







关联规则
关联规则又称为:Association Rules,旨在表达:如果一个消费者购买了产品A,那么他有多大几率会购买产品B?
故事背景:沃尔玛在分析销售记录时,发现啤酒和尿布经常一起被购买,于是他们调整了货架,把两者放在一起,结果真的提升了啤酒的销量。
原因解释:爸爸在给宝宝买尿布的时候,会顺便给自己买点啤酒?
沃尔玛是最早通过大数据分析而受益的传统零售企业,对消费者购物行为进行跟踪和分析。
对于关联规则,引入下面三个概念:支持度、置信度和提升度
支持度
支持度:是个百分比,指的是某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的频率越大。
| 订单编号 | 购买的商品 |
|---|---|
| 1 | 牛奶、面包、尿布 |
| 2 | 可乐、面包、尿布、啤酒 |
| 3 | 牛奶、尿布、啤酒、鸡蛋 |
| 4 | 面包、牛奶、尿布、啤酒 |
| 5 | 面包、牛奶、尿布、可乐 |
如上表所示,可以计算出:
“牛奶”的支持度=4/5=0.8
“牛奶+面包”的支持度=3/5=0.6。
置信度
置信度:是个条件概念,指的是当你购买了商品A,会有多大的概率购买商品B
| 订单编号 | 购买的商品 |
|---|---|
| 1 | 牛奶、面包、尿布 |
| 2 | 可乐、面包、尿布、啤酒 |
| 3 | 牛奶、尿布、啤酒、鸡蛋 |
| 4 | 面包、牛奶、尿布、啤酒 |
| 5 | 面包、牛奶、尿布、可乐 |
如上表所示,可以计算出:
置信度(牛奶→啤酒)=2/4=0.5
置信度(啤酒→牛奶)=2/3=0.67
提升度
提升度:商品A的出现,对商品B的出现概率提升的程度
| 订单编号 | 购买的商品 |
|---|---|
| 1 | 牛奶、面包、尿布 |
| 2 | 可乐、面包、尿布、啤酒 |
| 3 | 牛奶、尿布、啤酒、鸡蛋 |
| 4 | 面包、牛奶、尿布、啤酒 |
| 5 | 面包、牛奶、尿布、可乐 |
如上表所示,可以引发一个思考,如果我们单纯看置信度(可乐→尿布)=1,也就是说可乐出现的时候,用户都会购买尿布,那么当用户购买可乐的时候,就需要推荐尿布么?
这时候就需要引入提升度了,我们有以下公式:
提升度(A→B)=置信度(A→B)/支持度(B)
提升度的三种可能:
- 提升度(A→B)>1:代表有提升;
- 提升度(A→B)=1:代表有没有提升,也没有下降;
- 提升度(A→B)<1:代表有下降
对于提升度,如果还没有完全理解,可以换个通俗易懂的概念进行解释:对于itemA和itemB,
- 如果itemB单独出现的效果比itemA+itemB一起出现的效果好,这时提升度<1;
- 如果itemA+itemB一起出现的效果比itemB单独出现的效果好,这时提升度>1
Apriori
有了以上这三个概念,我们可以引入Apriori算法,所谓Apriori算法就是查找频繁项集(frequent itemset)的过程。
- 频繁项集:支持度大于等于最小支持度(Min Support)阈值的项集。
