数名称1= 参数1, 参数名称2 = 参数2…)
def mySum(**kwargs): print(kwargs, type(kwargs)) mySum(name='sz', age=12) # {'name': 'sz', 'age': 12} <class 'dict'>参数拆包
装包: 把传递的参数,包装成一个集合,称为装包
拆包: 把接收的参数,
def test(*args): print(args) test(1, 2, 3, 4) # (1, 2, 3, 4) # 拆包 def test(*args): print(*args) test(1, 2, 3, 4) # 1 2 3 4缺省参数
场景: 使用函数的时候,如果大多数情况下,使用的某个数据是一个固定值,或者属于主功能之外的小功能实现: 则可以使用默认值,这种参数称为"缺省参数"
定义 def 函数名(变量名1 = 默认值, 变量名 = 默认值2):
函数体 函数体中,即使外界没有传递指定变量,也可以使用,只不过是给定的默认值
使用 函数名(变量1,变量2) 此处如果是缺省参数,则可以不填写
参数注意
值传递和引用传递
值传递:是指传递过来的,是一个数的副本, 修改副本,对原件没有任何影响
引用传递:是指传递过来的,是一个变量的地址,通过地址,可以操作同一个原件
⚠⚠⚠
在Python中,只有引用传递(地址传递)
但是, 如果数据类型是可变类型,则可以改变原件
如果数据类型是不可变类型,则不可以改变原件
函数的返回值
场景: 当我们通过某个函数,处理好数据之后,想要拿到处理的结果
语法: def 函数()
函数体
return 数据
⚠⚠⚠
- return 后续代码不会被执行
- 只能返回一次
- 如果想要返回多个数据,可先吧多个数据包装成一个集合,整体返回 列表,元组,字典…
函数的使用描述
场景: 当我们编写三方函数,为了方便他人使用,就需要描述清楚我们所写的函数功能以及使用方式等信息
定义格式 : 直接在函数体的最上面,添加三个双引号对注释
def 函数():
‘’‘这里写帮助信息’‘’
查看函数使用文档: help(函数名称)
经验: 一般函数的描述,需要说明如下的几个信息
函数的功能
参数
含义
类型
是否可以省略
默认值
返回值
含义
类型
def caculate(a, b=1): """_summary_ 计算两个数据的和,差 Args: a (_type_):数值1,数值类型,不可选,没有默认值 b (int, optional):数值2,数值类型,可选,默认值:1 Returns: _type_: 返回计算的结果,元组:(和,差) """ he = a + b cha = a - b return (he, cha) help(caculate)
偏函数
概念&场景: 当我们写一个参数比较多的函数时,如果有些参数,大部分场景下都是某一个固定值,那么为了简化使用,就可以创建一个新函数,指定我们要使用的函数的某个参数,为某个固定的值,这个新函数就是偏函数
语法
方式1 自己写一个新的
方式2 借助functools模块的partial函数
import functools
newFuc = functools.partial(函数,特定参数=偏爱值)
# 1.偏函数 import functools def test(a, b, c, d=1): print(a + b + c, d) def test2(a, b, c, d=2): test(a, b, c, d) test2(1, 2, 3) # 6 2 newFunc = functools.partial(test, c=5) print(newFunc, type(newFunc)) newFunc(1, 2) # functools.partial(<function test at 0x000002348C1BC2F0>, c=5) <class 'functools.partial'> # 8
高阶函数
概念: 当一个函数A的参数,接收的又是另一个函数时,则把这个函数A称为时"高阶函数"
