







kaldi功能强大,几乎是语音识别领域必用的工具了。如果不想用他人的语料库而使用自己语料库来构建解码器,坑比较多过程也比较复杂,在这里做个笔记。
kaldi的安装比较简单,参照这个的博客:http://blog.topspeedsnail.com/archives/10013
如果安装过程中遇到PortAudio failed to open the default stream的错误,参照这个博客https://blog.csdn.net/u012236368/article/details/71628777
kaldi的原理就不赘述了,很多大佬也写了,kaldi的官网也有。下面主要介绍从一个语料库开始构建HCLG解码器的过程。
1.语料库的准备
语料库就是一个txt,一行一个句子(不要有标点符号,也不要有数字、英文之类的非中文符号),如下图所示:
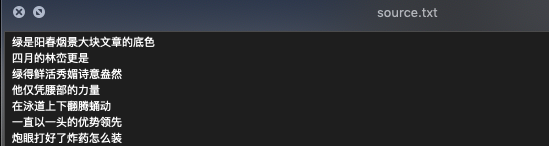
将其命名为source.txt。然后使用结巴分词对这些句子进行分词,以便后续构建基于这个语料库的用户字典。结巴分词的按照非常简单,pip一下就行。结巴分词后的文件就命名为source_divied.txt了。Python3的代码如下:
#divide_words.py
import jieba
input_file = open("source.txt", "r")
output_file = open("source_divided.txt", "w")
for line in input_file.readlines():
seg_list = jieba.cut(line, cut_all=Falsed)
s = " ".join(seg_list)
output_file.write(s)
print(s)
input_file.close()
output_file.close()处理分词之后的语料库,我们还需要一个字典文件,保存用到的分词(相当于一个集合)。就把这个字典文件命名为dict.txt。代码如下:
#make_dict.py
input_file = open("source_divided.txt", "r")
output_file = open("dict.txt", "w")
dict_set = set()
for line in input_file.readlines():
words = line.split()
line_set = set(words)
dict_set = dict_set.union(line_set)
for word in dict_set:
line = word + '\n'
output_file.write(line)
input_file.close()
output_file.close()
2.构建语言模型
关于语言模型是干什么的,网上有很多解释,这里也不介绍了。kaldi需要使用的是arpa格式的语言模型,大概长这样:

这就需要我们建立一个语言模型了。这里同样使用应用广泛的srilm来构建语言模型。安装和使用都非常简单,网上的教程也有很多,比如https://blog.csdn.net/u011500062/article/details/50781101和https://blog.csdn.net/ninesky110/article/details/82179541。一通操作之后,我们得到基于语料库的语言模型,命名为LPRD1000.apra。
3.构建G.fst
由于kaldi建立fst时并不是直接使用汉字而是使用编号来编码,因此我们需要一个文件来告诉kaldi每一个汉字的映射编码。这个文件我命名为dict_marked.txt,其实就是在dict.txt的基础之上加上了编号和一些格式上的东西。代码如下:
#make_dict_marked.py
with open("dict.txt", 'r') as input_file:
with open("dict_marked.txt", 'w') as output_file:
mark = 1
for line in input_file.readlines():
str = line.replace('\n', '')
output_file.write("%s %s\n" % (str, mark))
mark = mark + 1
output_file.write("<eps> 0\n")
output_file.write("#0 %s\n" % mark)
output_file.write("<s> %s\n" % (mark + 1))
output_file.write("</s> %s" % (mark + 2))运行完之后应该可以得到一个dict_marked.txt的文件,如下图所示:
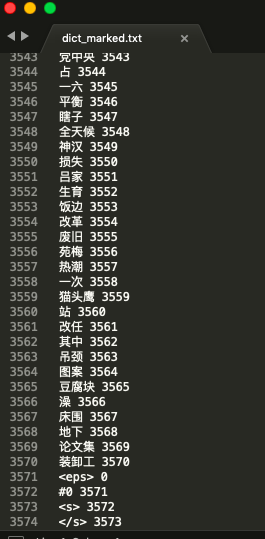
目前准备工作做好了,下面我们就需要使用kaldi把arpa文件转为G.fst
首先将目录切换到<kaldi安装位置>/src/lmbin/下(或者把这个目录加进环境变量也可以),把之前的dict_marked.txt和LPRD1000.arpa两个文件拷贝到这个目录下,使用命令
$./arpa2fst --disambig-symbol=#0 --max-arpa-warnings=-1 --read-symbol-table=dict_marked.txt LPRD1000.arpa LPRD1000_G.fst就可以生成一个叫LPRD1000_G.fst的Gfst了。详细的参数可以在代码中的帮助看到,也可以参考https://blog.csdn.net/lucky_ricky/article/details/77511543
如果遇到了缺少libfst.so.10之类的问题,就先用find命令找到这个so文件然后将其复制到 /usr/lib/下,再重试一遍之前的命令就可以了。至此,我们完成了G的构建。如果你想看看这个fst长什么样,可以用kaldi自带的fstprint命令和fstdraw命令。下一篇博客应该会讲如何构建L.fst,应该不会鸽掉。















 3412
3412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









