







 本文详细介绍了词语搭配的特征和检测方法,包括频率分析、均值方差法、假设检验(t检验、卡方检验、似然比)以及互信息计算。这些方法在术语抽取、句法分析、信息检索等领域有广泛应用,对于理解和识别语言中的固定搭配至关重要。
本文详细介绍了词语搭配的特征和检测方法,包括频率分析、均值方差法、假设检验(t检验、卡方检验、似然比)以及互信息计算。这些方法在术语抽取、句法分析、信息检索等领域有广泛应用,对于理解和识别语言中的固定搭配至关重要。
自然语言处理总复习(四)—— 词语搭配
一、介绍
(一)搭配的概念
- 搭配是由两个或两个以上的词所组成的语言表示,相当于说某些事情的习惯方式
- 两个或多个词序列,具有句法和语义单位的特性,并且它的准确无歧义的意思或含义往往不能直接由它的组成部分的意思和含义得出
(二)搭配的特征(标准)
1. 非复合构词
自然语言中,如果不能从各组成部分的意思推测出整体表述的意思,则称这个语言表述是非复合构词。
kick the bucket
international best practice
2. 不可替换性,不可更改性
white wine -> yellow wine?
as poor as church mouse / mice?
二、发现搭配的方案
(一)方案一:频率
1. 计数
不理想,绝大多数二元组都是功能词!
2. 简单的计量技术 + 简单的语言学知识
按词性进行过滤 (Justeson and Katz 1995) 或使用功能词的停用词表
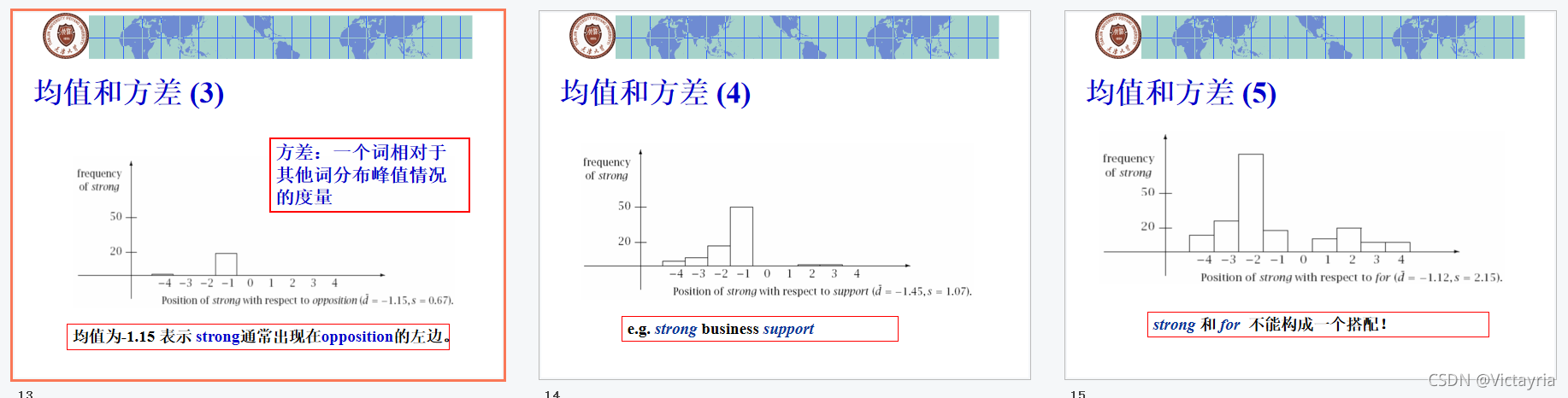
(二)方案二:均值和方差