# a, b 形参,变量 # 传递函数就是指 给变量赋值 # 函数本身,也可以作为数据,传递给另外一个变量 def test(a, b): print(a + b) print(test) print(id(test)) test2 = test test2(1, 2) # 3 def caculate(num1, num2, caculateFunc): print(caculateFunc(num1, num2)) def sum(a, b): return a + b def jianfa(a, b): return a - b caculate(6, 2, sum) caculate(6, 2, jianfa) # 8 # 4
返回函数
概念:是指一个函数内部,他的返回值时另一个函数
def getFunc(flag): # 1. 再次定义几个函数 def sum(a, b, c): return a + b + c def jian(a, b, c): return a - b - c # 2. 根据不同的flag值,来返回不同的操作函数 if flag == "+": return sum elif flag == '-': return jian result = getFunc("+") print(result, type(result)) res = result(1, 2, 3) print(res) # <function getFunc.<locals>.sum at 0x0000018ED6A5AF28> <class 'function'> # 6
匿名函数
概念: 也称为"lambda函数"
语法: lambda 参数1,参数2:表达式
限制 只能写一个表达式 不能直接return
表达式结果就是返回值
所以 只适用于一些简单操作
result = (lambda x, y: x + y)(1, 2) print(result) # 3 def newFuc(x, y): return x + y print(newFuc(4, 5)) # 9
闭包

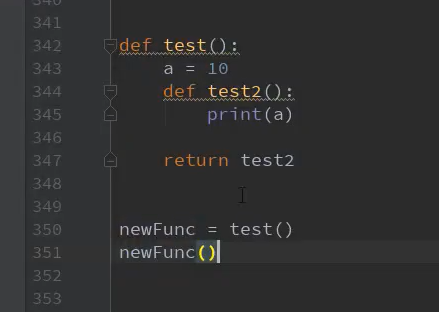


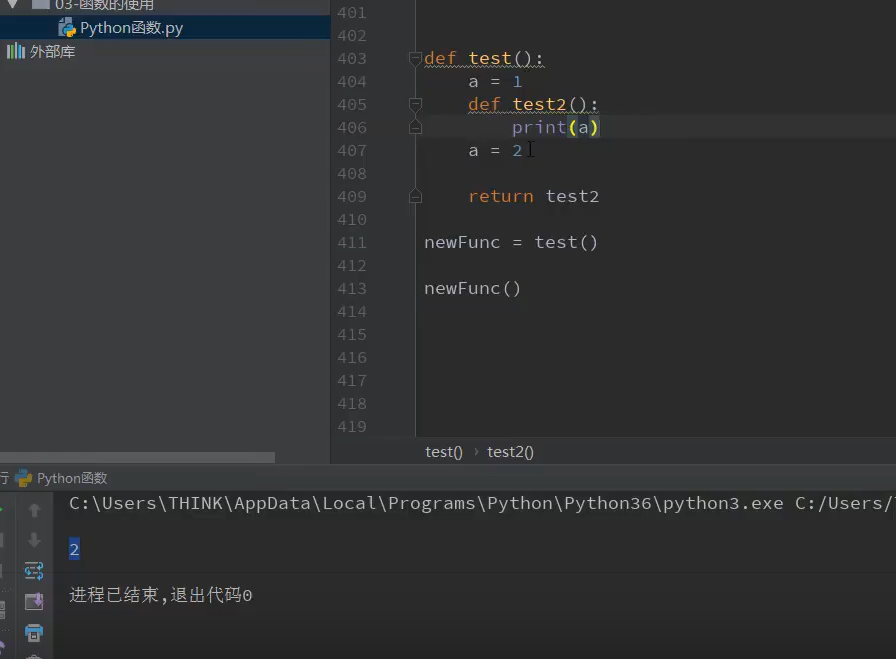
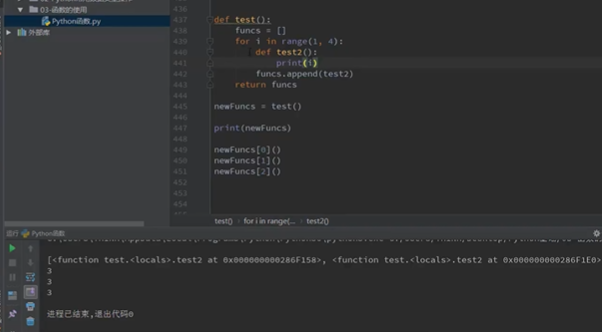
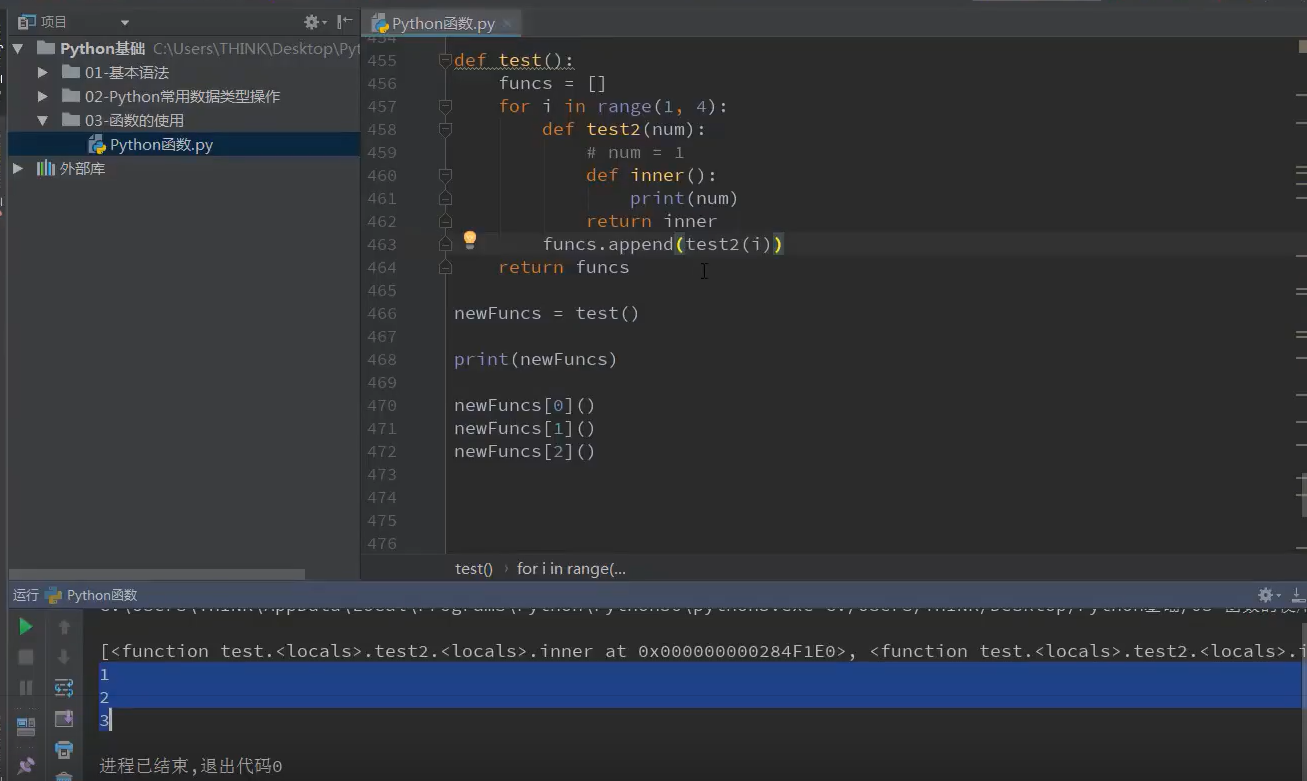
装饰器
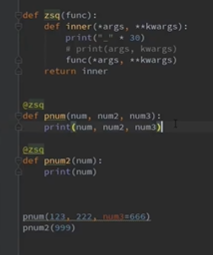
进阶
装饰器叠加: 从上到下装饰
从下到上执行
对有参数的函数装饰
生成器
是一个特殊的迭代器(迭代器的抽象层级更高)
所以,拥有迭代器的特性
惰性计算数据,节省内存
能够记录状态,并通过next()函数,访问下一个状态
具备可迭代特性
但是,如果打造一个自己的迭代器,比较复杂
需要很多方法
所以,就有一个更加优雅的方式”生成器"
创建方式
生成器表达式 把列表推导式[]换为()
# l = [i for i in range(1, 100) if i % 2 == 0] l = (i for i in range(1, 100) if i % 2 == 0) print(l) # print(next(l)) # print(l.__next__()) for i in l: print(i)生成器函数
函数中包含 yield语句
这个函数的执行结果就是生成器
def test(): print('xxx') yield 1 print('a') yield 2 print('b') g = test() # print(g) print(next(g)) print(next(g)) # yield 可以去阻断当前的函数执行,然后,当使用next()函数,或者,__next__(), # 都会让函数继续执行, 然后, 当执行到下一个 yield语句的时候,又会被暂停 # xxx # 1 # a # 2产生数据的方式
生成器具备可迭代特性
next()函数, 等价于 生成器.__next__()
for in
send()方法
send方法有一个参数,指定的是上一次被挂起的yield语句的返回值
相比于.__next__() 可以额外的给yield语句 传值
