






前言
前几天我带大家用ControlNet插件中的Canny模型生成线稿图片,今天再向大家介绍一款叫做“animeLineartStyle"的线稿lora,看看用它的生成线稿图片效果如何。
注:本文所有图片均为AI绘画软件 stable diffusion 生成。
一、文生图,直接生成线稿图

这个图片用的底模为 max.ckpt,种子数为 214638109,正向tag见下方:
best quality, ultra-detailed, illustration, intricate details, 8k, highres, extremely detailed_eyes,
black eyes, long hair,Laughing_face, braided_bangs, white hair, hair ribbon, (blush:0.5), upper body,
(skyscraper:1.3),
(ambient light:1.3), depth of field, easynegative
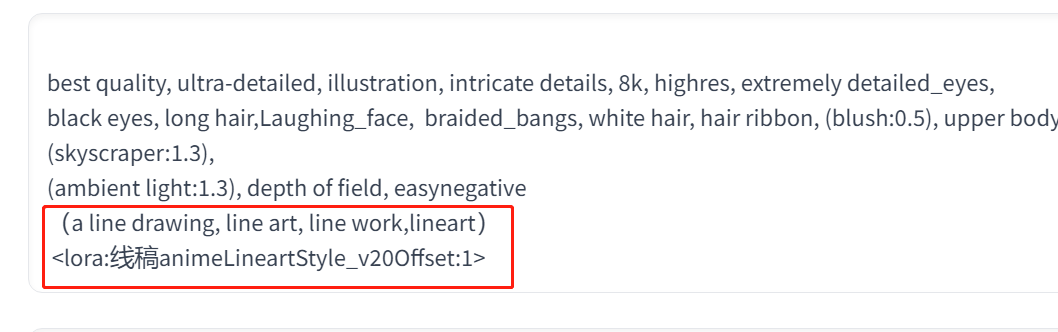
为了让这张照片产生线稿效果,我们还要加入一些线稿的提示词,然后再加入线稿lora:
线稿提示词:(a line drawing, line art, line work,lineart),具体正面 tag 见下图,有需要用提示词的朋友,可以点击图片后通过“转片转文字”获取提示词。
生成的线稿见下图。这个线稿效果还是比较不错的。图片中眼睛和嘴部还有颜色,想要解决这个问题我们可以将关键词中的含有颜色的关键词去掉,或者用PS去下色。而我觉得线稿中带一点颜色效果还不错,所以就不再花时间去处理它了。

变换种子数后,还可以得到如下图的线稿图

一、图生图,图片转成线稿图
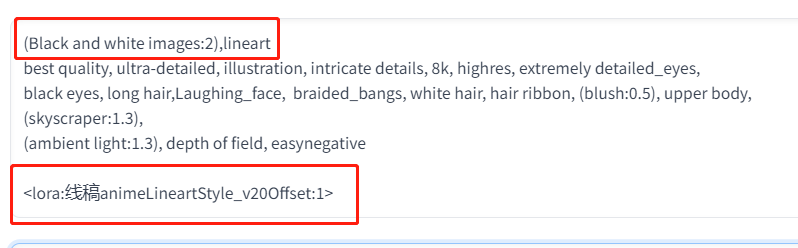
还是刚刚的图片,我们点击图生图按钮,在图生图中,增加关键词:(Black and white images:2),lineart,我们告诉AI,这是一个黑白图片,是一张线稿,最后再加入线稿的 lora。
具体tag写法见下图。
得到的线稿见下图。我们将原有图片转换成了具体线稿风格的图片,之所以颜色和嘴巴还有颜色,是因为我们用的图生图的原图片中眼睛和嘴巴颜色比较浓一些,可以调整重绘幅度来进行平衡,不过我觉得稍带点颜色也能接受,所以就不调了。

重绘幅度值的大小决定了生成图片多大程度遵从于原稿,如果重绘幅度值太小,线稿效果不明显,反之,如果便绘幅度值比较大,虽然线稿效果明显,但AI自由发挥的空间变大,相较原图变化会比较大,所以不同的数值还需要大家自己去测试,从而找到一个满意的效果。
下面这张是重绘幅度值调高后的效果,具体想要得到什么样的效果,大家自行取舍。

如果你喜欢这篇文章,多谢关注、点赞和评论,你的支持是我最大的动力。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









