






以下文章来源于Understanding the Limits of Artificial Intelligence for Warfighters: Volume 1, Summary,转载自军鹰动态
2024年1月3日,兰德公司发表了《人工智能作战使用的局限性分析》报告,该报告面向美空军使用需求,重点分析了人工智能(Artificial Intelligence,AI)应用于网络安全(Cybersecurity)、预测性维护(Predictive Maintenance)、兵棋推演(Wargames)和任务规划(Mission Planning)时的局限性,强调了AI系统训练与测试数据必须及时、可得、高质量,AI算法的局限性对其作战使用影响显著。

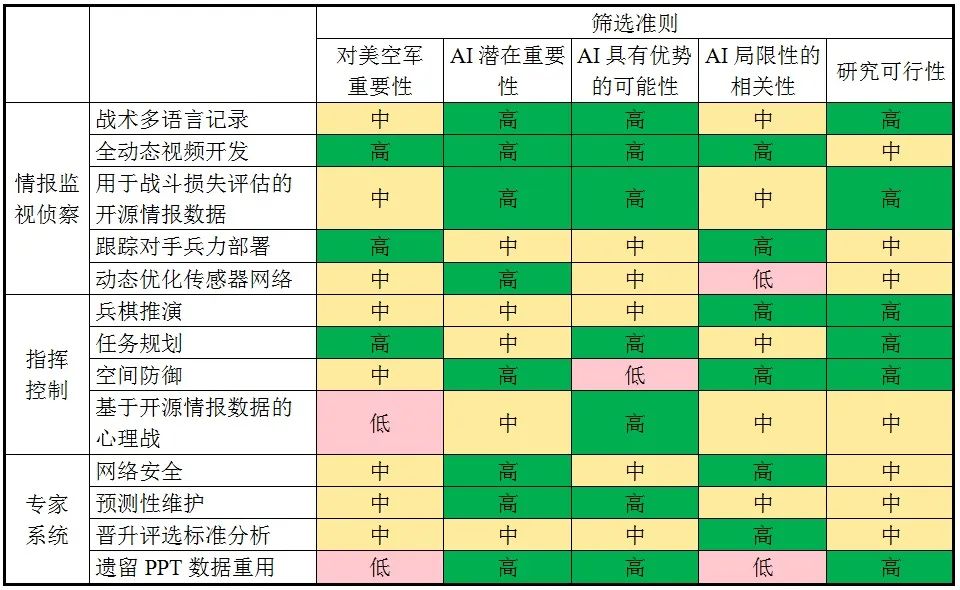
兰德公司的这篇报告聚焦机器学习中的监督学习和强化学习,并未考虑通用人工智能等机器学习领域的新兴前沿技术。兰德公司从情报监视侦察(Intelligence,Surveillance and Reconnaissance,ISR)、指挥控制(Command and Control,C2)和专家系统中选择了14个研究领域,考虑美空军关注度、潜在应用效果、局限性相关度等因素,最终筛选出网络安全、预测性维护、兵棋推演和任务规划四大领域开展分析。
1 网络安全

在网络安全领域,主要考虑分布偏移(Distribution Lift)对AI系统有效性的影响。
分布偏移是指AI系统需要处理的数据与其训练/测试数据随时间逐渐发生偏差,研究表明这一现象会导致AI系统性能随时间显著降低。由于黑客会不断尝试各种难以预料的方法开展攻击,因此简单扩充初始样本集的方式并不能有效应对分布偏移。
兰德公司研究团队针对网络渗透探测和恶意软件识别两大常见网络安全任务,分别基于公开基准数据集构建AI系统,并通过时间分片法评估数据分布偏移程度及其对AI系统的影响程度。
经过仿真分析,构建的AI系统确实出现了性能随时间衰退的现象,说明网络安全领域的AI系统具有内在的“保质期”,必须定期重新训练,且面向不同任务的AI系统的“保质期”不同。研究团队同时指出,前述的数据集分割方法是估计“保质期”的有效工具。
2 预测性维护