注意第一次调用 t.send(None)
def test(): res1 = yield 1 print(res1) res2 = yield 2 print(res2) print(g.send(None)) print(g.send(666)) # 1 # 666 # 2关闭生成器
g.close()
后续如果继续调用,会抛出StopIteration异常提示
⚠⚠⚠
如果碰到return 会直接终止, 抛出StopIteration异常提示
生成器只会遍历一次
递归函数
体现
函数A内部,继续调用函数A
概念
传递
回归
🌰
# 功能:如果是不直接知道结果的数据,就进行分解 9 9 * b! 8 = # 如果说,直接知道结果的数据,就直接返回1!= 1 def jiecheng(n): if n == 1: return 1 return n * jiecheng(n - 1) result = jiecheng(4) print(result) # 24
函数的作用域
基本概念
变量的作用域
变量的作用范围 可操作范围
Python是静态作用域,也就是说在Python中,变量的作用域源于它在代码中的位置。在不同的位置,可能有不同的命名空间
命名空间
是作用域的体现形式
不同的具体的操作范围
基于命名空间的常见变量类型
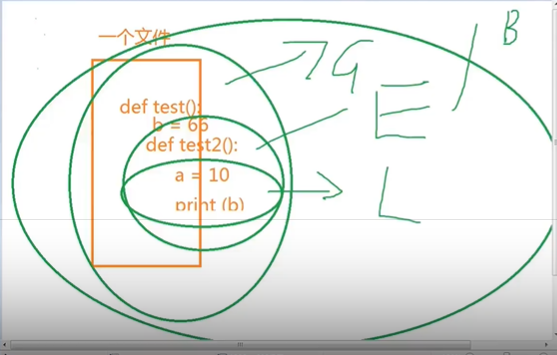
局部变量
在一个函数内部定义的变量;
作用域为函数内部
查看局部变量 locals()
全局变量
在函数外部,文件最外层定义的变量
作用域为整个文件内部
查看全局变量 gloabls()

Python文件操作
文件的使用流程
打开 open(“文件”,“模式”)
文件 指定文件路径
模式 控制操作模式
模式
🚩 r 以只读方式打开文件 这是默认模式
文件的直至将会放在文件的开头
注意:文件不存在,会报错
# 1. 打开文件 # 相对路径,相对于哪一个目录下面的指定文件 f = open("a.txt","r") # 2. 读写操作 content = f.read() print(content) # 3. 关闭文件 f.close()🚩 w 以只写方式打开文件
文件的指针将会放在文件的开头,所以写入新内容会覆盖原内容
注意:文件不存在,会自动创建一个新文件
# 1. 打开文件 # 相对路径,相对于哪一个目录下面的指定文件 f = open("a.txt", "w") # 2. 读写操作 f.write('123456') # 3. 关闭文件 f.close()🚩 a 以追加方式(只写)打开文件
文件的指针将会放在文件的结尾,所以写入新内容会增加到原内容后
注意:文件不存在,会自动创建一个新文件文件的相关操作
增加 b
rb wb ab
以二进制格式进行操作文件读写(如果文件时(图片 视频 音频)等二进制文件),则选择此项
# 1. 打开xx.jpg文件,取出内容,获取内容的前面半部分 # 1.1 打开文件 fromFile = open("xx.jpg","rb") # 1.2 读取文件内容 fromContent = fromFile.read() print(fromContent) # 1.3 关闭文件 fromFile.close() # 2. 打开另外一个文件xx2.jpg,然后,把取出来的半部分内容,写到xx2.jpg文件里去 # 2.1 打开文件 toFile = open("xx2.jpg","wb") # 2.2 写入操作 content = fromContent[0: len(fromContent) // 2] toFile.write(content) # 2.3 关闭文件 toFile.close()增加+
r+ w+ a+ rb+ rw+ ra+
代表都是以"读写模式"进行打开
其他特性基本和+前面的模式一致
部分操作有区别
读写
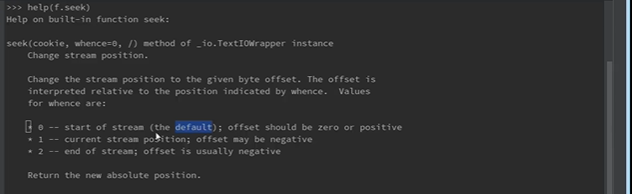
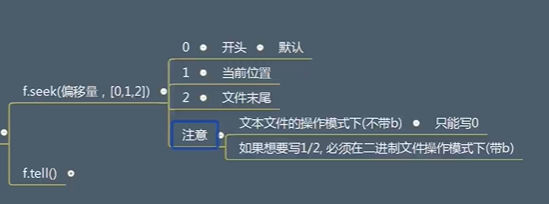
定位 f.seek(偏移量,[0,1,2])
