






数据分析-统计学知识Part1
一、随机变量和随机实验
1.随机试验是在相同条件下进行大量重复观测
· 特点:1.试验前不能断定产生的结果;2.能指出全部可能出现的结果;3.重复实验的结果以随机方式出现。
· 例子:抛硬币
2.随机变量是随机试验的结果。
例子:单次抛硬币结果,硬币正面朝上的次数,单次优惠券使用情况,优惠券转化率都可用X表示
二、样本和随机变量
样本:每次随机试验的结果,“观测值”,随机变量用X 表示,样本用x1,x2表示。
例子:使用优惠券用户xi=1,没有使用则xi=0
随机变量根据分布来区分不同。
三、随机变量分类
随机变量分为两类:连续型、离散型
离散型:可数(不是有限!)
例子:APP每小时用户数量,可按次序列举
连续型:不可数
例子:概率【0,1】,不是无限,无法依次取出
四、离散型随机变量的分布
1.伯努力分布(0-1分布)
每次实验只有非A即B的结果,p表示事件A发生,1-p表示事件B发生。
例子:抛硬币P(X=1)=0.5
例子:优惠券转化率p, P(X=1)=p
2.二项分布 (n重伯努利分布)
n个独立重复的伯努利分布称为n重伯努利分布,1.每个伯努利发生概率均为p;2.各实验结果相互独立
例子:发出1000张优惠券,有x张被使用的概率为:
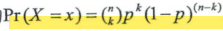
3.泊松分布
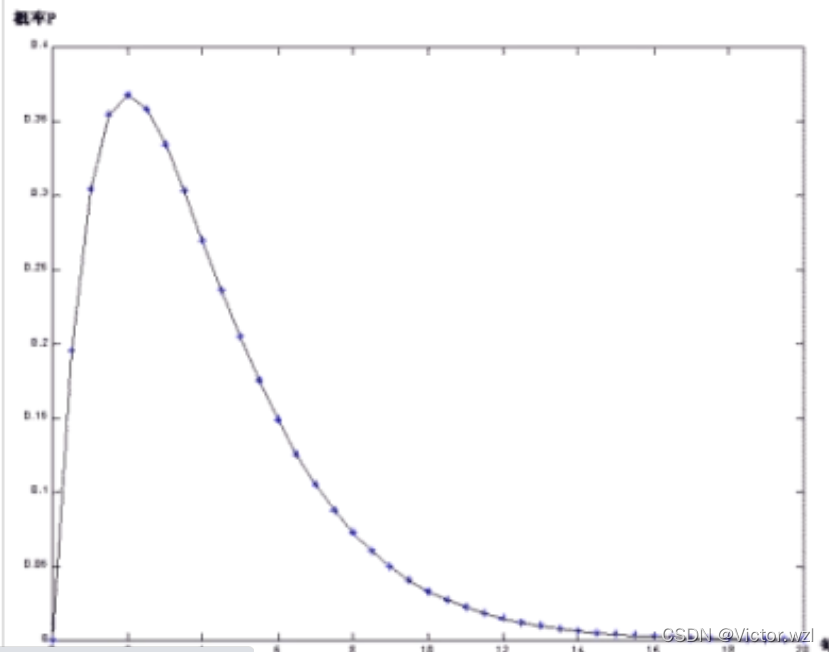
一种离散概率分布,描述单位时间或空间内随机事件发生的次数
例子:1.某APP在单位时间内访问的人数。2.如果一家音像店平均每周五晚上有400名顾客,那么在任何一个周五晚上有600名顾客进来的概率是多少?
分布律为: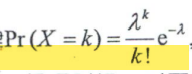
λ表示单位时间(或单位面积)内随机事件平均发生的次数。
使用场景:对于某些没有提前了解过的实验,可用泊松分布初步描述
五、连续型随机变量的分布
PDF和CDF
通常用F(x)表示连续型随机变量的分布函数,F(x)=Pr(X<=x),所以F(x)也称为累积函数分布 (CDF)
f(x)称为概率密度函数 (PDF),F(x)=
∫
−
∞
x
f
(
x
)
d
x
\int_{-\infty}^{x}f(x)dx
∫−∞xf(x)dx
1.均匀分布
概率密度函数为: f ( x ) = 1 b − a , x 在 [ a , b ] f(x)={1 \over b-a}, x在[a,b] f(x)=b−a1,x在[a,b]
2.正态分布
概率密度函数:
f
(
x
)
=
1
(
2
π
σ
)
e
−
(
x
−
μ
)
2
2
σ
2
f(x)={1 \over \sqrt(2 \pi \sigma)}e^{-(x-\mu)^2 \over 2 \sigma^2}
f(x)=(2πσ)1e2σ2−(x−μ)2
例子:KaTeX parse error: Undefined control sequence: \sigam at position 2: 3\̲s̲i̲g̲a̲m̲方法,用于数据质量监控,随着数据量的增加,其均值分布会逼近正态分布,即为中心极限定理
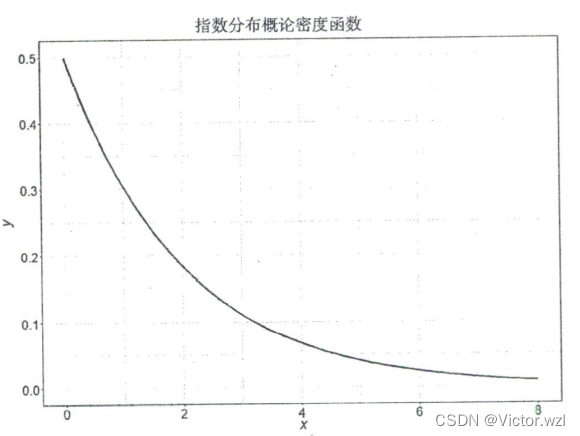
3.指数分布
描述泊松分布事件之间的时间的概率分布,即事件以恒定平均速率连续且独立发生的过程。
概率密度函数:
f
(
x
)
=
λ
e
λ
x
(
x
>
0
)
f(x)=\lambda e^{\lambda x}(x>0)
f(x)=λeλx(x>0),其中
λ
表
示
泊
松
分
布
里
单
位
事
件
内
发
生
某
件
事
件
的
次
数
\lambda表示泊松分布里单位事件内发生某件事件的次数
λ表示泊松分布里单位事件内发生某件事件的次数
特点 : 无记忆性,即
P
(
X
>
t
+
s
∣
X
>
t
)
=
P
(
X
>
s
)
P(X>t+s|X>t)=P(X>s)
P(X>t+s∣X>t)=P(X>s)
许多电子产品的寿命分布一般服从指数分布。如果T是某一元件的寿命,已知元件使用了t小时,它总共使用至少小时的条件概率,与从开始使用时算起它使用至少s小时的概率相等。














 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









