







卷积神经网络的基本原理
什么是卷积运算
数学上的卷积
数学上,我们通常用反褶和乘积运算定义卷积:
f
(
t
)
=
f
1
(
t
)
∗
f
2
(
t
)
=
∫
−
∞
+
∞
f
1
(
τ
)
f
2
(
t
−
τ
)
d
τ
f(t)=f_1(t)*f_2(t)=\int_{-\infty}^{+\infty}f_1(\tau)f_2(t-\tau)d\tau
f(t)=f1(t)∗f2(t)=∫−∞+∞f1(τ)f2(t−τ)dτ
这种运算得到的是两个函数
f
1
f_1
f1和
f
2
f_2
f2的“重合部分面积”,可以理解为两个函数相似程度的度量
矩阵的卷积
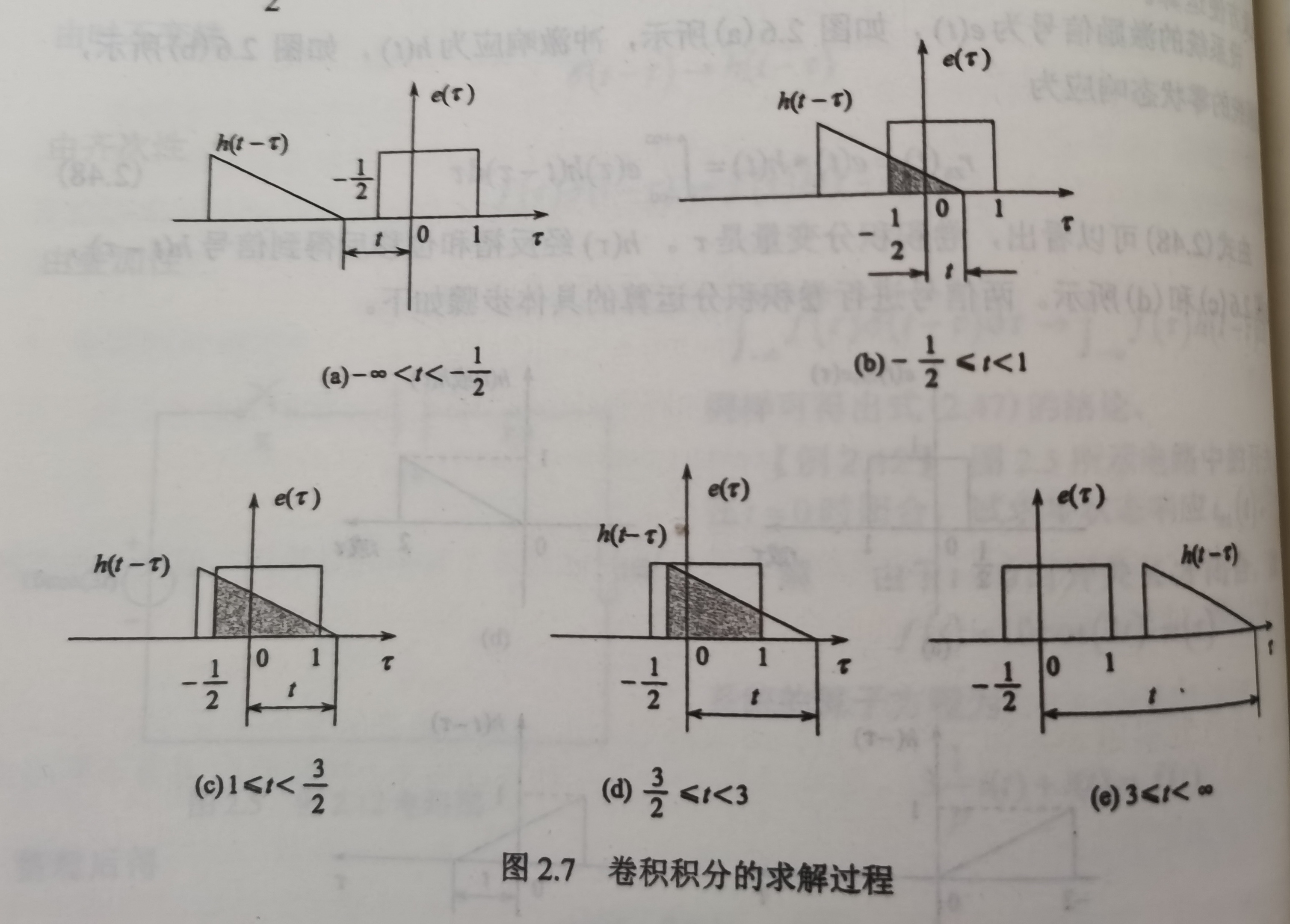
矩阵的卷积与数学上的卷积类似,将一个矩阵按照平移的方式与另一个矩阵对应位置的元素相乘再相加,得到新矩阵的元素,如下图:
我们知道数学上的卷积运算表示两个函数的相似程度,那么矩阵的卷积运算也是类似的。如果我们把kernel理解为一种“特征”,那么卷积运算就相当于透过这种“特征”的视角去扫描一遍input,从input中将与kermel所含”特征“相同的部分提取出来
例如在进行图片的处理的时候,我们采用如图矩阵作为kernel和一张图片(可以理解为一个二维矩阵,每个元素就是图片该点的像素值)进行卷积运算,将会得到锐化的效果。这是因为kernel中心点的像素显著加强,而边界的像素都-1。output=kernel卷积input,output中每个点相当于input中该点像素值剔除掉周围点的像素值,得到的output就有”锐化“效果

例如我们采用如图矩阵作为kernel和一张图片进行卷积运算,将会得到模糊效果。这是因为kernel中心点跟边界点取了相同的权重。output=kernel卷积input,output中每一个点相当于input中周围几个点叠加的效果,就变”模糊“了

机器学习中的应用
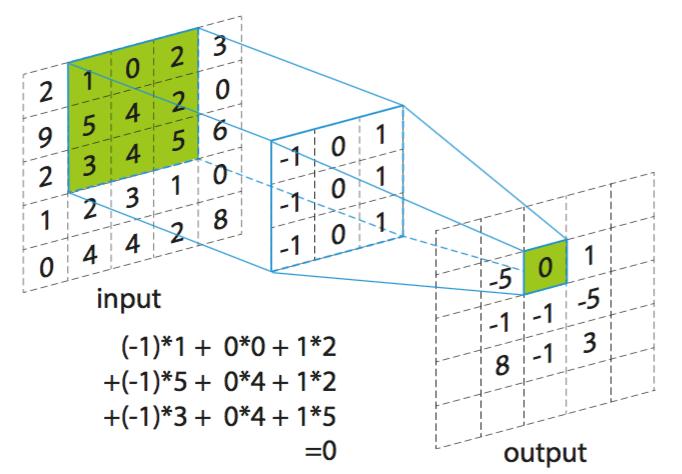
我们传统的全连接神经网络是这样的:
这种网络参数十分庞大,训练计算量很大。
