







一、概要
什么是因果推断?
在讲因果推断之前,我们在AI聊的更多的是相关性(correlation),对于相关性,我们可以有如下定义:
- 在观测到的数据分布中,变量X与输出Y相关,如果我们观测到X的分布,就可以推断出Y的分布
在相关性在AI界辗转多年后,又提出了因果性,也就是因果推断(Causal Inference),对此也有如下定义:
- 在改变变量X后,输出Y随着这种改变也随之变化, 则说明了X对Y的因果性
因果推断的必要性
与其说因果推断的必要性,不如切入到目前AI界的碰壁点讲起,可以从以下两点分析:
场景限制
- 许多应用场景无法直接做A/B test,如医药实验/政策落实等。这时候就需要因果推断来模拟场景的实验性。
- 即使有A/B test的可能,企业也很难承担实验成本;另一方面,用户体验感也会变得不好。
技术限制
- 现有机器学习都是基于相关关系去进行无限拟合(即使是深度学习),模型在上线时会受到不同因素而导致不稳定、泛化能力差。
- 现有机器学习普遍缺乏可解释性,即使有,也非常有限。
- 仅仅依靠模型对未来结果的预测,无法提供有效的行动策略选项,就会导致预测和决策之间存在巨大的差异。
因果推断的应用场景

- 用户福利/补贴/优惠券发放(左上)
- 用户广告投放(右上)
- 用户折扣发放(左下)
- 广告渠道投放(右下)
二、原理
框架
在讲背后原理前,先放个目前因果推断各种工具的大框架

因果估计器
这次我们分析一下上图框架中间的因果效应评估(Causal Effect Estimation),因为背后会运用不同的估计器estimator,估计器主要分为以下八个大模块,每个模块的估计器都对应着不同的算法逻辑和思路。
- Meta Learner
- Double Mahine Learning
- Doubly Robust
- Causal Tree
- Deep IV
- Nonparametric IV
- Approximation Bound
- Rscore
目前比较主流的估计器是Meta Learner,而对应Meta Learner又可以分为以下三种策略:
S-Learner
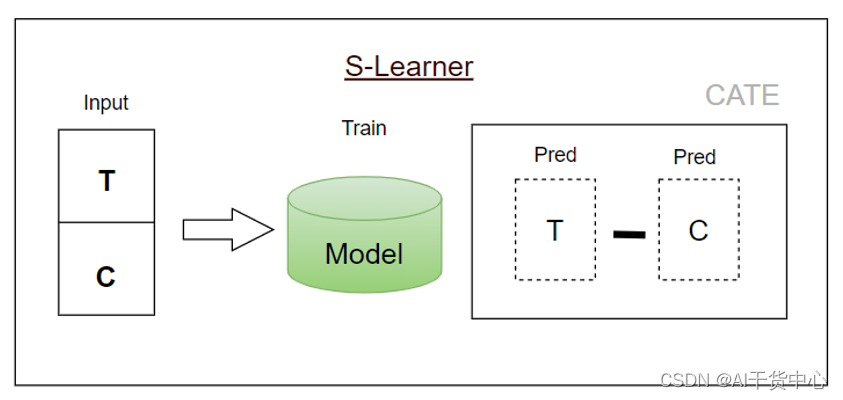
- 训练:通过现有模型对干预和不干预的数据直接训练建模(干预措施作为特征存在)
- 预测:分别对用户被干预和不被干预的概率P进行预测并相减,得到因果值
