







元数据内容标签/头部标签
- 元数据内容标签/头部标签(head、meta、title、link、script、noscript、style、base、template)
- 1. 元数据内容标签 有哪些 ?
- 2. ★ head 标签: 文档的头部 (所有头部元素的 容器;元数据容器;机器可读;文档的信息 )
- 2.1 head: 文档头部标签 的属性(无常用属性)
- 2.2 head: 文档头部标签的 8 个子标签 简介 (必要的元数据、配置)
- ⑴ title: 文档标题(显示在 浏览器标签页)
- ⑵ base: 链接 默认地址 和 打开位置 (href 属性:默认地址、解析相对 URL;设置打开位置:搭配 target 属性)
- ⑶ style: 设置 文档内部样式
- ⑷ link: 链接 外部资源 (CSS 样式表、图标文件;搭配 rel、type、href 属性)
- ⑸ meta: 文档 附加信息 (搭配 charset、http-equiv、 name、 content 属性)
- ⑹ script: 嵌入脚本 / 引用脚本 (可搭配 src 属性)
- ⑺ noscript:一段 HTML 代码 (浏览器 不支持/禁用 JS 时 显示)
- ⑻ template:隐藏的模板内容 (客户端;不显示;可用 JS 动态插入 DOM 再显示)
- 3. ★ meta 标签: 关于文档的 元数据 (文档数据的 数据)
- 3.1 content 属性: “名称/值”对 中的 值 (必须搭配 http-equiv 、name、itemprop 属性)
- 3.2 http-equiv 属性: HTTP 头部字段的名称 (搭配 content 属性 = 头部字段的值;在客户端/浏览器 控制页面行为)
- ⑴ 知识拓展:什么是 HTTP 头部字段?(请求/响应的元数据;网络通信)
- ⑵ 使用 meta 标签 可以替代服务器配置吗?
- ⑶ http-equiv 属性 常用值
- ① 内容 安全策略:http-equiv="content-security-policy" (有效来源;页面 允许加载、执行的 资源来源;减少网站漏洞;减少攻击)
- ▲ 知识拓展:什么是 内容安全策略 CSP?
- ② 默认样式表:http-equiv="default-style" (搭配 link[title]、 style[title];content 属性)
- ③ 自动刷新页面(重新加载)、重定向(自动加载 新页面):http-equiv="refresh" (必须搭配 content 属性)
- ④ 指定 IE 用最新渲染模式:http-equiv="x-ua-compatible"(IE 用当前 最新渲染引擎;必须搭配 content 属性;仅限 IE 浏览器;兼容 IE)
- ⑤ 页面 过期时间:http-equiv="expires"( 不推荐使用;搭配 content 属性;到期下载最新版本; GMT 时间 或 秒数;推荐 服务器端 HTTP 缓存控制 Cache-Control 响应头 设置)
- ⑥ 不缓存、不从缓存中访问内容:http-equiv="pragma"(不推荐使用;必须搭配 content="no-cache";推荐 服务器端 HTTP 响应头 设置)
- ⑦ ★ 浏览器 缓存控制:http-equiv="cache-control" (不推荐使用;必须搭配 content 属性;禁止缓存;允许谁缓存;缓存时间等;推荐 服务器端 HTTP 头 设置)
- ⑧ 网页 窗口打开位置:http-equiv="window-target"(不推荐使用;必须搭配 content 属性)
- ⑨ 其他 http-equiv 属性值:content-type、set-cookie 等(不推荐使用;仅做了解,大部分已被废弃)
- 3.3 name 属性:元数据的 名称 (必须搭配 content 属性)
- 3.3.1 name 属性值:HTML 规范中定义的 标准元数据名称
- ⑴ 页面应用程序名称:name="application-name" (应用名; 标识 web 应用;移动设备主屏幕)
- ⑵ 页面作者:name="author" (作者名;作者名/联系方式;公司/组织名)
- ⑶ 页面内容 描述:name="description" (搜索结果 页面摘要;搜索结果优化;增加点击率)
- ⑷ 生成页面的 软件名称/版本:name="generator" (网页生成工具)
- ⑸ 页面关键词:name="keywords"(关键词列表,逗号分隔;搜索引擎优化;网站排名)
- ⑹ ▲ HTTP referrer 头信息 :name="referrer" (访问者 来源地址 策略;页面间跳转时 访问者是谁;前一个网页的 URL;HTTP 访问者 来源地址;发送请求的 来源页面 URL;访客从哪里而来)
- ⑺ 页面主题颜色:name="theme-color"(移动端;浏览器标题栏、地址栏、工具栏颜色)
- ⑻ 配色方案:name="color-scheme"(浅色背景/白天模式、深色背景/夜间模式;搭配媒体查询)
- 3.3.2 name 属性值:HTML5 规范之外 惯用的元数据名称
- ⑴ 网页创作者: name="creator"(技术层面上 作者;非规范元数据名称)
- ⑵ 谷歌 索引爬虫: name="googlebot" (指明 谷歌爬虫如何处理内容)
- ⑶ 指定爬虫行为:name="robots" (索引、跟踪页面链接、缓存页面)
- ⑷ 雅虎 yahoo 爬虫行为: name="slurp" ( 仅用于 Yahoo Search 雅虎搜索引擎)
- ⑸ 窗口宽高 和缩放比例: name="viewport" (视口的宽度、高度、缩放比例、用户缩放)
- ⑹ 发布者/ 出版机构名称:name="publisher"
- ⑺ 爬虫 重新访问时间:name="revisit-after"
- ⑻ 开放图谱: property="og:*" (分享网页时 提供标题、图像、描述等,搭配 content 属性)
- ⑼ Twitter 分享时 提供卡片样式和内容: name="twitter:*"
- ⑽ 一部分 其他的规范之外的元数据名称
- 3.4 charset 属性:文档 字符编码 (一定要设置;charset="utf-8")
- 3.5 media 属性:指定 适用媒体
- 3.6 itemprop 全局属性:提供 用户定义的元数据(项目属性、用户元数据;事物的类型属性 Schema;更多语义;搭配 content 属性)
- 3.7 scheme 属性:解释 content 属性值 的格式含义(已废弃;元数据分类;格式/格式名/格式 URI;)
- 4. ★ base 标签:所有相对路径 的基准 url 、链接 目标打开位置 (搭配 href、target 属性)
- 5. ★ template 标签:隐藏的内容模板(客户端;不显示;可用 JS 动态插入 DOM 再显示)
- 6. basefont 标签:设置 默认 文本颜色、字体、字体大小 (已废弃)
- ♣ 结束语 和 友情链接
- 快速搜索:涉及知识点比较多,看过之后忘了很正常哒,想查询时,请按
Ctrl+F快速搜索关键字哦 (* ̄︶ ̄)。- 搜索后,多次按下 enter 键 ,或搜索框后的 上下箭头,就能在关键词之间快速跳转。
元数据内容标签/头部标签(head、meta、title、link、script、noscript、style、base、template)
- 元数据:在 HTML 中,元数据内容 指的是那些 不直接显示在页面上,但提供了 关于页面信息的数据(描述数据的数据)。
- 元数据用途:这些信息通常 对搜索引擎、浏览器 以及其他处理网页的程序非常重要。
- HTML 中的元数据:主要通过
<head>标签内的子标签 来实现;
- HTML 中的元数据:主要通过
1. 元数据内容标签 有哪些 ?
-
元数据内容类别的元素(元信息标签): 能修改文档其余部分的 表示或行为,设置 到其他文档的链接,或传递其他信息。
- 头部标签
<head>中的所有子标签,都是元数据内容,包括:- ❶
<meta> - ❷
<title> - ❸
<link> - ❹
<script> - ❺
<noscript> - ❻
<style> - ❼
<base> - ❽
<template>
- ❶
- 头部标签
-
元素的 类别划分:其中一些元素 属于多个内容类别。
- 例如,
<script>是元数据、流和短语内容类别的成员,并且是脚本支持元素;所以,<script>可用于需要元数据内容、短语内容或脚本支持元素的地方。
- 例如,
-
本文只详解
<head>、<meta>、<base>、<template>四个标签,其他的标签,见其他分类(学习其他分类的标签时 可以学到); -
HTML 元素内容分类的详解:内容分类 - HTML(超文本标记语言) | MDN
| 标签名 | 用于 |
|---|---|
① <head> | 定义关于 文档的信息。 |
② <meta> | 定义关于 HTML 文档的 元信息(文档数据的信息)。 |
③ <base> | 定义页面中 所有链接的 默认基准地址 或 默认目标打开位置(目标窗口或框架)。 |
④ <template> | 内容模板;可存储在文档中 以便后续使用的内容片段。隐藏的内容模板(客户端;不显示;可用 JS 动态插入 DOM 再显示) |
⑤ <basefont> | 已废弃。定义页面中 文本的 默认字体、颜色或尺寸。 |
2. ★ head 标签: 文档的头部 (所有头部元素的 容器;元数据容器;机器可读;文档的信息 )
-
<head>标签:是 HTML 文档中的一个容器元素;用于包含 元数据的容器,它的子标签用于 提供文档的各种信息和设置。 -
父元素和位置:
- 父元素:是
<html>标签;<html>标签 有两个子标签,第一个 子标签<head>,第二个子标签是<body>。- 结构(emmet 语法):
html > (head + body);
- 结构(emmet 语法):
- 元数据:
<head>元素包含了 文档的元数据,即 那些不是文档内容本身 但与文档紧密相关的信息,数据的数据。 - 主体内容中 不可见: 这些元数据 用于描述 HTML 文档,但不在文档的可见部分显示。
- 父元素:是
-
文档的 头部
- 如何定义 文档的头部 ? 什么是 所有头部元素的 容器 ?
- 使用
<head>头部标签 - 文档头部 包含内容: 包含 文档相关的 配置信息,机器可读信息(元数据),如 ❶ 标题、❷ 脚本、 ❸ 样式表 、❹ 编码方式 等。
- 使用
- 使用范围:
- 机器 处理的信息:
<head>元素 主要保存 用于机器处理的信息,而不是 为了人的可读性。 - 大部分 文档头部内容 不显示在页面中:
- 绝大多数 文档头部 包含的数据, 都不会作为页面内部的内容 直接显示给读者,如 编码方式、爬虫索引方式、页面作者 等。
- 机器 处理的信息:
- 如何定义 文档的头部 ? 什么是 所有头部元素的 容器 ?
-
文档头部
<head>标签的 8 个子标签- ①
<base>链接 基准地址和 目标打开位置 标签 - ②
<link>链接 标签 - ③
<meta>元信息 标签 - ④
<script>脚本 标签 - ⑤
<noscript>不支持 /禁用 JS 时 替代内容 - ⑥
<style>文档内部样式 标签 - ⑦
<title>文档标题 标签 - ⑧
<template>隐藏的内容模版 标签
- ①
-
文档头部
<head>标签的 必需子元素- 文档标题
<title>标签 ,定义 文档的 标题 ;- 文档 不能没有标题,这个一般能让用户清楚明了的知道 内容的主题,明确知道 该不该继续浏览。
- 文档标题
-
省略
<head>头部标签 对应 浏览器的处理- 自动创建: 如果在文档中 忽略了
<head>标签,则大部分浏览器 会自动创建一个<head>元素。当然,有一些不会。 - 不会 自动创建:下面这些浏览器经测试 不会自动创建一个
head元素:Android <=1.6, iPhone <=3.1.3, Nokia 90, Opera <=9.27, and Safari <=3.2.1。
- 不能省略: 所以,文档头部标签
head,一定要写上,免得造成 不必要的麻烦。
- 自动创建: 如果在文档中 忽略了
2.1 head: 文档头部标签 的属性(无常用属性)
| 属性名 | 属性值 | 用于 |
|---|---|---|
| =URL | 已废弃. 一个由 空格 分隔的 URL 列表,这些 URL 包含着 有关页面的 元数据信息 , 配置文件的 URL。 |
⑴ profile 属性: 配置文件 地址 url (指定元信息类型;html5 已废弃)
head标签profile属性- 用于:指定文档的元信息类型。
- 它的值 应该是一个有效的 URL,指向一个包含属性定义的文档,通常是一个 RDF(资源描述框架)文件。
- 与 当前文档 相关联的 配置文件的 URL。
- 一个或多个 元数据配置文件的 URI,用空格分隔;
- 它的值 应该是一个有效的 URL,指向一个包含属性定义的文档,通常是一个 RDF(资源描述框架)文件。
- 注意:在 HTML5 中,
profile属性不再被支持。:在 HTML5 中,profile属性不再被支持。
- 用于:指定文档的元信息类型。
- 使用
profile属性的好处包括:
- 搜索引擎优化(SEO):通过指定元信息的类型,搜索引擎可以更好地理解网页的内容和结构,从而提供更准确的搜索结果。
- 与其他应用程序的集成:许多应用程序 可以根据网页的元信息类型 执行特定的操作,如数据抓取、数据解析和可访问性改进。
- 例: 假设你有一个 RDF 文件
http://example.com/metadata,该文件包含了元信息定义。通过将profile属性设置为此 URL,你可以指定文档的元信息类型:- 在这个例子中,
profile属性告诉浏览器和搜索引擎更多关于网页的信息,这有助于它们更准确地处理和展示网页内容。
- 在这个例子中,
<head profile="http://example.com/metadata">
<title>文档标题</title>
</head>
常见的
profile属性值包括:
http://ogp.me/ns#:用于 Open Graph 协议,定义了网页在社交媒体平台上的展示方式。http://www.w3.org/1999/xhtml/vocab#:用于 XHTML 文档,定义了 XHTML 元素和属性的语义。http://www.w3.org/2006/vcard/ns#:用于 vCard 格式,定义了个人和组织信息的元信息类型。
- 为什么 要废弃
<head>标签的profile属性?
head标签的profile属性被废弃的原因 主要有两个方面:
声明元数据术语的不必要性:当
profile属性被用来 声明文档中用到的meta术语时,它是不需要的,完全可以省略。
因为这些元数据术语 可以通过其他方式进行声明和识别,所以profile属性 在这里没有存在的必要。用户可以直接去注册这些名字,而不需要通过profile属性来实现。触发特别用户代理行为的替代方法:当
profile属性被用来 触发特别的用户代理(user agent)行为时,可以用link元素替代。link元素提供了一种 更灵活和标准的方式 来定义 资源之间的关系,包括但不限于 样式表、favicons、预加载资源等。因此,profile属性的这一用途 也可以被link元素所替代。综上所述,由于
profile属性的功能 可以通过其他 HTML 元素和属性来实现,同时为了保持 HTML 规范的简洁性和一致性,W3C 在 HTML5 规范中将其废弃。开发者应当使用其他标准化的方法 来实现原有的功能。
2.2 head: 文档头部标签的 8 个子标签 简介 (必要的元数据、配置)
- 哪 8 个标签 可放在
<head>头部标签中 ?- 结构关系:
head >(meta + title + link + style + script + noscript + base + template) - ①
<base>链接 基准地址和目标打开位置 标签 - ②
<link>链接 标签 - ③
<meta>元信息 标签 - ④
<script>js 脚本 标签 - ⑤
<noscript>不支持 /禁用 JS脚本时 替代内容(提醒用户) - ⑥
<style>文档内部样式 标签 - ⑦
<title>文档标题 标签 - ⑧
<template>隐藏的内容模版 标签 - 这些子标签共同作用,为文档提供了 必要的元数据和配置,帮助浏览器 正确显示页面内容,并改善用户的浏览体验。
- 结构关系:
⑴ title: 文档标题(显示在 浏览器标签页)
-
⑴ head>
<title>文档标题 标签 -
<title>:定义文档的标题,显示在浏览器的标签页上。 -
例: 一个简单的 HTML 文档,带有 最基本的必需的元素:
<html>
<head>
<title>我的博客(我是文档的标题)</title>
</head>
<body>
文档的内容... ...
</body>
</html>
-
显示位置: 文档的标题,不会显示 在页面中,一般显示 在标题栏,具体位置是 标签页上;
-
为搜索引擎、用户 服务: 主要是给 搜索引擎看的,告诉搜索引擎 这个网页的 “内容重点”是什么;用户也可以 通过标签上的标题名 快速切换标签页,选择想看的内容;

<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<meta http-equiv="Content-Language" content="zh-cn" />
<title>我的博客(我是文档的标题)</title>
</head>
<body>
<p>这段文本会显示出来。</p>
</body>
</html>
- 显示结果:
⑵ base: 链接 默认地址 和 打开位置 (href 属性:默认地址、解析相对 URL;设置打开位置:搭配 target 属性)
- ⑵ head-
<base>链接 默认地址 和 打开位置 标签<base>:指定 基础 URL,用于 解析文档中 所有的相对 URL。- 所有链接的 默认地址或 打开位置;
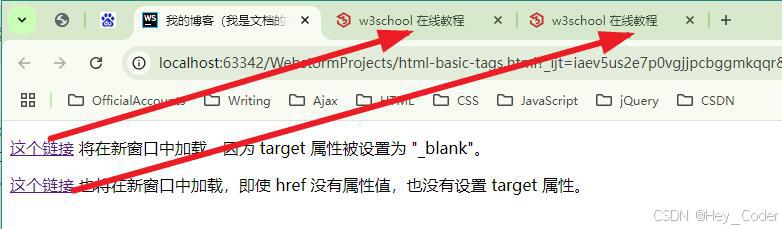
- 例: 使用
<base>链接 默认地址 和 打开位置 标签 使页面中的所有标签 在新窗口中打开。- base-
target="_blank"
- base-
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>我的博客(我是文档的标题)</title>
<!-- 设置了网页链接的默认地址和打开位置 -->
<base href="http://www.w3school.com.cn/" target="_blank">
</head>
<body>
<p>
<a href="http://www.w3school.com.cn" target="_blank">这个链接</a> 将在新窗口中加载,因为 target 属性被设置为 "_blank"。
</p>
<p>
<a href="">这个链接</a> 也将在新窗口中加载,即使 href 没有属性值,也没有设置 target 属性。
</p>
</body>
</html>
- 显示结果:
⑶ style: 设置 文档内部样式
-
⑶ head-
<style>样式标签- 设置 内部样式:
<style>:在 HTML 文档内部 直接设置 CSS 样式。
- 设置 内部样式:
-
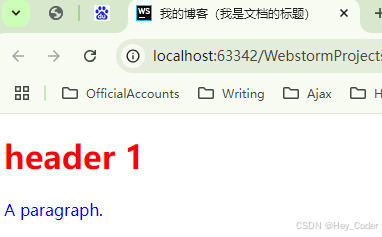
例: 使用
<head>头部 标签的 子元素<style>样式标签,给元素 设置样式;
<head>
<title>我的博客(我是文档的标题)</title>
<style>
h1 {color: red}
p {color: blue}
</style>
</head>
<body>
<h1>header 1</h1>
<p>A paragraph.</p>
</body>
- 显示结果
⑷ link: 链接 外部资源 (CSS 样式表、图标文件;搭配 rel、type、href 属性)
-
⑷ head-
<link>链接标签-
<link>:链接外部资源,如 CSS 样式表 、 图标文件。 -
例: 链接 CSS 文件(外部样式表):
<link rel="stylesheet" href="styles.css"> -
例: 链接图标:
<link rel="icon" href="favicon.ico" type="image/x-icon"> -
用于为网站设置一个图标,这个图标通常被称为“favicon”(favorite icon 的缩写,意为“收藏夹图标”)。
- 这个图标会显示在 浏览器的标签页、书签栏(收藏夹)、浏览器历史记录中,它可以帮助用户快速识别网站,以便于用户识别和区分不同的网站。
-
这个标签的各个属性含义如下:
rel="icon":指定了链接类型,告诉浏览器这是一个网站图标。href="favicon.ico":指定了图标文件的路径。这里假设图标文件名为favicon.ico,并且位于网站的根目录下。type="image/x-icon":指定了图标文件的类型,image/x-icon是 ICO 文件的 MIME 类型。
-
简而言之,这行代码的作用是 告诉浏览器在哪里 可以找到网站的图标文件,并将其显示在浏览器的相应位置。
-
-
例: 哔哩哔哩网站的 图标设置
<link rel="shortcut icon" href="https://i0.hdslb.com/bfs/static/jinkela/long/images/favicon.ico">
rel属性- 定义了 链接的性质,
shortcut icon表示这是一个快捷方式图标,也就是我们通常所说的 favicon。
- 定义了 链接的性质,
- 显示结果(标签页、收藏夹、浏览历史记录)
rel="shortcut icon"的使用
<link rel="shortcut icon">是一个 HTML 标签的用法,用于指定网页的快捷方式图标(Favicon)。尽管它是一个非标准的用法,但它在早期被广泛使用,并且在很多浏览器中仍然被支持。
尽管它不是标准的 HTML 规范,但很多浏览器(如Internet Explorer、早期的Firefox和Chrome)仍然支持这种写法。与
rel="icon"的区别
rel="shortcut icon":非标准用法,但兼容性较好,尤其在一些旧版本的浏览器中。rel="icon":标准的 HTML5 用法,推荐在现代网页开发中使用。
<link rel="icon" href="favicon.ico" type="image/x-icon">
- 在现代网页开发中,建议使用标准的
<link rel="icon">,以确保更好的规范性和兼容性。同时,还可以为不同设备和浏览器指定不同尺寸的图标,例如:
<link rel="icon" href="favicon.ico" type="image/x-icon">
<link rel="apple-touch-icon" sizes="180x180" href="apple-touch-icon.png">
<link rel="icon" type="image/png" sizes="32x32" href="favicon-32x32.png">
<link rel="icon" type="image/png" sizes="16x16" href="favicon-16x16.png">
⑸ meta: 文档 附加信息 (搭配 charset、http-equiv、 name、 content 属性)
-
⑸ head-
<meta>元信息 标签- 用于:告诉浏览器关于 文档的 附加信息;
-
例: 说明 文档的作者、 文档的修订 、文档的编辑软件;
<head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312" /> <meta name="author" content="w3school.com.cn"> <meta name="revised" content="David Yang,8/1/07"> <meta name="generator" content="Dreamweaver 8.0en"> </head>
<meta>:提供关于 HTML 文档的元数据,如 字符集、页面描述、关键词、重定向网址 等。
-
字符集声明:
<meta charset="UTF-8"> -
页面描述:
<meta name="description" content="这是我的博客,记录技术分享和生活点滴。"> -
关键词:
<meta name="keywords" content="博客,技术,分享"> -
重定向网址
-
如何 在网址已经变更的情况下,将用户 重定向到 另外一个地址 ?
-
使用
<meta>元信息标签<head> <meta http-equiv="Content-Type" content="text/html; charset=gb2312" /> <meta http-equiv="Refresh" content="5;url=http://www.w3school.com.cn" /> </head> <body> <p> 对不起。我们已经搬家了。您的 URL 是 <a href="http://www.w3school.com.cn">http://www.w3school.com.cn</a> </p> <p>您将在 5 秒内被重定向到新的地址。</p> <p>如果超过 5 秒后您仍然看到本消息,请点击上面的链接。</p>
-
-
<meta http-equiv="">:用于设置 HTTP 头部信息。<head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> </head> -
<meta name="viewport">:用于响应式设计,控制 视口的大小和比例。<head> <meta name="viewport" content="width=device-width, initial-scale=1.0"> </head> -
<meta property="og">:用于社交媒体分享时的 开放图谱(Open Graph)标签。- 开放图谱:一种协议,用于在社交媒体平台上分享网页内容时,提供网页的元数据,包括 标题、描述、图片等信息,以便在社交媒体上展示更加 丰富的内容预览.
<head> <meta property="og:title" content="我的博客文章"> <meta property="og:description" content="这篇文章介绍了..."> <meta property="og:image" content="image.jpg"> </head>
⑹ script: 嵌入脚本 / 引用脚本 (可搭配 src 属性)
-
⑹ head-
<script>元信息 标签- 用于 嵌入 或 引用 可执行脚本。
- 脚本语句 / 外部脚本文件:
script元素既可以 包含 脚本语句,也可以通过src属性 引入 外部脚本文件。 - MIME 类型: 必需的
type属性 规定脚本的 MIME 类型。
-
例: 引入 外部脚本,用
src资源地址 属性<!-- HTML4 and (x)HTML --> <script type="text/javascript" src="javascript.js"> <!-- HTML5 --> <script src="javascript.js"></script> -
例: 文档内部 嵌入脚本语句
<script type="text/javascript"> document.write("<h1>Hello World!</h1>") </script>
⑺ noscript:一段 HTML 代码 (浏览器 不支持/禁用 JS 时 显示)
<noscript>:定义在 JavaScript 被禁用时的替代内容。<head> <noscript> <div>您的浏览器不支持 JavaScript,或者已经禁用了 JavaScript。</div> </noscript> </head>
⑻ template:隐藏的模板内容 (客户端;不显示;可用 JS 动态插入 DOM 再显示)
-
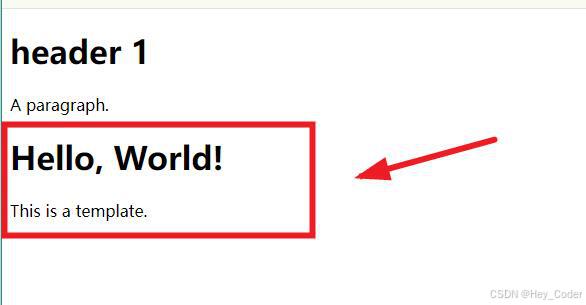
<template>/ˈtemplət/ 标签:是 HTML5 中引入的一个新元素,它用于定义一个 客户端的模(mú)板内容,这部分内容在页面加载时 不会被渲染,而是作为 隐藏的模板 保存在页面中。 -
<template>标签的内容:可以包含 HTML 元素、文本和脚本;- 显示:它们在初始时 不会显示在页面上,直到被 JavaScript 动态地插入到文档的 DOM(Document Object Model)中 才会显示。
-
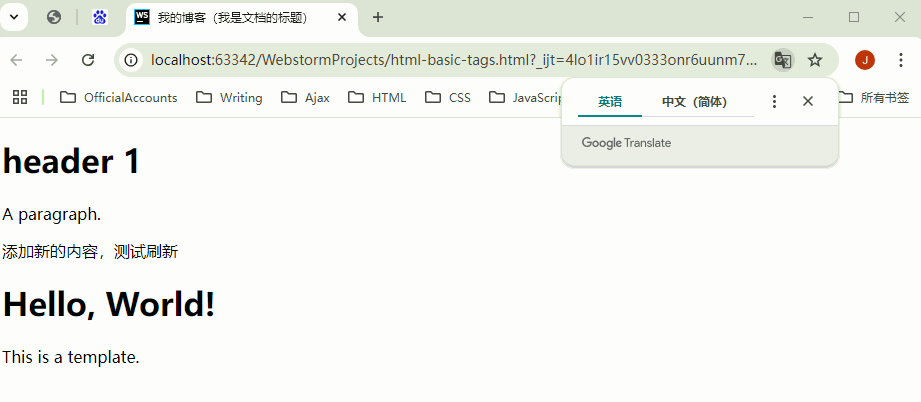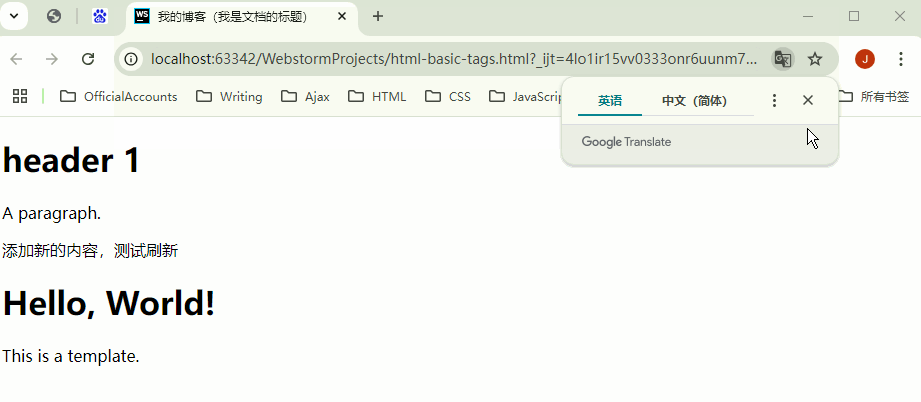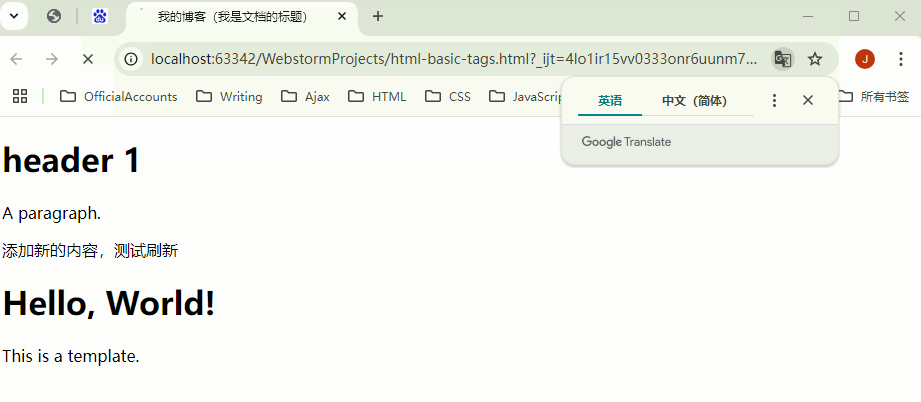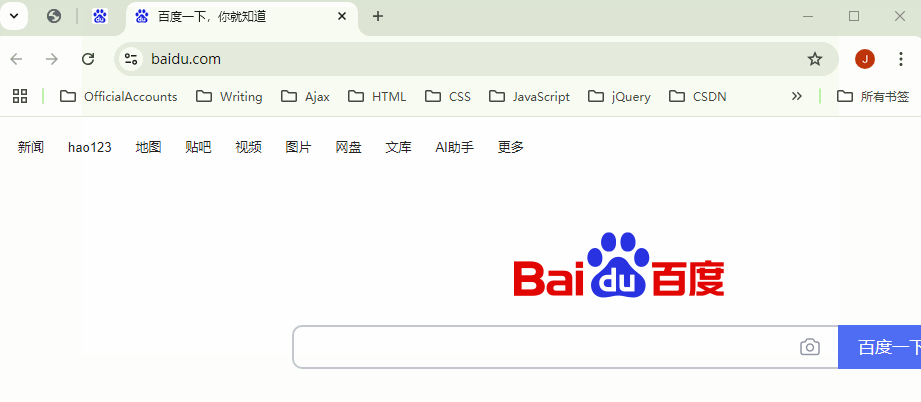
例: 下面是一个简单的
<template>使用示例:
<template id="myTemplate">
<div>
<h1>Hello, World!</h1>
<p>This is a template.</p>
</div>
</template>
<script>
// 当需要显示模板内容时,用 js 获取、克隆、添加到 DOM 中
document.addEventListener('DOMContentLoaded', (event) => {
var template = document.getElementById('myTemplate');
var clone = template.content.cloneNode(true);
document.body.appendChild(clone);
});
</script>
- 显示结果: 去掉 JS 代码 就不会显示了;
3. ★ meta 标签: 关于文档的 元数据 (文档数据的 数据)
-
<meta>标签用于:提供关于 HTML 文档的元数据(metadata)。- 元数据:是描述数据的数据,它不直接显示在页面上,但对页面的描述、行为和渲染有重要影响。
- 位置:
<meta>标签位于<head>部分中; - 用途:可以包含 多种类型的信息,包括 文档的字符编码、描述、关键词、作者、文档的最后修改时间等。
-
<meta>元信息标签的 限定位置- 文档头部
<head>头部 标签中,作为它的 子元素;head > meta;
- 文档头部
-
空标签:
<meta>元信息 标签 包含内容吗 ?- 空标签,不包含 任何内容。
-
正确关闭:
<meta>元信息 标签,HTML 与 XHTML 之间的差异- 在 HTML 中,
<meta>元信息 标签 没有结束标签。 - 在 XHTML 中,
<meta />元信息 标签必须 被正确地关闭。
- 在 HTML 中,
-
<meta>元信息的 使用说明<meta>提供 文档的 描述、关键词、字符编码、http 头部字段 等;- 使用
<meta>定义 与 文档相关联 的 名称/值 对;
<meta>标签 的属性列表- 必须指定一个:必须指定
name、http-equiv、charset和itemprop属性中的一个。 - 搭配使用:如果指定了
name、http-equiv或itemprop,则还必须指定content属性。否则,必须省略content属性。因为content属性是为前者 提供具体的值;没有前者,就不需要提供值了,就不需要这个属性了。
- 必须指定一个:必须指定
| 属性名 | 属性值 | 用于 |
|---|---|---|
① http-equiv | =content-security-policy,content-type , refresh,default-style,x-ua-compatible … | 名称/值对: HTTP 头部字段的名称 = http-equiv 属性值;HTTP 头部字段的值 = content 属性值。 |
② name | = author , description , keywords , generator , etc. | 提供 文档级的元数据(如 页面描述、关键词、作者等); |
③ charset | 字符编码名称; | 声明文档的字符编码。如果该属性存在,它的值必须是字符串“utf-8”,因为 utf-8 是 HTML5 文档的唯一有效编码。 |
④ content/ˈkɑːntent/ | =some_text | 定义与 http-equiv 、 name、 itemprop 属性 相关的值。 |
⑤ itemprop全局属性; <meta> 标签中 常用; | = author、name、url、image 等 | 提供 用户定义的元数据。 |
⑥ media | 媒体查询 | 指明 适用的媒体; |
⑦ scheme | =some_text | 用于 解释 content 属性值含义,如 指明 content 属性值的 格式。 |
3.1 content 属性: “名称/值”对 中的 值 (必须搭配 http-equiv 、name、itemprop 属性)
- ⑴
<meta>元信息 标签 的content内容 属性- 名称/值对 中的 值
- 如何提供 名称/值对 中的 值 ?
- 使用 meta-
content内容属性
- 使用 meta-
- 谁的值:此属性包含 和
http-equiv、itemprop、name属性 配对的值,具体的值 取决于http-equiv、itemprop、name的属性值。
- 如何提供 名称/值对 中的 值 ?
- meta-
content内容 属性值- 任何 有效的字符串;
- meta-
content内容属性的使用 要搭配什么属性 ?- 属性搭配: meta-
content内容 属性必须和name、itemprop、http-equiv属性 一起使用。 - name = value ⇒ x=a;
- x:
http-equiv、itemprop、name属性的值, 相当于 名称; - a:
content属性的值, 相当于 与名称配对的 值;
- 属性搭配: meta-
- 名称/值对 中的 值
3.2 http-equiv 属性: HTTP 头部字段的名称 (搭配 content 属性 = 头部字段的值;在客户端/浏览器 控制页面行为)
http-equiv属性-
在
<meta>标签中用来 模拟 HTTP 头部字段。- 这个属性 指定了一个 HTTP 头部字段的名称,而 搭配的
content属性 则提供了这个 头部字段的值。
- 这个属性 指定了一个 HTTP 头部字段的名称,而 搭配的
-
① 名称/值对:
- HTTP 头部字段的名称 =
http-equiv属性值; - HTTP 头部字段的值 =
content属性值; - 总结:通过两个属性,分别指定了 头部字段的名称,头部字段的值;
- HTTP 头部字段的名称 =
-
② 用途:
- ❶ 给浏览器信息,让文档内部 实现 头部字段的效果
http-equiv属性主要用于 模拟那些在 HTTP 协议中定义的 头部字段,使得这些 头部字段的效果 能够在 HTML 文档内部实现。它向浏览器提供 特定的指令或信息,以帮助正确和精确地 显示网页内容。
- ❷ 不修改服务器 、在客户端控制 页面行为
- 这个属性 允许网页开发者 在 HTML 文档内部 设置一些通常由服务器在 HTTP 响应中 发送的指令或信息。
- 使用
http-equiv属性可以 对浏览器的行为 进行精细控制,而 无需服务器端配置。 http-equiv属性提供了一种 在客户端(即 浏览器)控制页面行为 的方法,这在某些情况下 比服务器端配置更加灵活和方便。通过这种方式,开发者可以 在不修改服务器配置的情况下,对网页的加载、缓存、渲染等行为 进行调整。
- ❶ 给浏览器信息,让文档内部 实现 头部字段的效果
-
③
meta标签的http-equiv属性 语法格式是:<meta http-equiv="头部字段名称" content="头部字段的值">;
-
例: 告知 响应的过期时间;
<meta http-equiv="expires" content="31 Dec 2008"> -
HTTP 头部 就应该包含(“名称:值” 对):
- ɪkˈspaɪɚz/,到期、有效期;
expires:31 Dec 2008
-
⑴ 知识拓展:什么是 HTTP 头部字段?(请求/响应的元数据;网络通信)
- HTTP 头部字段(
HTTP headers):是 HTTP 协议中的重要组成部分,它们在 HTTP 请求和响应中 用于传递额外的信息。头部字段 允许客户端和服务器之间 传递关于 请求/响应的元数据,这些信息对于 正确处理 网络通信 至关重要。
以下是 HTTP 头部字段的一些主要用途:
① 请求和响应信息:
- 描述了 请求的性质(如 GET、POST、PUT、DELETE 等)和 响应的状态(如 200 OK、404 Not Found 等)。
② 资源定位:
- 通过
Host字段 指定请求的服务器域名和端口,允许在单个 IP 地址上 托管多个域名。③ 缓存控制:
- 使用
Cache-Control字段 控制响应的缓存行为,如 no-cache、no-store、max-age 等。④ 内容编码:
Content-Encoding字段 指定了响应内容的压缩格式,如 gzip,用于减少传输数据的大小。⑤ 内容类型和字符集:
Content-Type字段描述了响应内容的 MIME 类型,如 text/html、application/json 等。Content-Language字段 指定了内容的自然语言。⑥ 传输编码:
Transfer-Encoding字段 用于指定传输过程中使用的编码方式,如 chunked。⑦ 安全和认证:
Authorization/ˌɔːθərəˈzeɪʃ(ə)n/ 字段 用于提供认证信息。WWW-Authenticate/ɔːˈθentɪkeɪt/ 字段 用于服务器向客户端提示认证信息。⑧ 内容协商:
- 通过
Accept、Accept-Charset、Accept-Encoding和Accept-Language字段,客户端可以指定 它能够处理的媒体类型、字符集、编码和语言。⑨ 重定向:
Location字段 用于重定向响应中 指定新的资源位置。⑩ 条件请求:
If-Modified-Since和If-None-Match字段 用于实现缓存验证和避免不必要的数据传输。⑪ Cookie 管理:
Cookie和Set-Cookie字段 用于客户端和服务器之间交换 Cookie 信息,用于会话管理和用户跟踪。⑫ 跨源资源共享(CORS):
Access-Control-Allow-Origin和相关的 CORS 头部字段 用于控制资源 是否可以 被不同源的页面请求。⑬ 内容安全策略(CSP):
Content-Security-Policy字段 用于定义资源加载和执行的安全策略,以减少 XSS 攻击的风险。⑭ 服务器和客户端信息:
Server字段 提供了服务器软件的信息。User-Agent字段 提供了客户端(浏览器)的信息。HTTP 头部字段 提供了一种灵活和强大的方式 来传递关于请求和响应的重要信息,它们对于确保网络通信的效率、安全性和正确性至关重要。
-
HTTP 头部字段(HTTP headers)用在 HTTP 请求和响应消息中,它们提供了 关于 请求和响应的附加信息。
- 这些字段 允许客户端(如浏览器)和服务器之间 传递元数据,这些信息对于 正确处理网络通信 至关重要。
-
以下是 HTTP 头部字段的一些具体使用场景:
① 客户端请求(Request):
- 在客户端发送到服务器的 HTTP 请求中,头部字段可以包含请求的元信息,如:
User-Agent:标识发起请求的 客户端类型和版本。Accept:客户端能够处理的内容类型。Accept-Language:客户端偏好的语言。Accept-Encoding:客户端能够处理的压缩类型。Host:请求的服务器域名,用于虚拟主机。Referer:包含一个 URL,指向 当前请求的来源页面。Authorization/ˌɔːθərəˈzeɪʃ(ə)n/:认证信息,如用户名和密码。Cookie:存储在客户端的服务器状态信息。② 服务器响应(Response):
- 在服务器发送回客户端的 HTTP 响应中,头部字段提供了响应的元信息,如:
Content-Type:响应内容的 MIME 类型。Content-Length:响应体的大小。Cache-Control:控制缓存行为的指令。Expires:响应的过期时间。Last-Modified:资源最后修改的时间。ETag:资源的特定版本标识符。Set-Cookie:服务器发送给客户端的 Cookie 信息。Location:用于重定向的 URL。Server:标识服务器软件的信息。WWW-Authenticate/ɔːˈθentɪkeɪt/:服务器向客户端请求认证信息。③ 缓存控制:
- HTTP 头部字段用于控制和验证缓存,如
If-Modified-Since和If-None-Match。④ 内容安全策略(CSP):
Content-Security-Policy头部字段用于 增强 Web 应用的安全性,防止跨站脚本(XSS)攻击。⑤ 跨源资源共享(CORS):
- 通过
Access-Control-Allow-Origin等头部字段控制资源 是否可以被不同源的页面请求。⑥ 重定向:
- 使用
301 Moved Permanently、302 Found、303 See Other和307 Temporary Redirect等状态码和Location头部字段实现页面重定向。⑦ 压缩和编码:
Content-Encoding头部字段用于指定内容的压缩格式,如 gzip。⑧ 认证和授权:
Authorization/ˌɔːθərəˈzeɪʃ(ə)n/ 和WWW-Authenticate头部字段用于处理 HTTP 认证。⑨ 条件请求:
If-Match、If-None-Match、If-Modified-Since和If-Unmodified-Since头部字段用于执行条件请求。HTTP 头部字段是 HTTP 通信中不可或缺的一部分,它们提供了必要的上下文信息,帮助客户端和服务器正确地处理请求和响应。
⑵ 使用 meta 标签 可以替代服务器配置吗?
