







 本文探讨了时间序列预测中的四种常见策略:单步预测、直接多步预测、递归多步预测和多输出策略。通过实例解析如何处理复杂业务场景中的大规模序列数据,以及滞后特征在其中的作用,重点介绍了混合策略和使用深度学习进行多步预测的方法。
本文探讨了时间序列预测中的四种常见策略:单步预测、直接多步预测、递归多步预测和多输出策略。通过实例解析如何处理复杂业务场景中的大规模序列数据,以及滞后特征在其中的作用,重点介绍了混合策略和使用深度学习进行多步预测的方法。
所谓时间序列模型就是利用过去一段时间的序列信息去预测未来一天或多天的信息。
通常对于时间序列的预测策略都是单步预测,时间序列预测描述了预测下一个时间步长的观测值。如下图所示,某航空公司的客运流量。
time passengers
0 1949-01 112
1 1949-02 118
2 1949-03 132
3 1949-04 129
4 1949-05 121
5 1949-06 135
6 1949-07 148
7 1949-08 148
8 1949-09 136
9 1949-10 119
... ... ....
从上图可以看出,我们所获取的过去时序信息仅限于单变量的时序信息,而面对这类问题,通常都是采用arima,fbprohet之类的模型。然而,在一般复杂业务场景上碰到的问题基本上是成百上千的序列。
当然我们可以对每个序列单独用arima之类的方法来建模,理论上可以,但是实际上基本不可能,一方面维护成千上万的模型的成本是不可估计的,另一方面不同商品的序列长度差异很大,有的序列长度可能非常完整有1500+个序列数据,有的冷门商品或者是新上的商品序列长度很短可能只有不到10个,这种情况下,后者基本没法单独建模。
因此实际上我们常见的业务问题的数据形式是这样的:
商品 日期 销量序列数据
nike的XXX款衣服 2020-01-01 100
nike的XXX款衣服 2020-01-02 200
nike的XXX款衣服 2020-01-03 150
nike的XXX款衣服 2020-01-04 250
...
对于这些数据进行建模的最大问题就是,使用多少步的历史数据预测多少步的未来数据。即所谓的时间窗问题。 比如下图显示的用前一天的数据预测后一天的。
商品 日期 过去一天销量 销量序列数据
nike的XXX款衣服 2020-01-01 nan 100
nike的XXX款衣服 2020-01-02 100 200
nike的XXX款衣服 2020-01-03 200 150
nike的XXX款衣服 2020-01-04 150 250
...
这就是我们的所谓的滞后特征,也是时间序列问题中最常见的也是最重要的特征衍生方法。一般来讲,滞后数据越接近预测时间点,那么其信息对于预测的准确率贡献越大。
为了便于描述,这里假设一个序列:[1,2,3,4,5,6,7,8,9,10,X,Y,Z]
我们要做的是预测未来的3个时间点,X,Y,Z的序列的值,并且为了方便描述,这里我们统一仅仅使用1阶滞后特征。
No1.直接多步预测
直接多步预测的本指还是单步预测,多步转单步,比如上面我们要预测3个时间点的序列的值,则我们就构建3个模型:
model1:[1,2,3,4,5,6,7,8,9]==>[X]
model2:[1,2,3,4,5,6,7,8,9]==>[Y]
model3:[1,2,3,4,5,6,7,8,9]==>[Z]
这种做法的问题是如果我们要预测N个时间步,则复杂度很高,比如预测未来100天,则意味着我们要构建100个模型。
另外需要注意的是,在使用这种方法的时候,我们在进行特征工程的时候要比较小心,因为我们在序列问题的特征工程过程中常常会涉及到一些lag方法,即滞后特征的引入,比如对于: m o d e l 1 : [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ] = = > [ X ] model1:[1,2,3,4,5,6,7,8,9]==>[X] model1:[1,2,3,4,5,6,7,8,9]==>[X]