- 优点:只依赖于一个模型,避免多模型带来的累计误差
- 缺点:没有对Uplift直接建模,而是间接做减法得到,需要额外的特征工程
T-Learner
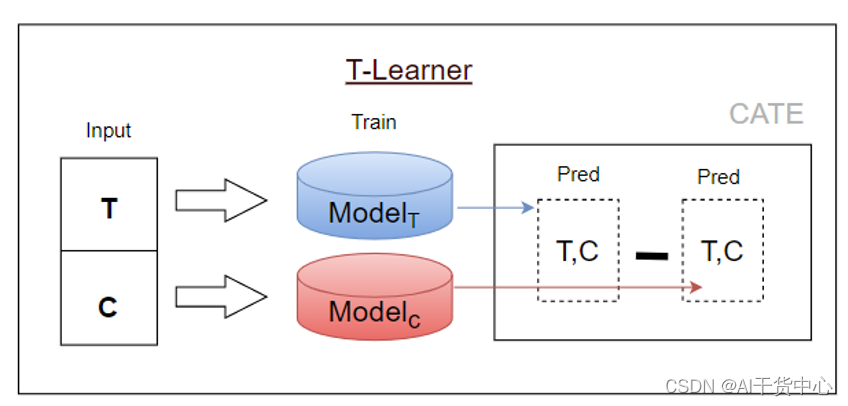
- 训练:通过现有模型对干预和不干预的数据分开进行训练建模(不存在干预特征)
- 预测:通过两个模型的预测值计算Uplift
- 优点:无需额外的特征工程
- 缺点:存在双模型带来的累计误差,当干预组和对照组之间的数据量差异较大时,对结果影响比较大
X-Learner
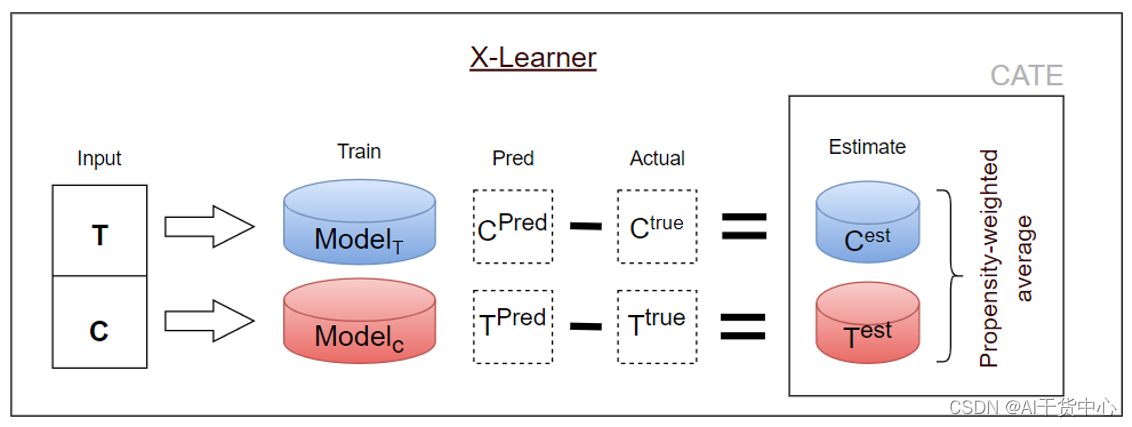
- 训练:先对干预和不干预的数据分开进行建模,然后用干预组的模型预测不干预的数据,用不干预的模型预测干预的数据,最后计算两者预测值之差,将该差值作为新的拟合目标,分别构建两个新模型
- 预测:两个新模型分别预测出差值,并通过加权方式求出Uplift值
- 优点:解决了对照组和实验组之间数据不平衡的问题
- 缺点:多模型带来了误差的累计,模型增加,计算成本高
三、案例分享
案例背景
- 一家销售软件的初创公司向其客户提供两项激励措施:技术支持(Tech Support)和折扣(Discount)
- 该公司拥有2000名客户的这两项投资的历史数据,以及这些客户在投资一年后产生的收入(Revenue)
- 他们希望使用这些数据来了解现有客户/新客户的最佳激励政策,以最大限度地提高投资回报率ROI
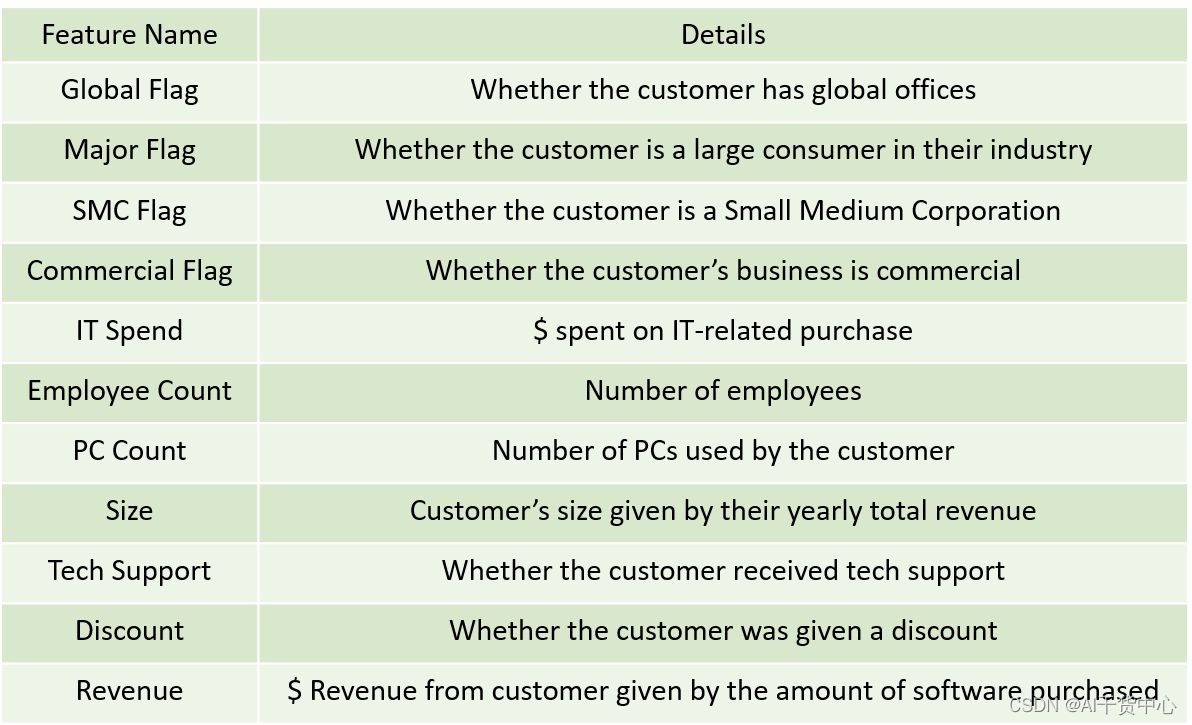
数据情况
代码
将该企业的历史数据,输入到Estimator模型,并指定Treatment和Outcome
from ylearn import Why
import numpy as np
import pandas as pd
import warnings
import matplotlib.pyplot as plt
import seaborn as sns
from imblearn.over_sampling import SMOTE
import xgboost as xgb
from ylearn.estimator_model.meta_learner import SLearner, TLearner, XLearner
warnings.filterwarnings("ignore")