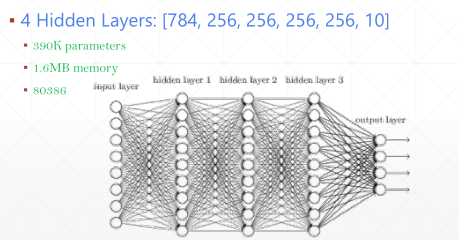
而我们发现人在识别事物的时候,一般只需要把注意力集中到某一些信息的特征上即可:

这种识别方法相当于用不同的kernel分别扫描输入,每一个kernel就相当于一个特征,比如"食物",“人”,”汽车“等等,通过用不同的kernel扫描输入,就能提取到特定的信息层。因此我们理论上只要优化出一组足够好的kernel,就能像人类一样去识别事物,产生智能。
而且这样能够将全连接网络变成部分连接网络,减少了参数量,使训练更加容易:

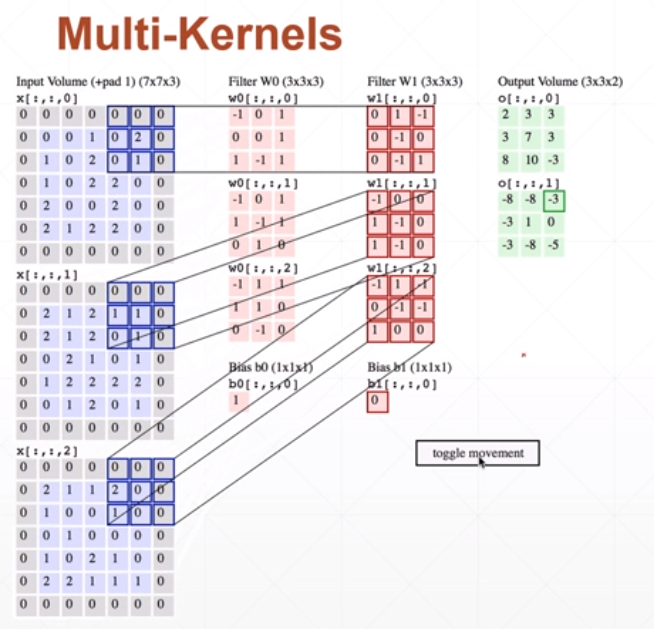
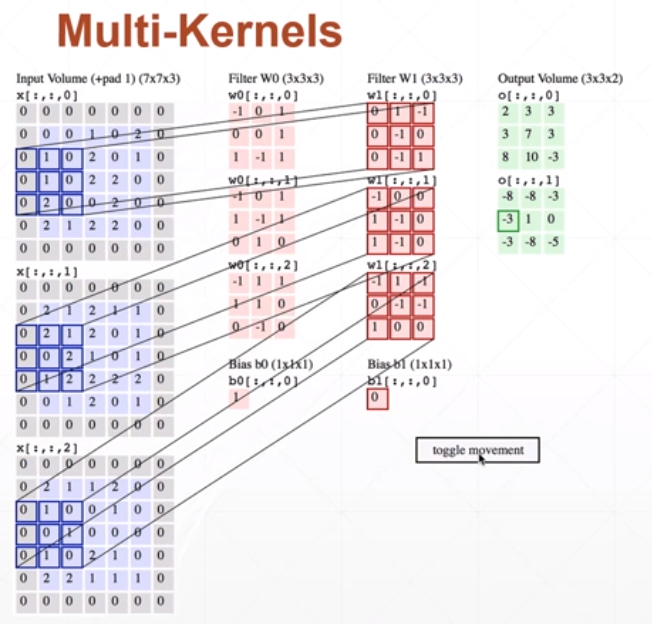
卷积神经网络的实现
特征提取
多特征扫描过程
我们用每一层kernel扫描一遍图像,得到一个信息层:
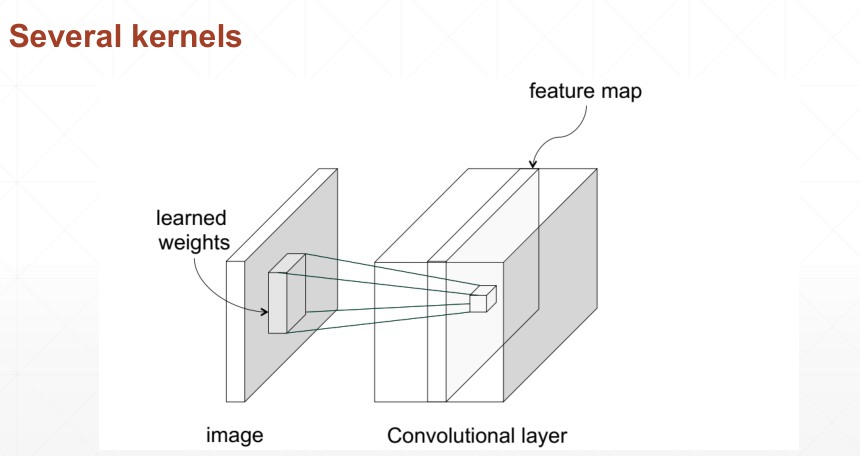
一般来说,图片的存储的size是[b,c,x,y],其中:
- x,y是图片的长和宽
- c是channel即图片的通道数
- b是batch即一共有多少张图片
那么进行扫描的kernel是size是[k,c,x,y],其中:
- x,y是kernel的大小
- c与图片的channel数一致,表示每一个通道都分配一张kernel
- k是kernel的个数,有多少个kernel相当于提取多少种特征
偏置bias的size为[k],表示为每一个kernel分配一个偏置
扫描的过程是:对图片的c个channel分别用该kenel的c个层去扫,得到c个信息层,然后将这些信息层对应位置的元素加起来再加上偏置bias,合并一个信息层输出
得到的输出为[b,k,x,y],其中:
- b是batch即一共有多少张图片
- k是新的通道数,即每一个kernel扫描并合并得到的一个信息层作为一个通道
- x,y是图片的长和宽
可以通过如下实例检验是否理解了这个运算过程:
补丁操作
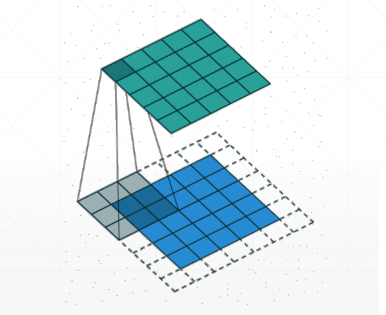
我们知道卷积运算扫描的过程会使得输出矩阵比原矩阵的维度缩小一些,为了使输出与输入矩阵大小保持一致,可以在原矩阵的边缘加上几层0,在代码中用Padding表示