在预测性维护领域,通过和传统的假设部件失效服从泊松分布的飞行器可持续性模型(Aircraft Sustainability Model,ASM)进行对比,分析AI模型对飞机部件失效预测精度的改善效果,进而支撑美空军战备备件包(Readiness Spares Packages,RSPs)维护与更新。
研究人员整理了“雷电”攻击机(A-10C)2007年9月至2022年6月间的部件失效数据,利用前10年的数据构建长短期记忆网络,余下数据用作模型校验。经过Kolmogorov-Smirnov检验,超过80%的失效数据并不服从泊松分布。ASM模型和AI模型对部件失效率的预测能力对比如下图所示,图中红色虚线是完全准确预测的参考线。
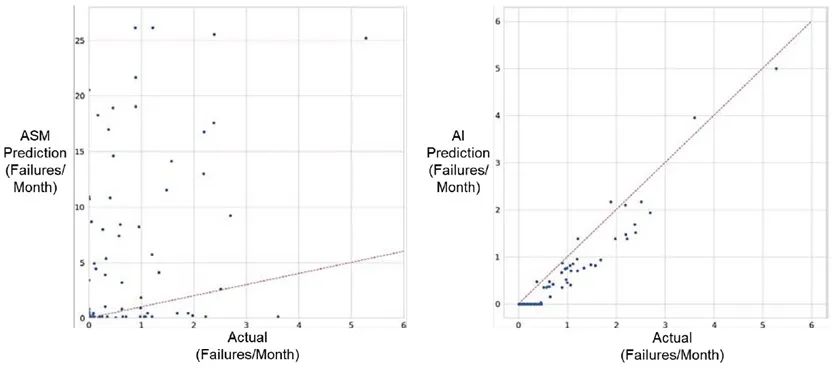
由上图可知,AI模型的平均预测误差约为1.6%,明显优于ASM模型,每月可降低备件成本约3000万美元,但缺点是将略微低估失效率。研究人员指出,这一概念验证性的AI模型取得的结果并不能否定ASM模型的效果,因为上述AI模型仅考虑了A-10C单一平台,且ASM模型除部件失效预测外还具备处理复杂运筹学问题的能力。
经综合分析,研究人员认为,AI模型能有效提高战备备件包的需求预测能力,但投入实用还需要对现有数据进行大量处理,且AI模型尚难以解决实战数据缺乏的问题。因此,美空军装备司令部(Air Force Materiel Command,AFMC)需要加强数据处理管道建设,开展飞机维护与战备备件包更新的回顾性分析;相关研究人员需要针对更多飞机平台采用AI模型开展失效分析,并尝试解决更加复杂的运筹学问题。
3 兵棋推演