-
使用
<meta>标签可以在一定程度上 模拟或替代某些服务器配置的效果,特别是在客户端(浏览器)层面上。meta标签通过在 HTML 文档中 设置元数据 来影响浏览器如何处理页面,但它们并不能替代所有的服务器配置。
-
以下是一些
meta标签可以替代或模拟的服务器配置场景,以及它们的局限性:
① 字符集设置:
meta标签可以通过http-equiv="Content-Type"设置页面的字符编码,这可以替代服务器在 HTTP 响应头中设置Content-Type的效果。② 缓存控制:
- 使用
http-equiv="Cache-Control"可以模拟服务器端的缓存控制指令,如no-cache或max-age。③ 页面刷新与重定向:
meta标签可以通过http-equiv="refresh"实现页面的自动刷新或重定向,这不需要服务器端的配置。④ 内容安全策略(CSP):
meta标签可以通过http-equiv="Content-Security-Policy"设置 CSP,这是一种客户端的安全性设置,服务器也可以通过 HTTP 头部设置 CSP。⑤ 浏览器兼容性:
meta标签可以通过http-equiv="X-UA-Compatible"/kəmˈpætəb(ə)l/ 强制 IE 浏览器使用 最新的渲染模式,这可以替代服务器端的一些配置。
局限性:
- 安全性:
meta标签的设置可以被用户或中间人攻击者修改,因此对于安全性至关重要的设置(如 CSP),最好在服务器端设置,以确保它们不能被篡改。- 范围:
meta标签只影响 当前页面,而服务器配置可以全局应用于 所有页面。- 控制级别:服务器配置提供了更细粒度的控制,例如 基于不同的用户代理、请求路径等条件 应用不同的规则。
- HTTP 响应码:对于需要特定 HTTP 响应码的情况(如 301重定向),必须使用服务器配置。
- 总的来说,
meta标签是强大的工具,可以用于 控制浏览器行为 和增强页面的元数据,但它们 不能完全替代服务器配置的所有功能,特别是在安全性和全局控制方面。在实际应用中,最好结合使用<meta>标签和服务器配置,以实现最佳的性能和安全性。
⑶ http-equiv 属性 常用值
- HTTP 头部字段名称 属性:
http-equiv-
枚举属性
http-equiv属性 所有 允许的值 都是 特定 HTTP header 的名称;- equiv:equivalent,/ɪˈkwɪvələnt/,对等的人或事物;简而言之,该属性的值 都是 和 HTTP 头部里的名称 对等的名称;
-
向浏览器 传递信息: 相当于 http 的文件头作用,可以向浏览器 传回一些有用的信息,以帮助 正确和精确地 显示网页内容;
-
http-equiv属性是一个枚举属性,包含以下关键字和状态:
| 关键字 | 符合规范 Conforming | 状态 State | 简短描述 Brief description |
|---|---|---|---|
| ❶ content-type(内容类型;设置字符集) | 是 | Encoding declaration | 设置字符集的另一种形式。 |
| ❷ default-style(默认样式表名称) | 是 | Default style | 设置默认 CSS 样式表集的名称。 |
| ❸ refresh | 是 | Refresh | 作为 刷新 或 定时重定向。 |
| ❹ x-ua-compatible(IE 浏览器使用最新渲染模式) | 是 | X-UA-Compatible | 在实践中,鼓励 Internet Explorer 更严格地遵循规范。 |
| ❺ content-security-policy(内容安全策略) | 是 | Content security policy | 在文档中执行内容安全策略。 |
| ❻ content-language(内容语言) | 否 | Content language | 设置 pragma-set 默认语言。 |
| ❼ set-cookie(设置缓存) | 否 | Set-Cookie | 没有效果。 |
① 内容 安全策略:http-equiv=“content-security-policy” (有效来源;页面 允许加载、执行的 资源来源;减少网站漏洞;减少攻击)
- 内容安全策略(CSP):
- 当需要 增强页面的安全性,防止 跨站脚本攻击(XSS)时,可以使用
http-equiv="Content-Security-Policy"。- n. 跨站脚本攻击(Cross-Site Scripting):一种常见的 网络安全漏洞,攻击者通过在目标网站上 注入恶意脚本,从而在用户的浏览器上 执行恶意操作。
- 内容安全策略主要指定: 允许的 服务器源和脚本端点,指定 被允许加载(执行)的来源,这有助于 防止跨站点脚本攻击。
meta标签的http-equiv属性用于模拟 HTTP 响应头的效果,其中content-security-policy是http-equiv属性的一个常见值,用于定义页面的内容安全策略(CSP)。
- 当需要 增强页面的安全性,防止 跨站脚本攻击(XSS)时,可以使用
-
以下是如何使用
meta标签的http-equiv="Content-Security-Policy"属性的例子: -
① 定义内容安全策略:
- 通过设置
http-equiv="Content-Security-Policy",可以指定 哪些动态资源被允许执行,这有助于 防止跨站脚本(XSS)攻击。
<meta http-equiv="Content-Security-Policy" content="default-src 'self'; script-src 'self' https://trustedscripts.example.com">- 在这个例子中,
default-src指令设置了 默认的资源加载策略,只允许加载来自 同一源/ 当前源('self')的资源,script-src指令指定了 允许执行脚本的来源,包括 当前源和https://trustedscripts.example.com。
- 通过设置
-
② 设置多个策略:
- 可以在一个
meta标签中设置多个内容安全策略。
<meta http-equiv="Content-Security-Policy" content="img-src 'self' data:url; font-src https://fonts.example.com; style-src 'self' 'unsafe-inline'">- 这个例子中,
- 图片来源
img-src指令: 允许加载 来自当前源和data:url的图片, - 字体来源
font-src指令: 允许从https://fonts.example.com加载字体资源, - 样式来源
style-src指令:允许加载来自同一来源的样式表,允许使用 内联样式('unsafe-inline')(虽然不推荐,但有时可能需要)。
- 图片来源
- 可以在一个
-
③ 报告安全事件:
- 可以使用
report-uri指令指定一个 URL,浏览器将向该 URL 发送违规报告。
<meta http-equiv="Content-Security-Policy" content="script-src 'self'; report-uri /csp-violation-report-endpoint">- 这个例子中,所有脚本 必须来自当前源,并且任何违反 CSP 的行为 都会被报告到服务器的
/csp-violation-report-endpoint路径。
- 可以使用
-
使用
http-equiv="Content-Security-Policy"时,content属性的值是一个字符串,其中包含了一系列的指令和值,这些指令 定义了页面 可以加载和执行的 资源来源。通过合理配置 CSP,可以增强网站的安全性,防止多种类型的攻击。
▲ 知识拓展:什么是 内容安全策略 CSP?
- 知识拓展:什么是 CSP?
- CSP(Content/ˈkɑːntent/ Security/sɪˈkjʊrəti/ Policy/ˈpɑːləsi/,内容安全策略)是一种额外的安全层,用于帮助 检测和减轻某些类型的攻击,特别是跨站脚本(XSS)和数据注入攻击。CSP 通过允许网站管理员 定义哪些动态资源是允许执行的,来减少攻击者 利用网站漏洞 注入恶意脚本的机会。
CSP 的主要目标包括:
防止XSS攻击:通过限制可以加载和执行的脚本,减少攻击者注入恶意脚本的风险。
减少数据注入攻击:防止攻击者 通过 SQL 注入等手段 篡改网站后端数据。
提供更细粒度的控制:允许开发者精确控制 资源加载策略,例如 脚本、样式、图片、字体等。
报告违规行为:CSP 可以配置为 报告违反安全策略的行为,而不影响页面的正常加载。
增强浏览器安全:CSP 是浏览器实现的安全特性,与服务器配置无关,增强了浏览器对网站内容的控制。
-
CSP 通过一系列的策略指令实现,这些指令在 HTTP 响应头或者 HTML 的
meta标签中设置。以下是一些常用的 CSP 指令: -
Content-Security-Policy(CSP),CSP 通过 指定 有效源(即浏览器认可的 可执行脚本或资源的 有效来源)来实现。
- 以下是 CSP 中常见的属性值及其含义:
- Fetch 指令
default-src:为其他 未明确指定的资源类型 提供默认的来源策略,定义默认加载策略。script-src:指定 允许加载和执行 JavaScript 脚本的来源,控制 JavaScript 的加载来源。script-src-elem:指定 允许加载<script>元素的来源。script-src-attr:指定 允许加载 内联事件处理器(如onclick)的来源。style-src:指定允许加载 CSS 样式的来源。style-src-elem:指定允许加载<style>元素和<link>元素的来源。style-src-attr:指定允许加载 单个 DOM 元素的 内联样式的来源。img-src:指定允许加载 图片和图标的来源。media-src:指定允许加载 音频和视频 媒体文件的来源。font-src:指定允许加载 字体文件的来源。connect-src:限制允许通过脚本接口加载的 URL,控制 XHR、WebSocket 等连接的来源。child-src:为 Web Worker 和其他嵌套浏览环境(如<frame>和<iframe>)指定合法来源。frame-src:为加载到<frame>和<iframe>中的嵌套浏览环境 指定合法来源。worker-src:指定允许加载 Worker 脚本的来源。object-src:指定允许加载<object>或<embed>标签的来源,控制插件(如 Flash)的加载来源。manifest-src:指定允许加载 应用程序清单文件的来源。fenced-frame-src(实验性):指定允许加载到<fencedframe>元素的内嵌浏览器内容的来源。- 文档指令
base-uri:限制在 DOM 中<base>元素可以使用的 URL,限制<base>标签的URL。sandbox:类似<iframe>的sandbox属性,为请求的资源 启用沙盒模式,限制页面行为。- 导航指令
form-action:限制 表单提交目标的 URL。frame-ancestors:指定可能嵌入页面的有效父项<frame>、<iframe>、<object>或<embed>。- 报告指令
report-to:提供代表一个或多个报告端点的 token,用于发送 CSP 违规信息,指定违规报告发送的端点。report-to指令仅在 CSP 3 中引入,部分浏览器可能不支持。如果需要兼容更多浏览器,可以使用report-uri指令(已废弃,但广泛支持)report-uri(已弃用):给浏览器提供发送 CSP 违规报告的URL(已弃用,推荐report-to)。- 其他指令
upgrade-insecure-requests:让浏览器将所有不安全的URL(通过 HTTP 访问)当作已经被安全的URL(通过 HTTPS 访问)替代,自动将 HTTP 资源升级为 HTTPS。require-trusted-types-for(实验性):在 DOM XSS 注入落点强制执行 Trusted Type。trusted-types(实验性):用于指定Trusted Type策略的允许值。- 弃用指令
block-all-mixed-content(已弃用):当页面使用 HTTPS 时,阻止使用 HTTP 的资源加载。- 值类型
'none': 禁止加载 任何资源。'self': 允许 同源资源。'unsafe-inline': 允许 内联资源(如<script>、<style>)。'unsafe-eval': 允许 动态代码执行(如eval)。'strict-dynamic': 允许通过 非解析器插入的脚本 加载其他脚本。'nonce-<value>': 允许带有特定 nonce 值的脚本或样式。'<hash-algorithm>-<base64-value>': 允许 特定哈希值的脚本或样式。'<host>': 允许指定 主机或域名。'<scheme>:: 允许指定 协议(如https:)。- CSP 的配置方式有两种:一种是通过 HTTP 响应头 Content-Security-Policy 设置;另一种是通过 HTML 页面中的
<meta>标签设置。
- 例如,以下 CSP 策略只允许加载 来自当前源的脚本和样式,并且报告任何违规到指定的 URL:
<meta http-equiv="Content-Security-Policy" content="script-src 'self'; style-src 'self'; report-uri /csp-report-endpoint">
- 或者作为 HTTP 响应头:
Content-Security-Policy: script-src 'self'; style-src 'self'; report-uri /csp-report-endpoint
- CSP 是一个强大的工具,可以帮助提高网站的安全性,但它需要正确配置和定期维护 以保持其有效性。
② 默认样式表:http-equiv=“default-style” (搭配 link[title]、 style[title];content 属性)
-
<meta>标签的http-equiv="default-style"属性值:- 用于:指定 默认的样式表,当浏览器不支持链接的样式表 或者用户没有选择其他样式表时,将使用这个默认样式表。
- 使用搭配:这个属性 通常与
<link>标签一起使用,<link>标签定义了文档的样式表,并且可以通过rel属性和title属性来 指定样式表的关系和名称。 - 配对属性
content的属性值:content属性的值 必须匹配 同一文档中的一个link元素上的title属性的值,或者 必须匹配 同一文档中的一个style元素上的title属性的值。- emmet 语法表示:如果
http-equiv=“default-style”⇒ 则meta[content] = link[title] | style[title]
- emmet 语法表示:如果
-
以下是 如何使用
meta标签的http-equiv="default-style"属性的步骤: -
① 链接样式表:
-
使用
<link>标签链接一个或多个样式表,并为每个样式表 指定一个title属性,这个title值 将被用作 识别样式表的标识符。<link rel="stylesheet" href="default.css" title="Default Style"> <link rel="stylesheet" href="fancy.css" title="Fancy Style">
-
-
② 指定默认样式表:
- 使用
meta标签的http-equiv="default-style"属性来指定默认的样式表。content属性的值应该与其中一个<link>标签的title属性值相匹配。
<meta http-equiv="default-style" content="Default Style"> - 使用
-
在这个例子中,
default.css被指定为默认样式表,它的title属性值为"Default Style",这与meta标签的content属性值相匹配。这意味着,如果用户没有选择其他样式表,或者浏览器不支持样式表,浏览器将使用default.css作为页面的样式表。- 请注意,
http-equiv="default-style"属性的使用 并不是所有浏览器都支持,而且它的行为可能因浏览器而异。因此,确保在多个浏览器和设备上测试你的页面,以确认样式表的正确应用。
- 请注意,
③ 自动刷新页面(重新加载)、重定向(自动加载 新页面):http-equiv=“refresh” (必须搭配 content 属性)
<meta>标签的http-equiv="refresh"属性- ❶ 用于:自动刷新页面、重定向页面;
- ❷ 用法:模拟 HTTP 响应头中的
Refresh头。- 这个属性 可以让浏览器 在指定的延迟后 刷新页面 或重定向到另一个页面。
- 刷新页面:自动重新加载 本页面,获取最新资源;
- 重定向:自动加载 其他页面,获取别的页面资源,查看新网页内容;
- 这个属性 可以让浏览器 在指定的延迟后 刷新页面 或重定向到另一个页面。
- ★ 自动刷新(重新加载) 和 重定向(跳转新页面): meta-
http-quiv="refresh"- ❶ 重新加载 + 设置时间间隔(刷新时间):
- 如果 搭配的
content内容值 属性 只包含一个正整数,则是 重新载入页面的 时间间隔,以 秒 为单位;
- 如果 搭配的
- ❷ 重定向 到指定链接 + 设置时间间隔:
- 如果
content包含一个正整数 并且跟着一个字符串,则是 重定向到 指定链接,并设置 时间间隔,以 秒 为单位;- 格式:
<meta http-equiv="refresh" content="时间(正整数);url=网址">- 例:
<meta http-equiv="refresh" content="5;url=https://www.baidu.com">
- 例:
- 属性分隔:空格;
- 属性值分隔:分号;
content的两个属性值 以分号;分隔。
- 格式:
- 如果
- 值 “
refresh” 应该 慎重使用,因为它会使得 页面 不受用户控制。
- ❶ 重新加载 + 设置时间间隔(刷新时间):
-
以下是 如何使用
meta标签的http-equiv="refresh"属性的例子: -
例: 页面自动刷新:
- 如果你想要页面在 5 秒后自动刷新,可以使用以下代码:
<meta http-equiv="refresh" content="5">- 这里,
content属性的值 “5” 表示刷新的延迟时间,单位是秒。- 每隔几秒自动刷新,重新获取资源,如果有新的资源 会更新;
- 例: 页面 自动重定向,自动加载新页面
- 如果你想要页面在 3 秒后自动跳转到另一个 URL,可以使用以下代码:
<meta http-equiv="refresh" content="3;url=https://www.baidu.com">
-
这里,
content属性值 表示页面将在 3 秒后重定向到https://www.baidu.com。 -
显示结果:会在几秒后,在当前窗口 自动加载其他页面,即 跳转到新页面;
- 请注意:
- ❶ 影响用户体验:
http-equiv="refresh"属性的使用 可能会 影响用户体验,因为它会在用户不知情的情况下 刷新或重定向页面。- 重定向 有些 不利于 有视力问题的人
- 使用
refresh值设置的页面 存在时间间隔过短的风险。使用辅助技术(如屏幕阅读器)导航的人 可能无法在自动重定向之前 阅读和理解页面内容。 - 突然的、未经宣布的页面内容更新 也可能让视力低下的人 感到困惑。
- 使用
- 重定向 有些 不利于 有视力问题的人
- ❷ 谨慎使用:因此,在使用时应该谨慎,并确保这种自动刷新或重定向 对用户是有益的。此外,一些现代浏览器 可能会限制或忽略
meta标签中的refresh行为,特别是在涉及跨域重定向时。
- ❶ 影响用户体验:
④ 指定 IE 用最新渲染模式:http-equiv=“x-ua-compatible”(IE 用当前 最新渲染引擎;必须搭配 content 属性;仅限 IE 浏览器;兼容 IE)
meta标签的http-equiv="x-ua-compatible"属性值-
❶ 用于:模拟 HTTP 响应头的效果,其中
X-UA-Compatible/kəmˈpætəb(ə)l/ 是一个常见的使用场景,用于 控制浏览器模式。 -
❷ 作用:确保页面在 IE 浏览器中的兼容性
- 对于需要在多个版本的 IE 浏览器中测试和显示一致性的网页,
X-UA-Compatible属性值 可以用来确保页面 在不同 IE 版本中的兼容性。 - 综上所述,
X-UA-Compatible属性值 主要与 IE 浏览器的兼容性设置有关,对于 非IE浏览器,这个属性没有效果。- 随着 IE 浏览器的逐渐淘汰和现代浏览器的发展,
X-UA-Compatible属性值的使用 越来越少,但在处理旧版 IE 浏览器的兼容性问题时仍然有其价值。
- 随着 IE 浏览器的逐渐淘汰和现代浏览器的发展,
- 对于需要在多个版本的 IE 浏览器中测试和显示一致性的网页,
-
-
以下是如何使用
http-equiv="X-UA-Compatible"属性的例子: -
例: 启用 IE 的当前最高版本 渲染模式(当前版本 匹配的渲染模式)
- 如果你希望页面在 Internet Explorer 中使用 当前最新的渲染引擎(即 IE=edge 模式),
- 这个设置主要是为了:让 IE 浏览器的用户 能够获得 【与他们 浏览器版本相匹配的 最佳浏览体验】。
- 可以使用以下代码:
<meta http-equiv="X-UA-Compatible" content="IE=edge"> - 如果你希望页面在 Internet Explorer 中使用 当前最新的渲染引擎(即 IE=edge 模式),
-
这行代码指示 IE 浏览器使用 其支持的最高版本渲染模式,例如 在 IE11 中使用 IE11 模式,而不是使用 较旧的兼容性模式。
- 这对于确保页面在 IE 浏览器中具有一致的外观和行为非常重要,尤其是在处理 CSS 和 JavaScript 兼容性问题时。
IE=edge表示:告诉 IE 浏览器使用 最新的可用的渲染引擎 来显示页面,即尽可能使用 IE 的最新版本模式 来渲染页面。- 指示 IE 浏览器使用 最高版本的渲染模式 来显示页面,忽略任何可能的 兼容性视图(即 不使用旧版 IE 的渲染模式)。
- 这种设置通常用于: 确保在 IE 浏览器中 页面能够以最新的标准和特性来渲染,从而提供 更好的用户体验和页面性能。
- 这对于旧版 IE 浏览器尤其重要,因为它们可能默认使用 兼容性视图 来渲染页面,这可能会导致现代 Web 特性 无法正确显示或工作。
- 如果用户的浏览器是 IE9 还未更新到 IE11 时,用什么渲染模式?
- 这个设置会告诉 IE9 使用它所支持的最新渲染模式。因此,在 IE9 中,页面将会使用 IE9 的最高版本渲染模式来显示,而不是 IE11 的模式。
- IE=edge 指令的作用: 是让浏览器 使用 最新的可用模式,但如果用户的浏览器版本是 IE9,还没有更新,那么它没有 IE11 的渲染模式,所以它 将只能使用 IE9 的模式。
- 这意味着 即使您指定了 IE=edge,IE9 用户仍然会 以 IE9 的标准来查看网页,而不是 IE11,只有更新了 才能用新版本的渲染模式。
- 因此,对于 IE9 用户来说,即使设置了 IE=edge,他们看到的页面渲染效果仍然是基于 IE9 的渲染引擎。
- 这个设置主要是为了:让 IE 浏览器的用户 能够获得 【与他们 浏览器版本相匹配的 最佳浏览体验】。
-
忽略 属性值
http-equiv="x-ua-compatible"的情况:- ❶ 其他现代浏览器 不用此属性值 指定渲染引擎:在某些情况下,如果指定了
X-UA-Compatible为IE=edge,现代浏览器(如 Chrome、Firefox)会忽略这个指令,因为它们不使用 IE 的渲染引擎。 - ❷ 仅用于 旧版 IE 浏览器:这意味着这个指令 主要用于旧版 IE 浏览器。
- 控制 不同版本的 Internet Explorer 浏览器 如何渲染网页。
- 除了 IE 浏览器外,其他浏览器如 Chrome、Firefox 等并不识别这个属性。
- 使用
X-UA-Compatible属性 可以确保你的网站 在不同浏览器中 提供一致的用户体验,尤其是在处理跨浏览器兼容性时。然而,随着现代浏览器的发展,这个属性的使用越来越少,因为主流浏览器 已经提供了良好的兼容性和最新的 Web 标准支持。
- ❶ 其他现代浏览器 不用此属性值 指定渲染引擎:在某些情况下,如果指定了
- 例: 控制 IE 浏览器的渲染模式:指定 IE 浏览器使用 特定的 IE 版本渲染模式
- 当你希望在不同版本的 IE 浏览器中保持一致的渲染效果时,可以通过设置
X-UA-Compatible属性 来指定浏览器使用 特定的 IE 版本渲染模式。例如:<meta http-equiv="X-UA-Compatible" content="IE=7">- 这行代码会让 IE 浏览器以 IE7 的渲染模式 来渲染页面。
- 强制 IE 浏览器使用 IE7 的渲染模式来显示页面,忽略任何更高版本的 IE 可能提供的更新的渲染引擎。
- 这种设置通常用于:确保在 旧版 IE 浏览器上 提供一致的页面渲染效果,尤其是在某些旧网站或旧版 Web 应用中,开发者可能需要 确保页面的兼容性。
- 然而,随着 IE 浏览器的逐渐淘汰和现代浏览器的发展,这种设置的使用 越来越少,因为它限制了页面使用现代 Web 标准和技术的能力
- 当你希望在不同版本的 IE 浏览器中保持一致的渲染效果时,可以通过设置
- 例: 配合 Google Chrome Frame 使用:
- 在过去,Google Chrome Frame 允许在 IE 浏览器中使用 Chrome 内核。
- 通过设置
X-UA-Compatible属性,可以指示页面在安装了 Chrome Frame 的 IE 浏览器中 使用 Chrome 内核渲染:
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">- 这行代码意味着:如果用户安装了 Chrome Frame,页面将 使用 Chrome 内核渲染;否则,使用 IE 的最高版本内核渲染。
- 通过设置
- 在过去,Google Chrome Frame 允许在 IE 浏览器中使用 Chrome 内核。
- 例: 淘宝网中 搭配的
content属性值
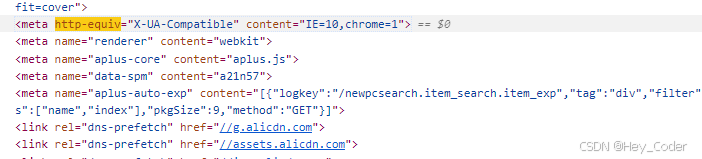
<meta http-equiv="X-UA-Compatible" content="IE=10,chrome=1">
<meta>标签用于:设置X-UA-CompatibleHTTP 响应头,这是一种用于 控制浏览器渲染模式 的元数据设置。http-equiv="X-UA-Compatible":这部分告诉浏览器这个meta标签 等同于发送了一个名为X-UA-Compatible的 HTTP响应头。content="IE=10,chrome=1":这部分指定了X-UA-Compatible头的内容。IE=10表示:尝试让 IE 浏览器 以 IE 10 的模式渲染页面chrome=1表示:如果用户安装了 Google Chrome Frame 插件(这是一个已经停止支持的技术,允许在 IE 中使用 Chrome 的渲染引擎),则尝试使用 Chrome Frame 来渲染页面。
- 这种设置通常用于:确保在旧版 IE 浏览器上 提供更好的兼容性和性能。然而,由于 Google Chrome Frame 已经不再被支持,且现代浏览器 已经提供了很好的兼容性,这种设置在当前的 Web 开发实践中已经较少使用。
⑤ 页面 过期时间:http-equiv=“expires”( 不推荐使用;搭配 content 属性;到期下载最新版本; GMT 时间 或 秒数;推荐 服务器端 HTTP 缓存控制 Cache-Control 响应头 设置)
-
<meta>标签的http-equiv="expires"属性- ❶ 用于:模拟 HTTP 响应头中的
Expires/ɪkˈspaɪɚz/,到期,有效期 头,它可以让网页 在指定的时间后过期,迫使浏览器 每次都从服务器 获取最新的页面内容。这通常用于 确保用户访问的是 最新的页面版本,而不是 缓存中的旧版本。 - ❷ 时间格式:必须使用 GMT 时间格式。
- 点击查看: 知识拓展:什么是 GMT 时间?
- 点击查看: 知识拓展:什么是 GMT 时间?
- ❶ 用于:模拟 HTTP 响应头中的
-
为什么 不推荐使用
meta标签的http-equiv="expires"属性值 ?- 替代:推荐 服务器端 HTTP 缓存控制 Cache-Control 响应头 设置;
兼容性和一致性问题:
Expires属性值使用一个绝对时间来指定资源的过期时间。这个时间戳 是服务器定义的,而本地时间的取值 来自客户端。如果服务器和客户端的时钟不一致,或者客户端的时间被故意修改,那么Expires的工作机制就会受到影响,导致意料之外的结果。优先级问题:
Expires的优先级在 HTTP 头部属性中是最低的。当Expires和Cache-Control同时存在时,只有Cache-Control生效。HTTP/1.1的替代方案:
Expires是HTTP/1.0时代的产物,而现代浏览器使用的都是 HTTP/1.1协议。在 HTTP/1.1中,Cache-Control提供了更精确细致的缓存功能,是Expires的替代品。Cache-Control可以提供更多的指令,如max-age、no-cache等,使得缓存控制更加灵活和强大。实现的复杂性:
Expires使用的是具体的时间点,而Cache-Control使用的是相对时间(如max-age),这使得Cache-Control更容易理解和实现,因为它不需要处理复杂的时间格式和时区问题。控制力度不足:
Expires只能指定一个绝对的过期时间,而不能提供 其他缓存控制指令,如 禁止缓存或设置最小新鲜时间等。Cache-Control提供了更多的控制选项,使得开发者可以根据需要 精细控制缓存行为。综上所述,由于
Expires的这些局限性和Cache-Control的优势,现代 Web 开发中推荐使用Cache-Control而不是Expires来管理 HTTP 缓存。
-
例 1: 使用
<meta>标签的http-equiv="expires"属性,指定 具体的过期时间<meta http-equiv="expires" content="Wed, 21 Oct 2026 07:28:00 GMT">- 在这个例子中,
content属性的值 设置了一个具体的日期和时间(Wed, 21 Oct 2026 07:28:00 GMT),2026年这是 页面过期的时间。- 一旦到达这个时间点,浏览器会认为 页面已经过期,并在下次用户访问时 从服务器重新下载页面。
- “Wed, 21 Oct 2026 07:28:00 GMT” 是按照GMT(格林尼治标准时间)时区表示的时间,而北京时间 比 GMT 时间快 8 小时。
- GMT 时间 转换成北京时间:
- 转换成北京时间(东八区,UTC+8/ GMT+8),需要在 GMT 时间基础上 加上8小时。
- 北京时间 = GMT+ 8;GMT = 北京时间 - 8;
- 所以,当 GMT 时间为:2026 年 10 月 21 日星期三 07:28:00时,北京时间是:2026 年 10 月 21 日星期三 15:28:00;
- 转换成北京时间(东八区,UTC+8/ GMT+8),需要在 GMT 时间基础上 加上8小时。
- 在这个例子中,
-
例 2: 使用 相对于当前时间的过期时间,设置页面 立即过期,每次访问 都要重新加载页面
<meta http-equiv="expires" content="0">- 这个例子中,
content属性的值设置为"0",意味着页面 立即过期,浏览器会在每次访问时 都重新加载页面。content="0":表示网页的过期时间。这里设置为 0,意味着网页在加载时 就已经过期;- 即 网页的内容在访问时 已经“过期”,浏览器不应该使用 本地缓存的版本,而是每次都从服务器 重新加载最新的内容。这样可以确保用户看到的是 最新的网页版本,而不是 旧的缓存版本。
- 这个例子中,
-
请注意,大多数现代浏览器和缓存服务器 可能会忽略
<meta>标签中的expires属性,而更倾向于使用 HTTP 响应头中 的 缓存控制Cache-Control/kæʃ/,/kənˈtroʊl/ 指令。- 因此,使用服务器端配置 来控制缓存行为 通常是更可靠的做法。
- 不过,在没有服务器端控制或需要快速设置时,
<meta>标签的expires属性 可以作为一个临时的解决方案。
-
使用场景:
- 当网页内容经常更新时(例如新闻网站、动态数据页面等),使用这段代码可以防止用户看到过时的内容。
- 用于开发和调试阶段,确保每次刷新 都能看到最新的代码更改。
-
注意事项:
- 性能影响:设置过短的过期时间(如几秒)会增加服务器的负载,因为浏览器需要频繁地从服务器重新加载页面。如果内容更新频率不高,建议设置更长的过期时间或使用更灵活的缓存策略(如 Cache-Control)。
- 兼容性:虽然
<meta http-equiv="expires">是一种常见的方法,但现代浏览器更推荐使用 HTTP 响应头(如Cache-Control和Expires)来控制缓存行为,因为它们更灵活且更符合标准。如果网页内容不经常更新,建议使用更合理的缓存策略(如设置合理的过期时间或使用Cache-Control头)。- 需要更精确地控制缓存,建议在服务器端设置 HTTP 响应头;
- 时间单位:
content的值 通常以秒为单位,表示从页面加载 开始计算的有效时间。
-
知识拓展:什么是 GMT 时间?
- GMT(Greenwich/ˈɡrenɪtʃ/ Mean Time,格林尼治标准时间)时间格式 是一种国际通用的时间表示方法,它基于 GMT 时区,即 协调世界时(UTC)。GMT 时间格式 通常以 24 小时制表示,包含星期,日 月 年 小时、分钟和秒,并且后面会跟上 时区信息。
星期, 日 月 年 小时:分:秒 GMT
- GMT(Greenwich/ˈɡrenɪtʃ/ Mean Time,格林尼治标准时间)时间格式 是一种国际通用的时间表示方法,它基于 GMT 时区,即 协调世界时(UTC)。GMT 时间格式 通常以 24 小时制表示,包含星期,日 月 年 小时、分钟和秒,并且后面会跟上 时区信息。
-
GMT 时间格式的一般形式是:
- 星期, 日 月 年 小时:分:秒 GMT
星期, DD 月 YYYY HH:MM:SS GMT
- 星期:星期几的缩写(如 Sun、Mon、Tue等)
- DD:月份中的一天,两位数字(01-31)
- 月:月份的缩写(如 Jan、Feb、Mar等)
- YYYY:四位数的年份
- HH:小时,24小时制(00-23)
- MM:分钟(00-59)
- SS:秒(00-59)
- GMT:时区标识
- 以下是一些 GMT 时间格式的例子:
2023年7月10日,下午3点15分,秒数为25,表示为:
Mon, 10 Jul 2023 15:15:25 GMT2024年1月1日,午夜12点整,表示为:
Wed, 01 Jan 2024 00:00:00 GMT2022年12月25日,上午9点30分,秒数为45,表示为:
Sun, 25 Dec 2022 09:30:45 GMT这种时间格式 广泛用于计算机和网络通信中,特别是在 HTTP 头信息、cookie 有效期、服务器日志记录 以及需要精确时间戳的场合。GMT 时间格式 确保了全球范围内的时间一致性,不受本地时区的影响。
- 北京时间 如何转换成 GMT 时间?
- 北京时间是中国的标准时间,位于 东八区,即 UTC+8。要将北京时间转换为 GMT(格林尼治标准时间,即UTC+0)时间,你需要从北京时间中 减去 8 个小时。
- GMT = 北京时间 - 8;
- 北京时间 = GMT+ 8;
- 对于在线转换或编程转换,你可以使用在线时间转换工具,或者在编程语言中使用相应的库 来自动处理时区转换。
- 北京时间是中国的标准时间,位于 东八区,即 UTC+8。要将北京时间转换为 GMT(格林尼治标准时间,即UTC+0)时间,你需要从北京时间中 减去 8 个小时。
- 以下是转换步骤:
确定北京时间:首先,你需要知道具体的北京时间。
减去8小时:从北京时间中减去 8 小时,得到对应的 GMT 时间。
例如:
如果北京时间是早上 8:00,那么 GMT 时间就是前一天的午夜 12:00(8:00 - 8小时 = 0:00,即 前一天的午夜 12:00)。
如果北京时间是晚上 20:00,那么 GMT 时间就是当天的中午 12:00(20:00 - 8小时 = 12:00)。
请注意,这种转换不考虑夏令时的影响。英国和一些其他国家/地区会实行夏令时,这时 GMT 会调整为 BST(British Summer
Time,英国夏令时),即 UTC+1。在夏令时期间,你可能需要 减去 7 个小时而不是 8 个。
- GMT 时间 和 UTC 时间的区别 是什么?