- 非频繁项集:支持度小于最小支持度的项集
我们把上面案例中的商品用ID来代表,牛奶、面包、尿布、可乐、啤酒、鸡蛋的商品ID分别设置为1-6。如下图所示
| 订单编号 | 购买的商品 |
|---|---|
| 1 | 1、2、3 |
| 2 | 4、2、3、5 |
| 3 | 1、3、5、6 |
| 4 | 2、1、3、5 |
| 5 | 2、1、3、4 |
如下图所示,先计算k=1项的支持度,假设最小支持度=0.5,那么Item4和6不符合最小支持度的,不属于频繁项集。
| 商品项集 | 购买的商品 |
|---|---|
| 1 | 4/5 |
| 2 | 4/5 |
| 3 | 5/5 |
| 4 | 2/5 (剔除) |
| 5 | 3/5 |
| 6 | 1/5 (剔除) |
在这个基础上,我们将商品两两组合,得到k=2项的支持度,筛选掉小于最小值支持度的商品组合。
| 商品项集 | 购买的商品 |
|---|---|
| 1,2 | 3/5 |
| 1,3 | 4/5 |
| 1,5 | 1/5 (剔除) |
| 2,3 | 4/5 |
| 2,5 | 2/5 (剔除) |
| 3,5 | 3/5 |
将商品进行K=3项的商品组合,筛选掉小于最小值支持度的商品组合,可以得到:
| 商品项集 | 购买的商品 |
|---|---|
| 1,2,3 | 3/5 |
| 2,3,5 | 2/5(剔除) |
| 1,2,5 | 1/5 (剔除) |
| 1,3,5 | 2/5 (剔除) |
最终的得到K=3项的频繁项集{1,2,3},也就是{牛奶、面包、尿布}的组合。
总结Apriori算法的流程:
- Step1,K=1,计算K项集的支持度;
- Step2,筛选掉小于最小支持度的项集;
- Step3,如果项集为空,则对应K-1项集的结果为最终结果。
- 否则K=K+1,重复1-3步。
Example
我们通过kaggle上面的一个超市购物篮的数据集,进行Apriori分析。
==>数据链接
该数据集为rawdata,没有记录TransactionID和列名,我们需要做的是统计交易中的频繁项集和关联规则。
import numpy as np
import pandas as pd
#读取数据
data = pd.read_csv('./Market_Basket_Optimisation.csv',header = None)
#查看原始数据
data
#将原始数据做数据清洗,剔除空值,将数据转成文本str格式
corpus = pd.DataFrame(columns = ['items'])
for row in range(data.shape[0]):
tmp = [i for i in data.iloc[row,:].values if str(i) != 'nan']
corpus.loc[row,'items'] = ','.join(tmp)
corpus

#将items进行multi-hot