treatment = ['Tech Support','Discount']
outcome = 'Revenue'
instrument = 'Size'
adjustment = [i for i in data.columns[:-2]]
why = Why(random_state=2022)
why.fit(data, outcome, treatment = treatment, instrument = instrument)
Estimator会对历史数据进行训练预估,并得到不同Treatment的因果效应值Causal Effect
下图展示了对比没有干预情况,如果采取Tech Support/Discount,会获得多大的效应增益
effect=pd.DataFrame(why.causal_effect(control = [0,0]))
effect

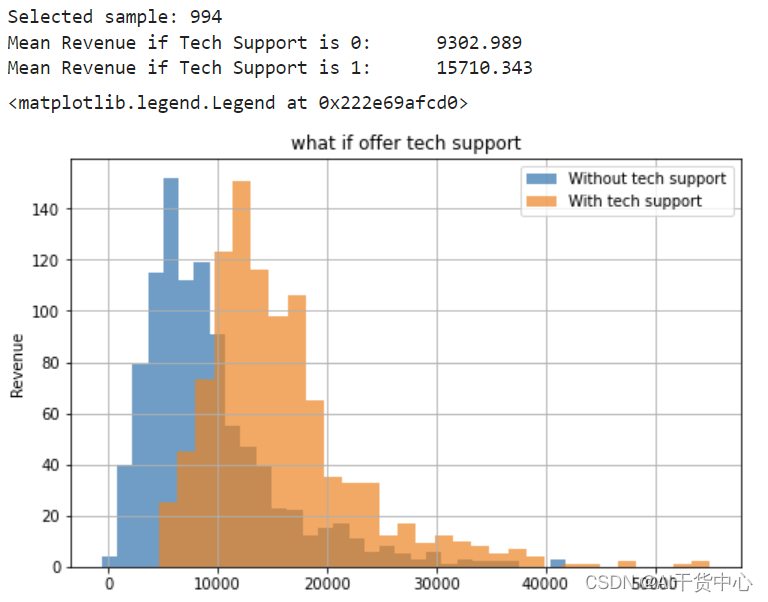
使用反事实推断,对没给予过Tech Support的994个样本使用反事实推断,假设他们都获得了Tech Support
import matplotlib.pyplot as plt
whatif_data= data[data['Tech Support'] == 0]
out_orig=whatif_data[outcome]
value_5=whatif_data['Tech Support'].map(lambda _:1)
out_whaif=why.whatif(whatif_data,value_5,treatment='Tech Support')
print('Selected sample:', len(whatif_data))
print(f'Mean {outcome} if Tech Support is 0:\t{out_orig.mean():.3f}' )
print(f'Mean {outcome} if Tech Support is 1:\t{out_whaif.mean():.3f}' )
plt.figure(figsize=(8, 5), )
out_orig.hist(label='Without tech support',bins=30,alpha=0.7)
out_whaif.hist(label='With tech support',bins=30,alpha=0.7)