- GMT(Greenwich Mean Time,格林尼治标准时间)和 UTC(Coordinated/ko,ɔrd’netɪd/ Universal/ˌjuːnɪˈvɜːrs(ə)l/ Time,协调世界时)在大多数实际用途中是相同的,它们之间的差异 非常微小,以至于在日常应用中可以 视为等同。然而,从技术角度来看,它们之间存在一些细微的差别:
定义:
- GMT:最初是基于地球自转的时间测量,即天文时间。GMT是在英国伦敦郊区的皇家格林尼治天文台的标准时间。
- UTC:是一种基于原子时的时间标准,基于铯(sè)原子的振动周期 来定义,它不随地球自转速度的变化而变化,是一种非常稳定的时间测量方式。
稳定性:
- GMT:可能会因为地球自转速度的微小变化而进行调整。
- UTC:不受地球自转速度影响,通过在必要时添加闰秒来保持UTC与世界时(UT1,基于地球自转的时间)的接近。
闰秒:
- GMT:不包含闰秒。如果地球自转速度变慢,GMT 会与太阳时(基于太阳的位置)逐渐偏离。
- UTC:包含闰秒。为了保持 UTC 与 UT1 的接近,会在必要时刻在 UTC 中插入闰秒,通常是在 6 月 30 日或 12 月 31 日。
用途:
- GMT:主要用于天文和导航领域。
- UTC:被广泛用于科学、商业、通信和航空等领域,特别是在需要精确时间同步的场合。
在实际应用中,大多数情况下 GMT 和 UTC 可以互换使用,因为它们之间的差异非常小,通常只有 几毫秒。然而,在需要非常高精度的时间测量的科学实验或技术应用中,这种差异可能会变得重要。对于大多数日常用途,GMT 和 UTC 之间的差异可以忽略不计。
⑥ 不缓存、不从缓存中访问内容:http-equiv=“pragma”(不推荐使用;必须搭配 content=“no-cache”;推荐 服务器端 HTTP 响应头 设置)
meta标签的http-equiv属性设置为"Pragma"/ˈpræɡmə/,编译指令,杂注 时,通常用来 模拟 HTTP 响应头中的Pragma指令。Pragma头 主要用于:指定特定的请求 应该遵循的指令,其中最常用的指令是no-cache/kæʃ/,缓存,用来告诉浏览器 不要使用缓存中的数据,而是每次都要向服务器 请求最新的数据。- 推荐使用:
- ❶ 用
http-equiv="Cache-Control"替换; - ❷ 最佳:在服务器端 通过 HTTP 响应头 来设置这些缓存控制策略。
- ❶ 用
- 为什么不推荐使用
meta标签的http-equiv="pragma"属性值 ?
HTTP/1.0遗留属性:
Pragma是 HTTP/1.0 中定义的一个 header 属性,它相当于 HTTP/1.1中的Cache-Control。由于 HTTP/1.1已经成为主流,Pragma作为较旧的规范,其使用已经不被推荐。向后兼容性问题:
Pragma通常用于 向后兼容基于 HTTP/1.0 的客户端。但在现代 Web 开发中,大多数客户端都支持HTTP/1.1,因此使用Pragma的必要性大大降低。控制力度不足:
Pragma的指令相对有限,不如Cache-Control提供的指令 丰富和灵活。Cache-Control可以提供更多的控制选项,如max-age、no-cache等,使得开发者可以根据需要精细控制缓存行为。可能被忽略:有些浏览器或代理服务器 可能不会尊重
meta标签中的缓存控制指令,特别是当它们与 HTTP 响应头中的指令冲突时。因此,为了保证缓存控制策略的有效性,最好在服务器端 通过 HTTP 响应头 来设置这些缓存控制策略。HTML5 规范中不推荐使用:根据 HTML5 规范,一些过去使用的属性和元素 已经被废弃或者不推荐使用,推荐使用更现代、更有效的方法来替代它们。
综上所述,由于
Pragma属性值存在上述局限性,现代 Web 开发中推荐使用Cache-Control来管理HTTP缓存,而不是依赖于meta标签中的Pragma指令。
-
例: 在这个例子中,
Pragma指令设置为no-cache,意味着浏览器 将不会缓存该页面,每次用户访问时 都会从服务器重新下载页面。- 注意:禁止浏览器 从本地计算机的缓存中 访问页面内容。 这样设定,访问者将 无法 脱机/离线 浏览,访问者将一直获取最新的内容。
<meta http-equiv="Pragma" content="no-cache"> -
例:
Pragma指令还可以有其他值,但no-cache是最常用的一个。使用Pragma时,通常还会配合 属性值 缓存控制Cache-Control头使用,以提供 更详细的 缓存控制指令。例如: -
这个例子中,
Cache-Control头提供了更具体的指令:- ❶ 不能 直接读取本地缓存(访问就重新请求,验证新版本)
no-cache:告诉浏览器在展示请求的响应前,必须先向服务器确认 响应是否还有效。- 指示浏览器在展示缓存中的内容之前,必须先向服务器 验证是否有更新的版本。
- 这意味着浏览器 不能直接从本地缓存读取数据,而是必须每次都检查服务器 以确认缓存的文档 是否仍然有效。
- 浏览器每次访问页面时 都必须向服务器请求,以获取最新的页面数据。
- 指示浏览器在展示缓存中的内容之前,必须先向服务器 验证是否有更新的版本。
- ❷ 不允许缓存
no-store/stɔːr/:告诉浏览器 不允许存储请求的响应,即 不允许缓存页面。- 页面 不应该被浏览器或中间代理服务器存储。
- 这是一个更严格的指令,它告诉浏览器 不允许存储任何版本的请求或响应。这通常用于保护 非常敏感的数据,确保即使在客户端 也不会留下任何痕迹。
- ❸ 过期请求新的 不能用过期的
must-revalidate/riˈvælɪˌdet/,使重新生效:如果缓存的响应 已经过期,那么浏览器必须向服务器 请求新的响应,而不能使用 缓存中的旧响应。- 这个指令告诉 任何中间缓存(如 代理服务器)在缓存的响应过期后,必须向原始服务器 请求新的响应,而不能提供过期的缓存内容。
- 任何缓存的页面数据 在过期后 都必须被重新验证,不能使用 过期的缓存。
- ❶ 不能 直接读取本地缓存(访问就重新请求,验证新版本)
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate">
-
这样的设置 通常用于:确保用户总是 获取最新的内容,特别是在 内容更新频繁的情况下,例如 管理面板、实时数据展示页面等。
-
▲ 请注意:
Pragma头是 HTTP/1.0 的遗留产物,而Cache-Control是 HTTP/1.1 的头,后者提供了 更灵活和详细的 缓存控制选项。因此,在新的网页设计中,推荐使用Cache-Control而不是Pragma。
⑦ ★ 浏览器 缓存控制:http-equiv=“cache-control” (不推荐使用;必须搭配 content 属性;禁止缓存;允许谁缓存;缓存时间等;推荐 服务器端 HTTP 头 设置)
- 浏览器 缓存控制:
- 当需要 控制浏览器缓存行为时,比如 禁止缓存 或设置特定的缓存策略,可以使用
http-equiv="Cache-Control"。 - 用于模拟 HTTP 响应头中的
Cache-Control指令,以控制 浏览器对页面的 缓存行为。
- 当需要 控制浏览器缓存行为时,比如 禁止缓存 或设置特定的缓存策略,可以使用
- 为什么 IDE 提醒
http-equiv="Cache-Control"是错误属性值?- 可能是因为在 HTML5 中,
meta标签的http-equiv属性与Cache-Control相关的使用 已经不如 HTTP 响应头中的Cache-Control指令 那样直接和有效。 - 推荐 服务器端 HTTP 头 设置 缓存控制
- 在 HTTP 响应头中设置
Cache-Control可以更精确地控制缓存行为,而meta标签中的Cache-Control可能不会像预期的那样被所有浏览器或代理(比如 一些内置浏览器)尊重和处理。 - 因此,虽然
http-equiv="Cache-Control"并没有被废弃,但在现代 Web 开发中,更推荐的做法是 在服务器端通过 HTTP 响应头来设置缓存控制策略,而不是依赖于 HTML 中的meta标签。这样做可以提供更可靠的缓存控制,并确保跨不同浏览器和代理服务器的一致性。
- 在 HTTP 响应头中设置
- 可能是因为在 HTML5 中,
- 为什么不推荐使用
meta标签的http-equiv="Cache-Control"属性值 ?
优先级问题:
Cache-Control指令在 HTTP 响应头中具有 更高的优先级。当在 HTTP 响应头和meta标签中同时设置了Cache-Control指令时,浏览器将优先采用 HTTP 响应头中的值。浏览器兼容性和一致性问题:不是所有的浏览器或代理服务器 都会尊重
meta标签中的缓存控制指令,尤其是一些现代浏览器和代理可能会忽略meta标签中的缓存控制,导致缓存控制策略无法按预期工作。HTTP/1.1的替代方案:在 HTTP/1.1 中,
Cache-Control提供了 更精确细致的缓存功能,是Expires和其他meta标签缓存控制的替代品。Cache-Control可以提供更多的指令,如max-age、no-cache等,使得缓存控制更加灵活和强大。控制力度不足:
meta标签中的Cache-Control指令相对有限,不如 HTTP 响应头中的Cache-Control提供的控制选项丰富,这限制了开发者对缓存行为的精细控制。实现的复杂性:使用
meta标签设置缓存控制 需要正确理解http-equiv和content属性的配合使用,这增加了实现的复杂性,并且容易出错。最佳实践:最佳实践是使用服务器配置(如 Nginx 或 Apache)来设置 HTTP 响应头中的
Cache-Control,这样可以更一致和可靠地控制缓存行为,而不是依赖于meta标签。因此,为了保证缓存控制策略的有效性和一致性,推荐使用 HTTP 响应头中的
Cache-Control指令,而不是meta标签的http-equiv="Cache-Control"属性值。
-
以下是如何使用这个
http-equiv="Cache-Control"属性值的一些例子,都必须搭配content属性: -
例: 禁止缓存、访问时 获取最新版本
- 如果你想要 确保用户每次访问页面时 都从服务器获取最新版本,可以使用以下设置:
-
❶
no-cache指令:不直接读取缓存,每次都验证更新; 让浏览器 每次都向服务器 验证是否更新,不直接读取缓存;- 浏览器不要直接从缓存中读取页面内容,而是需要重新验证页面是否更新。如果页面没有更新,浏览器可以使用缓存的内容;如果页面更新了,则会重新加载。
- 行为特点:
- 强制验证:每次请求时,浏览器都会向服务器发起验证请求,而不是直接使用缓存。
- 允许缓存:资源仍然可以被缓存,但必须经过验证才能使用。
- 适用场景:适用于那些内容可能会更新,但又不想完全禁缓存的资源。例如,动态页面或用户特定的数据。
-
❷
no-store指令:不缓存;告诉浏览器 不要将页面内容存储在任何缓存中,包括本地缓存和代理缓存。这意味着每次访问页面时,浏览器都会从服务器重新加载内容。 -
❸
must-revalidate指令:如果缓存过期,必须向服务器发起验证请求,从服务器获取新的内容。- 如果缓存中的资源过期(即超出了
max-age或Expires指定的时间),浏览器必须 重新验证资源的有效性。如果缓存中的资源未过期,则可以直接使用缓存,而无需验证。 - 行为特点:
- 仅在过期时验证:只有当缓存中的资源过期时,才需要向服务器发起验证请求。如果资源未过期,则可以直接使用缓存。
- 强制重新验证:一旦资源过期,必须重新验证,不能使用过期的缓存。
- 适用场景:适用于那些对时效性要求较高的资源,但又希望在资源未过期时利用缓存来提高性能。
- 如果缓存中的资源过期(即超出了
-
这段代码的作用:是禁止浏览器缓存页面内容,确保用户每次访问页面时 都能获取最新的内容。这通常用于 需要频繁更新的页面,例如 登录页面、动态数据页面等,以避免用户看到过时的信息。
-
<meta http-equiv="Cache-Control" content="no-cache, no-store, must-revalidate"> - 如果你想要 确保用户每次访问页面时 都从服务器获取最新版本,可以使用以下设置:
-
例: 允许页面被缓存,但设置过期时间/ 缓存时间(以秒为单位),到期重新获取
- 如果你希望页面被缓存,但过了一定时间后过期,可以使用
max-age指令:
<meta http-equiv="Cache-Control" content="max-age=3600">- max-age=3600:缓存有效时间;这个指令指定了响应 在被认为过期之前 可以在缓存中存储多长时间。在这个例子中,
max-age设置为 3600 秒,即1小时。这意味着浏览器或任何中间缓存 在1小时内 可以提供缓存的页面,而不需要再次向服务器请求。并且在 3600 秒(即1小时)后过期,需要重新获取内容。 - 综上:
- 页面可以 被浏览器或中间缓存系统(如 代理服务器)缓存。
- 页面在被缓存后的 1 小时内被认为是新鲜的,用户在这段时间内的重复访问 可以直接使用缓存的页面,无需再次从服务器加载。
- 这种设置适用于:那些不经常变化的 静态内容,允许页面被缓存 以减少服务器负载、提高页面加载速度。通过设置合理的
max-age值,可以平衡页面的新鲜度 和缓存的效率。
- 如果你希望页面被缓存,但过了一定时间后过期,可以使用
-
例: 仅允许页面 被公共缓存系统(共享缓存) 缓存,如 CDN 缓存
- 如果你希望页面 仅被公共 CDN 缓存,而不是 私有缓存(比如 用户的浏览器缓存),可以使用
public指令:
<meta http-equiv="Cache-Control" content="public, max-age=3600">-
public:这个指令表示响应 可以被任何 中间缓存(如 代理服务器)缓存,即使 通常只有非公共内容才会被缓存。通常,这个指令用于确保 响应可以被 CDN 等 公共缓存系统缓存。
-
max-age=3600:这个指令指定了 响应在被认为过期之前 可以被缓存多长时间。在这个例子中,
max-age设置为 3600 秒,即 1 小时。这意味着 任何中间缓存 在 1 小时内可以提供缓存的页面,而不需要再次向服务器请求。 -
综上:
- 页面可以被 任何中间缓存系统(如 CDN)缓存。
- 页面在被缓存后的 1 小时内 被认为是新鲜的,不需要再次从服务器获取。
-
这样的设置 通常用于那些 不经常变化的静态内容,允许页面被缓存 以减少服务器负载、提高页面加载速度。
- 如果你希望页面 仅被公共 CDN 缓存,而不是 私有缓存(比如 用户的浏览器缓存),可以使用
- 例: 不允许缓存,禁止页面 被任何缓存存储
- 如果你不希望页面 被任何缓存存储,可以使用
no-store指令:
<meta http-equiv="Cache-Control" content="no-store">- no-store:这个指令表示响应(即 服务器返回的数据)不应被存储在 任何类型的缓存中,无论是 私有缓存(如 用户的浏览器缓存)还是 共享缓存(如 代理服务器的缓存)。
- 这意味着 每次用户访问页面时,浏览器都必须向服务器 请求最新的数据,而不是 从本地缓存中加载。
- 综上
- 页面 不应被浏览器或任何中间缓存系统 存储。
- 每次用户访问页面时,页面都必须 从服务器重新获取,而不是从缓存中加载。
- 这种设置 通常用于:那些 包含敏感信息 或需要频繁更新的页面,确保用户总是 获取最新版本的页面,避免因缓存导致的 数据过时问题。
- 如果你不希望页面 被任何缓存存储,可以使用
- 例: 只能被 用户的浏览器缓存,不能被共享缓存,设置 过期时间/ 缓存时间(使用缓存页面的时间);
<meta http-equiv="Cache-Control" content="private, max-age=3600">- private:这个指令表示响应是 为单个用户准备的,只能被 用户的浏览器缓存,不能被共享缓存(如 代理服务器)存储。这通常用于 那些包含用户特定数据的页面,比如 用户的个人资料页面。
- max-age=3600:这个指令指定了响应 在被认为过期之前 可以在缓存中存储多长时间。
- 在这个例子中,
max-age设置为 3600 秒,即 1 小时。这意味着用户的浏览器 可以在 1 小时内 使用缓存的页面,而不需要再次向服务器请求。
- 在这个例子中,
- 综上:
- 页面 应该被用户的浏览器缓存,但不应该 被任何中间缓存(如 代理服务器或 CDN)缓存。
- 页面在被缓存后的 1 小时内被认为是新鲜的,用户在这段时间内的重复访问 可以直接使用缓存的页面,无需再次从服务器加载。
- 这种设置适用于那些 包含敏感或个性化信息的页面,需要确保不被共享缓存存储,同时又希望利用浏览器缓存 来提高加载效率。
- 例: 防止缓存(如 代理服务器)对响应内容 进行任何形式的 转换或压缩
<meta http-equiv="Cache-Control" content="no-transform">-
no-transform:这个指令用于 防止缓存(如 代理服务器)对响应内容 进行任何形式的转换或压缩。 -
这通常用于:确保返回的内容是 原始的、未经修改的版本,特别是对于那些 可能依赖于特定格式或编码的数据。
- 例如,某些代理服务器 可能会尝试优化传输的内容,比如 压缩图片或更改字符集编码,使用
no-transform指令 可以阻止这种行为,确保内容 以原始形式被缓存和传输。
- 例如,某些代理服务器 可能会尝试优化传输的内容,比如 压缩图片或更改字符集编码,使用
-
这种设置 通常用于以下情况:
-
保护内容完整性:确保传输的内容 不会被任何中间代理更改,这对于需要精确控制输出的应用(如 API 响应)非常重要。
-
避免不必要的转换:防止代理服务器 对内容进行不必要的处理,这可能会导致额外的延迟 或不正确的显示。
-
兼容性问题:解决由于内容转换 导致的兼容性问题,特别是在不同设备或浏览器上。
- 使用
no-transform指令有助于确保内容的一致性和可靠性,特别是在跨多个网络和服务器传输时。
- 使用
-
-
请注意,
meta标签中的Cache-Control指令 可能不会在所有浏览器中 被完全支持,尤其是no-store和must-revalidate这样的指令。因此,对于 需要精确控制缓存行为的场合,最好在服务器端 设置相应的 HTTP 响应头。
-
- 建议参考文章:Cache-Control - HTTP | MDN
- 看不懂英文的 可以点击右上角语言选项 切换到中文,降低学习难度。但需要小心,因为中文版的 可能会有一些错误翻译,会给人造成困惑,建议结合实例来看,感觉不对劲、难以理解时, 就切换回英文 自己尝试翻译下(可以借助翻译软件);
- 缓存控制:
cache-control指定 请求和响应 遵循的缓存机制。- 在 请求消息 或响应消息中 设置
cache-control,并不会修改 另一个消息处理过程中的 缓存处理过程。 - 请求时的 缓存指令: 包括
no-cache、no-store、max-age、max-stale、min-fresh、only-if-cached; - 响应消息中的 指令: 包括
public、private、no-cache、no-store、no-transform、must-revalidate、proxy-revalidate、max-age。 - 指令含义, 如下
-
❶ 公开内容 都能缓存 :
public- 含义:指示响应可以被任何缓存存储,包括 浏览器缓存和共享缓存(如 CDN 或代理服务器)。这意味着响应内容 可以被多个用户共享。
public是一个缓存指令,表示响应内容是 公开的,可以被任何缓存存储,无论它是私有的(如浏览器缓存)还是共享的(如 代理服务器或 CDN 缓存)。- 使用场景:适用于对所有用户都相同的静态资源,如 公共图片、CSS 文件或 JavaScript 文件。可以提高缓存效率,减少服务器负载。
-
❷ 私有缓存 :
private- 含义:指示响应只能被 单个用户的私有缓存(如浏览器缓存)存储,不能被共享缓存(如 CDN 或代理服务器)存储。
- 使用场景:适用于用户特定的内容或包含敏感信息的资源,如用户的个人信息页面。防止共享缓存 将用户数据泄露给其他用户。
-
❸ 不直接读取缓存,先验证更新:
no-cache-
含义:允许缓存,但每次使用缓存前 必须与服务器验证资源的有效性。如果资源未变更,服务器返回
304 Not Modified,否则返回新的资源。 -
使用场景:动态内容 或可能频繁更新的资源,例如 新闻页面 或用户动态数据。
no-cache指令:不直接读取缓存,每次都验证更新; 让浏览器 每次都向服务器 验证是否更新,不直接读取缓存;
-
浏览器不要直接从缓存中读取页面内容,而是需要重新验证页面是否更新。如果页面没有更新,浏览器可以使用缓存的内容;如果页面更新了,则会重新加载。
-
行为特点:
- 强制验证:每次请求时,浏览器都会向服务器发起验证请求,而不是直接使用缓存。
- 允许缓存:资源仍然可以被缓存,但必须经过验证才能使用。
- 适用场景:适用于那些内容可能会更新,但又不想完全禁缓存的资源。例如,动态页面或用户特定的数据。
-
-
❹ 不允许缓存:
no-store- 含义:禁止任何缓存行为,请求和响应都不会被存储。适用于敏感信息或用户隐私数据,确保每次请求都直接从服务器获取最新内容。
- 使用场景:登录页面、用户个人数据等需要严格保密的资源。
-
❺ 缓存过期 必须重新验证:
must-revalidate- 含义:缓存过期后,必须重新验证资源的有效性,不能直接使用过期缓存。
- 使用场景:对时效性要求较高的资源,但希望在缓存未过期时直接使用缓存。
-
❻ 最大缓存有效期:
max-age=<seconds>- 含义:设置缓存的最大有效时间(单位为秒),超过该时间后缓存失效。
- 使用场景:静态资源,如图片、CSS、JavaScript 文件等,可以设置较长的缓存时间以提高性能。
-
❼ 共享缓存 最大有效期:
s-maxage=<seconds>- 含义:与
max-age类似,但仅适用于共享缓存(如代理服务器),私有缓存会忽略该指令。 - 使用场景:大型网站或 CDN 环境中,控制代理服务器的缓存时间。
- 含义:与
-
❽最小新鲜期/有效期:
min-fresh=<seconds>- 含义:客户端希望获取的响应 在未来的指定秒数内 仍然是新鲜的(即未过期的)。如果缓存中的资源 无法满足这个条件,客户端会直接请求服务器以获取最新的响应。
- 使用场景:适用于客户端需要确保资源在未来一段时间内 仍然有效的情况,例如用户希望获取至少在未来几分钟内 不会过期的内容。
min-fresh=60是一种客户端缓存控制指令,确保客户端获取的资源 在未来 60 秒内仍然是新鲜的;- 这种设置适用于:那些需要保持一定新鲜度,但又不需要实时更新的页面,例如 新闻文章或博客帖子。通过设置
min-fresh值,可以确保用户在一定时间内访问页面时 获得的内容是相对较新的。
-
❾ 最大过期时间:
max-stale[=<seconds>]- 含义:客户端愿意接受已经过期的响应,可选的秒数 表示客户端愿意接受的过期时间上限。如果未指定秒数,则表示客户端愿意接受任何过期的响应。
- 使用场景:适用于网络状况不佳或对内容新鲜度要求不高的情况,例如 在离线模式下或用户希望尽快获取内容时。
max-stale=60:这个指令指定了浏览器可以接收一个已经过期 但不超过 60 秒的响应。max-stale指令 用于告诉浏览器在没有新鲜内容可用时,可以接受的最大过期时间。- 这种设置适用于:那些对实时性要求 不是极高的页面,允许用户在一定程度上 接受稍微过时的内容,以减少服务器请求和提高页面加载速度。通过设置
max-stale值,可以在没有新鲜内容可用时,提供一个 合理的回退选项。
-
❿ 共享缓存过期 先验证:
proxy-revalidate- 这个指令要求 任何共享缓存(如 代理服务器或 CDN)在提供缓存内容之前 必须先向原始服务器验证缓存内容的有效性。
- 与
must-revalidate类似,但仅适用于 共享缓存(如 代理服务器),私有缓存 会忽略该指令。它要求代理服务器在缓存的响应过期后,必须重新验证资源的有效性。 - 如果原始服务器指示 缓存内容已过期或已更新,则缓存必须 从原始服务器获取最新内容。
- 简而言之,
proxy-revalidate指令确保了 中间缓存 不会提供过时的内容。每次中间缓存 提供响应之前,都需要重新验证缓存的有效性,从而保证了用户 总是能够获取到最新的内容。
- 简而言之,
- 这种设置通常用于:那些更新频繁的动态内容,以确保即使在缓存中的内容 也能够得到及时的更新。这有助于 防止用户看到陈旧的信息,尤其是在内容的实时性非常重要的场景下。
-
❶ 禁止转换或修改:
no-transform- 含义:禁止代理服务器对响应内容进行转换或修改。
- 使用场景:防止代理服务器对资源进行压缩或格式转换,确保内容的完整性。
-
❷ 不更改内容、无需验证:
immutable- 含义:表示响应内容不会更改,客户端无需重新验证缓存。
- 使用场景:静态资源(如图片、CSS/JS 文件)且内容不会更改。
-
❸ 只接受已缓存:
only-if-cached- 含义:客户端只接受已缓存的响应,不会向服务器请求新内容。客户端仅接受来自缓存的响应,如果缓存中没有匹配的资源,则服务器应返回
504 Gateway Timeout。- 浏览器将尝试从缓存中加载请求的文档。如果文档不在缓存中,或者缓存的文档已经过期,那么浏览器将不会显示该页面,可能显示错误消息或者无内容的页面。
- 使用场景:适用于客户端希望减少网络请求,仅依赖本地缓存的情况,例如在离线模式或网络连接受限时。也可以用于节省带宽,因为如果页面已经被缓存,就不需要再次从网络下载。
- 然而,需要注意的是
only-if-cached并不是一个标准的Cache-Control指令,而且在所有浏览器中 都不一定被支持。- 在实际应用中,这个指令可能会导致 用户体验问题,因为如果页面不在缓存中,用户可能 无法看到任何内容。因此,使用这个指令时需要谨慎,并确保它符合你的网站或应用的特定需求。
- 含义:客户端只接受已缓存的响应,不会向服务器请求新内容。客户端仅接受来自缓存的响应,如果缓存中没有匹配的资源,则服务器应返回
-
❹ 验证时或出错时 使用过期缓存:
stale-while-revalidate和stale-if-error- stale /steɪl/,过期失效的、不新鲜的
- 含义:实验性指令,允许在后台验证新内容的同时,使用过期缓存。
- 使用场景:提高用户体验,减少等待时间,适用于对实时性要求不高的资源。
-
- 在 请求消息 或响应消息中 设置
- 总结
- 禁止缓存:使用
no-store。 - 强制验证:使用
no-cache或max-age=0, must-revalidate。 - 允许缓存:使用
public或private,并结合max-age或s-maxage设置缓存时间。 - 静态资源:使用
immutable和较长的max-age。 - 优化性能:使用
stale-while-revalidate或stale-if-error。
- 禁止缓存:使用
⑧ 网页 窗口打开位置:http-equiv=“window-target”(不推荐使用;必须搭配 content 属性)
http-equiv="window-target"属性值- 用于:设置 网页在浏览器中的 打开方式;
<meta http-equiv="window-target" content="_top">
-
http-equiv="window-target":- 模拟了一个 HTTP 响应头,用于告诉浏览器 如何处理页面中的 链接打开行为。
-
content="_top":- 指定了页面中的链接 应该 在哪个窗口或框架中打开。
_top值表示:链接将在 顶级窗口或框架中 打开,即 整个浏览器窗口,忽略任何可能的父框架或打开者框架。- 确保页面中的所有链接 都会在 当前 整个浏览器窗口 中打开,而不是 在框架或弹出窗口中打开。
- ❶ 强制页面 在当前窗口 以独立页面显示。
- ❷ 用来防止 别人在框架里 调用自己的页面。
-
这种设置通常用于:防止页面 被其他网站框架化(即 防止点击链接时 在另一个网站的框架内打开),增强了页面的控制权和安全性。
- 在早期的 Web 开发中,这种设置较为常见,但在现代 Web 开发中,由于安全策略和浏览器行为的变化,这种设置的使用已经减少。现代 Web 开发更多依赖于其他安全和控制手段,如 HTTP 安全头部和现代 JavaScript 框架。
- 为什么 不推荐使用
meta标签的http-equiv="window-target"属性值 ?
功能过时:
window-target属性主要用于控制页面在浏览器窗口中的打开方式,例如防止页面被其他网站的框架(frame)嵌入。然而,现代 Web 开发中,这种控制更多地通过其他方式实现,比如 使用X-Frame-OptionsHTTP响应头或者HTML的sandbox属性等更现代、更安全的方法来控制。安全性问题:
window-target属性的content值设置为_top时,可以强制页面在顶层窗口打开,这在某些情况下 可以防止点击劫持攻击。但是,这种方法 不如现代的安全措施有效,如使用Content Security Policy(CSP)头部来提供更细粒度的控制。浏览器支持和一致性问题:不是所有的浏览器 都会尊重
meta标签中的http-equiv属性值,特别是一些现代浏览器和代理 可能会忽略window-target的设置,导致 预期的窗口控制行为 无法实现。最佳实践:现代 Web 开发推荐使用 HTTP 头部字段 来控制页面行为,因为这些头部字段 具有更高的优先级,并且被所有浏览器一致支持。例如,使用
Content Security Policy头部 来替代window-target属性,以实现更安全、更有效的页面控制。综上所述,由于
window-target属性的功能过时、安全性问题 以及浏览器支持和一致性问题,不推荐使用meta标签的http-equiv="window-target"属性值。相反,应该采用更现代、更安全的方法 来控制页面的打开方式和安全性。
-
替代方法
- 要替代
meta标签的http-equiv="window-target" content="_top"以实现相同的效果,即防止页面 被其他网站框架化 或嵌入到其他页面中,可以通过以下几种方式:
- 要替代
-
❶ 使用服务器端配置:
-
在服务器端配置中 设置 HTTP 头部,例如 使用
X-Frame-Options头部 来控制页面 是否可以被框架化。 -
X-Frame-Options: DENY:完全禁止 页面被框架化。 -
X-Frame-Options: SAMEORIGIN:只允许 同源页面框架化。 -
这种方法需要服务器端的支持,并且是最为推荐的安全性做法。
-
-
❷ 使用 CSP (内容安全策略):
- 通过设置内容安全策略(CSP)来限制页面的加载和执行,从而防止被框架化。
- 这将阻止 任何页面框架化当前页面。
<meta http-equiv="Content-Security-Policy" content="frame-ancestors 'none'"> -
❸ 使用 HTML5 的
<base>标签:- 在 HTML5 中,可以使用
<base>标签的target属性来指定所有链接的打开方式。 - 这将使得 页面中所有的链接 都在新窗口 或新标签页中打开。
<base target="_blank"> - 在 HTML5 中,可以使用
-
❹ 使用 JavaScript:
- 可以通过 JavaScript 来控制窗口的打开行为
- 例如,可以监听所有链接的点击事件,并设置
target="_blank"属性,这样链接就会在新窗口或新标签页中打开,而不是在当前窗口的框架中打开。- 这种方法可以确保所有的链接 都不会在当前窗口打开,从而避免被框架化。
document.addEventListener('click', function(e) { if (e.target.tagName === 'A') { e.target.target = '_blank'; } }); -
❺ 使用 CSS:
- 对于某些特定情况,可以使用CSS的
:not伪类结合:target伪类 来隐藏被框架化的内容,但这通常不是推荐的做法,因为它依赖于 CSS 特性,并且可能在不同的浏览器中表现不一致。
html:not(:target) { display: none; }- 这种方法的效果有限,并且可能需要额外的 JavaScript 来处理复杂的逻辑。
- 对于某些特定情况,可以使用CSS的
⑨ 其他 http-equiv 属性值:content-type、set-cookie 等(不推荐使用;仅做了解,大部分已被废弃)
-
其他 http-equiv 属性值,仅做了解,部分已被废弃
- 被废弃或不推荐使用的属性值 ide 中会有提示,如 webstorm;会显示 “错误的属性值” 或 “已废弃的属性值”
-
❶ 内容类型 + 字符集声明:
http-equiv="Content-Type"(仍可使用,但建议用charset属性 替代)-
用于:声明 MIME 类型和文档的字符编码。
- 如果使用
content-type属性,与之在同一个<meta>元素中使用的content属性的值必须是"text/html; charset=utf-8"。 - 这相当于一个具有指定
charset属性的<meta>元素,并对其在文档中的放置位置有相同的限制。- 注意:该属性只能用于 MIME 类型为
text/html的文档,不能用于 MIME 类型为XML的文档。
- 注意:该属性只能用于 MIME 类型为
- 如果使用
-
字符集声明:
- 当需要指定 页面内容类型,页面使用的字符编码时,可以使用
http-equiv="Content-Type"来确保页面 正确渲染字符。
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> - 当需要指定 页面内容类型,页面使用的字符编码时,可以使用
-
属性搭配:
content属性- 它遵循与
HTTP content-type头部字段 相同的语法, 但由于它位于 HTML 页面内,因此除了text/html之外的 大多数值都不能使用。 因此,其content的有效语法是字符串'text/html' - 废弃原因: 只有 HTML 文档 可以使用
content-type,所以根本不需要特意说明,显得多余了,这就是为什么 它被废弃 并被charset属性 替换的原因,因为更简洁。
- 它遵循与
-
替代属性:
charset- 一般写成:
<meta charset="utf-8">; - 语法:
charset=IANAcharset;- 其中
IANAcharset是 IANA 定义的 字符集的 首选 MIME 名称。
- 其中
- 一般写成:
-
总结: 不要使用
content-type属性值, 因为它已过时。使用<meta>元素的charset属性 代替,定义 meta-charset字符编码 就可以了,不用定义http-quiv="content-type",多此一举。
-
-
为什么 不推荐使用
meta标签的http-equiv="content-type"属性值 ?
① 主要是因为在 HTML5 中,已经有了更简洁和明确的方式 来指定文档的字符编码,
即 直接使用:<meta charset="UTF-8">。
这种方式 更符合 HTML5 的标准,且具有 更好的兼容性和语义清晰度。② 此外,
http-equiv="content-type"属性值 用于:声明文档的 MIME 类型和字符编码,但在现代 Web 开发中,通常只有当 MIME 类型不是text/html或者当文档是 XHTML 格式时,才需要显式地指定content-type。
③ 对于绝大多数 HTML 文档而言,使用<meta charset="UTF-8">就足够了,因为它告诉浏览器 文档使用的是UTF-8编码,这是目前 最常用的字符编码,能够覆盖绝大多数字符,且被所有现代浏览器支持。
因此,为了代码的简洁性、清晰性以及与 HTML5 标准的一致性,
推荐使用<meta charset="UTF-8">来代替http-equiv="content-type"属性值。
这样做可以确保文档的字符编码 被正确识别,同时也使得 HTML 文档更加符合现代 Web 标准。
-
❷ 文档的 脚本类型(不推荐使用):content-script-type
<meta http-equiv="content-script-type" content="text/JavaScript">- W3C 网页规范,指明页面中 脚本的类型。
-
为什么 不推荐使用
meta标签的http-equiv="content-script-type"属性值 ?
W3C 标准的变化:
content-script-type属性值用于:指定页面中 脚本的类型,这在早期的 HTML 规范中是有意义的。然而,随着 HTML5 的推出,W3C 对于网页规范进行了更新,不再推荐使用http-equiv="content-script-type"。
在 HTML5 中,默认的脚本类型 是text/javascript,而且这个默认值 已经被广泛接受和使用,因此没有必要显式声明。简化代码:在现代 Web 开发中,推崇的是简洁和高效的代码实践。由于
text/javascript是默认的脚本类型,大多数情况下,开发者 不需要额外指定 脚本类型,这样可以减少 HTML 文档中的冗余标记,使代码更加简洁。浏览器的默认行为:所有现代浏览器都默认将
<script>标签的类型识别为text/javascript,这意味着即使不指定content-script-type,浏览器也能 正确解析和执行 JavaScript 代码。避免兼容性问题:在某些情况下,过度依赖
meta标签的http-equiv属性可能会导致跨浏览器兼容性问题。由于content-script-type不再被推荐使用,某些浏览器可能不再支持或者在未来的版本中移除对这一属性值的支持,这可能会导致依赖这一属性的网页在这些浏览器中出现问题。综上所述,由于 W3C 标准的变化、代码简化的需求、浏览器的默认行为 以及避免兼容性问题的考虑,不推荐使用
meta标签的
http-equiv="content-script-type"属性值。
-
❸ 设置 缓存(不推荐使用):set-cookie/ˈkʊki/,缓存文件 (已废弃,用 HTTP 的 Set-Cookie 头部)
- 为页面 定义 cookie。其内容必须遵循 IETF HTTP Cookie 规范 中定义的语法。
- 这个 pragma 是不符合规范的,没有效果。用户代理需要忽略这个 pragma。
- 如果 网页过期,那么存盘的 cookie 将被删除。
- 用法:
<metahttp-equiv="Set-Cookie" content="cookievalue=xxx;expires=Friday,12-Jan-200118:18:18GMT;path=/"> - 注意:必须使用 GMT 的时间格式。
- 用法:
- Note: 警告:请勿使用 此说明,因为它已过时。请改用 HTTP 的
Set-Cookie头部。
- 为页面 定义 cookie。其内容必须遵循 IETF HTTP Cookie 规范 中定义的语法。
-
不推荐使用
meta标签的http-equiv="set-cookie"属性值 ?
安全性问题:
set-cookie属性用于设置客户端的 Cookie,这是一个敏感操作,因为它涉及到 用户数据的存储。在meta标签中设置 Cookie 可能会增加安全风险,比如 跨站脚本攻击(XSS)。HTTP 响应头的替代:在服务器端通过 HTTP 响应头设置 Cookie 是更标准和推荐的做法。这种方法可以更精确地控制 Cookie 的属性,如 有效期、路径、域和安全标志等。
浏览器兼容性和一致性问题:不是所有的浏览器都会尊重
meta标签中的http-equiv属性值,特别是一些现代浏览器和代理可能会忽略set-cookie的设置,导致预期的 Cookie 设置行为无法实现。控制力度不足:使用 HTTP 响应头设置 Cookie 可以提供更多的控制选项,例如设置 HttpOnly 属性以防止客户端脚本访问 Cookie,增加安全性。
最佳实践:现代 Web 开发推荐使用 HTTP 头部字段来控制页面行为,因为这些头部字段具有更高的优先级,并且被所有浏览器一致支持。
综上所述,由于安全性问题、HTTP 响应头的替代方案、浏览器兼容性和一致性问题、控制力度不足 以及最佳实践的考虑,不推荐使用
meta标签的http-equiv="set-cookie"属性值。相反,应该采用更现代、更安全的方法来设置 Cookie。
-
❹ 文档 默认语言:
http-equiv="content-language"(已废弃,html 标签的 lang 属性 替代)- 这个指令 定义 页面使用的默认语言。
- 使用方式: 不要使用 这个指令,因为它已经过时了。
- 替代标签: 使用
<html>元素上 全局的 语言lang属性 来替代它。- 例:
<html lang="zh-CN">- 用于:指定 页面内容的主要语言为 简体中文。
- 例:
-
为什么不推荐使用
meta标签的http-equiv="content-language"属性值 ?