corpus = corpus['items'].str.get_dummies(sep=',')
corpus
#导入关联规则的包,输出频繁项集和关联规则
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
#此处设置最小支持度为0.02,可以根据需求进行调参
frequent_itemsets = apriori(corpus, min_support=0.02, use_colnames=True)
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=0.5)
#查看频繁项集
frequent_itemsets
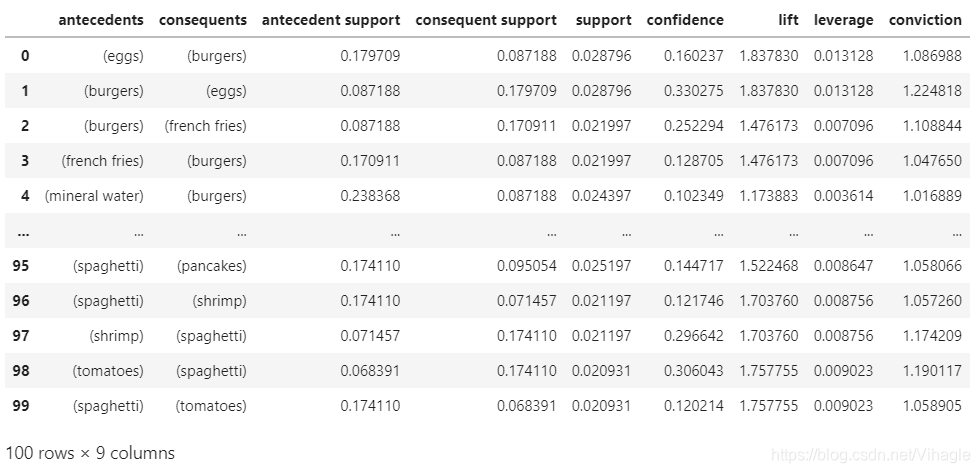
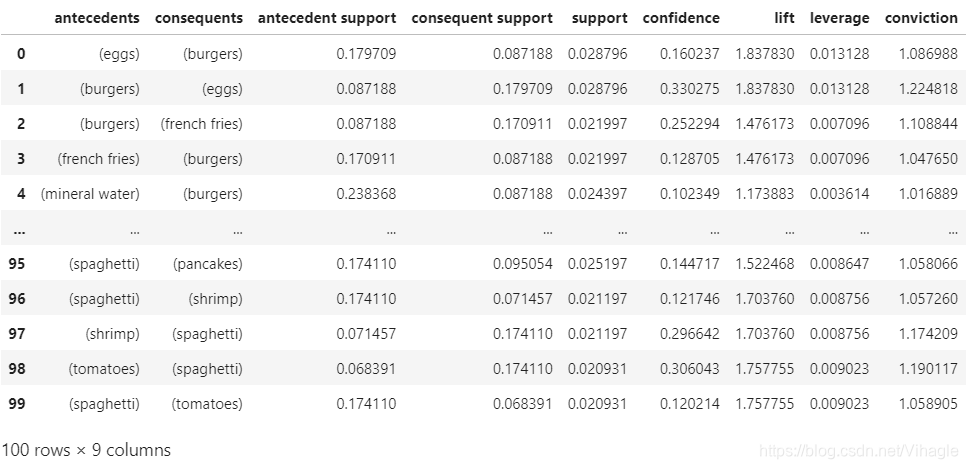
#查看关联规则
rules
#按照提升度进行排序展示
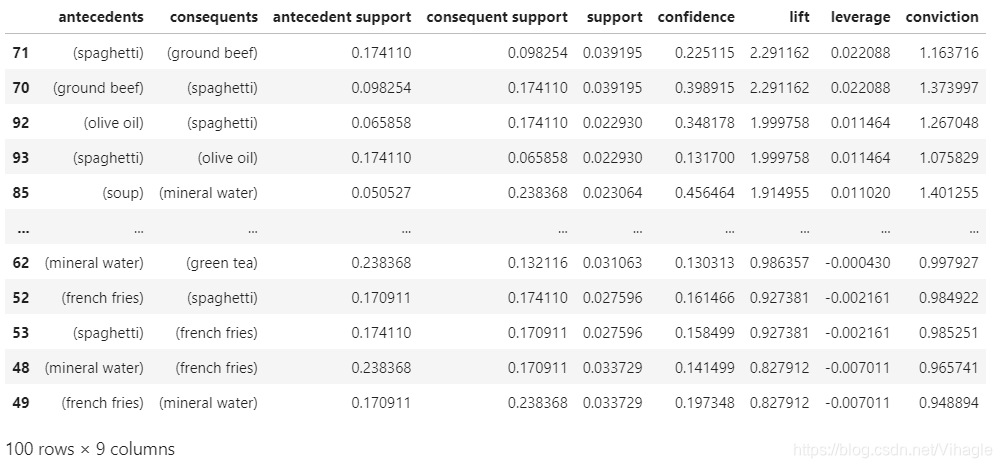
rules_lift_rank = rules.sort_values(by = ['lift'],ascending=False)
rules_lift_rank
一般意大利面的购买,能够提升橄榄油/碎牛肉的购买率,反之亦然。
#按照置信度进行排序展示
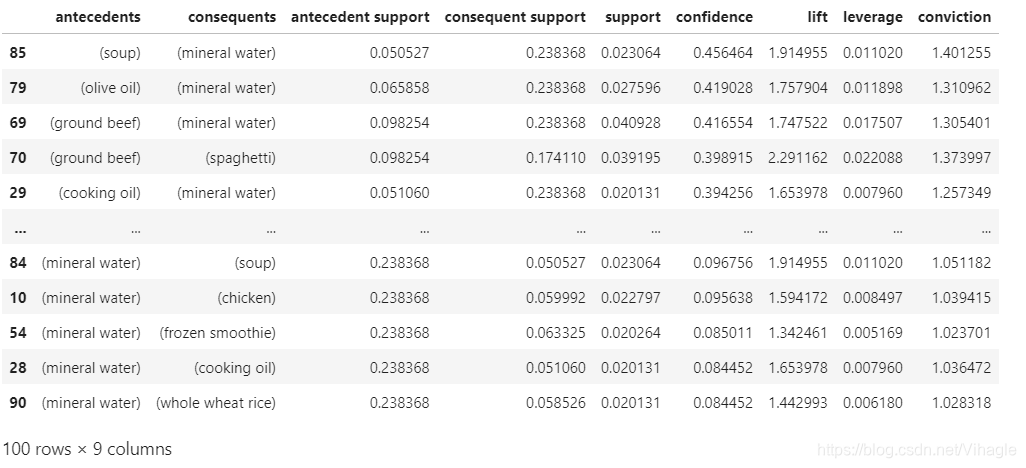
rules_confidence_rank = rules.sort_values(by = ['confidence'],ascending=False)
rules_confidence_rank
大多数用户购买商品的同时,也会选择购买矿泉水。The combinations of(item,mineral wate)have high confidence
#按照支持度(k=2)进行排序展示
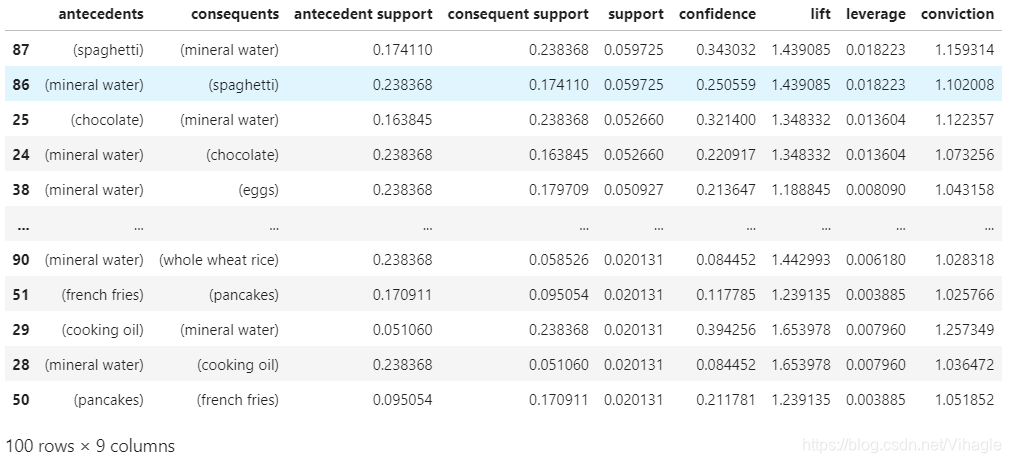
rules_support_rank = rules.sort_values(by = ['support'],ascending=False)
rules_support_rank
可以看出矿泉水的支持度是最高的,占购物篮总量的23%。 The mineral wate has highest support.
总结
Q:关联规则与协同过滤的区别?
A:
- 关联规则是基于transaction,而协同过滤基于用户偏好(评分)。
- 商品组合使用的是购物篮分析,也就是Apriori算法,协同过滤计算的是相似度。
- 关联规则没有利用“用户偏好”,而是基于购物订单进行的频繁项集挖掘。
在推荐系统中,两种推荐算法的思考维度不同,很多时候,我们需要把多种推荐方法的结果综合起来做一个混合的推荐。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











