







DAY 29 复习日
知识点回顾
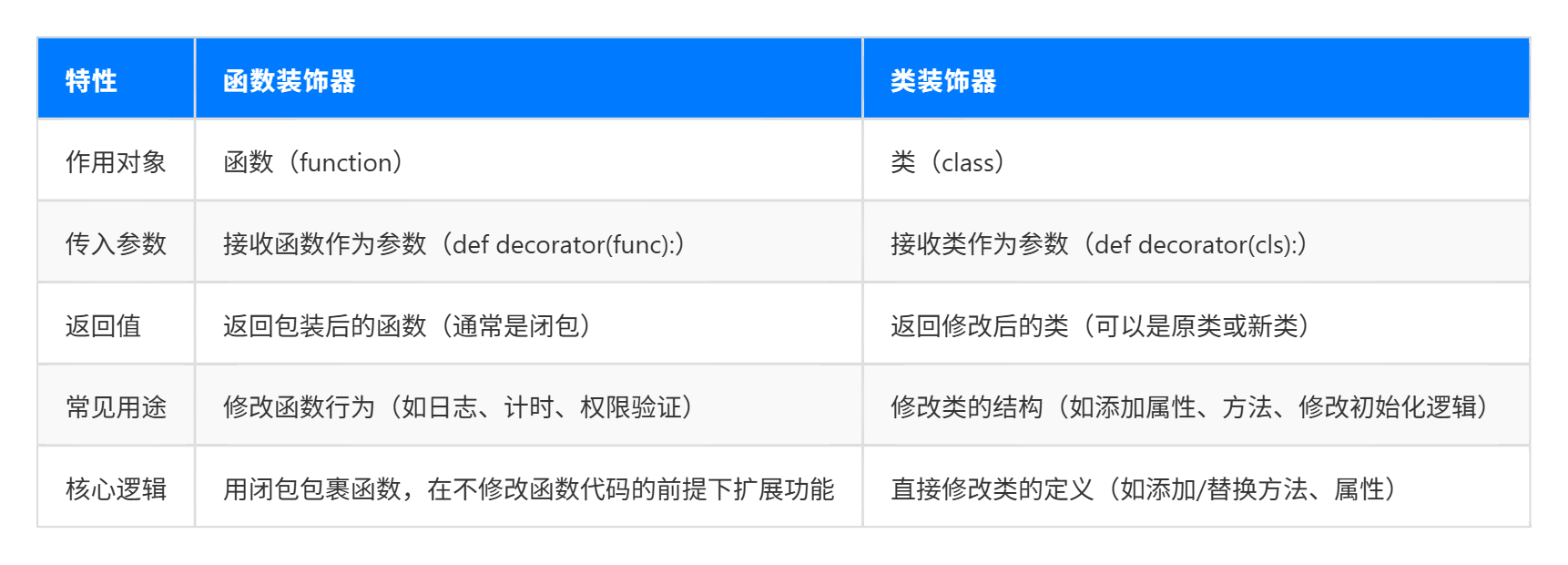
- 类的装饰器
- 装饰器思想的进一步理解:外部修改、动态
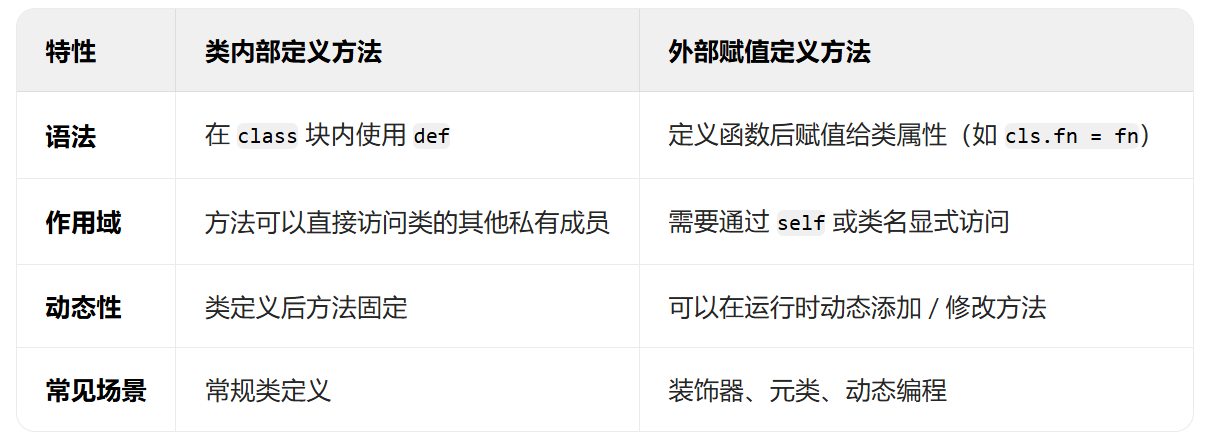
- 类方法的定义:内部定义和外部定义
作业:复习类和函数的知识点,写下自己过去29天的学习心得,如对函数和类的理解,对python这门工具的理解等,未来再过几个专题部分即将开启深度学习部分。
# 定义类装饰器:为类添加日志功能
def class_logger(cls):
# 保存原始的 __init__ 方法
original_init = cls.__init__
def new_init(self, *args, **kwargs):
# 新增实例化日志
print(f"[LOG] 实例化对象: {cls.__name__}")
original_init(self, *args, **kwargs) # 调用原始构造方法
# 将类的 __init__ 方法替换为新方法
cls.__init__ = new_init
# 为类添加一个日志方法(示例)
def log_message(self, message):
print(f"[LOG] {message}")
cls.log = log_message # 将方法绑定到类,这是一种将外部函数添加为类的属性的方法
return cls
@class_logger
class Teacher:
def __init__(self,name,age,lesson):
self.name = name
self.age = age
self.lesson = lesson
def teach(self):
print(f"{self.name} 教 {self.lesson}")
def __str__(self):
return f"{self.name} {self.age} {self.lesson}"
teacher1 = Teacher("李老师",30,"数学")
teacher1.teach()
teacher1.__str__()
teacher1.log("这是装饰器添加的日志方法") # 调用装饰器新增的方法经历了一个月的学习,对于传统机器学习和python代码基础有了一定的了解和掌握,也在kaggle数据平台做了实战演练,虽很粗糙但也是自己所学。拿到数据先认识数据,对数据预处理(清洗异常值,填补空值,独热/标签编码,标准/归一化),处理数据集不平衡,特征筛选/降维,划分数据集,代入模型预训练,调优/寻找最优超参数,混淆矩阵打印预测结果对比,shap可解释性分析。也学会一些聚类增加特征的方法。期待下面深度学习的学习时光。

















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