HTTP 头部字段的替代:
content-language属性值 用于指定文档的语言,这可以通过 HTTP 头部字段Content-Language实现。然而,在HTML文档中,使用meta标签的http-equiv属性来模拟 HTTP 头部字段并不是最佳实践,因为它可能不会像 HTTP 响应头那样 被所有浏览器或代理(如 微信内置浏览器)尊重。HTML5 中的替代方案:在HTML5中,推荐使用
lang属性来指定文档的语言,而不是使用meta标签的http-equiv属性。
例如,<html lang="en">用于指定页面内容的主要语言为英语。这种方法更直接、更清晰,并且符合 HTML5 的标准。浏览器支持和一致性问题:不是所有的浏览器都会尊重
meta标签中的http-equiv属性值,特别是当它们与 HTTP 响应头中的指令冲突时。因此,为了保证语言设置的有效性和一致性,最好在服务器端 通过 HTTP 响应头 来设置这些元数据。SEO 和国际化的最佳实践:对于搜索引擎优化(SEO)和国际化,使用
lang属性可以提供更准确的语言信息,帮助搜索引擎更好地理解和索引页面内容。同时,这也是国际化和本地化的最佳实践之一。综上所述,由于上述原因,不推荐使用
meta标签的http-equiv="content-language"属性值,而应使用 HTML5 的lang属性来指定文档的语言。
-
❺ 图片工具栏的 显示(不推荐使用):imagetoolbar
http-equiv="imagetoolbar "<meta http-equiv="imagetoolbar" content="false"/>- 指定 是否显示 图片工具栏,当为
false代表 不显示,当为true代表显示。
-
为什么 不推荐使用
meta标签的http-equiv="imagetoolbar"属性值 ?
主要是因为:这个属性值的使用场景 已经变得非常有限,并且有更好的替代方案。
功能限制:
http-equiv="imagetoolbar"属性值 用于:指定是否 在图片上显示工具栏,这在现代浏览器中 已经不再是一个常见的需求。随着 Web 技术的发展,用户交互和页面设计 已经变得更加复杂和多样化,简单的图片工具栏功能 已经不足以满足现代 Web 应用的需求。浏览器支持问题:不是所有的现代浏览器都支持这个属性值,或者即使支持,也可能不会按照预期工作。这意味着依赖这个属性值可能会导致跨浏览器兼容性问题。
用户体验:现代 Web 设计更加注重用户体验,而自动显示的图片工具栏 可能会干扰用户的操作,影响用户体验。
替代方案:对于需要提供图片编辑或操作功能的场景,开发者可以通过 JavaScript 和 CSS 来实现更加丰富和灵活的用户界面,而不是依赖于 HTML
meta标签的http-equiv="imagetoolbar"属性值。HTML5 和现代 Web 标准:随着 HTML5 和现代 Web 标准的推广,更加推荐使用 HTML5 的新特性和 API 来实现功能,而不是依赖于旧的、可能已经被废弃的属性值。
因此,考虑到上述因素,不推荐使用
meta标签的http-equiv="imagetoolbar"属性值,而是应该寻找 更现代、更有效的解决方案来满足需求。
3.3 name 属性:元数据的 名称 (必须搭配 content 属性)
<meta>标签的name属性- 用于:提供 文档级别的元数据;
- 元数据形式:这些元数据 以名称/值 对 的形式出现;
- 名称属性
name= 元数据的名称; - 内容属性
content= 元数据的值; - 冲突属性:不能 和
itemprop属性 同时使用- 在同一个
<meta>标签中,name、http-equiv、charset三者中 任何一个属性 存在时,itemprop属性 不能被使用。一般这几个属性 都用单独的<meta>设置;charset属性单独放一个<meta>标签,其他三个属性也单独放一个标签,这样,当需要设置 相匹配的值时,各自搭配自己的content属性;
- 在同一个
- 名称属性
- 如何设置 meta-
name属性值 ?<meta>标签的name属性 没有固定的属性值,它的值 取决于你想要提供 哪种类型的元数据信息;name属性的值:应该是 一个 有效的元数据名称,它定义了content属性中提供的 信息的类型。- 标准元数据名称 - HTML(超文本标记语言) | MDN
- ❶ 第一种:HTML5 规范中 定义的 标准元数据名称:标准 元数据名称 - HTML Standard(规范文档)
- ❷ 第二种:HTML5 规范之外 惯用的元数据名称:MetaExtensions - WHATWG Wiki
- 很多 HTML5 规范之外定义的常用 元数据名称 在 MetaExtensions - WHATWG Wiki 基本上 都能查到;
- 创建和使用 新的元数据名称
- 在创建和使用新的元数据名称之前:建议咨询 WHATWG Wiki MetaExtensions 页面—— 避免选择 已经在使用的元数据名称,避免重复 已经在使用的元数据名称的用途,并避免新的标准化名称 与您选择的名称冲突。(WHATWGWIKI)
- 任何人都可以 随时编辑 WHATWG Wiki MetaExtensions 页面 来添加元数据名称。但不一定都会被通过审核。
- HTML5 规范 中 定义了哪些 标准元数据名称 ?
- 8个:应用名、作者名、软件名;关键词、描述、来源地址策略;主题颜色、颜色方案;
根据 HTML 规范,以下是一些 定义的标准元数据名称:
1. application-name:应用名;指定当前页面 所代表的 Web 应用程序的名称。
author/ˈɔːθər/:作者名;文档作者的名字。
页面的作者。
html <meta name="author" content="作者名">generator/ˈdʒenəreɪtər/:生成代码的软件名;生成页面的软件的标识符。
生成页面的 软件或工具。
html <meta name="generator" content="WordPress 5.8">keywords:关键词;与页面内容相关的关键词,使用逗号分隔。
页面的关键词,有助于搜索引擎优化。
html <meta name="keywords" content="关键词1, 关键词2, 关键词3">description/dɪˈskrɪpʃn/:描述;页面内容的 简短而准确的摘要,搜索引擎可能会使用此字段 来控制网页在搜索结果中的外观。
页面的描述;
html <meta name="description" content="这是页面的简短描述。">referrer:访问者 来源地址 策略;控制 由当前文档发出的请求 的 HTTP
Referer请求头。theme-color:主题颜色;表示当前页面的 建议颜色,在自定义 当前页面或页面周围的用户界面的显示时,用户代理 应当使用此颜色。
content属性 应当包含一个有效的 CSS<color>值。color-scheme:颜色方案;指定 与当前文档兼容的 一种或多种配色方案。
- 这些元数据名称 可以通过
<meta>标签的name属性来指定,并配合content属性 提供具体的值。
- HTML5 规范之外 惯用的
name属性值 及其用途:- 很多规范之外 定义的常用 元数据名称 在 MetaExtensions - WHATWG Wiki 中可以查到;
- 有很多 规范之外的 惯用元数据名称,此处仅列出常见的几个;
- 很多规范之外 定义的常用 元数据名称 在 MetaExtensions - WHATWG Wiki 中可以查到;
viewport/ˈvjuːpɔːrt/:用于 移动设备 视口设置。
html <meta name="viewport" content="width=device-width, initial-scale=1.0">robots/ˈroʊbɑːts/:告诉搜索引擎爬虫 如何索引页面。
html <meta name="robots" content="index, follow">revisit-after:建议搜索引擎多久后 重新访问页面。
html <meta name="revisit-after" content="7 days">属性值的写法 应该遵循以下规则:
- 大小写不敏感:
name属性值 通常不区分大小写,但为了一致性和最佳实践,推荐使用小写。- 避免特殊字符:
name属性值中 不应包含特殊字符或空格,如果需要,可以使用连字符(-)或下划线(_)。- 明确含义:
name属性值 应该清晰地表明content属性值的含义。总的来说,
meta标签的name属性值 是根据你想要传达的元数据信息 来确定的,没有固定的值,但应该遵循 一定的命名惯例和规则。
- 什么是 有效的元数据名称 ?
元数据名称 用于:
meta标签的name属性中,用来 描述网页 特定信息的名称。
- 这些名称 通常遵循 一定的命名规范,以确保它们具有明确的含义,并且能够被浏览器、搜索引擎和其他处理工具 正确识别和使用。
以下是一些关于 有效元数据名称 的要点:
描述性:元数据名称 应该清晰地描述
content属性中 提供的信息。例如,description用于 描述页面内容,keywords用于 列出页面的关键词。简洁性:元数据名称 应该尽可能简洁,避免冗余和不必要的词汇。
小写字母:虽然 HTML 属性值不区分大小写,但为了一致性和最佳实践,通常推荐使用 小写字母。
使用连字符和下划线:如果元数据名称 由多个单词组成,可以使用连字符(-)或下划线(_)连接,例如
og:title或twitter_card。避免空格:元数据名称中 不应包含空格。
遵循约定:某些元数据名称 遵循特定的标准或约定,如 Open Graph协议(OGP)和Twitter Cards,它们定义了一系列预定义的元数据名称,用于 社交媒体分享。
自定义元数据:除了预定义的元数据名称,开发者也可以根据需要 创建自定义的元数据名称,但这些自定义名称 应该具有明确和一致的含义。
HTML5 规范:HTML5 规范中 没有列出所有可能的元数据名称,但提供了一些 常用的元数据名称,如
description、author、viewport等。搜索引擎优化(SEO):有效的元数据名称 对于搜索引擎优化至关重要,因为它们提供了 页面内容的额外信息,有助于搜索引擎 更好地理解和索引页面。
10. 兼容性:有效的元数据名称 应该被主流浏览器和搜索引擎 广泛支持和识别。
总之,有效的元数据名称 是描述网页特定信息的标准化标签,它们有助于浏览器、搜索引擎和其他工具 正确处理和显示网页内容。
3.3.1 name 属性值:HTML 规范中定义的 标准元数据名称
- 在 HTML5 中,有一些 常用的元数据名称(通过
meta标签的name属性指定)- 用于:提供关于 网页的 额外信息。
- 有助于: 搜索引擎优化、社交媒体分享、移动设备适配 等方面,从而可以提高 网页的 可访问性和用户体验。
以下是 HTML5 中常见的 元数据名称 及其用途:
⑴ 页面应用程序名称:name=“application-name” (应用名; 标识 web 应用;移动设备主屏幕)
- 应用程序名称: meta-
name="application-name";- 用于:指定当前页面 所代表的 Web 应用程序的名称。
- 显示:这个名称 通常显示在 浏览器的标签页上,特别是在移动设备上,当用户将网页 添加到主屏幕时,
application-name可以作为 应用的名称显示。 - 搭配的
content属性值:必须是一个 简短的 自由格式字符串,给出该页面所代表的 web 应用程序的名称。 - 使用限制:如果 页面不是 web 应用程序,则不能使用
application-name/ˌæplɪˈkeɪʃ(ə)n/ 元数据名称。- 简单的网页 不应该定义
name="application-name"属性值;
- 简单的网页 不应该定义
- 区分应用: 浏览器 可能会 通过使用该属性 去区分应用;
- 以下是如何使用
name="application-name"的示例 - 例: 基本使用
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="application-name" content="我的网站">
<title>我的网站</title>
</head>
<body>
<h1>欢迎来到我的网站</h1>
<!-- 页面内容 -->
</body>
</html>
- 在这个示例中,
<meta name="application-name" content="我的网站">指定了 应用的名称为“我的网站”。- 它通常用于:指定网页或 Web 应用的名称。当用户将这个网页 添加到他们的 移动设备主屏幕时,浏览器会使用这个名称 作为应用的名称。
- 请注意:不同的浏览器和操作系统 可能会以不同的方式 处理这个元数据,有些 可能不会显示这个名称,或者显示方式 可能有所不同。因此,
application-name只是一个建议,具体显示效果 取决于浏览器的实现。
- 这段代码的作用是告诉浏览器或其他设备,这个网页或Web应用的名称 是“我的网站”。它主要用于以下场景:
- ❶ Web 应用模式:当用户将网页添加到主屏幕 或以 Web 应用的形式 打开时,这个名称可能会 显示在应用图标下方。
- ❷ 搜索引擎:虽然
application-name对搜索引擎优化(SEO)的直接影响较小,但它仍然可以提供额外的上下文信息。 - 如果你在开发一个 Web 应用,使用这个标签可以让用户在使用过程中 获得更好的体验。
- 例: 多语言支持
- 可以给出 web 应用程序名称的翻译,使用
lang属性 指定每个名称的语言。 - 如果你的网站支持多种语言,你可能想要 为每种语言提供一个不同的应用名
application-name。这可以通过使用lang属性 和多个meta标签来实现:
- 可以给出 web 应用程序名称的翻译,使用
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="application-name" lang="en" content="English Site">
<meta name="application-name" lang="zh-CN" content="中文网站">
<title>多语言网站</title>
</head>
<body>
<h1>Welcome to My Multilingual Site</h1>
<!-- 页面内容 -->
</body>
</html>
- 在这个例子中,根据浏览器的语言设置,浏览器会显示 相应的应用名称。
这段代码是两个<meta>标签的组合,它们的作用是为同一个网页或Web应用定义不同语言版本的 应用名称。具体来说:
<meta name="application-name" lang="en" content="English Site">
<meta name="application-name" lang="zh-CN" content="中文网站">
-
解释:
-
❶
name="application-name"- 这个属性表明这些
<meta>标签定义的是网页或 Web 应用的名称(application-name)。它告诉浏览器或设备,这是该应用的名称。
- 这个属性表明这些
-
❷
lang="en"和lang="zh-CN"- 这是新增的属性,表示这些 元数据分别对应 不同的语言版本:
lang="en"表示第一个标签的内容 是英文(English)。lang="zh-CN"表示第二个标签的内容 是中文(简体中文)。
-
❸
content="English Site"和content="中文网站"- 这是每个标签的具体内容,分别定义了应用在不同语言环境下的名称:
- 英文环境下,应用名称为 “English Site”。
- 中文环境下,应用名称为 “中文网站”。
-
作用:
- 这段代码的目的是:为多语言环境下的 Web 应用或网页 提供 本地化的应用名称。当用户在不同语言的设备或浏览器上 访问该网页时,浏览器可以根据用户的语言设置 选择显示对应的名称。例如:
- 如果用户的设备语言 设置为英文,浏览器可能会显示 “English Site”。
- 如果用户的设备语言 设置为中文,浏览器可能会显示 “中文网站”。
-
应用场景:
- 这种做法在开发国际化(i18n)的 Web 应用时非常有用,尤其是当开发者希望应用在不同语言环境下 具有本地化的名称时。例如:
- internationalization,美 /ˌɪntərˌnæʃnələˈzeɪʃn/n. 国际化
- 当用户将网页添加到主屏幕时,应用图标下方 会显示本地化的名称。
- 在某些浏览器或设备的Web应用管理界面中,也会显示对应的本地化名称。
- 总之,这段代码是为 Web 应用提供多语言支持的一种方式,增强了用户体验的国际化和本地化。
- 例: 响应式网页设计
- 在响应式网页设计中,你可能想要 根据设备的类型(如手机或平板)来设置不同的
application-name
- 在响应式网页设计中,你可能想要 根据设备的类型(如手机或平板)来设置不同的
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="application-name" content="移动版网站">
<meta name="application-name" media="(min-width: 768px)" content="桌面版网站">
<title>响应式网站</title>
</head>
<body>
<h1>欢迎来到我的响应式网站</h1>
<!-- 页面内容 -->
</body>
</html>
- 在这个例子中,对于移动设备,浏览器会显示“移动版网站”作为应用名称;而对于桌面设备,浏览器会显示“桌面版网站”。
- 请注意,
meta标签的name="application-name"属性的效果 可能因浏览器和操作系统的不同 而有所差异。- 在某些浏览器中,即使设置了
application-name,添加到主屏幕时 仍然会显示<title>标签的内容。 - 此外,这个属性对于桌面网站的影响不大,主要用于移动设备上的 Web 应用。
- 在某些浏览器中,即使设置了
<meta>标签 的name="application-name"属性值 和<title>标签 有什么区别?
在 HTML 中有 不同的用途 和显示方式:
用途不同:
<title>标签定义了 文档的标题,这个标题显示在 浏览器的标签页上,同时也是 搜索引擎结果页面(SERP)中显示的主要文本。它是页面内容的摘要,对搜索引擎优化(SEO)非常重要。<meta name="application-name">标签 提供了一个名称,这个名称用于 在某些浏览器(尤其是 移动浏览器)中标识 Web 应用。当用户将网站 添加到主屏幕 或使用某些浏览器的“添加到主屏幕”功能时,这个名称可能会显示为 应用的图标名称。显示位置不同:
<title>标签的内容显示在 浏览器的标签页上,以及在 用户分享页面时的预览中。<meta name="application-name">的内容 通常只在用户将网页 添加到移动设备的主屏幕时 显示为应用的名称。对搜索引擎的影响:
<title>标签的内容对 搜索引擎非常重要,它是页面 SEO 的关键因素之一,直接影响页面 在搜索结果中的可见性。<meta name="application-name">对搜索引擎的影响不大,因为它主要用于 浏览器的界面显示,而不是 页面内容的描述。可访问性:
<title>标签的内容 对页面的可访问性至关重要,因为它为屏幕阅读器 提供了页面主题的即时概述。<meta name="application-name">的内容 对页面的可访问性影响不大,因为它 不直接显示在页面内容中。总结来说,
<title>标签 是页面的主要标题,对 SEO 和页面内容的描述 至关重要,而<meta name="application-name">是 一个辅助的元数据,主要用于 在移动设备上标识 Web 应用。两者在功能和显示上 有明显的区别。
⑵ 页面作者:name=“author” (作者名;作者名/联系方式;公司/组织名)
- 文档 作者名称: meta-
name="author"属性值- 用于:在 HTML 文档中 指定作者的名称。
- 目的:这个属性可以 帮助搜索引擎、浏览器 和其他工具 识别文档的创作者。
- 搭配
content属性值:必须是 一个自由格式的字符串,给出 页面作者之一的姓名。- 作者名称,可以用 自由的格式 去定义;
- 格式:
<meta name="author" content="作者名">
-
以下是几个使用
name="author"属性的例子: -
例: 单个作者
- 指定了 文档的作者是“Vicky”。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<!-- 指定单个作者 -->
<meta name="author" content="Vicky">
<title>我的个人网站</title>
</head>
<body>
<h1>欢迎来到我的个人网站</h1>
<!-- 页面内容 -->
</body>
</html>
- 例: 多个作者
- 如果你的文档 有多个作者,你可以使用多个
meta标签 来指定每个作者;
- 如果你的文档 有多个作者,你可以使用多个
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<!-- 指定多个作者 -->
<meta name="author" content="张三">
<meta name="author" content="李四">
<title>合作项目</title>
</head>
<body>
<h1>合作项目首页</h1>
<!-- 页面内容 -->
</body>
</html>
- 在这个例子中,文档有两个作者:“张三” 和 “李四”。
- 例: 包含 作者联系信息
- 有时候,你可能想 提供作者的联系信息,例如 电子邮件地址;
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<!-- 指定作者及其电子邮件地址 -->
<meta name="author" content="Jane Doe <jane.doe@example.com>">
<title>专业博客</title>
</head>
<body>
<h1>欢迎阅读我的博客</h1>
<!-- 页面内容 -->
</body>
</html>
- 在这个例子中,文档的作者是“Jane Doe”,并且提供了电子邮件地址“jane.doe@example.com”。
- 例: 公司或组织 作为作者
- 如果文档是由 公司或组织创作的,你也可以使用
name="author"属性来指定;
- 如果文档是由 公司或组织创作的,你也可以使用
<!-- w3school 的 作者名称-->
`<meta name="author" content="w3school.com.cn" />`
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<!-- 指定公司作为作者 -->
<meta name="author" content="CSDN">
<title>公司主页</title>
</head>
<body>
<h1>欢迎来到 CSDN</h1>
<!-- 页面内容 -->
</body>
</html>
- 在这个例子中,文档的作者是 “CSDN”。
⑶ 页面内容 描述:name=“description” (搜索结果 页面摘要;搜索结果优化;增加点击率)
- ① 页面内容的 描述:
<meta>标签的name="description"属性值- 用于:提供网页内容的 简短描述;
- 搜索结果 页面摘要:通常用于 搜索引擎结果页面的摘要。
- ❶ 标题下方:搜索引擎结果页面(SERPs)中,显示在 网页标题下面,帮助用户 了解网页的主要内容。
- ❷ 搜索 可见性、点击率:可以提高网页 在搜索引擎中的可见性,并可能 增加点击率。
- ② 搭配
content属性值:必须是 描述页面的 自由格式 字符串。- 该值必须 适合在页面目录中使用,例如 在搜索引擎 搜索结果页面中。
- 其中包含 页面内容的 简短精确的描述。
最佳实践
- 准确性:确保描述 准确地反映了页面内容。
- 简洁性:保持描述简洁,通常 不超过 150-160 个字符,因为搜索引擎可能会 截断过长的描述。
- 关键词:合理地包含 目标关键词,但避免关键词堆砌。
- 独特性:为每个页面 提供独特的描述,避免所有页面 使用相同的描述。
正确使用 name="description" 属性可以提高网页的搜索引擎优化(SEO)效果,吸引更多用户点击访问。
- 例: 淘宝、京东、CSDN、MDN 的页面内容描述;
<meta name="description" content="淘宝网 - 亚洲较大的网上交易平台,提供各类服饰、美容、家居、数码、话费/点卡充值… 数亿优质商品,同时提供担保交易(先收货后付款)等安全交易保障服务,并由商家提供退货承诺、破损补寄等消费者保障服务,让你安心享受网上购物乐趣!">
<meta name="description" content="京东JD.COM-专业的综合网上购物商城,为您提供正品低价的购物选择、优质便捷的服务体验。商品来自全球数十万品牌商家,囊括家电、手机、电脑、服装、居家、母婴、美妆、个护、食品、生鲜等丰富品类,满足各种购物需求。">
<meta name="description" content="CSDN是全球知名中文IT技术交流平台,创建于1999年,包含原创博客、精品问答、职业培训、技术论坛、资源下载等产品服务,提供原创、优质、完整内容的专业IT技术开发社区.">
<meta name="description" content="The MDN Web Docs site provides information about Open Web technologies including HTML, CSS, and APIs for both Web sites and progressive web apps.">
<meta name="description" content="HTML(超文本标记语言——HyperText Markup Language)是构成 Web 世界的一砖一瓦。它定义了网页内容的含义和结构。除 HTML 以外的其他技术则通常用来描述一个网页的表现与展示效果(如 CSS),或功能与行为(如 JavaScript)。">
- 展示结果:百度搜索“淘宝” 或“京东”时 出现的搜索结果页面,点击进入,按 F12 可以查看源代码;
name="description"时,搭配的content属性值,出现在 搜索引擎结果页面(SERPs)中,显示在 网页标题下面,帮助用户 了解网页的主要内容。- 页面描述的长度:通常 不超过 150-160 个字符,因为搜索引擎可能会截断过长的描述。
- 而 搜索结果页面展示图片时,能展示出来的文字 会更短;下图展示了 大概 100 个左右的汉字;
- 如下图:在搜索结果页面中,页面内容描述 没有被完全展示出来;未展示的部分 用“…” 来示意了;


⑷ 生成页面的 软件名称/版本:name=“generator” (网页生成工具)
<meta>标签的name="generator"/ˈdʒenəreɪtər/ 属性值- 用于:指定生成网页内容的工具或软件的 名称及版本。
- 实际用处:
- 这个元数据可以提供 关于网页内容是 如何生成的信息,对于网站管理员和开发者来说,这可能有助于 识别和解决兼容性问题。
- 搭配的
content属性值:- 该值必须是一个自由格式的字符串,用于 标识 生成文档的软件之一,一般是 软件名称、软件名称及版本。
- 谁不能用:不是由软件生成的页面,例如 由用户在文本编辑器中 编写标记的页面,就不能用这个属性值。
- 搜索引擎 如何通过
meta标签的name="generator"属性值 优化搜索结果 ?
识别内容管理系统(CMS):搜索引擎 可以识别网页内容是 由哪个 CMS 或网页编辑器生成的,这有助于搜索引擎 更好地理解 网页结构和内容。
提供背景信息:
meta标签的name="generator"属性 可以为搜索引擎提供 网页构建和管理的背景信息,有助于搜索引擎 更有效地 爬取和索引网站内容。辅助SEO分析:通过识别内容生成工具,搜索引擎可以 更好地理解网页的结构和内容,可能影响 页面的索引和排名。
个性化搜索结果:搜索引擎 可能根据用户的历史行为和偏好,结合网页生成工具的信息,提供更加个性化的搜索结果。
提高搜索结果的相关性:搜索引擎优化(SEO)工具和算法 可能会利用
meta标签的name="generator"属性值 来提高搜索结果的相关性,例如,通过识别特定工具 生成的内容特征,优化搜索算法。辅助网站诊断:搜索引擎 可以使用
meta标签的name="generator"属性值 来辅助诊断网站问题,例如,如果某个 CMS 或工具已知存在某些问题,搜索引擎可能会 提供相应的优化建议。综上所述,
meta标签的name="generator"属性值 在搜索引擎优化中扮演着 辅助角色,有助于搜索引擎 更好地理解和处理网页内容。
- 例: 网页编辑器
- 在这个例子中,表明这个网页是由 Adobe Dreamweaver CC 网页编辑器 生成的。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<!-- 指定网页编辑器 -->
<meta name="generator" content="Adobe Dreamweaver CC">
<title>我的个人网站</title>
</head>
<body>
<h1>欢迎来到我的个人网站</h1>
<!-- 页面内容 -->
</body>
</html>
⑸ 页面关键词:name=“keywords”(关键词列表,逗号分隔;搜索引擎优化;网站排名)
<meta>标签的name="keywords"属性值- 用于:提供 与网页内容相关的 关键词列表,关键词之间 逗号分隔。
- 实际用处:有助于搜索引擎优化(SEO);
- 这些关键词 可以帮助搜索引擎 了解网页的主题和内容,从而 在相关的搜索查询中 可能提高网页的排名。
- 尽管近年来,由于关键词堆砌等滥用行为,一些搜索引擎 可能不再给予这个标签 很高的权重,但它仍然可以作为 页面内容的一个补充说明。
最佳实践
- 相关性:确保列出的关键词 与网页内容高度相关,避免堆砌 无关关键词。
- 简洁性:不要过度填充关键词,保持列表 简洁明了。
- 更新维护:随着网站内容的更新,定期检查和更新关键词,确保它们 仍然准确反映页面内容。
请注意,过度优化 或滥用
meta标签的name="keywords"属性,如 填充无关关键词,可能会导致 搜索引擎对网站进行惩罚。
因此,使用时 应谨慎 并遵循搜索引擎的 最佳实践指南。
- 例: CSDN、淘宝、京东 官网首页的 页面关键词;
<meta name="keywords" content="CSDN博客,CSDN学院,CSDN论坛,CSDN直播">
<meta name="keyword" content="淘宝,掏宝,网上购物,C2C,在线交易,交易市场,网上交易,交易市场,网上买,网上卖,购物网站,团购,网上贸易,安全购物,电子商务,放心买,供应,买卖信息,网店,一口价,拍卖,网上开店,网络购物,打折,免费开店,网购,频道,店铺">
<meta name="Keywords" content="网上购物,网上商城,家电,手机,电脑,服装,居家,母婴,美妆,个护,食品,生鲜,京东">
⑹ ▲ HTTP referrer 头信息 :name=“referrer” (访问者 来源地址 策略;页面间跳转时 访问者是谁;前一个网页的 URL;HTTP 访问者 来源地址;发送请求的 来源页面 URL;访客从哪里而来)
<meta>标签的name="referrer"/ri’fə:rə/属性值- 用于:控制 HTTP 请求中的 访问者来源地址 Referrer 信息,即 发送请求的 前一个页面的 URL。
- 页面间跳转时:从一个网页 跳转到另一个网页
- referrerURL(来源地址):前一个页面 地址;
- current URL(当前地址):跳转到的新页面 地址;
- Referrer Policy(来源地址 策略):前一个页面 在请求新页面资源时,浏览器 是否发送/如何发送 来源地址信息 (Referrer 信息 = 前一个页面的地址),让新页面的服务器知道 访问者是谁,从哪里来,是谁在请求资源;
- 页面间跳转时:从一个网页 跳转到另一个网页
- 书写注意事项: “referrer”/ri’fə:rə/ ⇒ “re-fer-rer” ,有 4 个 r;容易被错写成 “referer” ⇒ “re-fe-rer” ,3 个 r,中间 音节的 r 容易漏写;意思是 推荐人、介绍人;在这里是 跳转前的页面地址;意思是告诉新页面 是谁介绍我 或 推荐我 访问新页面的,告诉新页面 我从哪里跳转过来的。
- HTTP 来源地址 - 维基百科,自由的百科全书
- Referer 的正确英语拼法是 referrer。这是早期 HTTP 规范当中存在的拼写错误,后来为保持向下兼容 将错就错。
- 修正:例如 DOM Level 2[1]、Referrer Policy[2] 等其他网络技术的规范 曾试图修正此问题,使用正确拼法,导致目前拼法并不统一。
- 在 Referrer Policy 中 拼写成 Referrer,在 HTTP 的 Referer 头中,拼写成 Referer 也算是一种 将错就错的 正确;
- 是否发送、如何发送 Referrer 头信息:
- 通过设置
name="referrer"这个属性,可以决定 是否发送 Referrer 头 以及 如何发送 Referrer 头信息。
- 通过设置
- 必须搭配的
content属性值:值 必须是 a referrer policy/ˈpɑːləsi/; 即content="a referrer policy"定义了 页面的 默认 referrer policy;
- 用于:控制 HTTP 请求中的 访问者来源地址 Referrer 信息,即 发送请求的 前一个页面的 URL。
- 知识拓展:什么是
Referrer Policy?- 来源地址 策略:
Referrer Policy是一个 HTTP 头部字段; - 用于:控制浏览器发送到服务器的 访问者来源地址 HTTP Referrer 字段 (= 页面跳转时,前一个页面的地址)。
- 这个字段 告诉服务器:用户是 从哪个页面 链接过来的,发送请求的 访问者 来源页面 URL,是前一个网页的 URL。
- 比如 我在 CSDN 中浏览某个博客,突然 点击博客中的一个链接,这就是 在请求其他资源,这个时候 要跳转到新页面,如果想告诉 新页面的服务器 是谁在请求资源,怎么操作?可以 通过 HTTP Referrer 字段 来控制;
Referrer Policy允许网站管理员 精细控制跨域请求时 发送的 Referrer 值。
- 来源地址 策略:
HTTP 来源地址(referer,或 HTTP referer)是 HTTP 表头的一个字段,用来表示 【从哪儿 链接到目前的网页】,采用的格式是 URL。换句话说,借着 HTTP 来源地址,目前的网页 可以检查【访客 从哪里而来】,这也常被用来 对付伪造的跨网站请求。
而 dereferer 则是将 HTTP 来源地址信息剥离,所以网站将无法识别 访客从何而来。
拼写问题
Referer 的正确英语拼法是 referrer。这是早期 HTTP 规范当中存在的拼写错误,后来为保持向下兼容 将错就错。例如 DOM Level 2[1]、Referrer Policy[2] 等其他网络技术的规范 曾试图修正此问题,使用正确拼法,导致目前拼法并不统一。
概念与功能
当访客访问网页时,HTTP 来源地址(referer 或 referring page)是 【前一个网页的 URL】。
如果是图片的话,通常指的就是 图片所在的网页。
在网页浏览器 送往网页服务器的时候,HTTP 来源地址 就被包含在 HTTP 请求方法中。网站会将来源地址记录 以便追踪用户的动态或进行统计,大部分分析软件 也都会处理这个信息。
但因 来源地址信息 可能会带来隐私权问题,不少网页浏览器 允许用户设置 不要提交这个信息,有些代理服务器和防火墙 也会将来源地址信息过滤掉,以避免外部 获知非公开的网络地址。
缺少引用地址信息 有可能会造成某些使用问题:
某些服务器 会因为缺少正确的来源地址信息 而进行阻挡,以避免 未经授权的图片引用(图像防盗链)或是 其他对服务器有影响的行为。
针对这样的阻挡,有些软件 还提供了针对特定网站 提交“假来源地址”的功能(反防盗链)。
Referrer Policy有几种不同的值,每种值 定义了不同情况下 Referrer 字段的行为:- 页面间跳转时
- referrerURL(来源地址):前一个页面 地址;
- current URL(当前地址):跳转到的新页面 地址;
- Referrer Policy(来源地址 策略):前一个页面 在请求新页面资源时,浏览器 是否发送/如何发送 来源地址信息
- 页面间跳转时
| 简述 | Referrer 头部 | 详解 |
|---|---|---|
| ❶ 完全不发送 访问者来源地址 Referrer 字段; | no-referrer/ri’fə:rə/ | 完全不发送 来源地址 Referrer 字段。 Referer 头 将被完全省略。 不将 referrer 信息与请求一起发送到任何源。 整个 Referrer 首部会被移除。访问来源信息 不随着请求一起发送。 意味着:在任何情况下,链接到其他页面或资源的请求中,都不会包含 Referer 信息。用途:这种设置 通常用于 增强用户隐私保护,因为它可以防止用户访问的当前页面地址 被泄露给其他网站。这在 处理敏感信息 或用户隐私至关重要的应用中 非常有用。 |
| ❷ 安全降级时: 不发送 访问者来源地址 Referrer 字段; 安全未降级:发送完整来源地址; | no-referrer-when-downgrade/ˌdaʊnˈɡreɪd/ | 只有当请求的 URL 是同等安全 或者更安全的协议(比如 从 http⇒ http,https ⇒ https,http ⇒ https)时,才会发送 Referrer 字段。 如果请求的 URL 协议安全性降低(比如从 https ⇒ http),则不发送 Referrer 字段。 用途:这样的设置 有助于保护用户隐私,同时在必要时 仍然提供访问者信息。 |
| ❸ 只发 源信息; 源信息:来源地址的“协议+域名”,去掉路径; | origin/ˈɔːrɪdʒɪn/ | 只发送 Referrer 字段的源信息(协议+域名),不包括 路径信息。 不管是否跨源和降级:当设置为 origin 时,无论请求的目标地址 是同源还是跨源,也无论请求是升级 还是降级安全协议,浏览器都只会发送 当前文档的源信息:协议和域名(origin),而不会发送 完整的 URL 路径和查询参数。用途:这种设置 有助于保护用户的隐私,因为它不会泄露 用户在当前页面上的具体活动细节,只提供协议和域名信息。 |
| ❹ 跨源:只发源信息; 同源:发完整来源地址; | origin-when-cross-origin | 当请求是同源的,发送完整的 Referrer 字段;当请求是跨域的,只发送源信息。 用途:这样的设置有助于 在保护用户隐私的同时,对内部导航 保持一定的透明度。 |
| ❺ 同源:发完整地址; 跨源: 不发地址; | same-origin | 只有当请求是同源的,才会发送完整的 Referrer 字段;如果是跨域的,则不发送。 用途:这样的设置有助于 在保护用户隐私的同时,对内部导航 保持一定的透明度。 |
| ❻ 协议不降级:才发源信息; 协议降级:不发地址; | strict-origin | 类似于 origin,发源信息,但是当请求的 URL 协议安全性降低时,也不发送 源信息。所以,加一个 strict 指的就是 协议的安全等级 不能降级,降级了 就不发了;这种设置可以 在保护用户隐私的同时,对于同等级 或更安全协议的请求 仍然提供域名信息,而对于降级到不安全协议的请求 则不发送任何 访问者的信息。 用途:在保护用户隐私的同时,对同样安全 或更安全的请求 保持一定的透明度。 |
| ❼ 跨源+协议安全不降级:才发源信息; 跨源+协议安全降级:不发地址; 同源:发完整来源地址; | strict-origin-when-cross-origin(默认值) | 类似于 origin-when-cross-origin,跨源发源信息,但是当请求的 URL 协议安全性降低时,也不发送 源信息。所以,加一个 strict 指的就是 协议的安全等级 不能降级,降级了 就不发了; |
| ❽ 发送 完整来源地址; 不管是否跨源,也不管协议是否降级; | unsafe-url(不推荐使用;特殊需求除外) | 无论请求是否跨源,协议是否降级,都会发送完整的 Referrer 字段,包括路径和查询字符串。 注意:这种设置可能会 导致用户隐私泄露,因此只有在 充分理解风险 并确实需要时才使用。 |
- 通过设置
Referrer Policy,网站可以保护用户隐私,防止敏感信息泄露,同时也能减少 因 Referrer 字段引起的安全问题。
-
Referrer 信息:是谁在请求资源?访问者是谁?