我们可以构建一阶滞后特征: [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ] , [ n a n , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 ] [1,2,3,4,5,6,7,8,9],[nan,1,2,3,4,5,6,7,8] [1,2,3,4,5,6,7,8,9],[nan,1,2,3,4,5,6,7,8],而待预测的X的一阶滞后是9,是我们已经观测到的值,因此取1阶滞后没有问题。
但是对于 m o d e l 2 : [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ] = = > [ Y ] model2:[1,2,3,4,5,6,7,8,9]==>[Y] model2:[1,2,3,4,5,6,7,8,9]==>[Y],我们无法使用1阶滞后,因为Y的一阶滞后是X,X并不是我们的观测值,这个时候我们的滞后特征只能从二阶滞后开始做起。所以对于后续的 m o d e l 3 , m o d e l 4 model3,model4 model3,model4都是同理。
Tips:时间窗的长度和我们处理无序的结构化问题有一些区别。直观来说,一般长度的概念对应的是样本的数量,但是实际上在结构化数据中,对应的是特征的维度,比如:
| lag_3 | lag_2 | lag_1 | label |
|---|---|---|---|
| 1 | 2 | 3 | 4 |
| 2 | 3 | 4 | 5 |
| 3 | 4 | 5 | 6 |
对于直接多步预测的方法,误差会随着预测时间步长的增加而增加,这样就到导致出现较高的方差。
No2.递归多步预测
递归多步预测本质上还是简单的多步预测,但是和第一种情况不同,递归多步预测不需要预测 时间步个模型,仅仅一个模型就够了。
同样是上面的一个例子:
[1,2,3,4,5,6,7,8,9,10,X,Y,Z]
model:[1,2,3...,9,10]==>[X]
model:[2,3,4...,10,pred(X)]==>[Y]
以此类推...
可以看出,由于使用了预测值代替了观测值,因此该递归策略产生累计误差。随着预测时间范围的增加,模型的性能可能会迅速下降。
No3.直接+递归混合策略
所谓混合策略的做法是,我们用model1预测X得到pred(X),然后将这个pred(X)作为model2的”观测“数据,纳入模型训练,即
model1:[1,2...9,10]==>[X]
model2:[2,3...9,10,pred(X)]==>[Y]
model3:[3,4...10,pred(X),pred(Y)]==>[Z]
...
No4.多输出策略
在传统的机器学习模型中,无法正常处理回归多输出问题,在多步预测中,是基于多个模型的输出。比如预测未来的3步是一个3输出模型,这个概念就类似于我们的多标签分类、多标签回归的概念。实际上针对于直接预测法,就是一种常见的使用传统的机器学习算法解决多标签问题的转化方法,而递归预测法本质上还是普通的简单的单标签问题。
但是深度学习可以很容易的打破这样的限制,这里介绍第四种策略:多输出策略。如下图
model:[8,9,10][X,Y,Z]
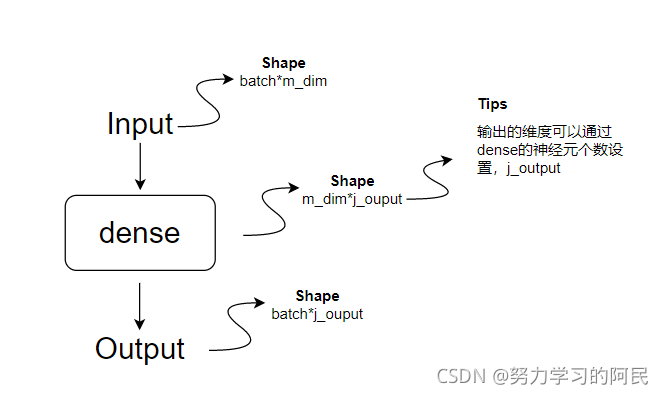
如上图所示,我们只需要把这里的Dense层的神经元个数设置为 j o u t p u t j_{output} joutput就可以( j j j是要预测的未来的时间的步数)。这是常见的使用nn进行多步预测的网络设计,特点就只是输出层的nn根据预测的时间步数进行设置而已。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