步长
kernel一次移动的长度,在代码中用Stride表示
python代码
使用nn类库实现
import torch
from torch import nn as nn
# 构造2维卷积层,1个channel,3个kernel
layer = nn.Conv2d(1, 3, kernel_size=3, stride=1, padding=0)
# 输入一张图片,batch=1,channel=1,x=28,y=28
x = torch.rand(1, 1, 28, 28)
# 输出
out = layer.forward(x)
print(x.size())
print(out.size())
print(layer.weight.shape)
print(layer.bias.shape)
# 结果
# torch.Size([1, 1, 28, 28])
# torch.Size([1, 3, 26, 26])
# torch.Size([3, 1, 3, 3])
# torch.Size([3])
使用底层函数实现
import torch
from torch.nn import functional as F
x = torch.rand(1, 1, 28, 28)
w = torch.rand(3, 1, 3, 3)
b = torch.rand(3)
out = F.conv2d(x, w, b, stride=1, padding=0)
print(out.size())
# 结果
# torch.Size([1, 3, 26, 26])
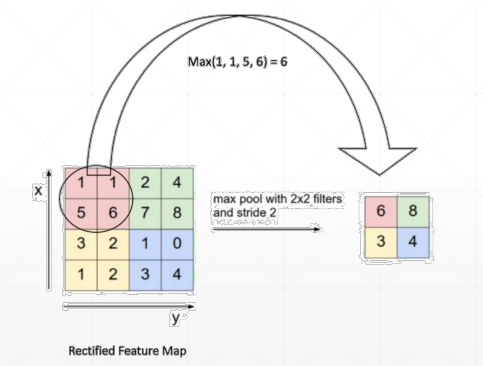
池化与采样
pooling
将一个输出的层压缩,采用的方法是使用一个”窗口“去扫这个层,将窗口内的最大值/平均值等等作为输出
python代码
使用nn类库实现
import torch
from torch import nn as nn
# 需要操作的层
x = torch.rand(1, 1, 28, 28)