- 点击网页中的链接 会进行页面间跳转,在从一个网页 跳转到另一个新网页时,需要先请求 新网页的资源,服务器收到请求后 给与响应,发送新网页的资源回来,我们才能看到新网页,而发送请求时 是否要发送访问信息(来源地址:前一个页面的地址),让服务器知道 是谁在请求资源,访问者是谁?可以 通过 Referrer 信息 来控制;
- 协议和域名
- https(=协议): //example.com/(=域名)page.html(=路径)
- 跨源:协议和域名,有一个不一样,就是跨源;
example.com和mozilla.org⇒ 不同域名,跨源;- https 和 http ⇒ 两个不同协议,跨源;即便 域名一样,协议不同,也是跨源;
- 同源:协议和域名,要一模一样;
- 只有当两个 URL 的协议、域名和端口 都相同时,它们才被认为是同源的。如果其中任何一个元素不同,那么这两个URL就被认为是不同源的;没有标明 端口时,协议和域名要一模一样;
- 源信息
origin:协议+域名,不含路径;https://example.com/(去掉具体路径);- 源信息:协议、域名和端口(可省略 用默认值),不包含路径和查询参数。
- 完整地址:协议+域名+路径;
https://example.com/page.html - 来源地址:页面间跳转时,前一个页面的地址;
- 协议和域名
- 点击网页中的链接 会进行页面间跳转,在从一个网页 跳转到另一个新网页时,需要先请求 新网页的资源,服务器收到请求后 给与响应,发送新网页的资源回来,我们才能看到新网页,而发送请求时 是否要发送访问信息(来源地址:前一个页面的地址),让服务器知道 是谁在请求资源,访问者是谁?可以 通过 Referrer 信息 来控制;
-
示例
| Referrer Policy | referrerURL(来源地址:前一个页面 地址) | current URL(当前地址:跳转到的新页面 地址) | 请求新页面资源时 发送的 Referrer 信息 |
|---|---|---|---|
❶ 不发送 访问者来源地址; | https://example.com/page.html → | 任何网址 (any domain or path) | 不发送 来源地址; no referrer; |
| ❷ 安全降级:不发送; 安全未降级:发送完整地址; no-referrer-when-downgrade | https://example.com/page.html → | https://example.com/otherpage.html | https⇒ https; 安全未降级,发送完整来源地址; https://example.com/page.html |
| https://example.com/page.html → | https://mozilla.org | https⇒ https; 安全未降级,发送完整来源地址;https://example.com/page.html | |
| https://example.com/page.html → | http://example.org | https⇒ http; 安全降级了,不发送地址; no referrer; | |
❸ 只发源信息(协议+域名);origin | https://example.com/page.html → | 任何网址(any domain or path) | 只发源信息(协议+域名,无路径); https://example.com/ |
| ❹ 跨源:只发源信息(协议+域名;无路径); 同源:发完整地址; origin-when-cross-origin | https://example.com/page.html → | https://example.com/otherpage.html | https://example.com⇒ https://example.com; 同源,发完整地址; https://example.com/page.html |
| https://example.com/page.html → | https://mozilla.org | https://example.com⇒ https://mozilla.org; 域名变了,跨源,只发源信息(协议+域名); https://example.com/ | |
| https://example.com/page.html → | http://example.com/page.html | https⇒ http; 协议安全降级了,跨源,只发源信息; https://example.com/ | |
| ❺ 协议不降级:才发源信息; 协议降级:不发地址; strict-origin | https://example.com/page.html → | https://mozilla.org | https⇒ https; 协议未降级,发送源信息; https://example.com/ |
| https://example.com/page.html → | http://example.org | https ⇒ http; 协议降级,不发送地址;no referrer | |
| http://example.com/page.html → | any domain or path | http⇒ https、http; 本身不安全协议(因为不会再降级),都发送源信息; http://example.com/ | |
| ❻ 跨源+协议安全不降级:只发源信息; 跨源+协议安全降级:不发地址; 同源:发完整来源地址; strict-origin-when-cross-origin | https://example.com/page.html → | https://example.com/otherpage.html | https://example.com⇒ https://example.com; 同源:发完整来源地址; https://example.com/page.html |
| https://example.com/page.html → | https://mozilla.org | https://example.com⇒ https://mozilla.org; 域名不同,跨源,协议相同,不降级,只发源信息; https://example.com/ | |
| https://example.com/page.html → | http://example.org | https⇒ http; 协议不同,且协议降级,不发送地址; no referrer; | |
| ❼ 同源:发完整地址; 跨源:不发地址; same-origin | https://example.com/page.html → | https://example.com/otherpage.html | https://example.com⇒ https://example.com; 协议、域名一样,同源,发完整地址; https://example.com/page.html |
| https://example.com/page.html | https://mozilla.org | example.com⇒ /mozilla.org; 域名不一样,跨源,不发送地址; no referrer; | |
| ❽ 发送 完整来源地址; 不管是否跨源,也不管协议是否降级; unsafe-url | https://example.com/page.html → | 任何网址(any domain or path) | 发送 完整来源地址; https://example.com/page.html |
- 总结
- 2个:不发、降级不发;
- 4个:只发源、跨源只发源、不降级才发源、跨源+不降级 才发源;
- 2个:同源发完整、都发完整;
- 遗留值 问题:如果
name属性值 是下表第一列给出的值之一,则将 值设置为 第二列给出的值:- 在HTML中,“legacy/ˈleɡəsi/ value” 通常指的是一些过时的、不再推荐使用的值,它们可能与旧的规范或特性有关。这些值可能仍然被支持 以确保向后兼容性,但它们并不是最佳实践,也不应该在新的代码中使用。
| 遗留值(Legacy value) | 对应的 标准 Referrer policy 名 |
|---|---|
| never | no-referrer |
| default | the default referrer policy |
| always | unsafe-url |
| origin-when-crossorigin | origin-when-cross-origin |
- 例:csdn 就使用了 一个
content="always",不是标准的 referrer policy 名称,直接使用content="unsafe-url"会更好;
-
来源地址策略 referrer policy 的使用
-
① 在 HTML 中 设置 来源地址策略 referrer policy
- ❶ 为整个文档设置 来源地址 referrer 策略:可以用一个
name="referrer"的<meta>元素 。
<meta name="referrer" content="origin" />- ❷ 在单个元素上 设置独立的 来源地址 referrer 策略
- 在
<a>、<area>、<img>、<iframe>、<script>、<link>元素上 设置referrerpolicy属性。 - 在
<a>、<area>、<link>元素上 设置rel属性 设置为noreferrer。
- 在
<a href="http://example.com" referrerpolicy="origin">…</a><a href="http://example.com" rel="noreferrer">…</a> - ❶ 为整个文档设置 来源地址 referrer 策略:可以用一个
- ② HTTP :指定 后备的 来源地址 referrer 策略
- 如果 在策略未获广泛的浏览器支持的情况下 指定一种后备策略,使用 逗号分隔 的列表,并将 希望使用的策略 放在最后:
- 如下,
no-referrer仅在strict-origin-when-cross-origin不被浏览器支持的情况下 被使用。
Referrer-Policy: no-referrer, strict-origin-when-cross-origin
-
③ 以下是
<meta>标签中 如何使用name="referrer"属性的几个例子: -
例: 不发送 推荐人来源地址(Referrer 头信息)
- 浏览器在任何情况下 都不会发送 Referrer 头信息。
- 在需要保护用户隐私 或者避免敏感信息泄露的情况下使用,例如 在处理涉及个人数据 或者版权内容的页面时,通过不发送 Referer 头 来减少跟踪用户行为的可能性。
meta标签的name="referrer" content="no-referrer"属性值- 用于:控制 HTTP
Referer请求头的发送行为。 - 当设置为
no-referrer时,浏览器将不会发送 HTTPReferer请求头,这意味着在任何情况下,包括链接到其他页面或资源的请求中,都不会包含Referer信息。 - 这种设置通常用于:增强用户隐私保护,因为它可以防止用户访问的当前页面地址 被泄露给其他网站。这在处理敏感信息 或用户隐私至关重要的应用中 非常有用。
- 用于:控制 HTTP
- 浏览器在任何情况下 都不会发送 Referrer 头信息。
-
假设你运营一个在线购物网站,你希望保护用户的隐私,避免在用户点击外部链接时 泄露他们正在访问的具体页面信息。你可以在你的 HTML 文档的
<head>部分添加如下meta标签:
<head>
<meta name="referrer" content="no-referrer">
</head>
- 这样设置后,无论用户从你的网站点击链接到其他网站,还是从其他网站链接到你的网站,浏览器都不会在 HTTP 请求中 包含
Referer头。这有助于 保护用户隐私,尤其是在 涉及敏感交易信息的电子商务网站中 尤为重要。
-
例: 仅在协议降级时 不发送来源地址/ Referrer 头信息(访问者 来源地址 = 前一个页面的地址)
- 指定了仅当 从 HTTPS 跳转到 HTTP 时 不发送 Referrer 头信息,其他情况下会发送。
meta标签的name="referrer" content="no-referrer-when-downgrade"属性值- 用于:控制 HTTP
Referer请求头的发送行为。 - 具体来说,这个属性值在以下情况下使用:
- 相对安全协议间请求:如果当前页面通过 HTTPS 提供内容,并且请求的目标地址也是 HTTPS ,或 通过 HTTP 到 HTTP 时,浏览器会发送完整的 URL 作为
Referer头。 - 降级安全协议请求:如果请求的目标地址从 HTTPS 降级到 HTTP,浏览器则不会发送
Referer头,以保护用户隐私和安全。- 如果你有一个使用 HTTPS 的网站,并且你希望在用户点击链接到其他 HTTP 网站时 不泄露你的网站地址,那么这个属性值就很有用。
- 用于:控制 HTTP
-
假设你有一个 https 网站
https://example.com,你希望在用户从你的网站点击链接到其他 http 网站时,不发送Referer头,你可以在你的 HTML 文档的<head>部分添加如下meta标签:
<head>
<meta name="referrer" content="no-referrer-when-downgrade">
</head>
-
这样设置后,当用户从
https://example.com点击一个链接到http://another-site.com(一个 HTTP 网站),浏览器将不会在请求中包含Referer头。- 但如果链接的目标网站也是 HTTPS 的,比如
https://secure-site.com,则浏览器会发送https://example.com作为Referer头。 - 这样的设置有助于保护用户隐私,同时在必要时仍然提供 访问者信息。
- 但如果链接的目标网站也是 HTTPS 的,比如
-
哔哩哔哩 网站就设置了这样的 referrer 信息
-
例: 只发送 来源地址的源信息;
- 指定了只发送来源的 源信息(协议、域名和端口),不包含 路径和查询参数。
meta标签的name="referrer" content="origin"属性值- 用于:控制 HTTP
Referer请求头的发送行为。 - 当设置为
origin时,无论请求的目标地址 是同源还是跨源,也无论请求是升级还是降级安全协议,浏览器都只会发送 当前文档的协议和域名(origin),而不会发送 完整的 URL 路径和查询参数。 - 这种设置 有助于保护用户的隐私,因为它不会泄露 用户在当前页面上的具体活动细节,只提供协议和域名信息。
-
假设你有一个网站
https://www.example.com,你想在用户点击链接 跳转到其他网站时,只发送 源信息(协议+域名) 作为Referer头,以保护用户隐私。
<head>
<meta name="referrer" content="origin">
</head>
-
这样设置后,无论用户点击链接到同源的
https://www.example.com/path/to/resource还是跨源的https://another-site.com,浏览器在发送请求时,Referer头都只会包含https://www.example.com。 -
这个设置对于保护用户隐私 特别有用,尤其是在用户访问包含敏感信息的页面时。
- 例如,如果你的网站 提供健康咨询或金融服务,用户可能 不希望他们的具体访问路径 被其他网站知晓。
- 通过设置
content="origin",你可以确保用户在访问你的网站时的隐私 得到保护。
- 例: 跨域请求时 只发送来源的源信息(协议+域名,不含路径和参数)
- 指定了对于 同源请求 发送完整的 Referrer 头,而对于跨源请求 只发送来源的源信息。
meta标签的name="referrer" content="origin-when-cross-origin"属性值- 用于:控制 HTTP
Referer请求头的发送行为。 - 具体来说,这个属性值在以下情况下使用:
- ❶ 同源请求:当请求的目标地址 与当前页面同源时,浏览器会发送 包含完整 URL(不包含 URL 参数)的
Referer头。 - ❷ 跨源请求:当请求的目标地址 与当前页面不同源时,浏览器只发送 当前文档的源信息(协议+域名)(origin),而不发送完整的 URL。
- 这种设置可以 在保护用户隐私的同时,对于同源请求 仍然提供足够的信息,比如 在追踪用户在网站内部的行为时 可能会用到。
- ❶ 同源请求:当请求的目标地址 与当前页面同源时,浏览器会发送 包含完整 URL(不包含 URL 参数)的
- 用于:控制 HTTP
- 假设你有一个网站
https://www.example.com,你想在用户从你的网站 点击链接到其他网站时,只发送域名作为Referer头,以保护用户隐私,但对内部链接 仍然发送完整的 URL。- 你可以在你的 HTML 文档的
<head>部分添加如下meta标签:
- 你可以在你的 HTML 文档的
<head>
<meta name="referrer" content="origin-when-cross-origin">
</head>
- 这样设置后,
- 当用户从
https://www.example.com/path/to/resource1点击一个链接到https://www.example.com/path/to/resource2(一个同源的页面),浏览器会发送https://www.example.com/path/to/resource1作为Referer头。 - 但如果用户 点击链接到
https://another-site.com(一个不同源的网站),浏览器只会发送https://www.example.com作为Referer头,而不会包含 具体的路径信息。 - 这样的设置有助于: 在保护用户隐私的同时,对内部导航 保持一定的透明度。
- 当用户从
-
例: 安全不降级 才发源信息,降级了 就不发地址
meta标签的name="referrer" content="strict-origin"属性值- 用于:控制 HTTP
Referer请求头的发送行为;- 具体来说,这个属性值在以下情况下使用:
- 安全协议间 请求:当请求的目标地址 与当前页面一样安全或者更加安全(例如 从 http ⇒ http、https ⇒ https、http ⇒ https),浏览器会发送当前文档的 源信息 协议+域名(origin)作为
Referer头。 - 降级安全协议 请求:如果请求的目标地址 从 HTTPS 降级到 HTTP,浏览器则不会发送
Referer头,以保护用户隐私和安全。 - 这种设置可以 在保护用户隐私的同时,对于同等级 或更安全协议的请求 仍然提供域名信息,而对于降级到不安全协议的请求 则不发送任何 访问者的信息。
-
假设你有一个使用 HTTPS 的网站
https://www.example.com,你想在用户点击链接 跳到其他网站时,只在目标网站同样安全或更安全时 发送域名作为Referer头,而在链接到 HTTP 网站时 不发送任何Referer头。- 你可以在你的 HTML 文档的
<head>部分添加如下meta标签:
- 你可以在你的 HTML 文档的
<head>
<meta name="referrer" content="strict-origin">
</head>
- 这样设置后,
- 当用户从
https://www.example.com点击一个链接到https://another-secure-site.com(一个同样是 HTTPS 的网站),浏览器会发送https://www.example.com作为Referer头。 - 但如果用户点击链接到
http://less-secure-site.com(一个 HTTP 网站),浏览器则不会在请求中 包含Referer头。 - 这样的设置有助于:在保护用户隐私的同时,对同样安全或更安全的请求保持一定的透明度。
- 当用户从
-
例: 同源 才发完整地址,不同源 不发地址
meta标签的name="referrer" content="same-origin"属性值- 用于:控制 HTTP
Referer请求头的发送行为。- 当设置为
same-origin时,浏览器将只在同源请求中 发送包含完整 URL(不包含 URL 参数)的Referer头。- 对于跨源请求,浏览器则不会发送
Referer头。 - 这种设置可以 在保护用户隐私的同时,允许在同一个域内 追踪用户的页面访问路径,这对于网站内部的分析和链接推荐等功能 可能是有用的。
- 对于跨源请求,浏览器则不会发送
- 当设置为
-
假设你有一个电子商务网站
https://www.example.com,你想在用户点击链接 跳到该网站内部的其他页面时,保留完整的 URL 作为Referer头,以便于分析用户在网站内的浏览行为。同时,你希望在用户点击链接到其他网站时,不发送Referer头以保护用户隐私。- 你可以在你的 HTML 文档的
<head>部分添加如下meta标签:
- 你可以在你的 HTML 文档的
<head>
<meta name="referrer" content="same-origin">
</head>
- 这样设置后,
- 当用户从
https://www.example.com/product1点击一个链接到https://www.example.com/product2(一个同源的页面),浏览器会发送https://www.example.com/product1作为Referer头。 - 但如果用户点击链接到
https://another-site.com(一个不同源的网站),浏览器则不会在请求中包含Referer头。 - 这样的设置有助于:在保护用户隐私的同时,对内部导航保持一定的透明度。
- 当用户从
-
例: 总是发送完整的 Referrer 头信息
- 指定了 总是发送完整的 Referrer 头信息,包括源信息、路径和查询字符串。
meta标签的name="referrer" content="unsafe-url"属性值- 用于:控制 HTTP
Referer请求头的发送行为。- 当设置为
unsafe-url时,无论是同源请求 还是跨源请求,浏览器都会发送 包含完整 URL(不包含 URL 参数)的Referer头。
- 当设置为
- 这种设置可能会 带来隐私和安全风险,因为它会在所有情况下 泄露用户的来源信息,包括 当请求从 HTTPS 降级到 HTTP 时。因此,这个属性值 通常不推荐使用,除非在特定的用例中 确实需要这样做,并且已经充分考虑了 潜在的风险。
-
假设你有一个网站
https://www.example.com,出于某种特殊需求,你需要在所有情况下 都发送完整的Referer头。- 你可以在你的 HTML 文档的
<head>部分添加如下meta标签:
- 你可以在你的 HTML 文档的
<head>
<meta name="referrer" content="unsafe-url">
</head>
- 这样设置后,无论用户从
https://www.example.com点击链接 跳到同源的https://www.example.com/path/to/resource还是跨源的https://another-secure-site.com或者降级到http://less-secure-site.com,浏览器都会在请求中 包含https://www.example.com作为Referer头。- 注意:这种设置可能会 导致用户隐私泄露,因此只有在充分理解风险 并确实需要时才使用。
⑺ 页面主题颜色:name=“theme-color”(移动端;浏览器标题栏、地址栏、工具栏颜色)
-
<meta>标签的name="theme-color"/θiːm/,/ˈkʌlər/ 属性- 用于:指定移动端 浏览器的主题颜色,该颜色将用于 浏览器的地址栏、工具栏等 界面元素。
- 通过设置该属性,可以增强网站在 移动端的视觉效果,提升用户体验。
- 在移动设备上,浏览器的界面元素(如 地址栏和工具栏)会根据网站的主题颜色 进行着色,以提供更一致的视觉体验。
- 正确设置 theme-color 可以使得网站在移动端浏览器中 看起来更加协调和专业。
- theme-color:定义用户代理 应该使用的建议颜色,以自定义 页面或周围用户界面的显示。会覆盖 web 应用清单中设置的任何主题颜色。
- 例如,浏览器可以用指定的值 为页面的 标题栏着色,或者将其用作选项卡栏或任务切换器中的高亮颜色。
- 视觉效果
- 设置 theme-color 后,用户在访问网站时 会看到浏览器界面元素(如地址栏和工具栏)与网站主题色相匹配。
- 这可以增强网站的品牌识别度,并提供更舒适的视觉体验。
- 搭配的
content属性值:字符串,一个有效的 颜色值, CSS<color>值。- 颜色值类型:十六进制颜色代码、RGB、RGBA、HSL、HSLA、CSS 颜色名称。
- 例:#ff0000(红色)、rgb(255, 0, 0)、hsl(0, 100%, 50%)。
- 值的选择:
- 应选择与网站主题色 一致的颜色值,以保持网站整体风格的一致性。
- 考虑到不同设备的显示效果,选择颜色时 应考虑色彩的对比度和可读性。
- 颜色值类型:十六进制颜色代码、RGB、RGBA、HSL、HSLA、CSS 颜色名称。
- 搭配的
media属性值: 多个<meta>设置name="theme-color"时,media属性值 必须是唯一的,这样才能有针对性地匹配;media属性可以用来 描述所提供的颜色 应该使用的环境。
- 浏览器支持
<meta>标签的name="theme-color"属性值,可以直接访问 theme-color Meta Tag | Can I use…来查看各个浏览器的支持情况。
- 用于:指定移动端 浏览器的主题颜色,该颜色将用于 浏览器的地址栏、工具栏等 界面元素。
-
theme-color:设置 Web 应用的主题颜色,用于 Android/ˈændrɔɪd/ Chrome 的工具栏颜色。
- 在 Android 设备上:主要影响 Google/ˈɡuːɡl/ Chrome/kroʊm/ 浏览器(谷歌浏览器)。
- 它允许网站开发者指定一个颜色,当用户将网站添加到主屏幕后,作为 web app 启动时的背景颜色,以及在某些情况下,改变浏览器工具栏的颜色。从 Android 5.0(Lollipop)开始,theme-color 还会影响 状态栏和导航栏的颜色。
- 在 iOS 设备上:Apple 在其 Safari 浏览器中实现了自己的一套机制来处理主题颜色。对于 iOS,主要的控制点是通过
apple-mobile-web-app-status-bar-style元信息 来改变顶部状态栏的颜色,当用户将网站添加到主屏幕 并以全屏模式启动时使用。- Safari 在某些情况下 可能也会受到 theme-color 元信息的影响,但这并不是官方文档明确支持的行为,可能是因为浏览器的实现细节或与其他元信息标签的交互导致的。因此,不能依赖 theme-color 在 iOS 上的一致行为,特别是在改变状态栏颜色方面,该操作不应被视为可靠的行为。
- 在 Android 设备上:主要影响 Google/ˈɡuːɡl/ Chrome/kroʊm/ 浏览器(谷歌浏览器)。
- 例:
<meta>元素对于 Android 端 Chrome 浏览器造成的影响。
<!--设置主题颜色为蓝色-->
<meta name="theme-color" content="#4285f4" />
- 显示结果:一开始背景色变为蓝色,后面版本 地址栏颜色 也从白色变为蓝色了 ;
#4285f4 是一种颜色代码,它代表的是一种蓝色调,具体是一种较深的蓝色,带有一点紫色的色调。这种颜色通常在网页设计和数字媒体中使用,给人以专业、现代的感觉。在 RGB 颜色模型中,#4285f4
对应的颜色值为:
- 红色(R):66
- 绿色(G):133
- 蓝色(B):244
这种颜色也被称为“Google 蓝”,因为它是 Google 品牌色彩之一。
- 例: 用
media来查询一个媒体类型,如果条件符合 则使用对应颜色。- 当用户设备处于浅色模式时,主题色为白色;处于深色模式时,主题色为黑色。
<meta name="theme-color" media="(prefers-color-scheme: light)" content="white" />
<meta name="theme-color" media="(prefers-color-scheme: dark)" content="black" />
...
-
<meta name="theme-color":- 这是HTML的元数据标签,
name="theme-color"表示定义网页的主题颜色。
- 这是HTML的元数据标签,
-
media="(prefers-color-scheme: light)":- 这是一个 媒体查询条件,表示这段代码只在用户设备处于“浅色模式”(
light)时生效。 prefers-color-scheme是一个 CSS 媒体特性,首选颜色方案,用于 检测用户的系统主题偏好。
- 这是一个 媒体查询条件,表示这段代码只在用户设备处于“浅色模式”(
-
content="white":- 这是主题颜色的具体值,设置为
white,即白色。
- 这是主题颜色的具体值,设置为
-
功能:
- 当用户的设备处于浅色模式时,这段代码会将网页的主题颜色设置为白色。深色模式,主题颜色为黑色;
- 主题颜色通常用于浏览器的标签页、地址栏等区域的背景色,或者在一些支持主题色的浏览器和操作系统中,影响网页的整体外观。
- 例: 使用绿色 作为主题色;
<!DOCTYPE HTML>
<title>HTML Standard</title>
<meta name="theme-color" content="#3c790a">
...
- 例: 如果我们只想 在暗模式下 使用 “绿色” 作为本标准的主题色,我们可以使用
preferences -color-scheme媒体特性:
<!DOCTYPE HTML>
<title>HTML Standard</title>
<meta name="theme-color" content="#3c790a" media="(prefers-color-scheme: dark)">
...
- 例: 动态变化,如果网站有多个主题或需要根据页面内容 动态改变主题颜色,可以使用 JavaScript 来动态设置
theme-color:
document.querySelector("meta[name=theme-color]").setAttribute("content", "#00ff00");
- 这段代码将主题颜色 更改为绿色(#00ff00)。
⑻ 配色方案:name=“color-scheme”(浅色背景/白天模式、深色背景/夜间模式;搭配媒体查询)
-
meta标签的name="color-scheme"属性- 用于:告诉浏览器页面支持的颜色模式,以便浏览器可以根据用户的系统偏好 自动切换到相应的颜色模式。
- 定义网页 在不同颜色模式(如 浅色模式和深色模式)下的颜色主题。
- 这个属性允许开发者 指定页面在不同用户偏好或系统颜色模式下的外观。
- 这个属性通常用在 移动端的网页设计中,以支持深色模式和浅色模式的自动切换。
- 为了帮助用户代理(浏览器)立即使用所需的配色方案 呈现页面背景(而不是等待 页面中的所有 CSS 加载),可以在
<meta>元素中提供“配色方案”值。
- 定义网页 在不同颜色模式(如 浅色模式和深色模式)下的颜色主题。
- 用于:告诉浏览器页面支持的颜色模式,以便浏览器可以根据用户的系统偏好 自动切换到相应的颜色模式。
-
搭配的
content属性值- 该值必须是与 CSS“color-scheme”属性值的语法匹配的字符串。它决定了页面支持的配色方案。
- CSS 颜色调整规范中 定义的标准名称
normal:未指定配色方案,应当仅使用 默认配色方案进行渲染;[light | dark]+:文档支持的一种或多种配色方案,优先第一种;- 文档所支持的一种或多种配色方案。如果多次指定同一个配色方案,则与仅指定一次效果相同。
- 如果指定了多种配色方案,则表示 文档优先选择第一种方案——如果用户更倾向于 选择第二种配色方案,则可以接受第二种。
only light:仅支持浅色模式(浅色背景,深色前景);- 按照规范,
only dark是无效的。如果在文档不支持深色模式的情况下 强迫其以深色模式进行渲染,会导致内容不可读。所以,在未经配置的情况下,所有主要浏览器 均默认使用“浅色模式”。
- 按照规范,
-
meta标签name="color-scheme"时 搭配的content属性值 必须是下列关键字之一。
color-scheme: normal;
color-scheme: light;
color-scheme: dark;
color-scheme: light dark;
color-scheme: only light;
/* 全局值 */
color-scheme: inherit;
color-scheme: initial;
color-scheme: revert;
color-scheme: revert-layer;
color-scheme: unset;
- 最常见的配色偏好:
-
浅色方案(“白天模式”):由浅色背景色 和深色前景/文本色组成。
-
深色配色方案(“夜间模式”):由相反的颜色组成,深色背景色 和浅色前景/文本色。
-
指定 浅深配色方案: 颜色可以改,并不代表一个确切的调色板(如 黑白),而是一系列可能的调色板。为了确保特定的前景或背景颜色,需要显式地指定它们。而不是使用浏览器的默认颜色搭配(浏览器默认搭配 一般是 黑-白)。
-
CSS color-scheme 规范文档:CSS Color Adjustment Module Level 1
-
-
以下是如何使用
meta标签的name="color-scheme"属性的例子: -
例: 支持浅色和深色模式:
<meta name="color-scheme" content="light dark">- 这个例子中,
content属性的值设置为"light dark",表示页面 同时支持浅色模式和深色模式。 - 这个声明意味着 你的网站或页面支持两种颜色模式:浅色模式(light)和深色模式(dark)。浏览器会根据用户的系统设置 或用户在浏览器中的首选项 自动切换这两种颜色模式。
- 浅色模式(light):这是大多数网站和应用的默认颜色模式,背景通常是白色或浅色,文字和其他元素通常是深色。
- 深色模式(dark):这种模式背景通常是深色,文字和其他元素是浅色,适合在低光环境下使用,可以减少眼睛疲劳,并且可能更节能。
- 这个例子中,
-
例: 仅支持浅色模式:
<meta name="color-scheme" content="light">- 在这个例子中,
content属性的值设置为"light",表示页面 仅支持浅色模式。
- 在这个例子中,
-
例: 仅支持深色模式:
<meta name="color-scheme" content="dark">- 这个例子中,
content属性的值设置为"dark",表示页面 仅支持深色模式。
- 这个例子中,
-
例: 使用 CSS 媒体查询 进一步控制颜色模式:
- 除了设置
meta标签外,你还可以结合 CSS 媒体查询来 为不同的颜色模式定义不同的样式。例如,为深色模式定义特定的背景色和文本色:
body { background-color: white; /* 默认浅色模式的背景色 为白色 */ color: black; /* 默认浅色模式的文本色 为黑色 */ } @media (prefers-color-scheme: dark) { body { background-color: black; /* 设置 深色模式的背景色 为黑色 */ color: white; /* 设置 深色模式的文本色 为白色 */ } }- 这个 CSS 代码会根据用户的系统偏好 自动应用不同的背景色和文本色。
- 除了设置
-
通过结合使用
meta标签的name="color-scheme"属性和 CSS 媒体查询,你可以创建一个能够 自动适应用户颜色偏好的 响应式网站。
- 常见问题
- ① 使用
<meta>标签的name="color-scheme"属性值时,如何显式指定背景色和前景色?
<style>
/* 1. 定义默认的背景色和文本颜色*/
body {
background-color: white; /* 默认背景色 为白色 */
color: blue; /* 默认文本色 为蓝色 */
}
/* 2. 使用媒体查询为深色模式 指定背景色和前景色/文本颜色:*/
@media (prefers-color-scheme: dark) {
body {
background-color: darkgreen; /* 设置深色模式的背景色 为深绿色 */
color: white; /* 设置深色模式的文本色 为白色 */
}
}
/* 3. 使用媒体查询为浅色模式 指定背景色和前景色:*/
@media (prefers-color-scheme: light) {
body {
background-color: white; /* 设置浅色模式的背景色 为白色 */
color: darkgreen; /* 设置浅色模式的文本色 为深绿色 */
}
}
</style>
-
显示结果
- 浅色模式:背景白色,文字深绿色;
- 深色模式:背景深绿色,文字白色;
- 浅色模式:背景白色,文字深绿色;
-
注:测试时,需要切换 系统的颜色模式 ,才会有变化(以下 windows 10 系统,详细方法 下方有介绍)
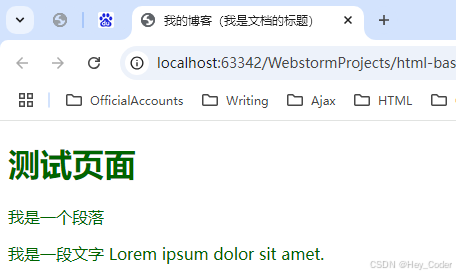
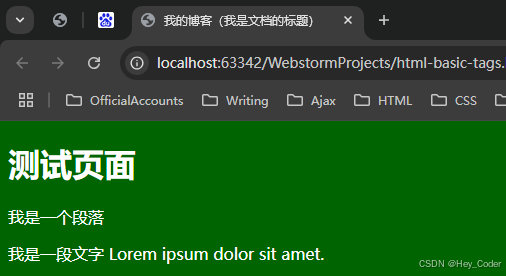

- ② 使用媒体查询 自定义了深色模式 的背景色 为什么没有变化?
- 设置了 颜色方案为深色模式
<meta name="color-scheme" content="dark">,且设置了@media (prefers-color-scheme: dark){}的 具体背景颜色 为background-color: darkgreen;,为什么网页的背景色还是黑色?
- 设置了 颜色方案为深色模式
如果你同时设置了
<meta name="color-scheme" content="dark">和 CSS 媒体查询
@media (prefers-color-scheme: dark),但网页的背景色仍然是黑色,这可能是由以下几个原因造成的:
浏览器不支持或未正确解析
meta标签:
- 并非所有浏览器都支持
meta标签的name="color-scheme"属性。如果用户的浏览器不支持这个属性,它将忽略这个设置。- 确保
meta标签位于<head>部分,并且没有拼写错误。CSS 媒体查询未被触发:
- 媒体查询
@media (prefers-color-scheme: dark)是基于用户系统的颜色偏好 设置的。如果用户的系统设置为浅色模式,即使页面设置了<meta name="color-scheme" content="dark">,媒体查询也不会被触发。- 确保你的CSS代码没有被其他样式覆盖。
CSS 优先级问题:
- 如果页面上有其他 CSS 规则设置了
background-color,并且这些规则的优先级更高,它们可能会覆盖你的媒体查询规则。- 检查CSS是否有其他规则覆盖了
background-color。CSS 代码错误:
- 确保 CSS 代码没有语法错误。例如,
darkgreen是一个有效的 CSS 颜色值,但如果写错或使用了无效的颜色值,可能会导致背景色不被正确设置。浏览器缓存问题:
- 有时浏览器缓存可能会导致旧的 CSS 样式被应用。尝试清除缓存或使用无痕/隐私模式打开页面,看看是否有变化。
页面其他脚本或样式的影响:
- 页面上的其他 JavaScript 脚本或 CSS 样式可能在运行时动态改变了背景色。
浏览器主题或扩展程序的影响:
- 某些浏览器主题或扩展程序可能会覆盖页面的样式,包括背景色。
- ③ 如何 触发媒体查询
@media (prefers-color-scheme: dark)?- 例: windows 10 系统 如何设置深色模式;
用户系统偏好: 用户的操作系统 需要设置为深色模式。在大多数现代操作系统中,如 Windows、macOS 和 Android,用户可以 在系统设置中选择深色模式。当系统设置为深色模式时,浏览器会根据这个偏好 应用相应的颜色方案。
浏览器支持: 用户使用的浏览器需要支持
prefers-color-scheme媒体查询。大多数现代浏览器,如 Chrome、Firefox、Safari 等,都支持这一特性。
在 Windows 10 系统中设置深色模式的步骤如下:
打开设置应用:
- 点击开始菜单(Start Menu)中的“设置”(Settings)图标,或者使用快捷键
Win + I打开设置应用。进入个性化设置:
- 在设置应用中,点击“个性化”(Personalization)选项。
选择颜色:
- 在个性化设置中,选择左侧菜单中的“颜色”(Colors)选项。
选择深色模式:
- 在颜色设置页面,向下滚动到“选择你的默认应用模式”部分。
- 你可以选择“深色”(Dark)来启用深色模式,或者选择“浅色”(Light)来启用浅色模式。
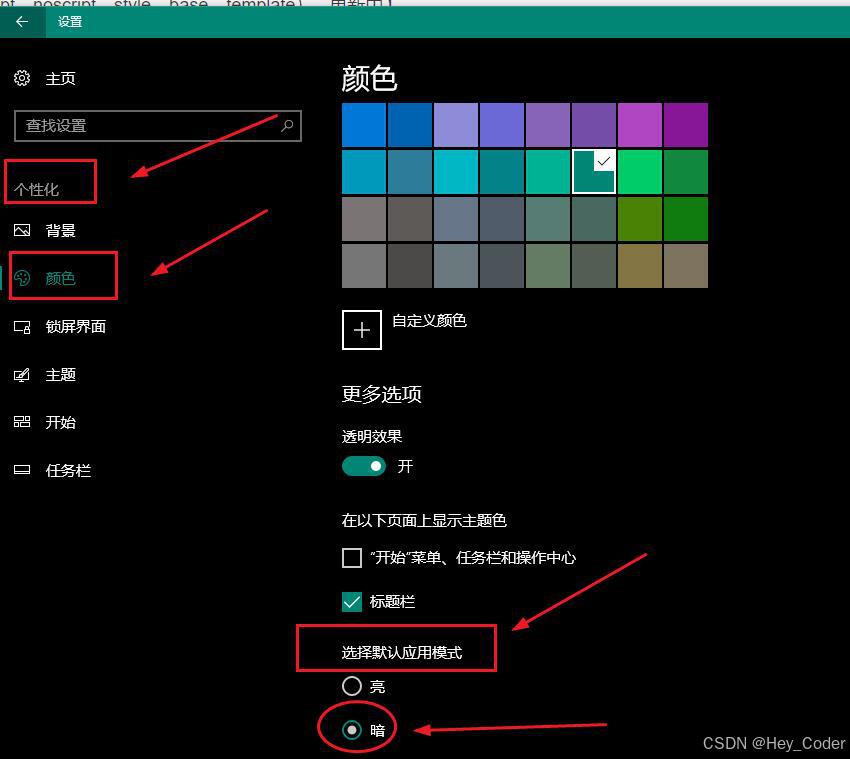
- ④
<meta>标签的name="color-scheme"和 css 的prefers-color-scheme属性,谁的优先级更高?- 例:
<meta>标签的name="color-scheme" content="light"只允许浅色模式,但系统设置为 深色模式,这个时候,页面会用默认颜色、浅色模式颜色、还是深色模式颜色?- 用户的系统偏好设置 优先级更高:浏览器会优先考虑 用户的系统偏好,并触发相应的
prefers-color-scheme媒体查询。即 会应用深色模式的颜色
- 用户的系统偏好设置 优先级更高:浏览器会优先考虑 用户的系统偏好,并触发相应的
- 例:
在决定
meta标签的name="color-scheme"和 CSS 的prefers-color-scheme
媒体查询的优先级时,我们需要理解它们各自的作用和应用场景。
meta标签的name="color-scheme":
- 这个属性用于 指示页面支持的颜色模式,告诉浏览器页面是 偏好深色模式、浅色模式,还是两者都支持。它的值会影响页面的默认颜色模式,但它不是用来 定义特定元素的颜色样式的。
CSS 的
prefers-color-scheme媒体查询:
- 这是一个 CSS 媒体查询,用于检测用户 是否偏好使用深色或浅色主题,并根据这个偏好 来应用不同的CSS样式。它允许开发者为不同的颜色模式 定义不同的样式规则。
在实际应用中,
meta标签的name="color-scheme"属性 定义了页面的默认颜色模式,而 CSS 的prefers-color-scheme媒体查询则允许页面根据用户的系统偏好 来动态调整样式。
如果页面通过meta标签指定了默认颜色模式,但用户的系统偏好设置与此不同,那么浏览器会优先考虑用户的系统偏好,并触发相应的prefers-color-scheme媒体查询。因此,从优先级的角度来看,用户的系统偏好(通过
prefers-color-scheme媒体查询检测到的)具有更高的优先级。meta标签的name="color-scheme"属性定义了页面的默认颜色模式,但如果用户的系统偏好与之冲突,浏览器会忽略meta标签的设置,以用户的偏好为准。简而言之,用户的系统偏好设置优先级更高。
-
⑤ 浏览器的 浅色/深色模式 和 系统设置的 浅色/深色模式 区别。
-
请注意,Chrome 浏览器的颜色模式 只影响 “浏览器的用户界面”,并不会改变 网页内容的颜色方案。
- 例: 谷歌浏览器设置为深色模式,标题栏编程黑灰色;但网页中的内容,使用的系统设置的浅色模式,匹配媒体查询中 自定义的 白色背景,深绿色文本;
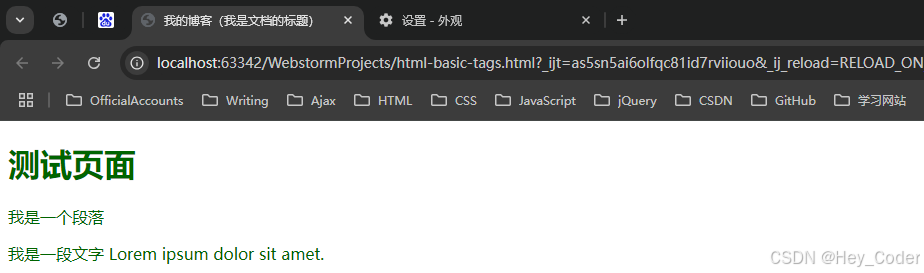
-
网页的颜色模式 通常由以下三个步骤搭配完成
- ❶ 开发者 设置
<meta>标签中的颜色方案:<meta name="color-scheme" content="light">、<meta name="color-scheme" content="dark">或<meta name="color-scheme" content="light dark">等 ; - ❷ 开发者 设置浅色/深色模式的颜色:设置 CSS 中的 媒体查询 首选颜色方案
prefers-color-scheme; - ❸ 用户的 系统设置(不是浏览器设置):把系统设置成 “深色模式”或“浅色模式”,一般都默认是浅色模式;
- ❶ 开发者 设置
-
-
在谷歌浏览器(Google Chrome)中设置深色模式的步骤如下:(浏览器的深色模式只影响 浏览器的外观,系统设置的深色模式 才影响网页)
3.3.2 name 属性值:HTML5 规范之外 惯用的元数据名称
-
HTML5 规范之外 惯用的元数据名称:MetaExtensions - WHATWG Wiki
- 很多规范之外 定义的常用 元数据名称 在 MetaExtensions - WHATWG Wiki 基本上 都能查到;
- 创建和使用 新的元数据名称
- ① 用户可以自定义
<meta>标签的name属性值- 自定义的
<meta>标签的name属性值 可以是任何字符串,浏览器会将其视为 普通的元数据。 - 虽然浏览器并不对自定义的
name属性值进行 特定的处理或识别,但它们可以被 JavaScript 或其他脚本语言 访问和使用。 - 浏览器如何处理自定义
meta标签- 解析和存储:当浏览器解析 HTML 文档时,它会读取所有的
<meta>标签,包括自定义的标签。浏览器将这些标签的name和content属性 存储在 文档对象模型(DOM)中。 - 访问:开发者可以通过 JavaScript 访问这些自定义的 meta 标签。例如,可以使用
document.querySelector或document.getElementsByName方法来获取特定的meta标签。 - 无标准行为:自定义的
name属性值 不会影响浏览器的行为或页面的呈现,除非开发者在脚本中 明确地为这些属性编写了逻辑。因此,使用自定义meta标签的主要目的是为了 存储特定的信息,供后续的脚本或应用程序使用。
- 解析和存储:当浏览器解析 HTML 文档时,它会读取所有的
- 自定义的
- ② 在创建和使用 新的元数据名称之前:建议咨询 WHATWG Wiki MetaExtensions 页面—— 避免选择 已经在使用的元数据名称,避免重复 已经在使用的元数据名称的用途,并避免新的标准化名称 与您选择的名称冲突。(WHATWGWIKI)
- 任何人都可以 随时编辑 WHATWG Wiki MetaExtensions 页面 来添加元数据名称。但不一定都会被通过审核。
- ① 用户可以自定义
-
HTML5 规范之外 惯用的
name属性值 及其用途:- 很多规范之外 定义的常用 元数据名称 在 MetaExtensions - WHATWG Wiki 中可以查到;
- 有很多 规范之外的 惯用元数据名称,此处仅列出常见的几个;
- 很多规范之外 定义的常用 元数据名称 在 MetaExtensions - WHATWG Wiki 中可以查到;
viewport/ˈvjuːpɔːrt/:用于 移动设备 视口设置。
html <meta name="viewport" content="width=device-width, initial-scale=1.0">robots/ˈroʊbɑːts/:告诉搜索引擎爬虫 如何索引页面。
html <meta name="robots" content="index, follow">revisit-after:建议搜索引擎多久后 重新访问页面。
html <meta name="revisit-after" content="7 days">属性值的写法 应该遵循以下规则:
- 大小写不敏感:
name属性值 通常不区分大小写,但为了一致性和最佳实践,推荐使用小写。- 避免特殊字符:
name属性值中 不应包含特殊字符或空格,如果需要,可以使用连字符(-)或下划线(_)。- 明确含义:
name属性值 应该清晰地表明content属性值的含义。总的来说,
meta标签的name属性值 是根据你想要传达的元数据信息来确定的,没有固定的值,但应该遵循 一定的命名惯例和规则。
- 自定义 属性值:有些 自定义的
<meta>标签的name属性值,在 MetaExtensions - WHATWG Wiki 查询不到,浏览器无特别处理,但网站本身可以使用;- 例: 哔哩哔哩、淘宝 网站的自定义 meta 标签的 name 属性值
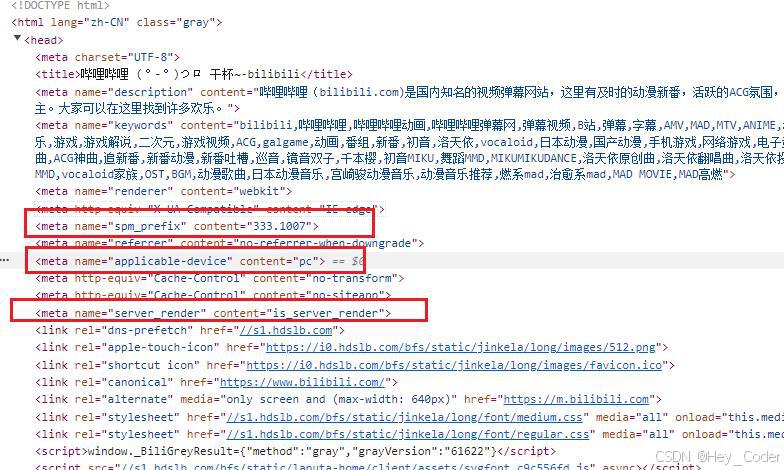
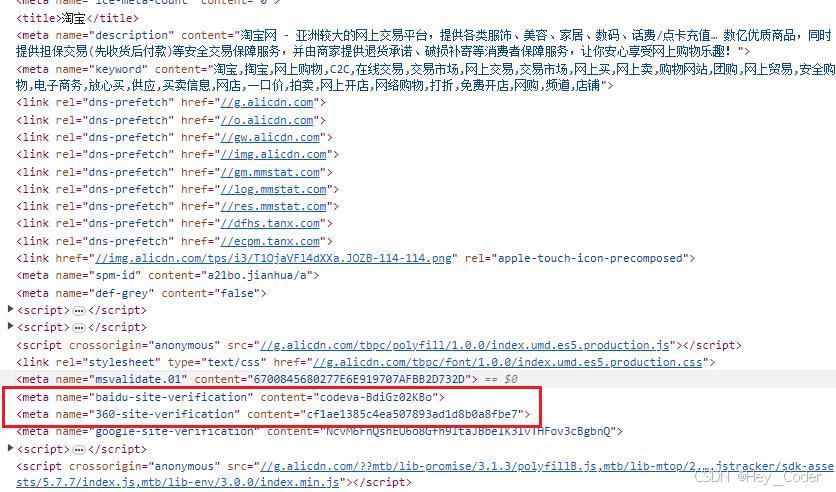
网站验证服务 name=“msvalidate.01” 在 MetaExtensions - WHATWG Wiki 中可以查到;
<meta name="msvalidate.01" content="6700845680277E6E919707AFBB2D732D">
是一个自定义的 HTML 元数据标签,用于提供 特定于搜索引擎或网站验证服务的信息。
在这个例子中,name属性被设置为"msvalidate.01",而content属性包含了一串字符,这串字符是与微软的验证服务 相关的一个密钥或标识符。这种元数据 通常用于网站所有者 向搜索引擎(如必应)证明他们对网站的所有权。
通过在网页的
<head>部分添加这样的meta标签,网站所有者可以验证 他们对特定页面或整个网站的控制权,这有助于管理网站 在搜索引擎结果中的表现,例如修改索引规则、防止内容被缓存等。具体来说,
msvalidate.01可能是 微软验证服务的一个特定版本或标识,而content中的值 是分配给该网站的唯一验证代码。
这样的标签 对于网站管理员来说是有用的,因为它帮助他们 管理网站与搜索引擎之间的交互,但对于最终用户来说,这些信息通常是不可见的,也不会影响页面的正常显示和功能。
⑴ 网页创作者: name=“creator”(技术层面上 作者;非规范元数据名称)
-
meta标签的name="creator"/kriˈeɪtər/ 属性- 用于:指定网页内容的创作者或作者。
- 这个标签可以放在 HTML 文档的
<head>部分,以提供关于文档作者的信息。 - 虽然这个信息对于普通用户可能不可见,但它可以被搜索引擎用来显示作者信息,或者被其他工具和应用程序 用来识别内容的来源。
-
以下是如何使用
meta标签的name="creator"属性的例子:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="creator" content="张三">
<title>Document Title</title>
</head>
<body>
<h1>Welcome to My Website</h1>
<p>This is a paragraph of text on my website.</p>
</body>
</html>
-
在这个例子中,
meta标签的name="creator"属性被设置为content="张三",这意味着网页的作者被标记为“张三”。- 这个信息可以被搜索引擎索引,并可能在搜索结果中 显示作者的名字。
-
请注意,
meta标签的name="creator"属性 并不是所有搜索引擎都会使用,其效果可能因搜索引擎的算法和政策而异。- 此外,随着时间的推移,搜索引擎可能不再支持或不再显示这些信息。因此,使用这个属性主要是为了提供元数据的完整性,而不是为了特定的 SEO 目的。
-
知识拓展:
meta标签的name="creator"和name="author"的区别是什么?