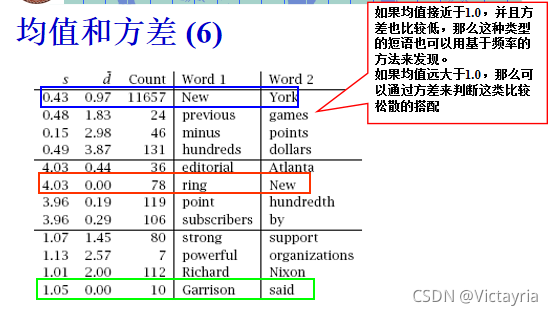
- 如果均值接近于1.0,并且方差也比较低,那么这种类型的短语也可以用基于频率的方法来发现。
- 如果均值远大于1.0,那么可以通过方差来判断这类比较松散的搭配。
均值和方差方法的应用
- 术语抽取( Smadja,1993)
- 自然语言生成(Smadja and McKeown, 1990)
对于组成Knock/door来说,它可能并不是一个我们想要的严格术语意义上的搭配,但是对于文本生成来说,它却可能是非常有用的。 - 句法分析
含自然搭配的分析结果可被优先选择 - 信息检索
用户查询和文档的相似度以搭配来确定,检索准确率将提高
(三)方案三:假设检验
1. 假设检验的作用和目的

2. 关键
定义零假设: 两个词语的组合的高频出现是一种偶然现象。
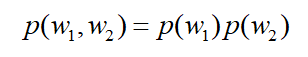
3. 检验方法
(1)t 检验