f = open('a.txt','r') f.seek(2) print(f.tell())#tell()告诉指针位置 print(f.read()) print(f.tell()) f.close()读
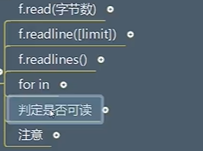
写
f.write(‘内容’) 返回值是写入的字节长度
判定是否可写 .writeable()
关闭
f.close()
可以释放系统资源 会立即清空缓冲区的数据内容到磁盘文件
补充: f.flush() 立即清空缓冲区的数据内容到磁盘文件

-
文件的相关操作
模块 import os
操作
重命名 os.rename(‘old’,‘new’) 修改单级 目录/文件 名称
os.renames(‘old’,‘new’) 修改多级 目录/文件 名称
删除
删除文件 os.remove(‘文件路径’ ) 不存在会报错
删除目录
os.rmdir(path) 不能递归删除目录 如果文件夹非空,会报错 os.removedirs(path) 可递归删除目录 如果文件夹非空,会报错
创建
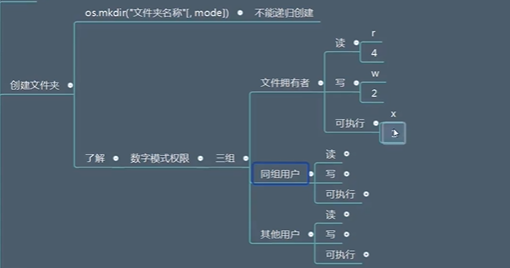
-
🌰
-
文件复制
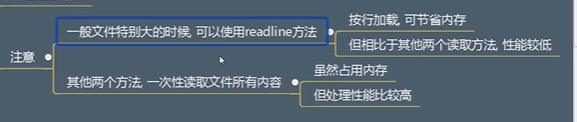
# 1. 只读模式,打开要复制的文件 # 增加模式,打开副本文件 source_file = open("d.txt","r",encoding="utf-8") dst_file = open("d_bat.txt","a",encoding="utf-8") # 2. 从选文件中读取内容 # 写到目标文件中 content = source_file.read() dst_file.write(content) # 3. 关闭源文件和目标文件 source_file.close() dst_file.close()大文件复制注意:
将文件分解为小部分
# 1. 只读模式,打开要复制的文件 # 增加模式,打开副本文件 source_file = open("d.txt","r",encoding="utf-8") dst_file = open("d_bat.txt","a",encoding="utf-8") # 2. 从选文件中读取内容 # 写到目标文件中 while True: content = source_file.read(1024) if len(content) == 0: break print("---",content) dst_file.write(content) # 3. 关闭源文件和目标文件 source_file.close() dst_file.close()文件分类,并生成文件清单
# 文件分类 # 0. 获取所有的文件名称列表 import os import shutil path = "files" if not os.path.exists(path): exit() os.chdir("files") file_list = os.listdir("./") print(file_list) # 1. 遍历所有的文件(名称) for file_name in file_list: print(file_name) # 2. 分解文件的后缀名 # 2.1 获取最后一.的索引位置 index= file_name.rfind(".") if index == -1: continue print(index) # 2.2 根据这个索引位置,当作起始位置,来截取后续的所有字符串内容 extension = file_name[index + 1:] print(extension) # 3. 查看一下,是否存在同名的目录 if not os.path.exists(extension): os.mkdir(extension) shutil.move(file_name, extension) # 4. 如果不存在这样的目录 -> 直接创建一个这样名称的目录 # 5. 目录存在 -> 移动过去# 列清单 import os file_list = os.listdir("files") print(file_list) # 通过给定的文件夹,列举出这个文件夹当中,所有的文件,以及文件夹,子文件夹当中的所有文件 def listFiles(dir): # 1. 