meta标签的name="creator"和name="author"
都可以用来指定 网页内容的创作者或作者,但在语义上和使用习惯上有所不同:
语义上的区别:
name="author":这个属性更通用,用来指定网页内容的作者。它可以直接告诉搜索引擎和读者 谁是内容的创作者。name="creator":这个属性通常用于 指定创作技术内容的人,比如 网页的开发者或设计者。它更多地用于技术层面的识别,尤其是在一些内容管理系统(CMS)中。使用习惯上的区别:
name="author":在SEO(搜索引擎优化)和内容创作中更常见,因为它直接关联到内容的创作者,这对于内容的版权和归属非常重要。name="creator":在技术文档或需要区分内容创作者和技术实现者的情况下使用。例如,在一些项目中,可能有人负责内容创作,有人负责网页设计和开发,这时可以使用creator来指明技术实现者。搜索引擎处理方式:
- 搜索引擎可能对这两个属性的处理方式不同。有些搜索引擎可能更重视
author属性,因为它直接关联到 内容的版权和创作者。而creator属性可能被用来识别技术实现者,这在某些情况下对于搜索引擎理解网页的技术结构是有帮助的。兼容性:
- 在 HTML5 规范中,
meta标签的name="author"属性是明确定义的,而name="creator"属性并不是 HTML5 规范的一部分。因此,从规范的角度来看,author属性更受推荐。总的来说,
name="author"更多用于内容创作者的标识,而name="creator"可能用于更技术层面的创作者标识。在实际应用中,选择使用哪个属性取决于你的具体需求和目标。如果你的目标是明确标识内容的创作者,使用name="author"可能更合适;如果你需要区分技术实现者,可以考虑使用name="creator"。
⑵ 谷歌 索引爬虫: name=“googlebot” (指明 谷歌爬虫如何处理内容)
-
meta标签的name="googlebot"属性是name="robots"属性值的一个替代名称,它专门被 Googlebot(Google 的网页爬虫 crawler /'krɔlɚ/索引搜寻器)使用。- 这个属性允许你:指定 Googlebot 如何索引你的网页。以下是如何使用
meta标签的name="googlebot"属性的例子:
- 这个属性允许你:指定 Googlebot 如何索引你的网页。以下是如何使用
-
例: 允许 Googlebot 索引并跟随链接:
<meta name="googlebot" content="index, follow">- 这表示允许 Googlebot 索引该页面,并跟随页面上的链接。
-
例: 不允许 Googlebot 索引但允许跟随链接:
<meta name="googlebot" content="noindex, follow">- 这表示不允许 Googlebot 索引该页面,但允许它跟随页面上的链接。
-
例: 不允许 Googlebot 索引且不跟随链接:
<meta name="googlebot" content="noindex, nofollow">- 这表示不允许 Googlebot 索引该页面,也不让它跟随页面上的链接。
-
例: 不允许 Googlebot 存档页面:
- archive:/ˈɑːrkaɪv/,把…存档
<meta name="googlebot" content="noarchive">- 这表示要求 Google 不缓存页面内容。
-
请注意,
name="googlebot"属性值的使用 应遵循搜索引擎优化的最佳实践,以确保你的网页 能够按照你的意图被 Googlebot 正确处理。这些设置 对于控制网页 在搜索引擎中的表现 非常重要。
- 知识拓展:搜索引擎爬虫是什么?
- 搜索引擎爬虫(Search Engine Crawler/ˈkrɔːlər/),也称为 网页爬虫(Web Crawler)、蜘蛛(Spider)或 机器人(Bot),是一种 自动化的软件程序,搜索引擎 用来自动浏览互联网 并收集网页信息的程序。其主要任务是 浏览互联网上的网页,并收集信息 以供搜索引擎 索引和存储。
- 它的主要任务是:发现新的或更新的网页,并将这些网页的内容、链接等信息 存储到搜索引擎的数据库中。这个过程称为索引(indexing)。
- 索引页面:意味着 将网页的内容和元数据 存储到搜索引擎的索引数据库中,以便用户在搜索时 能够快速检索到。
- 搜索引擎爬虫的工作是 搜索引擎运作的核心部分,它们帮助搜索引擎 了解和跟踪 互联网上存在的网页内容。
① 搜索引擎爬虫的 一些主要特点和功能:
网页抓取:
- 爬虫访问网站,下载网页内容,包括文本、图片、视频等。
链接跟踪:
- 爬虫通过网页上的超链接 发现和访问更多的网页。
内容分析:
- 爬虫分析网页内容,提取关键词、元数据和其他相关信息。
索引构建:
- 爬虫将收集的数据 发送回搜索引擎的服务器,用于构建或更新索引数据库。
更新频率:
- 爬虫定期重新访问 已索引的网页,以检测和更新网页内容的变化。
遵守规则:
- 爬虫遵循网站提供的
robots.txt文件中的规则,该文件指示爬虫 哪些页面可以访问,哪些页面应该避免。处理动态内容:
- 一些爬虫能够处理 JavaScript 和其他客户端脚本生成的动态内容。
用户体验优化:
- 搜索引擎爬虫的优化和改进 旨在提供更快、更相关的搜索结果,从而提升用户体验。
搜索引擎爬虫 对于维护互联网信息的可访问性和最新性 至关重要。它们确保搜索引擎 能够提供最新的信息,并帮助用户找到他们需要的内容。不同的搜索引擎,如 Google、Bing 和 Baidu,都有自己的爬虫程序 来抓取和索引网页。
② 搜索引擎爬虫 索引页面的一个简单例子:
发现网页:搜索引擎爬虫开始于一个或多个已知的网页(种子URL),然后通过这些网页上的链接发现更多的网页。
抓取内容:爬虫访问这些网页,下载网页的 HTML 内容。
解析内容:爬虫解析 HTML 内容,提取出文本、链接、图片、视频等信息。
建立索引:爬虫将提取的信息存储到搜索引擎的数据库中。这个过程包括对网页内容进行处理,比如去除停用词(如“的”、“是”等常见的、对搜索结果帮助不大的词),计算词频等。
用户搜索:当用户在搜索引擎中输入查询词时,搜索引擎会检索其索引数据库,找到包含这些查询词的网页,并根据一定的算法(如PageRank)对结果进行排序,然后展示给用户。
举例说明:
假设你有一个个人博客网站,你发布了一篇新的文章。为了让这篇文章能够被搜索引擎发现,你需要:
提交网址:你可以手动将你的博客网址提交给搜索引擎,或者通过搜索引擎提供的站长工具提交。
爬虫访问:搜索引擎的爬虫会访问你的网站,抓取你的文章页面。
内容解析:爬虫解析你的文章内容,提取出标题、正文、关键词等信息。
建立索引:爬虫将这些信息 存储到搜索引擎的数据库中。
用户搜索:当用户在搜索引擎中搜索与你文章相关的关键词时,搜索引擎会从其索引中找到你的网页,并将其显示在搜索结果中。
这个过程就是 搜索引擎爬虫索引页面的大致流程。通过索引,搜索引擎能够 快速响应用户的查询请求,提供相关的搜索结果。
③ 搜索引擎爬虫 跟随页面链接是什么意思?
搜索引擎爬虫 跟随页面链接 是指爬虫在访问一个网页后,会识别并跟踪 该网页上的超链接,然后访问这些链接指向的其他页面。这个过程允许爬虫 从一个页面开始,逐步探索和索引整个网站或互联网上的多个页面。
以下是这个过程的一个例子:
起始页面:假设搜索引擎爬虫从网站首页(例如:
https://www.example.com)开始。识别链接:爬虫访问首页后,会解析 HTML 代码,识别页面上的所有超链接(
<a>标签)。这些链接可能指向网站内部的其他页面,也可能指向外部网站。跟踪链接:爬虫会根据一定的规则(比如 链接的相关性、权重等)决定哪些链接是值得跟踪的。然后,爬虫会访问这些链接指向的页面。
重复过程:对于每一个新访问的页面,爬虫都会重复上述过程,解析页面内容并跟踪页面上的新链接。这样,爬虫可以不断地从一个页面跳转到另一个页面,逐步构建起对整个网站或互联网的索引。
深度和广度:爬虫可以被设置为优先深度爬取(深入跟踪一个链接的子链接)或广度爬取(先访问当前页面的所有链接,再逐级深入)。
举例说明:
假设我们有一个新闻网站,爬虫从首页开始,识别出所有新闻文章的链接。然后,爬虫会访问每篇新闻文章的页面,从每篇文章页面,它又可以识别出评论链接、作者页面链接、相关新闻链接等。爬虫会根据预设的规则(例如,只跟踪新闻相关页面),决定哪些链接是重要的,并继续跟踪这些链接。通过这种方式,爬虫可以构建起对整个新闻网站的索引,包括所有新闻文章、评论和其他相关内容。
④ 搜索引擎爬虫 存档页面是什么意思?
搜索引擎爬虫存档页面 通常指的是 爬虫在访问和抓取网页内容时,将这些 网页保存 到搜索引擎的数据库中,以便用户在进行搜索查询时 能够检索到这些页面。这个过程类似于 图书馆中的图书归档,网页被“存档”以便将来检索。
以下是这个过程的一个例子:
假设有一个新闻网站,每天都会发布新的新闻文章。搜索引擎爬虫会定期访问这个网站,抓取新发布的新闻页面。这些页面的内容和元数据(如标题、发布日期等)被存储在搜索引擎的数据库中,这个过程就是存档页面。举例说明:
新闻发布:一个新闻网站发布了一篇关于重大事件的报道,网页地址是
https://www.news.com/event报道。爬虫访问:搜索引擎爬虫检测到这个新页面(可能是 通过网站地图、RSS 订阅或其他方式),然后访问这个页面。
内容抓取:爬虫读取页面的 HTML 内容,并提取出重要的信息,如 文章标题、正文、发布时间等。
存档页面:提取的信息 被存储在搜索引擎的数据库中,这个过程就是存档页面。这样,当用户搜索与这篇报道相关的关键词时,搜索引擎可以快速地从数据库中 检索到这篇报道,并将其显示在搜索结果中。
用户搜索:几天后,用户在搜索引擎中搜索与该事件相关的关键词,搜索引擎从其存档的页面中 检索到这篇报道,并将其展示在搜索结果中。
通过这种方式,搜索引擎 能够为用户提供最新的、相关的信息,即使原始网页 可能已经更新或更改了内容。
存档页面确保了即使原始内容发生变化,用户仍然能够通过搜索引擎访问到他们需要的信息。
⑤ 搜索引擎爬虫“存档页面”和“索引页面”的区别是什么?
搜索引擎爬虫的存档页面和索引页面是两个相关但不同的概念:
存档页面:
- 含义:存档页面 通常指的是 搜索引擎将 网页的快照保存 在其服务器上,以便在原始网页不可用 或发生变化时,用户仍然可以 查看网页的原始内容或历史版本。
- 目的:存档的主要目的是为了 提供网页的历史记录,允许用户查看 网页在特定时间点的状态,这在原始网页被删除或更新后尤其有用。
- 用户访问:用户可以通过搜索引擎的“网页快照”或“缓存”链接 访问存档页面。
索引页面:
- 含义:索引页面 指的是搜索引擎 将网页的内容、元数据和结构化数据等信息 存储在其数据库中,以便快速响应用户的搜索查询。
- 目的:索引的主要目的是 为了提高搜索效率和相关性,确保用户能够 快速找到最相关的搜索结果。
- 用户访问:用户在搜索结果中 看到的链接和摘要 就是基于索引页面的信息,点击这些链接 会直接访问原始网页。
区别:
- 存储内容:存档页面存储的是 网页的完整快照,包括 HTML、CSS 和 JavaScript 等,而索引页面存储的是 网页的文本内容、链接、元数据等信息。
- 访问方式:存档页面 通常通过搜索引擎提供的 特定链接访问,而索引页面 是通过 搜索结果列表中的链接 直接访问原始网页。
- 更新频率:索引页面会根据爬虫的抓取频率 定期更新,以反映网页的最新内容,而存档页面一旦创建,通常不会频繁更新,除非网页有重大变化。
- 功能重点:索引页面更侧重于 提高搜索效率和结果的相关性,而存档页面更侧重于 保存网页的历史状态。
简而言之,存档页面是 网页的历史快照,而索引页面 是搜索引擎用于 快速检索和提供搜索结果的 数据库记录。两者共同支持搜索引擎的功能,但各自扮演不同的角色。
⑶ 指定爬虫行为:name=“robots” (索引、跟踪页面链接、缓存页面)
meta标签的name="robots"属性值-
用于:告诉搜索引擎爬虫 如何对待当前页面的内容。
-
这个属性值 搭配的
content值 可以包含多个指令,这些指令告诉搜索引擎 是应该索引页面、跟随链接、存档页面还是执行其他操作。- /ˈroʊbɑːts/
-
<meta name="robots">搭配的content的属性值- 它是一个 以逗号分隔的 列表,其中的值 取自以下列表:
-
| 属性值 | 描述 | 用于 |
|---|---|---|
| index/ˈɪndeks/ | 允许 索引;允许搜索引擎 索引该页面(默认行为); 表示允许搜索引擎 将当前网页的内容 收录到索引中,使其能够在“搜索结果”中显示。 | All;所有爬虫; |
| noindex | 阻止 索引;禁止搜索引擎索引该页面; 禁止搜索引擎 将当前网页的内容 收录到索引中。也就是说,当前网页 不会出现在搜索引擎的搜索结果中。 | All;所有爬虫; |
| follow/ˈfɑːloʊ/ | 允许 跟踪 链接;允许搜索引擎 跟随页面上的链接(默认行为); 表示允许搜索引擎爬虫 跟随当前页面上的链接,进一步爬取其他页面。 | All;所有爬虫; |
| nofollow | 阻止 跟踪 ; 阻止爬虫 跟踪页面上的链接 ; 禁止搜索引擎爬虫 跟随当前网页上的任何链接。也就是说,爬虫 不会通过当前网页的链接 去访问其他页面。 | All;所有爬虫; |
| all | 与 “ index, follow” 等价;允许索引和跟踪页面链接; | |
| none | 与 “noindex, nofollow” 等价 ;不允许索引和跟踪页面链接; | |
| noarchive | 要求搜索引擎 不缓存页面内容; 告诉搜索引擎 不要缓存当前网页的内容。这意味着 搜索引擎不会保存“该页面的快照”,用户无法通过搜索引擎的缓存功能 查看该页面的旧版本。 | Google、Yahoo、Bing |
| nosnippet | 不在搜索引擎的结果中 显示该网页的任何描述; | Google、Bing |
| noimageindex | 告诉搜索引擎 不要索引该网页中的图片。 | |
| nocache | noarchive 的替代名称。要求搜索引擎 不缓存页面内容; | Bing |
| noodp | 防止使用 打开目录项目描述(如果有的话) 作为 搜索引擎结果页面中的 页面描述 ; 开放目录项目(Open Directory Project,简称 ODP;ODP 是一个网络目录,它为搜索引擎提供了网页的描述。当网站管理员不希望搜索引擎使用这些外部来源的描述,而是希望使用自己提供的 meta 标签描述时,就可以使用 noodp 指令。 | Google, Yahoo, Bing |
| noydir | 防止使用 Yahoo 目录描述(如果有的话)作为 搜索引擎结果页面中的 页面描述; | Yahoo |
备注:只有正规的爬虫/ 协作搜寻器/ 机器人 遵守这些规则。恶意爬虫不会也这么做。
- 只有访问相应的页面之后,机器人才能读取到这些规则。 为避免这一点带来的带宽消耗,可以在 robots.txt 文件中声明一些规则。
- 如果你想从机器人的索引中 移除某个页面:
noindex可以做到这一点,但机器人还是得先访问那个页面,读取到noindex
规则。遇到这种情况时,请确保 robots.txt 文件没有阻止机器人 重新访问那个页面。- 一些规则是互相矛盾的:比如 index 和 noindex,或者 follow 和 nofollow。这种情况下,机器人的表现是不可预测的,而且不同机器人的表现可能有不同。
- 一些爬虫机器人,比如 Google、Yahoo 和 Bing 的搜索引擎爬虫,支持在 HTTP
X-Robots-Tag请求头中应用相同的规则。
这允许非 HTML 文档和文件等应用这些规则。
开放目录项目(Open Directory Project,简称 ODP)是一个由志愿者编辑和维护的 网络分类目录,它允许用户提交网站,并通过人工审核来收录网站。ODP 的目标是创建一个全面、准确的 网站分类目录,以帮助用户找到他们需要的信息。
什么是开放目录项目(ODP)?
- 人工编辑:与自动生成的搜索引擎索引不同,ODP 依赖于志愿者编辑对网站进行分类和描述,以确保目录的准确性和相关性。
- 免费资源:ODP 是一个免费资源,任何人都可以访问和使用其目录数据,无需支付费用。
- 广泛使用:ODP 的数据被许多搜索引擎和门户网站使用,如 Google、Netscape、AOL 等,作为搜索结果的一部分。
- 社区驱动:ODP 鼓励社区参与,任何人都可以申请成为编辑,帮助维护和扩展目录。
什么情况下需要使用 ODP?
网站推广:如果你拥有一个网站,希望提高其在线可见性,可以通过向ODP提交你的网站来增加曝光度。被ODP收录可以提高网站的权威性和搜索引擎排名。
搜索引擎优化(SEO):ODP 可以作为 SEO 策略的一部分,因为它有助于提高网站的反向链接和信誉。
信息检索:用户在寻找特定主题或类别的网站时,可以使用 ODP 作为一个分类目录,快速找到相关资源。
研究和教育:研究人员、学生和教育工作者可以使用 ODP 来找到特定领域的权威网站和资源。
网站审核和质量控制:ODP 的人工审核过程确保了目录中的网站具有一定的质量标准,这对于需要高质量信息的用户来说是一个重要的参考。
社区参与:如果你对互联网社区有热情,并希望为维护和扩展网络资源做出贡献,可以申请成为 ODP 的编辑。
总的来说,ODP 是一个有助于提高网站可见性、促进信息检索和社区参与的重要工具。
ODP(Open Directory Project)的官方网址 。不过,需要注意的是,DMOZ 在 2017 年已经停止了服务,所以这个网址已经不再活跃。尽管如此,DMOZ 的精神和部分数据被其他项目如 ODP Archive 等所继承。
例: 索引和跟随链接
index,follow:允许搜索引擎索引页面并跟随页面上的链接。
html <meta name="robots" content="index,follow">例:不索引但跟随链接
noindex,follow:不允许搜索引擎索引页面,但允许搜索引擎跟随页面上的链接。
html <meta name="robots" content="noindex,follow">例:不索引也不跟随链接
noindex,nofollow:不允许搜索引擎索引页面,也不跟随页面上的链接。
html <meta name="robots" content="noindex,nofollow">例:不存档
noarchive:要求搜索引擎不存档页面,即不在搜索结果中显示“缓存”链接。
html <meta name="robots" content="noarchive">例: 不显示摘要
nosnippet:要求搜索引擎不在搜索结果中 显示页面的摘要。
html <meta name="robots" content="nosnippet">例: 不索引图片
noimageindex:要求搜索引擎不将页面上的图片 索引到其图片搜索中。
html <meta name="robots" content="noimageindex">例: 不允许翻译
notranslate:要求搜索引擎不要将页面内容翻译成其他语言。
html <meta name="robots" content="notranslate">例:不允许 开放目录项目 作为 页面摘要
noodp:要求搜索引擎不使用开放目录项目(ODP)的描述作为页面的摘要。
html <meta name="robots" content="noodp">例:指令可以根据页面的特定需求 进行组合使用
- 例,如果你希望搜索引擎索引页面 但不希望它跟随页面上的链接,你可以使用:
html <meta name="robots" content="index,nofollow">请记住,这些指令应该放在 HTML 文档的
<head>部分中。搜索引擎爬虫会根据这些指令 来决定如何对待页面内容。例: 告诉搜索引擎不要在搜索结果中 显示该页面的摘要(snippet)。
- 通常,搜索引擎会在搜索结果中 显示一个网页的标题和一段简短的描述(摘要),帮助用户了解网页内容。如果网页使用了
nosnippet指令,搜索引擎就不会显示这段描述,只显示网页的标题。使用
nosnippet指令的 HTML 代码示例如下:
- 这行代码应该放在网页的
<head>部分中。
html <meta name="robots" content="nosnippet">这个指令的用途包括:
保护版权内容:如果网页内容是版权保护的,网站管理员可能不希望搜索引擎显示过多的内容摘要,以免侵犯版权。
避免内容误解:如果网页内容容易被误解或者断章取义,使用
nosnippet可以防止搜索引擎显示不完整的信息。保护隐私:对于包含敏感信息的页面,使用
nosnippet可以减少信息泄露的风险。提高点击率:有些网站管理员认为,不显示摘要可以增加用户点击链接的可能性,因为用户对页面内容的好奇心可能会驱使他们点击。
统一品牌形象:对于品牌形象严格的公司,他们可能希望用户点击链接后直接访问网站,而不是通过搜索引擎的摘要了解内容。
⑷ 雅虎 yahoo 爬虫行为: name=“slurp” ( 仅用于 Yahoo Search 雅虎搜索引擎)
- 同上一个 爬虫程序行为: meta-
name="slurp";- 与
robots一样, 但其 仅使用于Slurp -- Yahoo Search的抓取工具。 - slurp :美 /slɜːrp/;
- 与
meta标签的name="slurp"属性值- 用于:是特定于 Yahoo! 搜索引擎爬虫的指令,用于告诉 Yahoo! 的爬虫(名为 Slurp)如何对待页面内容。
- 这个属性搭配的
content属性值 可以包含多个指令,这些指令告诉爬虫是应该索引页面、跟随链接、存档页面还是执行其他操作。以下是一些常用的指令和它们的组合示例:
索引和跟随链接:
index,follow:允许搜索引擎索引页面并跟随页面上的链接。
html <meta name="slurp" content="index,follow">不索引但跟随链接:
noindex,follow:不允许搜索引擎索引页面,但允许搜索引擎跟随页面上的链接。
html <meta name="slurp" content="noindex,follow">不索引也不跟随链接:
noindex,nofollow:不允许搜索引擎索引页面,也不跟随页面上的链接。
html <meta name="slurp" content="noindex,nofollow">不存档:
noarchive:要求搜索引擎不存档页面,即不在搜索结果中显示“缓存”链接。
html <meta name="slurp" content="noarchive">不显示摘要:
nosnippet:要求搜索引擎不在搜索结果中显示页面的摘要。
html <meta name="slurp" content="nosnippet">不索引图片:
noimageindex:要求搜索引擎不将页面上的图片索引到其图片搜索中。
html <meta name="slurp" content="noimageindex">不允许翻译:
notranslate:要求搜索引擎不要将页面内容翻译成其他语言。
html <meta name="slurp" content="notranslate">不允许使用ODP描述:
noodp:要求搜索引擎不使用开放目录项目(ODP)的描述 作为页面的摘要。
html <meta name="slurp" content="noodp">这些指令可以根据页面的特定需求进行组合使用。例如,如果你希望搜索引擎索引页面 但不希望它跟随页面上的链接,你可以使用:
html <meta name="slurp" content="index,nofollow">请记住,这些指令应该放在HTML文档的
<head>部分中。Yahoo! 的爬虫 会根据这些指令来决定如何对待页面内容。
⑸ 窗口宽高 和缩放比例: name=“viewport” (视口的宽度、高度、缩放比例、用户缩放)
-
meta标签的name="viewport"属性值- 用于:控制移动设备上的视口(viewport)设置,以确保网页 能够正确地在不同设备上显示。
- 这个标签对于“响应式网页设计” 非常重要,因为它可以影响 网页的布局和渲染方式。
-
<meta name="viewport">搭配的content属性值
| Value | 可能值 | 描述 |
|---|---|---|
① 视口的宽度:width/wɪdθ/ | 一个 正整数 或 字符串 device-width ;通常设置为 device-width 以匹配 设备的屏幕宽度。 | 宽度: 以 pixels(像素)为单位, 定义 viewport/ˈvjuːpɔːrt/(视口)的宽度。 |
② 视口的高度: height/haɪt/ | 一个 正整数 或 字符串 device-height;通常设置为 device-height 以匹配 设备的屏幕高度,但较少使用。 | 高度: 以 pixels(像素)为单位, 定义 viewport(视口)的高度。 |
③ 初始缩放比例: initial-scale/ɪˈnɪʃ(ə)l/,/skeɪl/ | 一个 0.0 到10.0之间的正数 | 缩放比例:设置了 页面的 初始显示比例;定义 设备宽度(纵向模式下的设备宽度 或横向模式下的设备高度)与视口大小之间的 初始缩放比率。 定义设备宽度(宽度和高度中更小的那个:如果是纵向屏幕,就是设备宽度 device-width,如果是横向屏幕,就是设备高度 device-height)与 视口大小之间的 初始缩放比例。 |
④ 最大缩放比例:maximum-scale/ˈmæksɪməm/ | 一个 0.0 到10.0之间的正数 | 最大缩放比例: 设置用户能够缩放到的最大比例,定义缩放的最大值; 它必须 大于或等于 最小缩放比例 minimum-scale的值,不然会导致不确定的行为发生。 |
⑤ 最小缩放比例: minimum-scale/ˈmɪnɪməm/ | 一个 0.0 到10.0之间的正数 | 最小缩放比例: 设置用户能够缩放到的最小比例,定义缩放的最小值; 它必须 小于或等于 最大缩放比例 maximum-scale的值,不然会导致不确定的行为发生。 |
⑥ 用户缩放: user-scalable/ˈskeɪləbl/ | 一个布尔值(yes 或者 no) | 用户 手动缩放: 设置是否 允许用户缩放;如果设置为 no,用户将 不能放大或缩小网页。默认值为 yes。缩放和使用: 通过将user-scalable设置为 no来 禁用缩放 功能,会妨碍 视力低下的人 阅读和理解页面内容。 |
⑦ 视口适应大小:viewport-fit | auto、contain 或者 cover | ❶ auto 值不会影响初始布局视口,整个网页都是可见的,但特殊区域可能会裁剪内容。❷ contain 值意味着视口被缩放 以适合显示内的最大矩形。完整显示,但特殊区域附近 可能留白;❸ cover 值 意味着视口被缩放 以填充设备显示。全屏显示,但特殊区域 可能遮挡内容;它确保网页内容能够覆盖整个屏幕,包括设备的特殊区域(如刘海、圆角等)。 建议使用 安全区域嵌入变量 safe-area-inset-*,来避免遮挡,以确保重要的内容 不会出现在显示之外 而导致看不见。safe-area-inset 浏览器支持 ;如 设置 viewport-fit=cover 后,网页内容会全屏显示,但可能会被特殊区域遮挡一部分。开发者可以通过 CSS 的 env() 函数(如 padding-top: env(safe-area-inset-top))来调整内容,避免被遮挡。 |
例: 基本的视口设置:
- 这个设置 告诉浏览器将视口宽度设置为 设备的屏幕宽度,并设置初始缩放比例为1.0(即不缩放)。
html <meta name="viewport" content="width=device-width, initial-scale=1.0">例: 禁止用户缩放:
- 这个设置 禁止用户对页面进行缩放。
html <meta name="viewport" content="width=device-width, user-scalable=no">例: 设置最大和最小缩放比例:
- 这个设置限制了页面的缩放比例,使得页面只能以初始比例显示,用户不能放大或缩小。
html <meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0, user-scalable=no">例: 响应式设计:
这个设置中的
viewport-fit=cover是一个较新的属性,用于控制视口 如何适应设备屏幕,特别是在有刘海或凹槽的设备上。
html <meta name="viewport" content="width=device-width, initial-scale=1.0, viewport-fit=cover">请记住,
meta标签的name="viewport"属性 应该放在HTML文档的<head>部分中,以确保在页面加载时 这些设置能够生效。这些设置 对于确保网页在不同设备上的正确显示和操作至关重要。
-
例: MDN 网站 使用的 窗口、机器人爬虫
-
name="viewport"viewport是一个特殊的元标签名称,用于定义网页在不同设备上的视口(viewport)设置。- 视口:是指 浏览器窗口的 可视区域,它决定了网页内容的显示范围和缩放比例。
-
❶
width=device-width:这告诉浏览器将视口的宽度设置为设备的屏幕宽度。- 这意味着网页的宽度会适配设备的屏幕宽度,不会超出屏幕边界。
- 这个参数告诉浏览器将网页的宽度设置为 设备的屏幕宽度。换句话说,网页的布局宽度 会根据设备的屏幕宽度自动调整,从而实现响应式设计。
- 例如,如果用户在手机上访问网页,
device-width通常是手机屏幕的宽度(如360px或375px);如果在平板或电脑上访问,device-width则是相应设备的屏幕宽度。
-
❷
initial-scale=1:这设置了页面加载时的 初始缩放比例为 1,即页面以 100% 的比例显示,没有缩放。initial-scale=1表示页面加载时 不会自动缩放,而是以 1:1 的比例显示内容。- 如果设置为其他值(如
initial-scale=0.5),页面会以50%的比例显示,可能会导致内容看起来过小。 - 这个值也可以设置为其他数值,比如
initial-scale=1.5表示页面加载时 以 150% 的比例显示。 - 至于用户能否缩放页面,
initial-scale=1并没有直接限制用户的缩放行为。initial-scale=1只是设置了页面的初始显示比例,用户仍然可以通过手势(如 双指缩放)来放大或缩小页面。
-
❸
content="index, follow"允许 爬虫 索引页面, 允许 爬虫 跟踪页面上的链接;
-
-
作用
- 响应式设计:通过设置
width=device-width,网页能够根据设备屏幕宽度调整布局,确保在不同设备上都能良好显示。 - 避免缩放问题:
initial-scale=1确保页面加载时以正常比例显示,避免用户需要手动缩放才能查看内容。 - 提升用户体验:让网页在移动设备上显示更加清晰、自然,避免内容过大或过小,提升用户的浏览体验。
- 响应式设计:通过设置
如果你想要限制用户缩放,需要添加
user-scalable=no属性,如下所示:
html <meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no">这样设置后,用户将无法缩放页面,页面会 始终 以初始设置的比例显示。但请注意,这种限制可能会影响用户体验,因为用户在需要时 无法放大页面 以更好地阅读内容。
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="robots" content="index, follow">

- 知识拓展:屏幕的“安全区域” 是什么意思?