1)将 t 检验应用到词语搭配识别上
应用方法: 把一个文本语料库看成N个二元组的长序列,如果我们感兴趣的二元组出现,则其计数值加1,不出现则为0(二项式分布)
常见的分布统计检验,用我们给予假设H0所求得的w1与w2同时出现的概率。如果实际样本的频率与这个接近,并且t值在置信区间内即为假设H0成立。
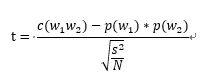
2)t 检验不适用的情况
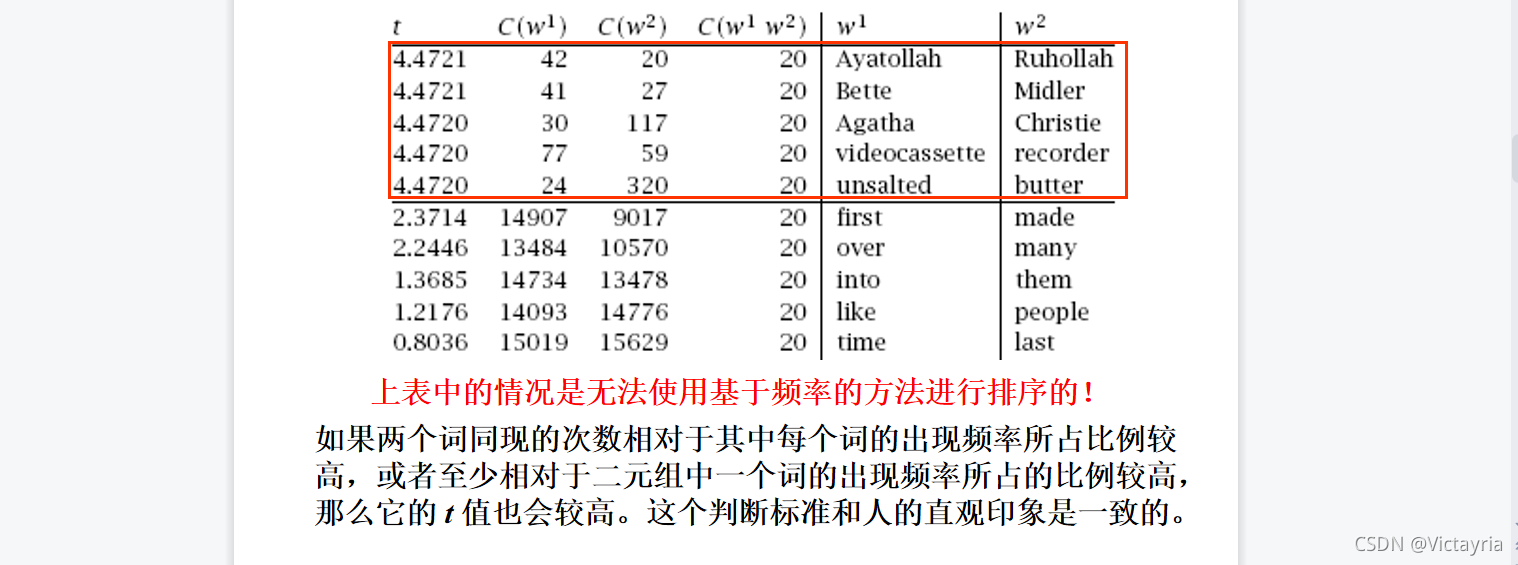
3)t 检验用于区分近义词
a) 问题描述:
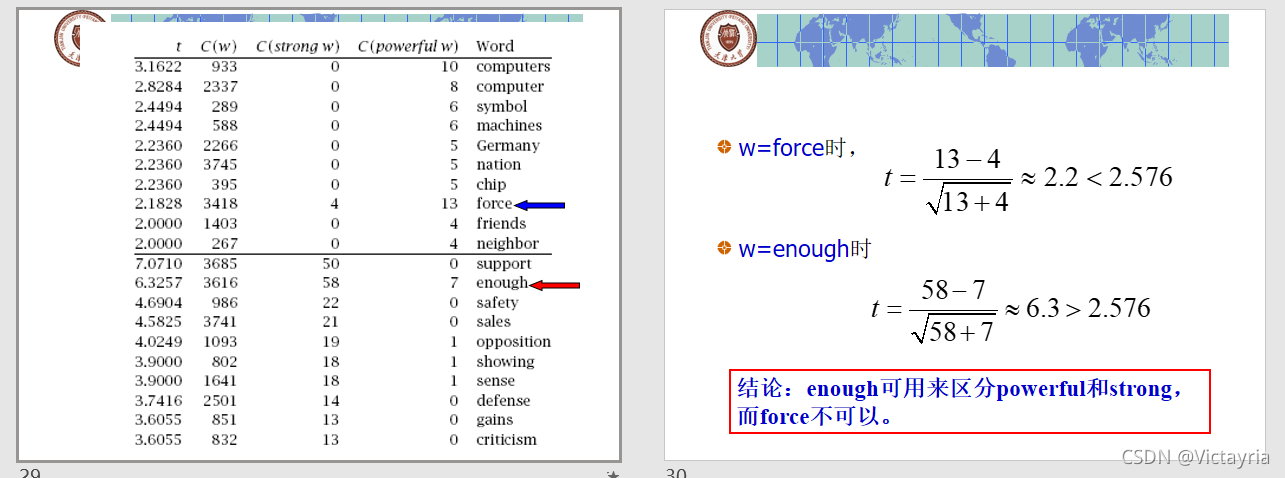
寻找一些词,这些词与另两个意义相近的词的同现模式可以很好地区分后两者之间的差别。例如,在辞典编纂中,我们希望找到这样的一些词,可以很好的区分strong和powerful的不同。
b) 方案:利用 t 检验
随机变量为:
x
1
−
x
2
x_1 - x_2
x1−x2
假想期望值:
μ
=
0
\mu=0
μ=0(零假设:两个词的平均差异为0)
两个独立的随机变量差异的方差和 = 它们单独方差的和
因此有如下 t 统计量表达式:
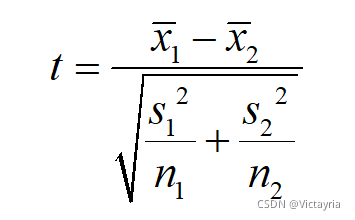
其中
x
1
=
1
N
∑
x
1
i
=
C
(
x
1
)
N
x
2
=
1
N
∑
x
2
i
=
C
(
x
2
)
N
x_1 = \dfrac{1}{N}\sum x_{1i}=\dfrac{C(x_1)}{N} \\ x_2 = \dfrac{1}{N}\sum x_{2i}=\dfrac{C(x_2)}{N}
x1=N1∑x1i=NC(x1)x2=N1∑x2i=NC(x2)
当我们在同一个预料库中比较两个词的时候,
n
1
n_1
n1和
n
2
n_2
n2是相同的,因此可以进行简化。