plt.ylabel(f'{outcome}')
plt.title(f'what if offer tech support')
plt.legend()
从结果看出如果提供Tech Support,带来了平均15710 – 9302 = 6408的效果增益
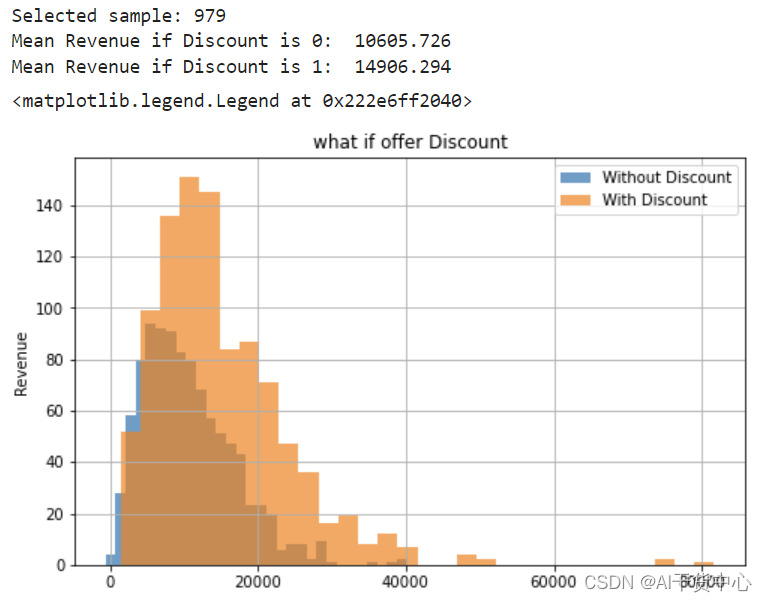
使用反事实推断,对没给予过Discount的979个样本使用反事实推断,假设他们都获得了Discount
import matplotlib.pyplot as plt
whatif_data= data[data['Discount'] == 0]
out_orig=whatif_data[outcome]
value_5=whatif_data['Discount'].map(lambda _:1)
out_whaif=why.whatif(whatif_data,value_5,treatment='Discount')
print('Selected sample:', len(whatif_data))
print(f'Mean {outcome} if Discount is 0:\t{out_orig.mean():.3f}' )
print(f'Mean {outcome} if Discount is 1:\t{out_whaif.mean():.3f}' )
plt.figure(figsize=(8, 5), )
out_orig.hist(label='Without Discount',bins=30,alpha=0.7)
out_whaif.hist(label='With Discount',bins=30,alpha=0.7)
plt.ylabel(f'{outcome}')
plt.title(f'what if offer Discount')
plt.legend()
从结果看出如果提供Discount,带来了平均14906 – 10605 = 4301的效果增益
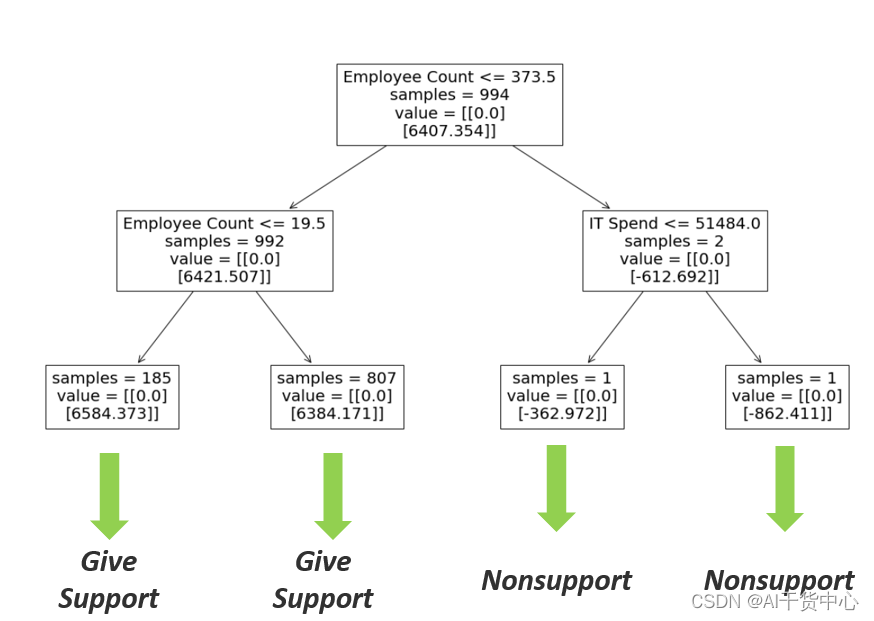
我们通过因果推断给出关于Tech Support和Discount最优的决策路径


















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