- 在网页设计和开发中,“安全区域”(Safe Area) 是一个重要的概念,特别是在涉及到现代移动设备的屏幕显示时。
- 安全区域是指:设备屏幕中可以安全显示内容的区域,不包括设备的 特殊设计部分(如刘海、圆角、底部导航栏等 特殊区域)。
❶ 安全区域的背景
- 现代移动设备(如iPhone X及后续型号、许多Android设备)通常有一些特殊的屏幕设计,例如:
- 刘海(Notch):屏幕顶部的缺口,用于放置摄像头、传感器等。
- 圆角屏幕(Rounded Corners):屏幕的四个角是圆弧形的。
- 底部导航栏(Home Bar):屏幕底部的虚拟按钮或手势区域。
- 这些设计使得屏幕的某些部分 不适合显示内容,或者显示内容 可能会被遮挡。因此,设备制造商定义了“安全区域”,以帮助开发者和设计师避免内容被这些特殊区域遮挡。
❷ 安全区域的作用
- 安全区域的作用:是确保网页或应用的内容 在设备屏幕上能够完整显示,同时避免被以下部分遮挡:
- 刘海(Notch):屏幕顶部的缺口。
- 圆角(Rounded Corners):屏幕的圆弧形边缘。
- 底部导航栏(Home Bar):屏幕底部的虚拟按钮或手势区域。
❸ 安全区域的范围
- 安全区域通常是一个矩形区域,位于屏幕的中间部分,避开上述 特殊区域。例如:
- 在带有刘海的设备上,安全区域会避开 屏幕顶部的缺口。
- 在带有圆角屏幕的设备上,安全区域会避开 屏幕的圆弧边缘。
- 在带有底部导航栏的设备上,安全区域会避开 屏幕底部的虚拟按钮区域。
❹ 如何使用安全区域
- 在网页设计中,可以通过CSS的
env()函数(环境变量)来适配安全区域。常见的环境变量包括:safe-area-inset-top:屏幕顶部安全区域的内边距。safe-area-inset-right:屏幕右侧安全区域的内边距。safe-area-inset-bottom:屏幕底部安全区域的内边距。safe-area-inset-left:屏幕左侧安全区域的内边距。❺ 使用说明
env(safe-area-inset-top):为内容添加顶部内边距,避免被刘海遮挡。env(safe-area-inset-bottom):为内容添加底部内边距,避免被底部导航栏遮挡。env(safe-area-inset-left)和env(safe-area-inset-right):为内容添加左右内边距,避免被圆角屏幕遮挡。❻ 安全区域的重要性
- 提升用户体验:确保网页内容不会被设备的特殊区域遮挡,用户可以完整地查看和交互。
- 适配多种设备:现代设备屏幕设计多样,安全区域帮助开发者统一适配这些设备。
- 避免内容裁剪:通过适配安全区域,可以避免内容被裁剪或显示不完整。
总结
- 安全区域是设备屏幕中 适合显示内容的区域,避开刘海、圆角和底部导航栏等 特殊部分。通过 CSS 的
env()函数,开发者可以轻松适配这些区域,确保网页内容在不同设备上都能完整显示且不被遮挡。
- 【
meta标签name="viewport"时,content属性值viewport-fit=auto,viewport-fit=contain,viewport-fit=cover有什么区别?】viewport-fit是一个用于控制 网页内容 如何适配设备屏幕的属性,特别是在有特殊区域(如刘海、圆角屏幕、底部导航栏等)的设备上。它有三个主要的值:auto、contain和cover。以下是它们的区别:
- ①
viewport-fit=auto(不全屏、不遮挡、但可能裁剪)-
行为:这是默认值。当设置为
auto时,浏览器会根据设备的安全区域(safe areas)自动调整视口大小,确保网页内容不会被特殊区域遮挡。 -
效果:网页内容会被裁剪以适应安全区域,可能会导致内容显示不完整,但不会被遮挡。
-
适用场景:适用于不需要全屏显示的网页,或者开发者不希望内容被特殊区域遮挡的场景。
-
示例:
- 在带有刘海的设备上,网页内容会被裁剪,以确保内容不会被刘海遮挡。
-
- ②
viewport-fit=contain(完整显示 但留白)-
行为:视口会调整大小以适应安全区域,但不会覆盖特殊区域。网页内容会被完整显示,但可能会在安全区域外留下空白区域。
-
效果:内容不会被裁剪,但可能会在屏幕边缘(如刘海或底部导航栏)周围出现空白区域。
-
适用场景:适用于需要完整显示内容,但不介意屏幕边缘有空白的网页。
-
示例:
- 在带有刘海的设备上,网页内容会完整显示,但刘海区域下方可能会出现空白。
-
- ③
viewport-fit=cover(全屏显示、可能遮挡,搭配 css 的env()函数 去遮挡)-
行为:视口会覆盖整个屏幕,包括特殊区域。网页内容会完整覆盖屏幕,但可能会被特殊区域遮挡一部分。
-
效果:内容会完整显示,但可能会被特殊区域(如刘海、底部导航栏)遮挡一部分。
-
适用场景:适用于需要全屏显示内容的网页,如登录页面、全屏视频播放器等。开发者可以通过CSS的
env()函数(如padding-top: env(safe-area-inset-top))来调整内容布局,避免被遮挡。 -
示例:
- 在带有刘海的设备上,网页内容会完整覆盖屏幕,但可能会被刘海遮挡一部分。开发者可以通过 CSS 调整内容布局来避免遮挡。
-
- 总结
| 设置 | 内容是否被裁剪 | 内容是否被遮挡 | 是否覆盖 非安全区域 | 适用场景 |
|---|---|---|---|---|
viewport-fit=auto | 是(可能裁剪) | 否 | 否 | 不需要全屏显示的网页 |
viewport-fit=contain | 否 | 否 | 否 | 需要完整显示内容,不介意空白 |
viewport-fit=cover | 否 | 是(可能遮挡) | 是 | 需要全屏显示内容的网页 |
-
使用推荐
- 如果你需要网页内容完整显示 且不被遮挡,但不介意屏幕边缘有空白,可以使用
viewport-fit=contain。 - 如果你需要网页内容完整覆盖屏幕(如全屏页面),可以使用
viewport-fit=cover,并结合 CSS 的env()函数调整布局。 - 如果你不需要特别处理特殊区域,可以使用默认的
viewport-fit=auto。
- 如果你需要网页内容完整显示 且不被遮挡,但不介意屏幕边缘有空白,可以使用
-
viewport-fit=cover应用场景- 全屏显示:在需要网页内容完整覆盖设备屏幕时(如登录页面、全屏视频播放器等),
viewport-fit=cover是非常有用的。 - 避免安全区域问题:在带有刘海或圆角屏幕的设备上,
viewport-fit=cover可以确保网页内容 不会被安全区域裁剪,同时通过 CSS 的env()函数 调整内容布局,避免被遮挡。env(),environment,环境变量值;- 定义的
safe-area-inset-*值可用于: 确保即使在非矩形的视区中, 内容也可以完全显示。
- 全屏显示:在需要网页内容完整覆盖设备屏幕时(如登录页面、全屏视频播放器等),
-
完整示例
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, viewport-fit=cover">
<title>Full Screen Example</title>
<style>
body {
margin: 0;
padding: 0;
width: 100vw;
height: 100vh;
display: flex;
justify-content: center;
align-items: center;
background-color: #f0f0f0;
}
.content {
padding-top: env(safe-area-inset-top);
padding-bottom: env(safe-area-inset-bottom);
padding-left: env(safe-area-inset-left);
padding-right: env(safe-area-inset-right);
}
</style>
</head>
<body>
<div class="content">Full Screen Content</div>
</body>
</html>
- CSS
/* 使用四个安全区域插入值,没有回退值 Using the four safe area inset values with no fallback values */
env(safe-area-inset-top);
env(safe-area-inset-right);
env(safe-area-inset-bottom);
env(safe-area-inset-left);
/* 带回退值,逗号分隔 Using them with fallback values */
env(safe-area-inset-top, 20px);
env(safe-area-inset-right, 1em);
env(safe-area-inset-bottom, 0.5vh);
env(safe-area-inset-left, 1.4rem);
- 值 Values:
safe-area-inset-top,safe-area-inset-right,safe-area-inset-bottom,safe-area-inset-left
safe-area-inset-*:由四个定义了 视口边缘内矩形的top,right,bottom和left的环境变量组成,这样可以安全地放入内容,而不会有 被非矩形的显示切断的风险。- 对于矩形视口,例如 普通的笔记本电脑显示器,其值等于零。
- 对于非矩形显示器(如圆形表盘,iPhoneX 屏幕),在 用户代理设置的四个值 形成的矩形内,所有内容均可见。
- 注意:不同于其他的 CSS 属性,用户代理定义的属性名字 对大小写敏感。
safe-area-inset-*必须小写,否则是无效值;
⑹ 发布者/ 出版机构名称:name=“publisher”
meta标签的name="publisher"属性值- 用于:指定网页内容的 发布者或出版机构的名称。
这个属性在以下情况下使用:
标识内容来源:当你想要明确指出内容的发布者或出版机构时,使用
name="publisher"可以提供这一信息。这对于品牌识别和版权声明非常有用。搜索引擎优化(SEO):通过提供发布者信息,可以帮助搜索引擎更好地理解网页内容的背景,这可能对搜索引擎优化有正面影响。
社交媒体分享:在社交媒体平台分享内容时,
publisher信息可以显示为内容的来源,增加信任度和识别度。内容版权声明:在版权声明中使用,表明内容的版权归属。
- 例: 在这个例子中,
content属性的值 “CSDN” 就是指明 该网页内容的发布者是 CSDN。- 这个标签可以放在 HTML文 档的
<head>部分中,以确保在页面加载时 这些信息能够被正确识别和使用。
- 这个标签可以放在 HTML文 档的
<meta name="publisher" content="CSDN">
⑺ 爬虫 重新访问时间:name=“revisit-after”
meta标签的name="revisit-after"属性值- 用于:告诉搜索引擎爬虫 在指定的时间后 才重新访问页面。
- 这个属性特别适用于 那些不经常更新的页面,通过设置一个合理的重访时间,可以减少搜索引擎爬虫 对服务器资源的占用,同时也能提高 爬虫的效率。
- 什么情况下使用
name="revisit-after":
页面内容不频繁更新:如果你的网站中 有某些页面内容 不经常变化,比如一些静态的介绍页面 或者不常更新的新闻页面,使用
revisit-after可以减少搜索引擎爬虫 对这些页面的访问频率。减轻服务器压力:在流量高峰期间,减少不必要的爬虫访问 可以减轻服务器的压力,特别是在资源有限的情况下。
优化爬虫资源分配:通过设置
revisit-after,可以让搜索引擎 更有效地分配爬取资源,优先爬取那些更新更频繁的页面。
如何使用
name="revisit-after":例: 搜索引擎爬虫应该在7天后再次访问这个网页。
html <meta name="revisit-after" content="7 days">例:表示搜索引擎爬虫应该在 30 天后再次访问这个网页。
- 如果重访时间过短,爬虫将按它们定义的默认时间来访问。
- 也可以使用其他的时间单位,如 “months”或“hours”;
<meta name="revisit-after" content="30 days">
<meta name="revisit-after" content="1 month">请注意,revisit-after 属性值 并不是所有搜索引擎都支持,且其效果可能因搜索引擎的实现而异。因此,使用时需要考虑到这一点。
⑻ 开放图谱: property=“og:*” (分享网页时 提供标题、图像、描述等,搭配 content 属性)
- 开放图谱(Open Graph Protocol,简称 OG 协议)
- 用于:在社交媒体上 分享网页内容时,能够以更丰富的形式展现,而不仅仅是一个链接。
- 描述:用于社交媒体分享时 提供标题、描述和图像,以便在 Facebook、Twitter 等平台上正确显示。
og:*(Open Graph协议)元数据名称 虽然不是 HTML5 标准的一部分,但它们被广泛用于社交媒体平台,用于控制页面在社交媒体上的显示方式。这些元数据名称使用property属性而不是name属性,并且它们的值通常通过content属性来指定。
以下是 使用开放图谱的步骤和示例:
基本步骤
- 添加 Meta 标签:在网页的HTML代码中的
<head>部分添加特定的 Meta 标签。- 设置基本属性:包括
og:title、og:type、og:image和og:url,这些是每个页面都需要的基本属性。
基本属性
og:title:网页的标题,例<meta property="og:title" content="My Website" />。
og:type:内容的类型,例<meta property="og:type" content="website" />。
og:image:代表对象的图片 URL,例<meta property="og:image" content="http://example.com/image.jpg" />。
og:url:网页的网址URL,例<meta property="og:url" content="https://www.example.com" />。可选属性
除了基本属性外,还有一些可选属性可以提供更丰富的信息:
og:description:对象的简短描述。
og:site_name:如果对象是更大网站的一部分,应该显示的 网站名称。
og:locale:这些标签的 语言环境。
og:audio:与对象相关的 音频文件 URL。
og:video:与对象相关的 视频文件 URL。
开放图谱(Open Graph Protocol),简称 OG 协议,是一种互联网协议。
最初由 Facebook 在 2010 年 F8 开发者大会上发布。 它用于 标准化网页中的元数据使用,使得社交媒体可以 以丰富的“图形”对象 表示共享的页面内容。
开放图谱协议 通过在网页中 嵌入特定的 Meta 标签来提取元数据:这些标签包括标题、描述、图片、视频等。当用户在社交媒体上分享该网页时,这些元数据将 被自动抓取 并展示在分享页面上。
开放图谱的主要应用场景包括:
提升社交媒体展示效果:通过提供丰富的元数据,可以控制网站在社交媒体上的展示方式,包括标题、描述、图像等,吸引更多用户点击链接,提高页面的可见性。
增加可分享性:为每个页面定义适当的元数据,鼓励用户分享内容,扩大受众范围,增加流量和参与度。
提高搜索引擎排名:社交媒体共享和互动可以影响搜索引擎排名。使用开放图谱协议,可以改善网站在社交媒体上的表现,从而提高搜索引擎排名。
优化网站在社交媒体上的展示:当页面被共享时,开放图谱控制信息如何从第三方网站传输到社交媒体平台,帮助优化访客看到的内容形式。
开放图谱的使用非常简单,可以通过在 HTML 中添加一些关键元素来实施,例如
og:title、og:description、og:image、og:url等。
这些标签帮助社交媒体平台 识别和展示网页内容,使得 共享的页面内容 不仅仅是一个链接,而是 包含标题、图片和描述的“丰富信息卡片”。
开放图谱(Open Graph Protocol,简称 OG 协议)在以下情况下 需要使用:
社交媒体分享:当你希望网页内容 在社交媒体上被分享时 能够以更丰富的形式展现,包括 标题、图片、描述等信息,而不是仅仅显示一个链接。
提高内容吸引力:使用 OG 协议可以提升内容在社交媒体上的吸引力,鼓励用户点击查看,从而提高点击率和用户参与度。
SEO 优化:优化的 Open Graph 标签可以提高内容在社交媒体上被注意和点击的可能性,为网站带来更多流量,是 SEO 策略中的一个重要工具。
控制社交媒体展示形象:网站所有者可以通过设置 OG 标签来控制他们在社交媒体上展示的形象,例如公司的标志、简介和产品信息等。
增强网站可发现性:使用 OG 协议的网页可能会在搜索引擎结果中获得更高的排名,因为搜索引擎可以更好地理解网页的内容和主题。
提升转化率:OG 协议可以使站点在被链接分享时有更丰富的内容展现,从而提升站点的转化率。
改善社交媒体网站上的内容预览:使用 OG 协议可以确保在在线分享内容时显示特定的图片、标题和描述,改善内容在社交媒体网站上的预览效果。
总结来说,任何希望在社交媒体上提高可见性、吸引用户点击、提升SEO效果的网站都应该使用开放图谱协议。
- 例: 标准元数据名称 - HTML(超文本标记语言) | MDN 网页中的 开放图谱;
- 标题、描述、网站名、类型、网址、语言、图片、图片类型、图片宽高、图片替代文本
<meta property="og:url" content="https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/meta/name">
<meta property="og:title" content="标准元数据名称 - HTML(超文本标记语言) | MDN">
<meta property="og:type" content="website">
<meta property="og:locale" content="zh_CN">
<meta property="og:description" content="The <meta> 元素可用于提供 名称 - 值 对形式的文档元数据,name 属性为元数据条目提供名称,而 content 属性提供值。">
<meta property="og:image" content="https://developer.mozilla.org/mdn-social-share.d893525a4fb5fb1f67a2.png">
<meta property="og:image:type" content="image/png">
<meta property="og:image:height" content="1080">
<meta property="og:image:width" content="1920">
<meta property="og:image:alt" content="The MDN Web Docs logo, featuring a blue accent color, displayed on a solid black background.">
<meta property="og:site_name" content="MDN Web Docs">
- 例: ADHD七小时超长集中注意力&专注学习&舒缓压力背景音|脑波音乐_哔哩哔哩_bilibili 网页中的 开放图谱;
<meta data-vue-meta="true" property="og:type" content="video">
<meta data-vue-meta="true" property="og:title" content="ADHD七小时超长集中注意力&专注学习&舒缓压力背景音|脑波音乐_哔哩哔哩_bilibili">
<meta data-vue-meta="true" property="og:image" content="//i1.hdslb.com/bfs/archive/dec67bc75ebc5df99e7515244e1812853f43ef6a.jpg@100w_100h_1c.png">
<meta data-vue-meta="true" property="og:url" content="https://www.bilibili.com/video/BV1884y137AZ/">
<meta data-vue-meta="true" property="og:width" content="846">
<meta data-vue-meta="true" property="og:height" content="566">
⑼ Twitter 分享时 提供卡片样式和内容: name=“twitter:*”
- twitter:card, twitter:title, twitter:description, twitter:image(Twitter Cards):
- 描述:类似于Open Graph,用于 Twitter 分享时 提供卡片样式和内容。
<meta name="twitter:card" content="summary">
<meta name="twitter:title" content="页面标题">
<meta name="twitter:description" content="页面描述">
<meta name="twitter:image" content="http://example.com/image.jpg">
- 例: 标准元数据名称 - HTML(超文本标记语言) | MDN 网页中 用于 Twitter 分享时的设置
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:creator" content="MozDevNet">
⑽ 一部分 其他的规范之外的元数据名称
一部分 可能用到的 规范之外的元数据名称
① apple-mobile-web-app-capable:
- 告诉 Safari 浏览器 该页面可以作为一个全屏的 Web 应用程序运行。window.navigator.standalone 获取 是否以全屏运行。
<meta name="apple-mobile-web-app-capable" content="yes">② apple-mobile-web-app-status-bar-style:设置 iOS 设备上Safari浏览器的状态栏颜色。可以设置为 black 或 black-translucent 来改变状态栏文本和图标颜色,或者通过 default 恢复到系统默认颜色。
- 为了使 apple-mobile-web-app-status-bar-style 元信息标签生效,首先需要在 HTML 头部声明 apple-mobile-web-app-capable 元信息标签,并将其值设为 yes。
这样设置表明您的网站可以作为一个“全屏”的 Web 应用程序运行,即当用户从主屏幕启动该网站时,它将在没有浏览器界面的状态下运行。
<meta name="apple-mobile-web-app-status-bar-style" content="black-translucent">③ msapplication-TileColor:设置 Windows 任务栏图标和启动屏幕的背景颜色。
<meta name="msapplication-TileColor" content="#00bcd4">④ msapplication-config:引用一个XML文件,其中包含了用于 IE11 的浏览器选项卡图标(favicon)和其他信息。
<meta name="msapplication-config" content="/browserconfig.xml">
3.4 charset 属性:文档 字符编码 (一定要设置;charset=“utf-8”)
<meta>元信息 标签 的charset字符编码 属性- 文档 字符编码和覆盖:
- 声明 当前文档所使用的 字符编码;
- 如果该属性存在,它的值必须是字符串“
utf-8”,因为utf-8是 HTML5 文档的唯一有效编码。
- meta-
charset的属性值:- 字符编码 名称: 此特性的值 必须是一个 符合由 IANA 所定义 的 字符编码 首选 MIME 名称(preferred MIME name )之一。
- IANA: 互联网 地址编码分配 机构(Internet Assigned Numbers Authority)
- 字符编码 名称: 此特性的值 必须是一个 符合由 IANA 所定义 的 字符编码 首选 MIME 名称(preferred MIME name )之一。
- 文档 字符编码和覆盖:
- 字符编码 使用说明: 尽管 标准 不要求必须使用 某些特定的字符编码,但它还是给出了一些建议:
- ❶ utf-8: 鼓励使用
UTF-8;
utf-8为万国码 支持所有语言字符;这是一种广泛支持的编码方式,可以表示几乎所有语言的字符。- ❷ 不能使用和安全风险:
- 不应该使用 不兼容 ASCII 的编码规范, 以避免 不必要的安全风险
- 浏览器不支持他们 (这些不规范的编码)可能会 导致浏览器渲染 html 出错. 比如
JIS_C6226-1983, JIS_X0212-1990, HZ-GB-2312, JOHAB,ISO-2022系列,EBCDIC系列 等文字 ;- ❸ 必须禁用 和跨站脚本攻击:
- 开发者必须禁用
CESU-8, UTF-7, BOCU-1或SCSU这些字符集,因为这些字符集 已经被证实 存在跨站脚本攻击(XSS)的风险。- ❹ 避免使用:
- 发者应 尽量避免 使用
UTF-32字符集对网页 进行编码,因为不是所有的 HTML5 编码算法,能够将其与UTF-16编码 区分开来。- ❺ 声明 和 保存 相匹配:
- 文档内 声明的字符编码 , 必须与 页面保存时 所使用的编码 相匹配,以避免乱码和安全漏洞.
- ❻
<meta>元素的位置:
<meta charset="utf-8" />应该放在<head>部分的最开始,这样浏览器在解析页面时 可以立即识别字符编码。<meta>元素必须包含在<head>元素中 ,并且在HTML代码的 前 1024 个字节内,因为某些浏览器 在选择编码之前 只查看前面这些字节。- 尽量靠前: 所以,文档的字符编码 越早定义 越好,位置 尽量靠前;
- ❼ 优先级:
<meta>元素只是 确定字符集的 算法中的一部分。HTTP的Content-Type头部 以及任何Byte-Order Marks元素 都优先于此元素。- ❽ 定义字符集的必要性 和网页脚本风险: 强烈建议 使用该 meta-
charset字符集 属性定义 字符编码.
- 如果未定义,某些 跨脚本技术 可能危害网页,如
UTF-7 fallback cross-scripting technique. 保持 设置该属性 以避免类似风险。- ❾ 另一种 定义方式:
- 一种,直接用
<meta>元素 的charset属性 定义 字符编码:<meta charset="utf-8" />;- 另一种,在 XHTML 中,meta 标签的用法略有不同,需要使用
http-equiv属性来指定字符集:<meta http-equiv="Content-Type" content="text/html; charset=utf-8">;- 其中,在
content属性值中 再用个charset属性 来定义 字符编码。
- 后者的语法 仍然是允许的,但是 不再推荐。
- ❿ 一致性:确保你的服务器也发送正确的
Content-Type头部信息,其中包含正确的字符编码,以避免与 HTML 头部中的 meta 标签冲突。
总结:正确设置字符编码 对于确保网页内容 在不同浏览器和设备上正确显示 至关重要。
- 涉及的 常用字符编码
-
①
gb2312,采用的编码是 简体中文; -
②
big5,采用的编码是 繁体中文; 港澳台使用. -
③
iso-2022-jp,采用的编码是 日文; -
④
ks_c_5601,采用的编码是 韩文; -
⑤
iso-8859-1,采用的编码是 英文; -
⑥ ★
utf-8,世界通用 的语言编码; (推荐使用的字 符编码)- 包含全世界 所有国家 需要用到的字符
- 强烈推荐
utf-8字符编码,可以很有效的预防,因为字符编码 设置不同,而出现 字符乱码的情况. 
- 不设置
charset属性,也很可能出现 乱码的情况,所以这个属性,一定要设置,而且,最好设置为charset="utf-8",最大限度 避免出现乱码;
- 强烈推荐
- 淘宝网、MDN 用的都是这个字符编码:
<meta charset="utf-8" />
- 包含全世界 所有国家 需要用到的字符
-
⑦
gbk:gb2312一般是 简体中文,gbk在简体中文的范围上 扩展了 繁体中文.适合香港台湾.- w3school 用是这个编码:
<meta charset="gbk" />
- w3school 用是这个编码:
-
总结: 不要使用
content-type属性值, 因为它已过时。使用<meta>元素的charset属性 代替,定义 meta-charset字符编码 就可以了,不用定义http-quiv="content-type",多此一举。
-
- 为什么 不推荐使用
meta标签的http-equiv="content-type"属性值 ?
① 主要是因为在 HTML5 中,已经有了更简洁和明确的方式 来指定文档的字符编码,
即 直接使用:<meta charset="UTF-8">。
这种方式 更符合 HTML5 的标准,且具有 更好的兼容性和语义清晰度。
② 此外,http-equiv="content-type"属性值 用于:声明文档的 MIME 类型和字符编码,但在现代 Web 开发中,通常只有当 MIME 类型不是text/html或者当文档是 XHTML 格式时,才需要显式地指定content-type。
③ 对于绝大多数 HTML 文档而言,使用<meta charset="UTF-8">就足够了,因为它告诉浏览器 文档使用的是UTF-8编码,这是目前 最常用的字符编码,能够覆盖绝大多数字符,且被所有现代浏览器支持。
因此,为了代码的简洁性、清晰性以及与 HTML5 标准的一致性,
推荐使用<meta charset="UTF-8">来代替http-equiv="content-type"属性值。
这样做可以确保文档的字符编码 被正确识别,同时也使得 HTML 文档更加符合现代 Web 标准。
gbk 和 gb2312 的区别
GB2312 和 GBK 是中文字符编码标准,它们都是由中国国家标准总局制定的,用于编码中文字符。以下是它们的主要区别:
字符集大小:
- GB2312:这是一个较早的中文字符编码标准,发布于 1980 年。它是一个双字节编码系统,基本集包含了 6763 个汉字和682个其他符号,包括拉丁字母、日文假名等,总共 7445 个字符。
- GBK:全称是汉字内码扩展规范,发布于 1995 年。它是 GB2312 的扩展,包含了 GB2312 的所有字符,并增加了更多的汉字和符号,总共收录了21003个汉字,包括简体字和繁体字,以及日韩汉字等。
编码范围:
- GB2312:编码范围是 0xB0A1-0xF7E。GB2312 的编码范围较小,只能覆盖有限的汉字。
- GBK:编码范围是 0x8140-0xFEFE。GBK 的编码范围更大,能够覆盖更多的汉字和符号。
兼容性:
- GB2312:由于 GB2312 的编码范围有限,它只能兼容 GB2312 自己的字符集。
- GBK:GBK 设计时考虑了向后兼容性,它完全兼容 GB2312,即 GB2312中 的所有字符在 GBK 中都有相同的编码。
使用场景:
- GB2312:由于字符集较小,GB2312 主要用于早期的中文计算机系统和简单的文本处理。
- GBK:由于字符集更大,GBK 适用于需要处理大量汉字和符号的场合,如现代的中文操作系统、网页、文档处理等。
国际化:
- GB2312:由于字符集较小,GB2312 在国际化方面的能力有限。
- GBK:GBK 虽然比 GB2312 有所改进,但由于它主要针对中文,因此在国际化方面 仍然不如 UTF-8 等国际通用编码。
发展趋势:
- GB2312:随着技术的发展,GB2312 由于字符集的限制,已经逐渐被更先进的编码标准所取代。
- GBK:虽然 GBK 比 GB2312 更先进,但由于它仍然存在编码范围的限制,并且不是国际标准,所以也逐渐被 UTF-8 等国际通用编码所取代。
总的来说,GBK 是 GB2312 的扩展和改进,它能够覆盖更多的汉字和符号,但随着国际化和互联网的发展,两者都逐渐被更通用的编码 如 UTF-8 所取代。
-
什么情况下,需要使用
meta标签的charset属性 ?meta标签的charset属性在以下情况下特别有用:
-
① 多语言支持:当网页包含多种语言的字符时,使用
charset属性可以确保所有字符 都能被正确解析和显示。- 示例: 在这个例子中,
charset="UTF-8"确保了页面能够正确显示英文、中文和日文字符。
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>多语言页面</title> </head> <body> <p>英语:Hello World!</p> <p>中文:你好,世界!</p> <p>日文:こんにちは、世界!</p> </body> </html> - 示例: 在这个例子中,
-
② 特殊字符:当网页包含特殊字符或符号时,使用
charset属性可以避免字符显示错误或乱码。- 示例: 在这个例子中,
charset="UTF-8"确保了版权符号和 HTML 实体能够被正确显示。
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>包含特殊字符的页面</title> </head> <body> <p>版权所有 © 2024</p> <p>大于小于符号:> 和 <</p> </body> </html> - 示例: 在这个例子中,
-
③ 国际化网站:对于面向全球用户的网站,使用
charset属性可以确保不同语言的用户 都能获得良好的浏览体验。- 示例: 在这个例子中,
charset="UTF-8"支持了网站的国际化,使得不同语言的用户 都能正确阅读内容。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>国际化网站</title> </head> <body> <p>欢迎来自世界各地的用户!</p> </body> </html> - 示例: 在这个例子中,
-
④ 避免字符编码冲突:当服务器配置或文件编码 与页面编码不一致时,使用
charset属性可以避免字符编码冲突。- 示例: 假设服务器配置为发送
Content-Type: text/html; charset=ISO-8859-1,而页面文件实际使用的是UTF-8编码。如果不在 HTML 中指定charset="UTF-8",可能会导致页面显示乱码。
- 示例: 假设服务器配置为发送
-
⑤ SEO 优化:搜索引擎优化(SEO)中,正确的字符编码 可以提高页面的可读性和索引效果。
- 示例: 在这个例子中,
charset="UTF-8"确保了页面内容能够被搜索引擎正确解析和索引。
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>SEO优化页面</title> </head> <body> <p>优化后的页面内容,包含关键词。</p> </body> </html> - 示例: 在这个例子中,
-
总结:使用
meta标签的charset属性 是确保网页内容在不同浏览器、设备和语言环境中正确显示的关键步骤。
3.5 media 属性:指定 适用媒体
-
meta标签的media属性- 用于:指定媒体查询(Media Queries),以便根据不同的设备特性(如屏幕宽度、分辨率等)来应用不同的 CSS 样式。这个属性在响应式设计中非常有用,它允许网页在不同设备上呈现不同的布局和样式。
-
例:
media属性可以用来 描述所提供的颜色 应该使用的环境。- 如果我们只想在“深色模式”下 使用“绿色”作为 主题色,我们可以使用 偏爱的颜色方案
prefers-color-scheme媒体特性: media="(prefers-color-scheme: dark)"是一个 CSS 媒体查询,用于检测用户是否 在操作系统级别设置了深色模式。- 如果用户的系统偏好设置为深色模式,那么这个媒体查询就会匹配,相应的 CSS 样式就会被应用。
- 这个媒体查询特别有用,因为它允许网页开发者 为使用深色模式的用户 自动提供暗色主题的样式,而无需用户手动切换
- 这样,网页就可以更好地融入用户的系统外观和感觉,提供更一致的用户体验。
- 如果我们只想在“深色模式”下 使用“绿色”作为 主题色,我们可以使用 偏爱的颜色方案
<title>HTML Standard</title>
<meta name="theme-color" content="#3c790a" media="(prefers-color-scheme: dark)">
-
例: 特定设备优化:你可以使用
meta标签的media属性来为特定设备提供优化。- 这个例子中,
meta标签指定了在屏幕宽度小于或等于 768 像素的设备上,使用 IE 的最新渲染引擎(ie=edge)。screen:表示这段代码适用于 屏幕显示设备。(max-width: 768px):这是一个媒体查询条件,表示这段代码只在 屏幕宽度 小于或等于768像素时生效。768像素是一个常见的响应式设计阈值,通常用于区分移动设备和桌面设备。
<meta http-equiv="x-ua-compatible" content="ie=edge" media="screen and (max-width: 768px)"> - 这个例子中,
-
例: 响应式设计:在响应式设计中,你可以使用
meta标签来设置视口,确保页面在不同设备上正确显示。- 在这个例子中,
meta标签设置了视口,使得页面的宽度等于设备的宽度,并且初始缩放比例为 1。CSS 中的媒体查询 则根据屏幕宽度应用不同的样式。
<!DOCTYPE html> <html> <head> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>响应式页面</title> <style> /* 基础样式 */ body { margin: 0; font-family: Arial, sans-serif; } /* 大屏幕(桌面)样式 */ @media screen and (min-width: 1024px) { .container { width: 80%; margin: auto; } } /* 小屏幕(手机)样式 */ @media screen and (max-width: 768px) { .container { width: 95%; margin: auto; } } </style> </head> <body> <div class="container"> <h1>欢迎来到我的响应式网站</h1> <p>这个页面会根据你的屏幕尺寸自动调整布局。</p> </div> </body> </html> - 在这个例子中,
-
注意事项
meta标签的media属性通常与 CSS 媒体查询一起使用,而不是直接在meta标签中设置样式。meta标签的media属性主要用于指定媒体查询,而不是直接控制样式。实际的样式控制应该在 CSS 中通过媒体查询来实现。- 确保在使用响应式设计时,测试你的网站在不同设备和浏览器上的表现,以确保最佳的用户体验。
CSS 媒体查询(Media Queries):是一种在 CSS3 中引入的功能,它允许网页设计者 根据设备的特定特征,如 屏幕尺寸、分辨率、方向等,来应用不同的 CSS 样式规则。媒体查询使得响应式设计成为可能,即网页能够 根据不同设备的特性 动态调整布局和样式,以提供最佳的用户体验。
在 HTML 和 CSS中,
media属性用于 指定媒体查询,这些查询定义了 CSS 样式的适用条件,基于不同的设备特性,如屏幕宽度、分辨率等。有效的媒体类型是一组预定义的关键词,用来描述目标设备的类别。
以下是一些常用的有效媒体类型:
all:
- 适用于 所有设备。
print:
- 适用于 打印机和打印预览。
screen:
- 适用于电脑屏幕、平板电脑、智能手机等 屏幕显示设备。
speech:
- 适用于屏幕阅读器等 发声设备。
除了这些基本的媒体类型,还可以使用更具体的媒体特性 来进一步细化样式的应用条件,例如:
width/wɪdθ;wɪtθ/:
- 指定设备的 视口宽度。
height/haɪt/:
- 指定设备的 视口高度。
device-width/dɪˈvaɪs/:
- 指定设备的 屏幕宽度。
device-height:
- 指定设备的屏幕高度。
orientation/ˌɔːriənˈteɪʃ(ə)n/:
- 指定设备的 方向(portrait/ˈpɔːrtrət/,竖向 或 landscape/ˈlændskeɪp/,横向)。
resolution/ˌrezəˈluːʃ(ə)n/:
- 指定设备的 分辨率。
scan:
- 指定 电视的扫描类型(progressive 或 interlaced)。
color:
- 指定设备的 色彩位数。
color-index:
- 指定设备的 颜色索引位数。
monochrome/ˈmɑːnəkroʊm/:
- 指定设备的 单色显示能力。
媒体查询可以 结合这些媒体特性 来创建复杂的条件,例如:
@media screen and (max-width: 600px) { /* 小于 600px 屏幕的 CSS规则, CSS rules for screens narrower than 600px */ } @media print { /* CSS rules for print media */ } @media screen and (min-resolution: 2dppx) { /* CSS rules for high-resolution screens */ }在这些例子中,CSS 样式将根据屏幕宽度、是否为打印媒体以及屏幕分辨率来应用不同的规则。这些媒体查询使得开发者能够创建更加灵活和适应不同设备需求的 Web 页面。
3.6 itemprop 全局属性:提供 用户定义的元数据(项目属性、用户元数据;事物的类型属性 Schema;更多语义;搭配 content 属性)
meta标签的itemprop属性- 是 HTML5 中引入的全局属性;
- 用于:在结构化数据中 定义一个项目(item)的具体属性。
- 通过
itemprop,开发者可以为 HTML 元素添加属性,以提供关于网页内容的 更多语义信息,这对于搜索引擎优化(SEO)和富数据的标记特别有用。itemprop属性位置- 单独放在一个
meta标签上,一般不能和name、http-equiv或字符集charset属性 设置在同一个<meta>元素上。(MDN) - why?