列举出,当前给定的文件夹,下的所有子文件夹,以及子文件 file_list = os.listdir(dir) print(file_list) # 2. 针对于,列举的列表,进行遍历 for file_name in file_list: new_fileName = dir + "/" + file_name # 相对路径问题 # 判定,是否是目录,listFiles if os.path.isdir(file_name): print(new_fileName) listFiles(new_fileName) else: # 打印下,文件名称 print("\t" + file_name) print("")
# 写一个清单文件 import os file_list = os.listdir("files") print(file_list) # 通过给定的文件夹,列举出这个文件夹当中,所有的文件,以及文件夹,子文件夹当中的所有文件 def listFilesToTxt(dir, file): # 1. 列举出,当前给定的文件夹,下的所有子文件夹,以及子文件 file_list = os.listdir(dir) print(file_list) # 2. 针对于,列举的列表,进行遍历 for file_name in file_list: new_fileName = dir + "/" + file_name # 相对路径问题 # 判定,是否是目录,listFiles if os.path.isdir(file_name): # print(new_fileName) file.write(new_fileName + "\n") # listFiles(new_fileName) listFilesToTxt(new_fileName, file) else: # 打印下,文件名称 print("\t" + file_name) # print("") file.write("\n") f = open("list.txt",'a') listFilesToTxt('files', f)
重命名 os.rename(‘old’,‘new’) 修改单级 目录/文件 名称
os.renames(‘old’,‘new’) 修改多级 目录/文件 名称
删除
删除文件 os.remove(‘文件路径’ ) 不存在会报错
删除目录
os.rmdir(path) 不能递归删除目录 如果文件夹非空,会报错 os.removedirs(path) 可递归删除目录 如果文件夹非空,会报错
创建
[外链图片转存中…(img-18vxuQ2g-1649813026201)] [外链图片转存中…(img-yOk86xlu-1649813026202)]
-
-
🌰
-
文件复制
# 1. 只读模式,打开要复制的文件 # 增加模式,打开副本文件 source_file = open("d.txt","r",encoding="utf-8") dst_file = open("d_bat.txt","a",encoding="utf-8") # 2. 从选文件中读取内容 # 写到目标文件中 content = source_file.read() dst_file.write(content) # 3. 关闭源文件和目标文件 source_file.close() dst_file.close()大文件复制注意:
将文件分解为小部分
# 1. 只读模式,打开要复制的文件 # 增加模式,打开副本文件 source_file = open("d.txt","r",encoding="utf-8") dst_file = open("d_bat.txt","a",encoding="utf-8") # 2. 从选文件中读取内容 # 写到目标文件中 while True: content = source_file.read(1024) if len(content) == 0: break print("---",content) dst_file.write(content) # 3. 