c) 举例
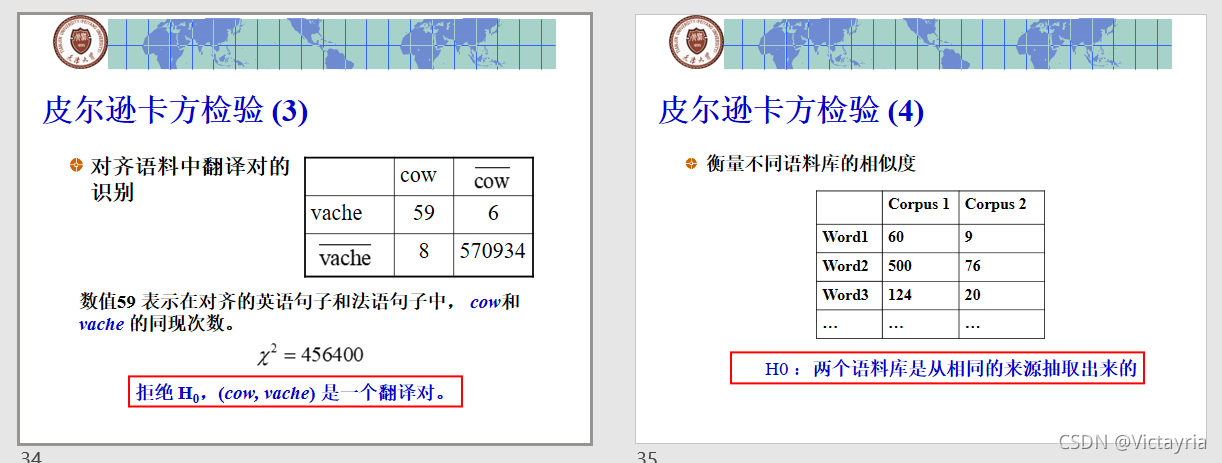
(2)皮尔逊卡方检验
t 检验假设了数据的先验分布为正态分布,而一般情况下并非正态分布。
卡方检验不要求数据的正态分布特性。
1)卡方检验的概念和作用
比较观测频率和期望频率,以验证独立性。如果差别很大,则可以拒绝独立的零假设。
2)卡方检验的一般公式
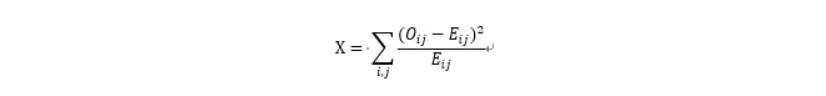
其中O是观察值,E为期望值。
比如在假设H0的情况下,w1,w2单独出现,同时出现,同时不出现的概率都应该和整个文本w1,w2有关,而且可以算出期望值。
3)举例和计算方法

4)皮尔逊卡方检验的应用
(3)似然比
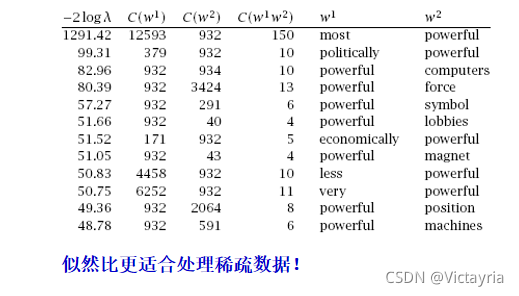
1)似然比的概念
现有的N个样本中我们可以得出对一些参数的似然函数。其中根据假设H0,H1我们可以得到似然函数L0,L1。
似然比就是,L0/L1。似然比越大表示,H0(原假设)越可信。

