










AndrewNg - 线性回归
经典的Ng房屋问题,给定数据集如下:
房屋面积20141600240014163000⋮房间数量33324⋮价格400220369232540⋮
x∈R2 , x(i)1 表示房屋面积, x(i)2 表示房间数量,首先我们会估计 y 是
hθ(x)=∑i=1nθixi=θTx,
其中 n 为输入向量中特征个数(不包含
J(θ)=12∑i=1m(hθ(x(i))−y(i))2
最小均方差算法( Least mean square)
我们的目标是选取可以使 J(θ) 最小的的 θ 。为了得到最终的 θ ,一般我们会给 θ 赋上初值,通过相关的算法对 θ 迭代求值,知道 θ 收敛。这里提及的是梯度下降法,迭代式如下:
θj:=θj−α∂∂θjJ(θ).
当然, θ0,...,θn 是同时迭代更新的。这里的 α 我们是用来控制学习速率的参数。当然写代码的时候式子中的偏导还得再求一下,为了计算方便起见,假设我们先只有一个样本 (x,y) ,即 J(θ) 中的求和符号先忽略一下:
∂∂θjJ(θ)=∂∂θj12(hθ(x)−y)2=(hθ(x)−y)∂∂θj(hθ(x)−y)=(hθ(x)−y)∂∂θj(∑i=0nθixi−y)=(hθ(x)−y)xj
所以对于一个训练样本来说,迭代式会变成:
θj:=θj+α(y(i)−hθ(x)(i))x(i)j.
要将上边的迭代式拓展到含 m 样本的训练集上,我们一般用到的有两种修改方法,其一如下:
很明显这个算法每一次的迭代都要遍历整个训练集,所以起名叫 批量梯度下降。我们说沿着梯度方向总能够找到局部最优解(说明问题的优化与初值有关),而且我们这里的问题还是一个凸二次函数,说明它只有一个局部最优解就是全局最优解。
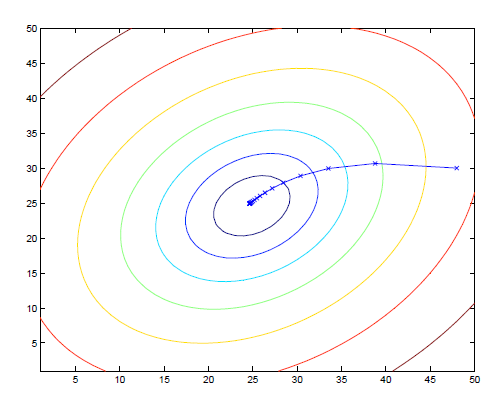
可以看到图中是初值为(48,30)时梯度下降法的迹。与批量梯度下降法对应, 随机梯度下降法相对来说更适合比较大的数据集:
Loopuntilconvergence:{for i to m{θj:=θj+α(y(i)−hθ(x)(i))x(i)j(for every j).}}
相比于批量梯度下降法每次都要遍历训练集才能更新 θ 来说,随机梯度下降立杆见影,每一步都会对 θ 有一个调整,不过其最后只能接近最优而到不了真正的最优。
下节预告
换一种方法,用公式直接推导出 θ 的值,规范形方程(normal equations),简单粗暴!















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









