






一.知识背景
1.算法:深度优先搜索
深度优先搜索(Depth-First Search,简称 DFS)是一种遍历或搜索树或图的算法。它尽可能深地搜索树的分支,直到达到底部,然后再回溯并继续探索其他分支。DFS 在很多场景下都很有用,包括路径查找、全排列生成、图的连通性检测等。
下面是深度优先搜索的基本原理和步骤:
2.基本原理
递归/迭代:DFS 可以通过递归或显式的栈实现。递归自然地利用了函数调用的栈,而显式的栈实现则需要手动维护一个栈数据结构。
回溯:在搜索过程中,如果当前路径不通或已经达到目标,算法会回溯到上一个节点,继续探索其他未探索的路径。
3.主要步骤
访问当前节点:标记当前节点为已访问。
递归/迭代地访问邻接节点:对于每一个邻接节点,如果该节点未被访问,则递归/迭代地访问该节点。
回溯:如果所有邻接节点都已访问过,回溯到上一个节点,继续探索其他可能路径。
二.代码举例
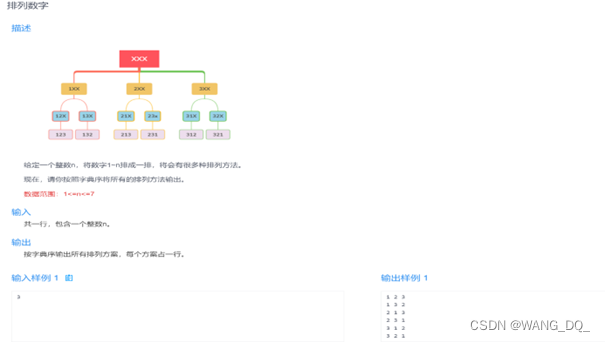
1.排列数字排列数字(dfs)_给定一个整数 n,将数字 1~n 排成一排,将会有很多种排列方法。 现在,请你按照字-CSDN博客文章浏览阅读544次,点赞3次,收藏2次。题目给定一个整数n,将数字1∼n 排成一排,将会有很多种排列方法。现在,请你按照字典序将所有的排列方法输出。输入格式共一行,包含一个整数n。输出格式按字典序输出所有排列方案,每个方案占一行。数据范围1≤n≤7输入样例:3输出样例:1 2 31 3 22 1 32 3 13 1 23 2 1代码#includeusing namespace std;const int N = 10;i..._给定一个整数 n,将数字 1~n 排成一排,将会有很多种排列方法。 现在,请你按照字 https://blog.csdn.net/falldeep/article/details/118702934
https://blog.csdn.net/falldeep/article/details/118702934
#include<iostream>
#include<vector>
#include<algorithm>
#include<cstring>
using namespace std;
vector<string> ans; // 存储所有生成的排列
string path; // 当前排列路径
vector<bool> used; // 标记当前字符是否已经被使用
// 深度优先搜索函数,参数 s 是输入字符串,u 是当前排列的深度
void dfs(string s, int u) {
if (u == s.size()) { // 递归终止条件:如果当前深度等于字符串长度,说明已经生成了一个完整排列
ans.push_back(path); // 将当前排列加入结果集
return; // 返回上一层递归
}
// 遍历字符串 s 中的每个字符
for (int i = 0; i < s.size(); i++) {
if (!used[i]) { // 如果字符 s[i] 未被使用
path[u] = s[i]; // 将字符 s[i] 放在排列的第 u 位置
used[i] = true; // 标记字符 s[i] 已被使用
dfs(s, u + 1); // 递归调用 dfs,深度加 1
used[i] = false; // 回溯:复位标记数组,将字符 s[i] 标记为未使用
}
}
}
int main() {
string line;
cin >> line; // 从标准输入读取一个字符串
sort(line.begin(), line.end()); // 对字符串进行排序,使得生成的排列按字典序排列
path = line; // 初始化当前排列路径
used = vector<bool>(line.size()); // 初始化标记数组,长度与输入字符串相同,初始值为 false
dfs(line, 0); // 调用深度优先搜索函数,从深度 0 开始生成全排列
// 输出所有生成的排列
for (const auto& t : ans) {
cout << t << endl;
}
return 0; // 返回 0,表示程序正常结束
}
2.字符全排列
#include<iostream>
#include<vector>
#include<algorithm>
#include<cstring>
using namespace std;
vector<string> ans; // 存储所有生成的排列
string path; // 当前排列路径
vector<bool> used; // 标记当前字符是否已经被使用
// 深度优先搜索函数,参数 s 是输入字符串,u 是当前排列的深度
void dfs(string s, int u) {
if (u == s.size()) { // 递归终止条件:如果当前深度等于字符串长度,说明已经生成了一个完整排列
ans.push_back(path); // 将当前排列加入结果集
return; // 返回上一层递归
}
// 遍历字符串 s 中的每个字符
for (int i = 0; i < s.size(); i++) {
if (!used[i]) { // 如果字符 s[i] 未被使用
path[u] = s[i]; // 将字符 s[i] 放在排列的第 u 位置
used[i] = true; // 标记字符 s[i] 已被使用
dfs(s, u + 1); // 递归调用 dfs,深度加 1
used[i] = false; // 回溯:复位标记数组,将字符 s[i] 标记为未使用
}
}
}
int main() {
string line;
cin >> line; // 从标准输入读取一个字符串
sort(line.begin(), line.end()); // 对字符串进行排序,使得生成的排列按字典序排列
path = line; // 初始化当前排列路径
used = vector<bool>(line.size()); // 初始化标记数组,长度与输入字符串相同,初始值为 false
dfs(line, 0); // 调用深度优先搜索函数,从深度 0 开始生成全排列
// 输出所有生成的排列
for (const auto& t : ans) {
cout << t << endl;
}
return 0; // 返回 0,表示程序正常结束
}















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