2)似然比的特点
- 更适合处理稀疏数据
3)似然比的计算


(四)方案四:互信息
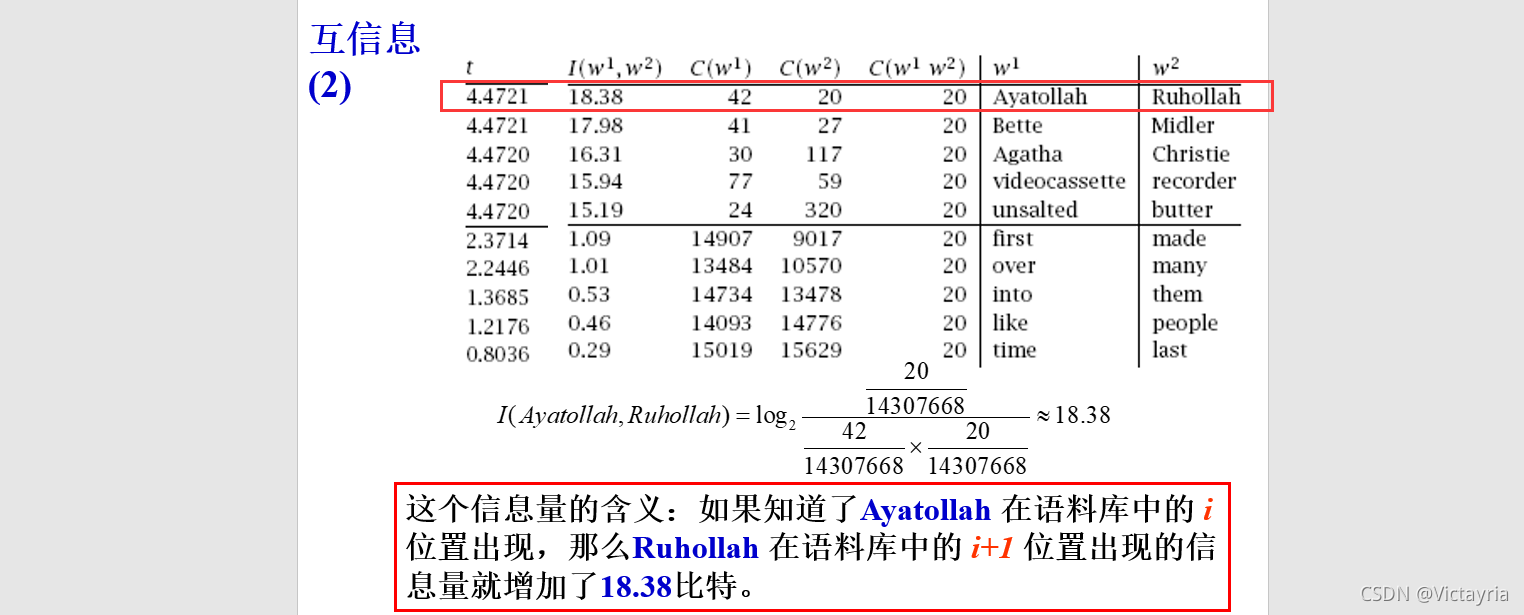
1. 互信息的概念和计算公式
1)互信息
在已知 y 情况下,获得的有关 x 的信息量。
2) 计算公式及举例

2. 问题和不足
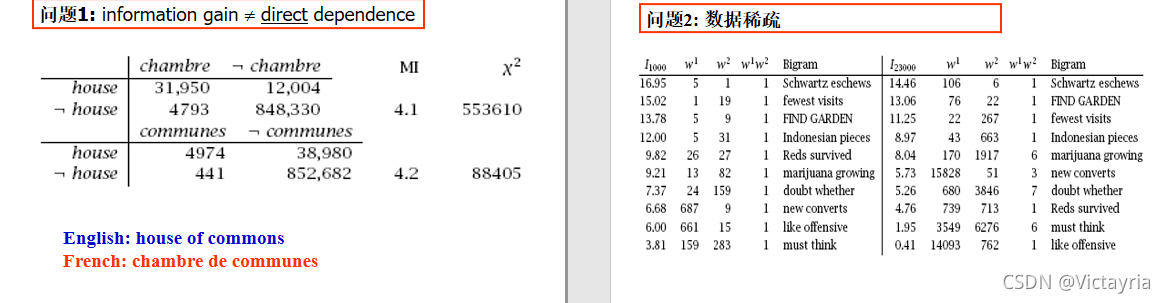
- 当互信息值较低的时候,两个词语的依赖关系仍然有可能很高
- 数据稀疏的情况对互信息非常不友好,通常当频数高于3的词才能有效
3. 互信息总结

词语搭配的应用



















 3894
3894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











