







HMM模型介绍
由隐状态序列,生成可观测状态的过程。
两个基本假设:
- 第t个隐状态只和前一时刻的t-1隐状态相关,与其他时刻的隐状态无关。
- 在任意时刻t的观测值只依赖于当前时刻的隐状态值,和其他时刻的隐状态无关。

HMM模型参数
- 转移概率:t时刻的隐状态qi转移到t+1时刻的隐状态qj的概率。

- 发射概率:t时刻由隐状态qj生成观测状态vk的结果。

- 初始隐状态概率:自然语言序列中第一个字o1的实体标记是qi的概率。
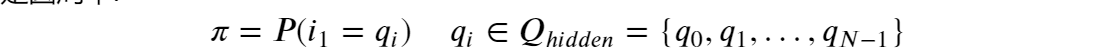
HMM模型的学习算法
- 有了最佳参数,如何使用参数解决序列标注?(前向传播)

这样不能保证全局最优,所以需改进为维特比算法。 - 参数估计过程:极大似然估计?
个人认为就是直接数个数

维特比算法
- 建立两个Table,第一个存储当前时刻落在每种隐状态的最大概率;第二个Table存储对应T1中每个隐状态最大概率是从上一时刻哪个隐状态转移过来。规格都是𝑛𝑢𝑚_ℎ𝑖𝑑𝑑𝑒𝑛_𝑠𝑡𝑎𝑡𝑒𝑠∗𝑠𝑒𝑞𝑢𝑒𝑛𝑐𝑒_𝑙𝑒𝑛𝑔𝑡ℎ 。
- 用初始隐状态矩阵的每个元素和发射矩阵初始时刻对应字符(此时为v0)的列的每个元素相乘,得到0时刻的T1,T2。


- 在之后1时刻,(此时对应字符为v1)要计算落入当前隐状态的最大概率,就要分别计算前一时刻不同隐状态转移到当前隐状态后生成当前时刻字符的概率,取最大值,写入T1,并且在T2中记录对应路径。这就是之前的单步贪婪算法。重复步骤,填完表格。

- 最后由T1表格的最后一列的最大值,得到最后一步的最优隐状态,然后向前回溯,依据就是T2表格记录的值,每次根据找到的当前最优隐状态,在T2中当前时刻对应的行(即前一时刻的最优隐状态),找到前一时刻的最优隐状态,重复找完即可。
- 其实还有方便的矩阵运算方法,这样方便编程实现,具体如下。并且还要注意要把矩阵元素取对数,这样乘变加,不会因为太小而变成0.
















 2018
2018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