# 池化层,窗口大小为2*2方阵,步长为2
layer = nn.MaxPool2d(2, stride=2)
out = layer(x)
print(out.size())
# 结果
# torch.Size([1, 1, 14, 14])
使用底层函数实现
import torch
from torch.nn import functional as F
# 需要操作的层
x = torch.rand(1, 1, 28, 28)
# 池化,窗口大小为2*2方阵,步长为2
out = F.avg_pool2d(x, 2, stride=2)
print(out.size())
# 结果
# torch.Size([1, 1, 14, 14])
upsample
将一个输入层扩大,一般采用插值的方法,就是将每一个元素都复制一遍
python代码
使用底层函数实现
import torch
from torch.nn import functional as F
x = torch.rand(1, 1, 28, 28)
out = F.interpolate(x, scale_factor=2, mode='nearest')
print(out.size())
# 结果
# torch.Size([1, 1, 56, 56])
激活函数
relu函数常用来作为激活函数使用,输出时会忽略掉负值
python代码
使用nn类库实现
layer = nn.ReLU(inplace=True)
使用底层函数实现
out = F.relu(x)
标准化
对于训练时输入的每一张图片,如果不进行标准化,可能会因为激活函数的原因产生梯度离散,如下图中值很小的输入几乎为0:

同时,由于输入的分布不均匀,使得一部分权值w对loss影响很大而另一部分的w影响很小,使得一些w更新速度十分缓慢:
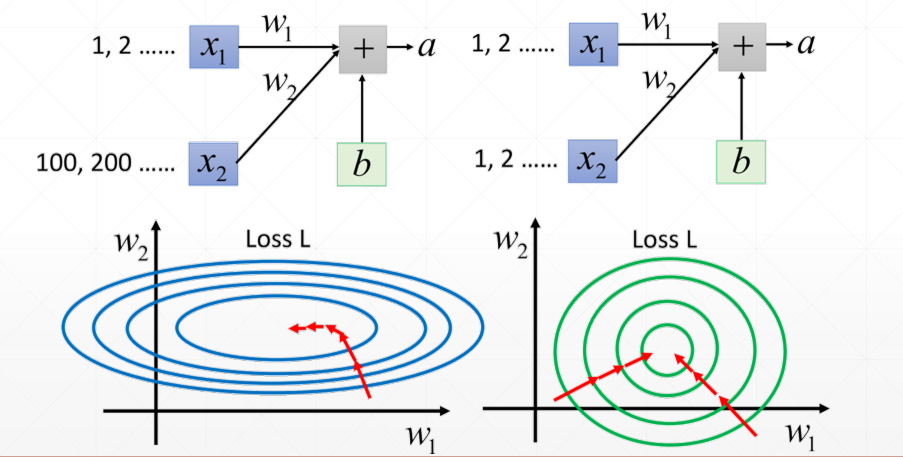
因此需要对输入进行标准化,使其落在激活函数的最佳“放大区间”上。具体的做法就是统计期望和方差,通过 z = z − μ σ z=\frac{z-\mu}{\sigma} z=σz−μ将输入变成分布为 N ( 0 , 1 ) N(0,1) N(0,1)的变量,统计的方式有如下几种:
- Batch Norm:按照channel来统计
- Layer Norm:按照batch来统计
- Instance Norm:按照单张图片来统计
- Group Norm:按照几张图片一组来统计
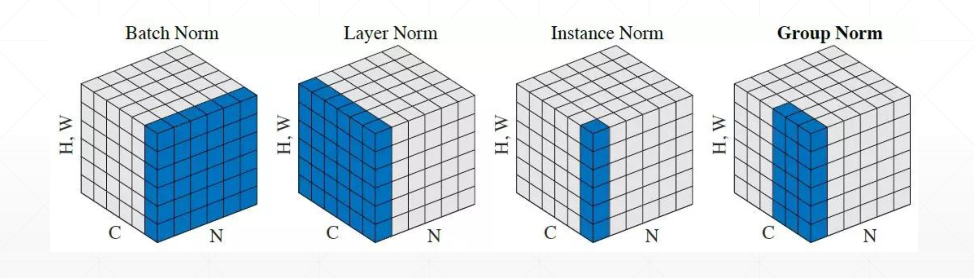
对于以上的标准化,以Batch Norm为例说明其计算过程:
-
为每c个channel各初始化一个当前期望running_mean和一个当前方差running_var
-
标准化的过程需要综合考虑全局,而不是以当前batch的期望和方差来标准化。具体操作为每输入一个batch,用动量的思想来更新期望和方差,即 x n e w = ( 1 − m ) x o l d + m x n o w x_{new}=(1-m)x_{old}+mx_{now} xnew=(1−m)xold+mxnow,其中 m m m为动量,表示当前的值所占的比重,动量越大更新越倾向于向当前值变化,动量小则更新倾向于维持原来的方向不变,最后得到c个期望和c个方差
-
用这c组期望和方差分别更新每一张图片的c个channel
-
之后进行变换 x i = γ ∗ x + β x_i=\gamma*x+\beta xi=γ∗x+β得到分布为 N ( β , γ ) N(\beta,\gamma) N(β,γ)的输入,其中 γ \gamma γ和 β \beta β两个参数需要进行学习
测试的时候需要加上layer.eval()以防测试数据反向传播改变模型
标准化的优点
- 使得模型的训练速度加快了
- 具有良好的Robust性,增加了learning rate的可调节范围,使得梯度下降的过程更加稳定
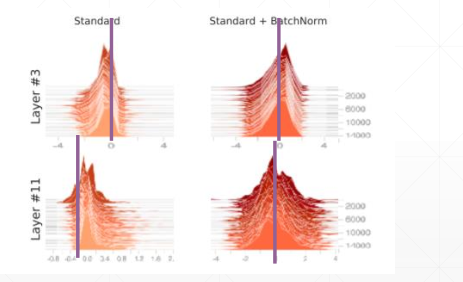
从下面这张图中可以看出经过标准化操作之后,期望接近0附近,方差也压缩到一个比较小的值















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