- 单独放在一个
根据 HTML5 规范,
itemprop属性不能与name、http-equiv或charset属性同时出现在同一个<meta>标签中的原因如下:❶ 语义区分/ 语义冲突
name属性用于定义文档级别的元数据,通常与content属性一起使用,以名值对的形式提供信息。
<meta>标签的name、http-equiv和charset属性分别用于 定义文档级别的元数据、模拟 HTTP 头部信息和声明字符集;
itemprop属性用于定义微数据(microdata),即用户自定义的元数据,与itemscope和itemtype等属性配合使用,通常与content属性一起使用,以名值对的形式提供信息。将两者混用会导致 语义不清晰,无法明确区分元数据的类型和用途。
❷ 规范限制
- HTML5 规范明确指出,当
<meta>标签中存在name、http-equiv或charset属性时,itemprop属性不能被使用。这种限制是为了保持 HTML 的语义清晰性和一致性,避免解析错误或歧义。❸ 解析优先级问题
- 如果允许
itemprop与name等属性混用,浏览器或解析器可能会在解析过程中产生优先级冲突,导致某些属性被忽略或错误解析。
关于 下方示例 ↓,哔哩哔哩网站的特殊情况
- 尽管HTML5规范明确禁止这种用法,但实际开发中可能会出现不符合规范的情况。这可能是由于以下原因:
历史遗留代码:网站可能在早期开发时未严格遵循规范,后续未进行修正。
搜索引擎优化(SEO)需求:某些情况下,开发者可能认为这种用法对搜索引擎优化有益,尽管这并不符合HTML5标准。(下方示例 是把该网页和该视频的 标题、关键词、描述、作者 都等同了,所以
name属性和itemprop放在一起使用,不怕歧义;因为这个网页的主题内容 就是这个视频;)浏览器兼容性问题:某些浏览器可能对这种用法进行了非标准的解析,导致开发者误以为这种用法是可行的。
然而,这种用法并不符合 HTML5 规范,可能会导致不可预测的行为或兼容性问题。
-
以下是如何使用
meta标签的itemprop属性的一些示例: -
例: ADHD 七小时超长集中注意力&专注学习&舒缓压力背景音|脑波音乐_哔哩哔哩_bilibili 网页中的
itemprop属性;- ❶ 项目范围
itemscope属性:定义了一个新的项目; - ❷ 项目类型
itemtype属性:提供了 项目类型的网址;itemtype的值(如https://schema.org/Product)来自Schema.org网站的词汇表,用于明确指定 数据的类型。itemscope和itemtype:共同定义了一个产品(Product)的上下文(语境)。一般写在 各种属性所在标签的 父元素里;
- ❸ 具体属性
itemprop属性:定义了项目的 具体属性,如name、description 和 price。
- ❶ 项目范围
<head itemprop="video" itemscope="" itemtype="http://schema.org/VideoObject">
<meta data-vue-meta="true" itemprop="keywords" name="keywords" content="ADHD七小时超长集中注意力&专注学习&舒缓压力背景音|脑波音乐,冥想,学习,纯音乐,专注,ADHD,音乐,音乐综合,哔哩哔哩,bilibili,B站,弹幕">
<meta data-vue-meta="true" itemprop="description" name="description" content="https://www.youtube.com/watch?v=RG2IK8oRZNA&amp;t=425s多动症缓解音乐是专门为帮助多动症患者提高注意力和焦点而设计的。它通常包括舒缓的旋律和平静的节奏,可以放松思想并帮助提高注意力。这种类型的音乐可以在学习、工作或从事其他需要集中注意力的任务时作为背景噪音使用。, 视频播放量 2166366、弹幕量 2069、点赞数 56202、投硬币枚数 14567、收藏人数 143767、转发人数 14590, 视频作者 Mo35chi, 作者简介 三无mochi,相关视频:8小时|多动症缓解音乐|ADHD Relief Music|工作学习专注背景音乐(自用),最稀有的声部——女低音,每天睡4小时,睡13小时和睡8小时的区别,患有ADHD(注意缺陷多动障碍)的人,日常生活是怎样的?,ADHD患者与普通人的行为细微差异,如果世界是为ADHD(多动症)而定制的…,【心流冥想】每天10min,收获超强专注,高效一整天 | 专注系列01,一些 ADHD患者常见的口头表达问题,四小时超长巴赫学习音乐 |古典音乐|集中注意力|写作业音乐|油管超火学习音乐|听着巴赫学习,你自律你的,我低效我的,别管">
<meta data-vue-meta="true" itemprop="author" name="author" content="Mo35chi">
<meta data-vue-meta="true" itemprop="name" name="title" content="ADHD七小时超长集中注意力&专注学习&舒缓压力背景音|脑波音乐_哔哩哔哩_bilibili">
<meta data-vue-meta="true" itemprop="url" content="https://www.bilibili.com/video/BV1884y137AZ/">
<meta data-vue-meta="true" itemprop="image" content="//i1.hdslb.com/bfs/archive/dec67bc75ebc5df99e7515244e1812853f43ef6a.jpg@100w_100h_1c.png">
<meta data-vue-meta="true" itemprop="thumbnailUrl" content="//i1.hdslb.com/bfs/archive/dec67bc75ebc5df99e7515244e1812853f43ef6a.jpg@100w_100h_1c.png">
<meta data-vue-meta="true" itemprop="uploadDate" content="2023-03-23 20:08:20">
<meta data-vue-meta="true" itemprop="datePublished" content="2023-03-23 20:08:20">
</head>
meta标签的itemprop属性 为我们提供了更准确和详细地 定义HTML元素内容的方式。- 通过使用
itemprop属性,我们可以更好地 描述网页的结构和语义,提高搜索引擎 对网页的理解和索引。
- 通过使用
meta标签的itemprop属性 在以下情况下使用:
定义项目属性:当需要为HTML元素添加具体的项目属性时,可以使用
itemprop属性。这有助于提供更多关于元素内容的语义信息,使得搜索引擎或其他应用程序能够更好地理解页面内容。网页SEO优化:使用
itemprop属性可以提升网页的搜索引擎优化(SEO)效果,因为它允许网页开发者更准确地描述网页的结构和内容,从而提高搜索引擎对网页的理解和索引。与 Schema.org 结合使用:
itemprop属性常与 Schema.org/ˈskiːmə/ 结合使用,Schema.org 是一个用于 定义【结构化数据的 共享词汇表】,定义的是【事物的 类型和属性】。通过使用 Schema.org 提供的 属性和类型,可以为 HTML 页面 添加更多的 语义信息,以便搜索引擎 更好地理解和解释页面内容。隐藏数据:有时,网页上有值得标识的信息,但因为它们在网页上的显示方式 导致它们不能被标识。这些信息可能通过图像或 Flash object 本身来表达,或者是隐含其中并没有在网页上明确表示。此时,使用带有
content属性的meta标签明确表示该信息。指定页面的主要内容:有时候我们希望搜索引擎能够 更好地理解页面的主要内容,这样可以提高网页在搜索结果中的排名。我们可以使用
itemprop属性来指定页面的主要内容。定义文章的摘要:在网页开发中,我们经常需要为文章定义一个简短的摘要,方便读者快速了解文章内容。我们可以使用
itemprop属性来定义文章的摘要。指定作者和发布日期:如果我们想要为网页指定作者和发布日期,我们可以使用
itemprop属性来定义这些元数据。
- 例: 以下是一个具体的使用示例:
<div itemscope itemtype="http://schema.org/Product">
<span itemprop="name">产品名称</span>
<meta itemprop="mpn" content="product12345" /> <!-- 产品型号 -->
<meta itemprop="brand" content="品牌名称" /> <!-- 品牌 -->
<span itemprop="description">产品描述</span> <!-- 产品描述 -->
<meta itemprop="sku" content="SKU12345" /> <!-- 库存单位 -->
</div>
- 在这个例子中,
itemprop属性 用于为产品定义不同的属性,如 名称、型号、品牌、描述和库存单位,这些属性都是基于Schema.org 的词汇表定义的。这样的结构化数据 可以帮助搜索引擎更好地理解页面内容,并在搜索结果中 提供更丰富的信息。 - 友情链接:Schema.org 中文站
- schema 网站存在的意义 是什么?
- schema 网站里 定义了 很多事物的“类型、属性”,如上方示例,搭配微数据
itemscope、itemtype、itemprop等属性,用到标签里,可以方便 搜索引擎等 理解语义; - Schema.org 中文站 词汇表 - Schemas Docs
- schema 网站里 定义了 很多事物的“类型、属性”,如上方示例,搭配微数据
- 简而言之,schema 就是 给各种事物 分类型,每个类型的事物 都有一个属性集合,这些属性提供 该事物的很多信息,就是“语义信息”;
-
如下,Schema 其中一个“视频”类型,下面有很多“属性”,每个都是跟视频相关的信息,用来给视频 提供更多 语义信息;
-
一个“视频”类型,有以下多种“属性”;各个属性 一般作为
itemprop的属性值,作为属性名称,用在<meta>标签里时,具体值,写在搭配的content属性里; -
-
Schema 中 常见的事物分类
- 创造性工作: CreativeWork, 书 Book, 电影 Movie, 音乐 MusicRecording, 食谱 Recipe, 电视剧 TVSeries …
- 嵌入式非文本对象: 音频 AudioObject, 图像 ImageObject, 视频 VideoObject
- 事件 Event
- 医药和健康类型: MedicalEntity 词条.
- 组织 Organization
- 人物 Person
- 地点 Place, 本地商户 LocalBusiness, 餐馆 Restaurant …
- 产品 Product, 售价 Offer, 均价 AggregateOffer
- 评论 Review, 综合评论 AggregateRating
-
- schema 网站存在的意义 是什么?
itemprop属性如何使用?有哪些属性值 ?itemprop属性是 HTML5 中用于微数据(Microdata/ˈmaɪkroʊ/,/ˈdeɪtə/)的全局属性,用于为 HTML 元素添加 自定义的属性名称和值,从而为搜索引擎、爬虫或其他解析器 提供“更丰富的 语义信息”。
❶ 定义微数据的上下文(语境,context/ˈkɑːntekst/)
- 在使用
itemprop之前,需要通过itemscope和itemtype定义一个微数据项的上下文(语境)。itemtype是一个 URL,指向一个词汇表(如 Schema.org),定义了itemprop属性的语义。- 在这个例子中,
itemscope和itemtype定义了一个关于“人”类型 的微数据项,itemprop用于指定 “人”的每个属性的名称。<div itemscope itemtype="https://schema.org/Person"> <p>姓名:<span itemprop="name">张三</span></p> <p>职位:<span itemprop="jobTitle">工程师</span></p> <p>公司:<span itemprop="worksFor">ABC公司</span></p> </div>
❷
itemprop与<meta>标签的结合
- 如果需要在
<meta>标签中使用itemprop,可以将itemprop和content属性一起使用,但不能与name、http-equiv或charset属性混用。- 在这种情况下,
<meta>标签用于隐藏的元数据,不会在页面上显示。<div itemscope itemtype="https://schema.org/Person"> <meta itemprop="name" content="张三"> <meta itemprop="jobTitle" content="工程师"> <meta itemprop="worksFor" content="ABC公司"> </div>
- ❸
itemprop的属性值 示例itemprop的属性值取决于:所使用的词汇表(如 Schema.org)。- 常见的属性值包括:
name:表示名称或标题。description:表示描述性文本。image:表示图像的 URL。url:表示链接的 URL。price:表示价格。jobTitle:表示职位。worksFor:表示工作单位。- 这些属性值的具体含义和用法 需要参考所使用的【schema 事物类型和属性-词汇表】。
- ❹ 注意事项
- 【
itemprop必须与itemscope和itemtype一起使用,否则没有语义】。- 在
<meta>标签中使用itemprop时,不能与name、http-equiv或charset属性混用。- 常用的词汇表包括 Schema.org,它提供了 丰富的语义属性。
- 通过合理使用
itemprop,可以为网页 添加更丰富的语义信息,提升搜索引擎的解析效果。
3.7 scheme 属性:解释 content 属性值 的格式含义(已废弃;元数据分类;格式/格式名/格式 URI;)
-
meta标签的scheme属性(已废弃)- 用于:定义
content属性中 值的格式,用于解释content属性值的格式。 scheme属性值:可以是一个格式名称(如"ISBN"),一个格式(如"YYYY-MM-DD"),或者是一个指向提供有关格式更多信息的 URI 的链接。<meta>标签的scheme属性 并不是一个标准的 HTML5 属性,而是早期 HTML 中用于定义 元数据分类的属性。- 然而,在现代 HTML5 中,
scheme属性已经被废弃。取而代之的是使用微数据(Microdata)和 Schema.org 词汇表 来定义和分类 元数据。
- 然而,在现代 HTML5 中,
- 用于:定义
-
例: 以下是
scheme属性的一个使用示例:- 第一个
meta标签 定义了一个名为date的元数据,其值为"2009-01-02",并且通过scheme属性 指定了这个日期值的格式为"YYYY-MM-DD"。 - 第二个
meta标签 定义了一个名为identifier的元数据,其值为"0-2345-6634-6",并且通过scheme属性 指定了这个值的格式为"ISBN"(International Standard Book Number)),意味着这是一个国际标准书号。
- 第一个
<head>
<meta name="date" content="2009-01-02" scheme="YYYY-MM-DD">
<meta name="identifier" content="0-2345-6634-6" scheme="ISBN">
</head>
- 注意:
scheme属性在 HTML5 中不被支持,并且已被标记为已弃用 。- 这意味着虽然一些浏览器可能仍然支持它,但开发者不应该在新的网页设计中使用这个属性,并且应该寻找替代方案。
scheme属性的目的- 是为了让浏览器或用户代理 能够更准确地理解和处理
content属性中的值,如果浏览器或用户代理能够识别scheme属性指定的方案,那么它就可以更准确地解释content属性的值。
- 是为了让浏览器或用户代理 能够更准确地理解和处理
- 所有主流浏览器都曾支持
scheme属性,但鉴于其已被弃用,开发者应当避免使用,并更新现有代码以兼容现代 web 标准 。
- 元数据的种类
- 根据
<meta>的不同属性,元数据的类型 可以是以下类型之一:- 整个页面: meta-
name:- 如果设置了
name,则它是 文档级 元数据,应用于 整个页面。
- 如果设置了
- 如何 服务页面: meta-
http-equiv- 如果设置了
http-equiv,它就是一个指令——通常由 web服务器提供 关于如何服务 web 页面的信息。(发送文档前,传送给浏览器参考的 值对,更精确 显示网页)
- 如果设置了
- 字符编码: meta-
charset- 如果设置了
charset字符集,则它是一个字符集 声明—网页使用的 字符编码。
- 如果设置了
- 用户 元数据: meta-
itemprop- 如果设置了
itemprop,则它是 用户定义的元数据——对于用户代理来说 是透明的,元数据的语义 是特定于用户的。
- 如果设置了
- 整个页面: meta-
4. ★ base 标签:所有相对路径 的基准 url 、链接 目标打开位置 (搭配 href、target 属性)
- 指定 所有链接的 默认地址 或 打开位置
- 如何为 页面上的 所有相对路径 规定默认地址 或 指定默认打开位置 ?
- 使用
<base>基准url 或目标打开位置 标签- 基准路径 url: HTML
<base>元素 用于 文档中 所有 相对url 的 基准路径 url。- 所有相对 URL 的 根 URL / 基准 url;
- 需要注意的是,使用
<base>标签时应当谨慎,因为它会影响到所有页面上的href和src属性相对路径的定位。
- 仅限 一个: 一个文档中 只能 有 一个
<base>元素。- 选择 第一个: 如果使用 多个
<base>元素,则只遵从 第一个href和 第一个打开位置target,其他所有元素 都被忽略。 - 可以在一个
base标签中同时指定href属性和target属性。这样做可以同时为文档中的所有相对链接 设置一个基础 URL 和一个目标窗口或框架。
- 选择 第一个: 如果使用 多个
- 查询: 一个文档的 基本 URL,可以通过 使用
document.baseURI的 JS 脚本查询。 - 限定 父元素: 任何 不带有任何其他
<base>元素的<head>元素,即 一个head标签中 只能有 一个base标签;- 必须属性:一个
base元素 必须有一个href属性 或 一个target属性,或者两者都有。 - 所以,要指定两个属性时,不要分开在两个
base标签中指定href和target,HTML 规范并不支持这样做,但可以只指定 其中一个属性。 - 一个 HTML 文档中只能有一个
base元素,因此你不能有两个base标签。如果你尝试在文档中使用多个base标签,浏览器通常会忽略除第一个之外的所有base标签。- 如果需要改变链接的目标,你可以直接在
<a>标签中使用target属性,而不是尝试使用多个base标签。
- 如果需要改变链接的目标,你可以直接在
- 必须属性:一个
- 基准路径 url: HTML
- 使用
- 使用
<base>基准 url 或打开位置 标签- ❶
base标签的href属性 影响到的 标签- ①
<a>链接href - ②
<img>图片src - ③
<link>链接href - ④
<form>标签中的 URL。
- ①
- ❷
base标签 的target属性 一般只影响到<a>链接href; - ❸ 不影响: Open Graph 标记 不识别
<base>,所以meta标签中的 url 应该 始终具有 完整的绝对url。- og: Open Graph,例如:
<meta property="og:image" content="https://example.com/thumbnail.jpg">
- og: Open Graph,例如:
- ❶
- 如何为 页面上的 所有相对路径 规定默认地址 或 指定默认打开位置 ?
- 使用说明
- 限定 位置:
<base>基准url 或打开位置 标签 必须位于 什么位置 ?- 文档头部
<head>元素的内部。
- 文档头部
- 限定 位置:
- 正确 关闭:
<base>基准url 或打开位置 标签 ,HTML 与 XHTML 之间的差异- 在 HTML 中,
<base>基准 url 或打开位置 标签 没有结束标签; - 在 XHTML 中,
<base>基准 url 或打开位置 标签 必须被正确地关闭。
- 在 HTML 中,
- 例: 在
base标签 中指定基准 url, 页面其他的地址 可以用 相对 url;- 在这个例子中,
base标签的href属性被设置为https://www.example.com/,这意味着文档中的所有相对路径 都会以这个 URL 作为基础。 base标签还有其他属性,比如target,可以用来指定所有链接打开时的目标窗口或框架。- 需要注意的是,
base标签应该放在head部分,而且一个 HTML 文档中 只能有一个base标签。
- 在这个例子中,
<!DOCTYPE html>
<html>
<head>
<base href="https://www.example.com/">
<title>Base Tag Example</title>
</head>
<body>
<a href="page1.html">Go to Page 1</a> <!-- 这将指向 https://www.example.com/page1.html -->
<img src="images/logo.png" alt="Company Logo" /> <!-- 这将指向 https://www.example.com/images/logo.png -->
</body>
</html>
- 为什么 在一个 HTML 文档中,只能有一个
<base>标签?- 这是由 HTML 规范明确规定的。原因如下:
❶ 语义唯一性
<base>标签用于定义 文档中 【所有相对 URL 的基准路径】。如果存在多个<base>标签,浏览器将无法确定 应该使用哪一个作为基准路径,从而导致 解析上的歧义和混乱。❷ 规范限制
- HTML 规范(包括 HTML5)明确规定,一个文档中只能包含一个
<base>标签。这是因为<base>标签的作用范围 是整个文档,多个<base>标签 会导致冲突和不可预测的行为。❸ 浏览器实现
- 浏览器在解析 HTML 文档时,通常只会处理第一个
<base>标签,并忽略后续的<base>标签。因此,即使在文档中使用了多个<base>标签,也只有第一个会被生效。例: 以下是一个正确的
<base>标签使用示例:<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Base Tag Example</title> <base href="https://example.com/path/to/base/" target="_blank"> </head> <body> <a href="page1.html">Page 1</a> <a href="page2.html">Page 2</a> </body> </html>
在这个例子中:
- 所有相对路径的链接(如
page1.html和page2.html)都会被解析为https://example.com/path/to/base/page1.html和https://example.com/path/to/base/page2.html。- 所有链接都会在新标签页中打开(由
target="_blank"指定)。如果使用多个
<base>标签会发生什么?
- 如果在文档中使用了多个
<base>标签,浏览器通常会忽略除第一个之外的所有<base>标签。
例:<base href="https://example.com/path1/"> <base href="https://example.com/path2/">
在这种情况下,只有
https://example.com/path1/会被生效,而https://example.com/path2/会被忽略。总结
- 一个 HTML 文档中只能有一个
<base>标签。- 多个
<base>标签 会导致冲突和不可预测的行为。- 浏览器通常只会处理第一个
<base>标签,并忽略后续的<base>标签。- 因此,为了确保文档的正确解析和行为一致性,应始终只使用一个
<base>标签。
4.1 base 标签 的属性
- 必需的属性
| 属性名 | 属性值 | 用于 |
|---|---|---|
| href | = URL | 指定 页面中 所有相对链接的 基准 URL。 |
- 可选的属性
| 属性名 | 属性值 | 用于 |
|---|---|---|
| target | =_blank , _parent , _self , _top , framename | 链接 打开位置在 何处打开 页面中 所有的链接。 |
⑴ href 属性: 所有相对路径的 基准路径 url (一个绝对 url)
-
⑴
base标签的href属性- 用于:指定一个基础 URL,这个 URL 将作为文档中 所有相对路径的基准。
- 当你在 HTML 文档中使用相对路径时,浏览器会将这些路径与
base标签的href属性值结合起来,以确定最终的绝对路径。 - abbr. 超文本引用(hypertext/ˈhaɪpərtekst/ reference/ˈrefrəns/);
- 当你在 HTML 文档中使用相对路径时,浏览器会将这些路径与
- 基准 url: 用于文档中 使用相对 URL 地址的 基准路径 URL。
- 位置: 如果指定了 该属性,这个元素必须 写在 其他任何属性值是 URL 的元素之前。
- 使用优先: 如果指定了 多个
<base>元素,只会使用 第一个<base>元素的href和target值, 其余都会被忽略。
- 用于:指定一个基础 URL,这个 URL 将作为文档中 所有相对路径的基准。
-
例: 以下是
base标签href属性的使用示例:
<!DOCTYPE html>
<html>
<head>
<!-- 设置基础 URL -->
<base href="https://www.example.com/directory/" target="_blank">
<title>Base Tag Example</title>
</head>
<body>
<!-- 相对路径将与基础 URL 结合 -->
<a href="page1.html">Go to Page 1</a> <!-- 这将指向 https://www.example.com/directory/page1.html -->
<a href="../contact.html">Go to Contact</a> <!-- 这将指向 https://www.example.com/contact.html -->
<img src="images/logo.png" alt="Company Logo" /> <!-- 这将指向 https://www.example.com/directory/images/logo.png -->
<script src="scripts/app.js"></script> <!-- 这将指向 https://www.example.com/directory/scripts/app.js -->
</body>
</html>
-
在这个例子中:
<base href="https://www.example.com/directory/">:- 定义了一个基础 URL,即
https://www.example.com/directory/。
- 定义了一个基础 URL,即
<a href="page1.html">:- 链接到
page1.html,由于page1.html是一个相对路径,浏览器会将其与基础 URL 结合,最终指向https://www.example.com/directory/page1.html。
- 链接到
<a href="../contact.html">- 链接到
contact.html,这里的..表示上一级目录,所以最终指向https://www.example.com/contact.html。
- 链接到
<img src="images/logo.png">- 图片的
src属性 也是一个相对路径,最终指向https://www.example.com/directory/images/logo.png。
- 图片的
<script src="scripts/app.js"></script>- 脚本的
src属性 同样是一个相对路径,最终指向https://www.example.com/directory/scripts/app.js。
- 脚本的
-
base标签的href属性对于 确保文档中的所有链接 都正确指向预期的资源非常有用,尤其是在单页应用或者大型网站中,可以 减少“维护链接”的复杂性。
base标签的href属性值可以是 相对 url 吗?不可以,
base标签的href属性值必须是绝对 URL。这是因为base标签的作用是 为文档中所有的相对 URL 提供一个基础(基点),以便浏览器能够解析出完整的 URL 路径。如果
base标签的href属性值是相对 URL,那么它将无法提供一个明确的基点,因为相对 URL 本身就需要一个上下文(即当前的绝对路径)来解析。因此,HTML 规范要求base标签的href属性必须指向一个完整的绝对路径。
例如,以下是一个有效的
base标签使用:
html <base href="https://www.example.com/">以下是一个无效的使用,因为它使用的是相对 URL:
html <!-- 这是错误的用法 --> <base href="/path/to/resource/">在实际开发中,始终应该使用 完整的绝对 URL 作为
base标签的href属性值。
绝对 url 和 相对 url 的区别是什么?
- 绝对 URL(Absolute/ˈæbsəluːt/ URL)和相对 URL(Relative/ˈrelətɪv/ URL)是网页中 用来指定资源位置的两种不同方式:
绝对 URL
定义:绝对 URL 是一个 完整的网址,它从根(协议)开始,包含了访问资源所需的 全部路径信息。
结构:通常包括 协议(如
http或https)、域名(如www.example.com)、端口号(可选)、路径(如/path/to/resource)以及查询字符串(可选)。示例:
https://www.example.com/path/to/resource.htmlhttps://www.example.com:8080/path/to/resource?query=param绝对 URL 使得资源的位置 独立于当前页面的位置,无论从哪里访问,都能准确定位到资源。
相对 URL
定义:相对 URL 是一个 不包含协议和域名 的 URL,它依赖于当前页面的 URL 来解析最终的资源位置。
结构:可以是简单的文件名,也可以包含目录结构,但不包含协议和域名。
示例:
index.html(指向当前目录下的index.html文件)images/logo.png(指向当前目录下的images目录中的logo.png文件)../css/style.css(指向上一级目录下的css目录中的style.css文件)相对 URL 的优势 在于它们使得网站结构更加灵活,尤其是在网站内部链接时,可以减少因网站结构变化 而需要更新的链接数量。
区别
- 完整性:绝对 URL 是完整的,而相对 URL 是依赖于当前页面 URL 的。
- 位置独立性:绝对 URL 不依赖于 当前页面的位置,相对 URL 则依赖。
- 使用场景:绝对 URL 常用于链接到 外部网站 或确保链接的明确性,相对 URL 常用于 网站内部资源链接。
- 灵活性:相对 URL 更灵活,因为它们可以随着网站结构的变化而自动调整。
- SEO(搜索引擎优化):绝对 URL 对搜索引擎更友好,因为它们提供了明确的资源位置。
在实际开发中,选择使用绝对 URL 还是相对 URL 取决于 具体的需求和上下文。
⑵ target 属性:所有链接的 打开位置(关键字;目标窗口或框架;新窗口/新标签页、当前窗口/框架、父框架、整个窗口/顶级框架)
base标签的target属性- 用于:指定文档中 所有链接打开时的 目标窗口或框架。
- 位置: 如果指定了 此属性,则此元素必须位于 具有值为 url 的属性 的任何其他元素 之前。
<base>标签的target属性会影响:页面中 所有 没有明确指定自身target属性的超链接(<a>标签)和表单(<form>标签)。它为这些元素 提供了 一个默认的 目标窗口或框架。
- 目标打开位置
target属性值- 通常是浏览器提供的 关键字
| 属性值 | 用于 |
|---|---|
❶ _blank | 在 新窗口 或 新标签页 打开链接。 |
❷ _self | 默认值。在 当前的窗口 或 当前框架 打开链接(默认值)。 |
❸ _parent | 在 父框架中 打开链接。如果没有父选项,则此选项的行为与 _self 相同。 |
❹ _top | 在 整个窗口 中打开链接,会清除所有框架。覆盖当前的窗口,加载到 顶级框架中(没有父元素的祖先的位置),如果没有父元素, 则此选项的行为与_self相同。 |
❺ framename | 在 指定的框架中 打开被链接文档(仅在使用框架时有效)。 |
-
注意事项
- ❶
<base>标签的target属性 可以被单个超链接或表单的target属性覆盖。 - ❷ 如果页面中使用了框架(frames),
_parent和_top的行为会有所不同。 - ❸ HTML5 不再支持
<frameset>,因此_framename_的使用场景较少。- 搭配
<iframe>标签的name属性时,仍可使用;这种方式特别适用于 需要将内容加载到特定<iframe>的场景。
- 搭配
- 通过合理使用
<base>标签的target属性,可以统一管理页面中链接的打开方式,减少重复代码。
- ❶
-
例:
base标签target属性的使用示例
<!DOCTYPE html>
<html>
<head>
<!-- 设置基础 URL 和链接打开的目标 -->
<base href="https://www.example.com/directory/" target="_blank">
<title>Base Tag Example</title>
</head>
<body>
<!-- 所有相对路径的链接都将在新窗口打开 -->
<a href="page1.html">Go to Page 1</a> <!-- 在新窗口打开 https://www.example.com/directory/page1.html -->
<a href="../contact.html">Go to Contact</a> <!-- 在新窗口打开 https://www.example.com/contact.html -->
<img src="images/logo.png" alt="Company Logo" /> <!-- 图片不会打开新窗口 -->
<script src="scripts/app.js"></script> <!-- 脚本不会打开新窗口 -->
</body>
</html>
- 在这个例子中,
base标签的target属性被设置为_blank,这意味着 文档中所有的链接(通过<a href>定义的)都将在新的浏览器标签页或窗口中打开。
- 例:把链接打开的目标位置,规定为 新窗口中打开
- base-
target="_blank" - 淘宝网 使用的就是这个,在新窗口中 打开链接
<base target="_blank" />,作为head的 最后一个元素;
- base-

- 【注意事项:
<base>标签的target属性 会影响哪些元素 ?】<base>标签的target属性会影响:页面中 所有 没有明确指定自身target属性的超链接(<a>标签)和表单(<form>标签)。它为这些元素 提供了一个默认的目标窗口或框架。
具体影响的元素:
<a>标签、<form>标签;❶ 超链接(
<a>标签)
<base>标签的target属性会影响所有没有明确指定target属性的<a>标签。- 例:
<head> <base target="_blank"> </head> <body> <a href="https://example.com">链接1</a> <!-- 会在新标签页打开 --> <a href="https://example2.com" target="_self">链接2</a> <!-- 会在当前页面打开 --> </body>链接1:会继承
<base>标签的target="_blank",在新标签页中打开。链接2:明确指定了
target="_self",因此会覆盖<base>标签的默认行为,在当前的标签页中 打开。
- ❷ 表单(
<form>标签)
<base>标签的target属性 同样会影响所有没有明确指定target属性的<form>标签。- 例:
<head> <base target="_blank"> </head> <body> <form action="submit.php"> <!-- 提交后会在新标签页打开 --> <input type="submit"> </form> <form action="submit2.php" target="_self"> <!-- 提交后会在当前页面打开 --> <input type="submit"> </form> </body>
- 第一个表单:会继承
<base>标签的target="_blank",提交后在新标签页中打开。- 第二个表单:明确指定了
target="_self",因此会覆盖<base>标签的默认行为,在当前标签中打开。
不受影响的元素
<base>标签的target属性不会影响以下元素:
❶ 非超链接或表单的元素
- 其他元素(如
<img>、<script>、<link>等)不受<base>标签的target属性影响。这些元素的行为由其自身的属性(如src或href)决定。❷ 明确指定了
target属性的元素
- 如果
<a>或<form>标签已经明确指定了target属性,则会覆盖<base>标签的默认行为。注意事项
❶ 全局性
<base>标签的target属性是全局性的,作用于整个文档。因此,建议谨慎使用,以避免意外行为。❷ 框架(Frames)
- 如果页面使用了框架(
<frameset>),target属性的行为可能会与预期不同。例如:
_parent会将目标加载到 父框架中。_top会将目标加载到 整个窗口中,清除所有框架。❸ HTML5 中的
<iframe>
- 如果页面中包含
<iframe>,target属性同样会影响<a>和<form>标签的目标窗口。- 在这种情况下,链接会在指定的
<iframe>中打开。例:
<a href="https://example.com" target="myFrame">链接</a> <iframe name="myFrame"></iframe>
- 总结
<base>标签的target属性主要用于:为页面中的超链接(<a>)和表单(<form>)提供默认的打开目标。- 它是一个全局设置,但会被单个元素的
target属性覆盖。其他元素(如<img>、<script>等)不受其影响。
5. ★ template 标签:隐藏的内容模板(客户端;不显示;可用 JS 动态插入 DOM 再显示)
<template>:内容模板元素 - HTML(超文本标记语言) | MDN
⑴ 什么 template 标签?
<template>/ˈtemplət/,模板 标签:是 HTML5 中引入的一个新元素,它用于定义一个 客户端的模板内容,这部分内容在页面加载时 不会被渲染,而是作为 隐藏的模板 保存在页面中。<template>标签的内容:可以包含 HTML 元素、文本和脚本;- 显示:它们在初始时 不会显示在页面上,直到被 JavaScript 动态地插入到文档的 DOM(Document Object Model)中 才会显示。
以下是
<template>标签的一些关键特点:
① 内容隐藏:
<template>中的内容在页面加载时 不会显示,直到被 JavaScript 显式地克隆和插入到 DOM 中。② 性能优化:由于
<template>中的内容在初始渲染时 不会被处理,它可以提高 页面加载性能,特别是当页面包含大量重复的 HTML 结构时。③ 客户端模板:
<template>可以用于实现 客户端模板系统,其中 JavaScript 可以动态填充数据 到预先定义的模板中。④ Web Components:
<template>标签是构建 Web Components/kəmˈpoʊnənts/ 不可或缺的一部分,它允许开发者 定义自定义元素的 Shadow DOM。⑤ 代码分离:
<template>标签可以将结构和内容分离,使得 HTML 结构更加模块化,易于维护。⑥ 延迟加载:对于不需要立即显示的内容,可以使用
<template>来延迟加载和渲染,从而优化页面性能。
- 下面是一个简单的
<template>使用示例:
<template id="myTemplate">
<div>
<h1>Hello, World!</h1>
<p>This is a template.</p>
</div>
</template>
<script>
// 当需要显示模板内容时,克隆并插入到 DOM 中
document.addEventListener('DOMContentLoaded', (event) => {
var template = document.getElementById('myTemplate');
var clone = template.content.cloneNode(true);
document.body.appendChild(clone);
});
</script>
- 在这个例子中,
<template>标签定义了一个包含标题和段落的模板。当页面加载完成后,JavaScript 会克隆这个模板的内容,并将其插入到文档的body中,这时模板中的内容才会显示在页面上。
⑵ 什么情况下需要使用 template 标签?
-
在 HTML 中,
<template>标签- 用于:定义一个模板,它是一个隐藏的容器,用于封装 HTML 文档中的一段内容,这段内容在页面加载时 不会被渲染或显示。
<template>标签的内容 只有在 JavaScript 被用来插入到文档的 DOM 中时才会显示。
-
以下是一些使用
<template>标签的情况: -
① 客户端模板:使用
<template>可以创建客户端模板,这些模板可以由 JavaScript 动态填充数据,实现页面内容的动态更新。<template id="myTemplate"> <div> <h1></h1> <p></p> </div> </template> <script> const template = document.querySelector('#myTemplate'); const instance = template.content.cloneNode(true); document.body.appendChild(instance); </script> -
② 性能优化:
<template>标签可以用于性能优化,因为它允许浏览器预先解析和缓存模板内容,这样在实际使用时可以减少解析时间。 -
③ 代码分割:在构建大型应用时,
<template>可以用于代码分割,将页面的不同部分定义在不同的模板中,按需加载。 -
④ Web Components:在使用 Web Components 构建自定义元素时,
<template>标签是定义组件内容的标准方式。<template> <style> :host { display: block; } </style> <div>自定义元素内容</div> </template> -
⑤ 避免页面闪烁:在页面加载时,使用
<template>可以避免内容的闪烁,因为模板内容在初始时不可见,只有在准备好之后才会被插入到 DOM 中。 -
⑥ 复用内容:
<template>可以用来定义可以复用的内容片段,例如,列表项或动态生成的对话框。 -
⑦ 延迟加载:对于不需要立即显示的内容,可以使用
<template>来延迟加载,减少初始页面加载时间。 -
⑧ 服务器端渲染与客户端渲染的结合:在某些情况下,服务器端渲染的内容可能需要与客户端渲染的内容结合,
<template>可以作为两者之间的桥梁。 -
总的来说,
<template>标签是一个非常有用的工具,它提供了一种 将标记和内容 封装起来的方法,以便在需要时 由脚本动态处理和插入到文档中。这使得<template>成为现代 Web 开发中一个强大的构建块。
6. basefont 标签:设置 默认 文本颜色、字体、字体大小 (已废弃)
- 基础 文本颜色、字体、 字体大小
- 使用
<basefont>基准字体 标签 [已废弃]- 基本 字体 : (
<basefont>)为其 父元素派生的其他元素 设置 默认字体、大小和颜色。 - 有了这个设置,就可以使用 字体
<font>元素来更改字体的大小,使之相对于基本大小有所不同。
- 基本 字体 : (
- 使用
- 已过时 不要使用: 这个特性已经过时了。
- 尽管它在一些浏览器中 仍然可以工作,但它的使用 是不被鼓励的,因为它可以 随时被删除。尽量避免使用它。
- 不要再使用 这个标签! 尽管在HTML 3.2中曾经(不严格地)标准化,但是 它并不被主流的浏览器所支持。
- 而且,不同的浏览器、甚至同一浏览器的 相邻版本,都没有使用 相同的实现方式; 实际上,使用这个标签 总是导致不确定的结果。
- 不要再使用 这个标签! 尽管在HTML 3.2中曾经(不严格地)标准化,但是 它并不被主流的浏览器所支持。
- 从HTML 4起,HTML 不再传递 样式信息(除
<style>元素和 所有元素的style属性 内容外)。
- 尽管它在一些浏览器中 仍然可以工作,但它的使用 是不被鼓励的,因为它可以 随时被删除。尽量避免使用它。
- 替代的 css: 应该使用 CSS 属性
- (如
font, font-family, font-size, ,color)来更改元素内容的 字体配置。
- (如
basefont标签的 浏览器支持- 只有 IE 支持
<basefont>基准字体 标签。 - 应该 避免使用该标签,浏览器 基本上 都不支持这个标签了.

- 只有 IE 支持
- 已废弃: HTML 与 XHTML 之间的差异
- 在 HTML 4.01 中,不赞成 使用
basefont元素; - 在 XHTML 1.0 Strict DTD 中,不支持
basefont元素。
- 在 HTML 4.01 中,不赞成 使用
6.1 basefont 标签 可选的属性
| 属性名 | 属性值 | 用于 |
|---|---|---|
| color | rgb(x,x,x) , #xxxxxx , colorname | 不赞成使用。请使用样式取代它。规定文档中的 默认文本颜色。 |
| face | font_family | 不赞成使用。请使用样式取代它。规定文档中的 默认字体。 |
| size | number | 不赞成使用。请使用样式取代它。规定文档中的 默认字体大小。使用数值或者相对值。数值值域为1~7,1最小,默认值为3。 |
- 示例1: 规定页面上的 默认 字体 颜色和 字号:
<head>
<basefont color="red" size="5" />
</head>
<body>
<h1>This is a header</h1>
<p>This is a paragraph</p>
</body>

♣ 结束语 和 友情链接
-
快速搜索:涉及知识点比较多,看过之后忘了很正常,想查询时,请按
Ctrl+F快速搜索关键字哦 (* ̄︶ ̄)。- 搜索后,多次按下 enter 键 ,或搜索框后的 上下箭头,就能在关键词之间快速跳转。
-
参考文档
- HTML 标签的规范文档:HTML Standard ;
- 如果学到某个知识点 觉得困惑和冲突,可以直接看 规范文档,这是最标准;进入后 Ctrl + F ,直接搜关键词 快速定位要看的知识点;
- W3School 教程;
- MDN HTML 教程;
- 内容分类 - HTML(超文本标记语言) | MDN ;
- Cache-Control - HTTP | MDN ;
- 元数据名称
- HTML 规范中定义的 标准元数据名称:标准 元数据名称 - HTML Standard(规范文档) ;
- 其他 惯用的元数据名称:MetaExtensions - WHATWG Wiki ;
- Referrer Policy 规范文档
- Referrer-Policy - HTTP | MDN
- Referer - HTTP | MDN
- MetaExtensions - WHATWG Wiki
- Schema.org 中文站
- HTML 标签的规范文档:HTML Standard ;
- 感谢:♥♥♥ 如果这篇文章 对您有帮助的话,可以点赞、评论、关注,鼓励下作者哦,谢谢小可爱们 ~╮( ̄▽ ̄)╭ ~
- 喜欢请收藏:喜欢本文 可收藏哦,方便快捷,会持续进行 ❶ 知识点更新 及 ❷ 修正错误。
- 欢迎指正: 如果发现 有需要 更正的细节问题,欢迎指正。
- 转载 请注明出处 ,Thanks♪(・ω・)ノ
- 作者:Hey_Coder
- 来源:CSDN
- 原文:
https://blog.csdn.net/VickyTsai/article/details/89422277 - 版权声明:本文为博主原创文章,转载请附上博文链接!


















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