2010年以来,AI在国际象棋、围棋、星际争霸等领域进展神速,采用AI开展兵棋推演逐渐受到广泛关注。
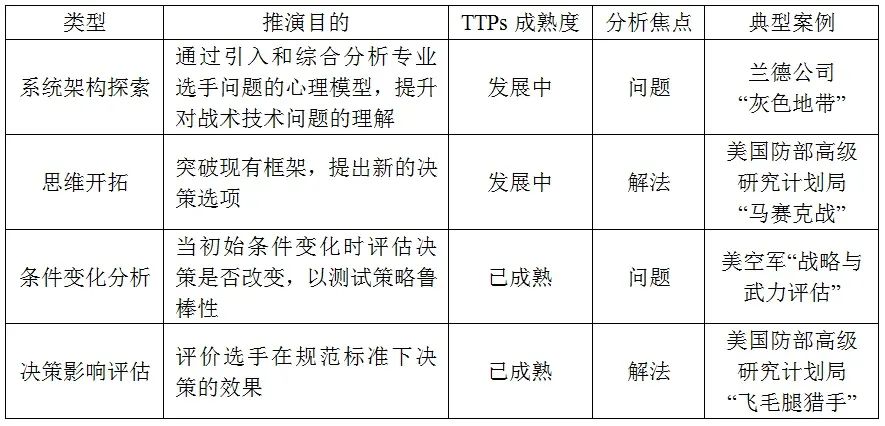
按照推演目的,兵棋可分为系统架构探索、思维开拓、条件变化分析、决策影响评估四类,相应的战术、技术和规程(Tactics, Techniques, and Procedures,TTPs)的成熟度、分析焦点及典型案例如下表所示。
按照推演过程,兵棋可分为准备、进行、判定、解释四个阶段。在不同目的的兵棋推演的不同阶段,应用AI的技术可行性和效费比如下表所示,其中红色表示不可行,绿色表示可行,黄色表示介于两者之间。
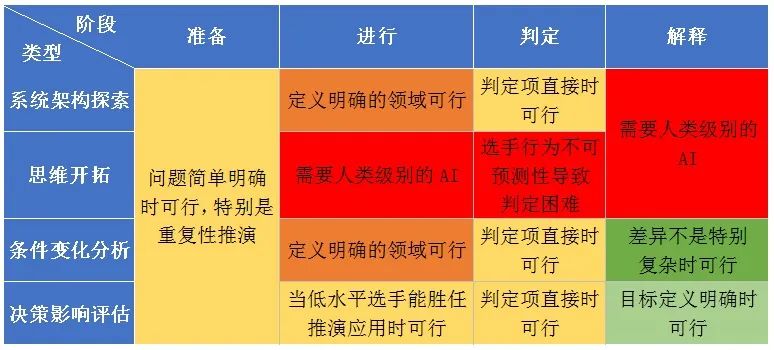
目前适合应用AI的兵棋推演的特点是:
评价指标定义明确、数量较少的条件变化分析和决策影响评估;
判定阶段计算模型权重高,或有大量数据需要判定;
数据捕获和交互阶段使用了先进的人机交互技术(例如相机和话筒);
多次重复,特别是零和模型与对抗演练。
综上所述,研究人员认为,AI技术研究资源目前应聚焦上述适合应用的领域,同时加大数字化推演架构和人机交互技术的推广力度,不断探索AI技术支撑战略研究的能力。
4 任务规划

在任务规划领域,通过和传统运筹学方法对比,分析AI技术改善多约束路径规划问题实时求解的能力。
研究人员使用兰德公司的目标获取模型(RAND Target Acquisition Model,RTAM)构建了单架无人机避障飞行的场景。传统路径规划方法将空域划分为离散的子空间,根据给定的代价函数解析求解最优路径。传统路径规划方法和兰德公司的仿真、集成与建模先进框架(Advanced Framework for Simulation,Integration and Modeling,AFSIM)中的强化学习方法的求解结果对比如下。
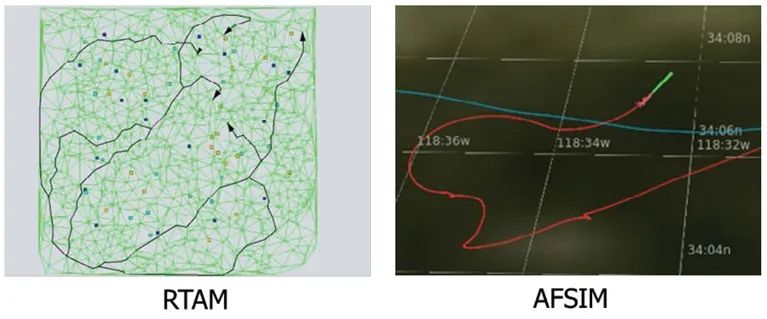
仿真结果表明,对于定义明确的路径规划问题,基于AI的路径规划结果最优性不如传统的运筹学方法,AI能快速生成大量近似最优的强鲁棒结果,能够辅助支持人类决策。限于当前技术水平,AI难以应用到长期战略级规划中。
研究人员认为,美空军需要加大强化学习研究投入,开发能够替代现有任务规划方法的AI模型,还需要探索采用AI提升无人机在突发情况下的快速处置能力。
本文来源:军鹰动态


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