关闭源文件和目标文件 source_file.close() dst_file.close()文件分类,并生成文件清单
# 文件分类 # 0. 获取所有的文件名称列表 import os import shutil path = "files" if not os.path.exists(path): exit() os.chdir("files") file_list = os.listdir("./") print(file_list) # 1. 遍历所有的文件(名称) for file_name in file_list: print(file_name) # 2. 分解文件的后缀名 # 2.1 获取最后一.的索引位置 index= file_name.rfind(".") if index == -1: continue print(index) # 2.2 根据这个索引位置,当作起始位置,来截取后续的所有字符串内容 extension = file_name[index + 1:] print(extension) # 3. 查看一下,是否存在同名的目录 if not os.path.exists(extension): os.mkdir(extension) shutil.move(file_name, extension) # 4. 如果不存在这样的目录 -> 直接创建一个这样名称的目录 # 5. 目录存在 -> 移动过去# 列清单 import os file_list = os.listdir("files") print(file_list) # 通过给定的文件夹,列举出这个文件夹当中,所有的文件,以及文件夹,子文件夹当中的所有文件 def listFiles(dir): # 1. 列举出,当前给定的文件夹,下的所有子文件夹,以及子文件 file_list = os.listdir(dir) print(file_list) # 2. 针对于,列举的列表,进行遍历 for file_name in file_list: new_fileName = dir + "/" + file_name # 相对路径问题 # 判定,是否是目录,listFiles if os.path.isdir(file_name): print(new_fileName) listFiles(new_fileName) else: # 打印下,文件名称 print("\t" + file_name) print("")[外链图片转存中…(img-rOKcq35P-1649813026204)]
# 写一个清单文件 import os file_list = os.listdir("files") print(file_list) # 通过给定的文件夹,列举出这个文件夹当中,所有的文件,以及文件夹,子文件夹当中的所有文件 def listFilesToTxt(dir, file): # 1. 列举出,当前给定的文件夹,下的所有子文件夹,以及子文件 file_list = os.listdir(dir) print(file_list) # 2. 针对于,列举的列表,进行遍历 for file_name in file_list: new_fileName = dir + "/" + file_name # 相对路径问题 # 判定,是否是目录,listFiles if os.path.isdir(file_name): # print(new_fileName) file.write(new_fileName + "\n") # listFiles(new_fileName) listFilesToTxt(new_fileName, file) else: # 打印下,文件名称 print("\t" + file_name) # print("") file.write("\n") f = open("list.txt",'a') listFilesToTxt('files', f)
-















 51万+
51万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









