







作为一个小型项目,使用一台 Redis 服务器已经非常足够了,然而现实中的 项目通常需要若干台Redis服务器的支持:
- 从结构上,单个 Redis 服务器会发生单点故障,同时一台服务器需要承受所有的请求负载。这就需要为数据生成多个副本并分配在不同的服务器上;
- 从容量上,单个 Redis 服务器的内存非常容易成为存储瓶颈,所以需要进行数据分 片。
同时拥有多个 Redis 服务器后就会面临如何管理集群的问题,包括如何增加节点、故障 恢复等操作。 为此,本章将依次详细介绍 Redis 中的复制、哨兵(sentinel)和集群(cluster)的使用 和原理。
一、概述
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数 据。但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导 致数据丢失。为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务 器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。
为此, Redis 提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据 同步到其他数据库上。
二、配置
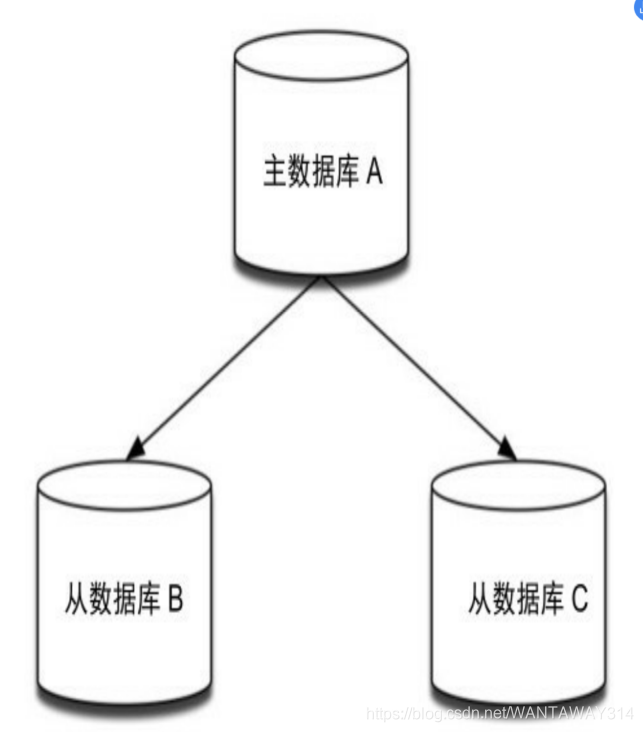
在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据库(slave)。
主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数 据库。
而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有 多个从数据库,而一个从数据库只能拥有一个主数据库
在 Redis 中使用复制功能非常容易,只需要在从数据库的配置文件中加入“slaveof 主数 据库地址 主数据库端口”即可,主数据库无需进行任何配置。
三、原理
Redis实现复制的过程:
当一个从数据库启动后,会向主数据库发sync命令,主数据库收到sync命令开始在后台保存快照(即RDB持久化的过程)并将保存快照期间收到的命令缓存起来。当快照完成后,redis会将快照文件和所有的缓存命令发送给从数据库。从数据库收到后,会载入快照文件并执行收到的缓存的命令。
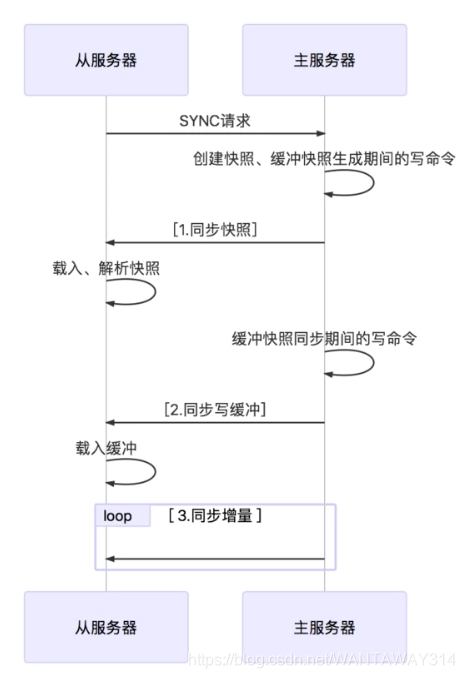
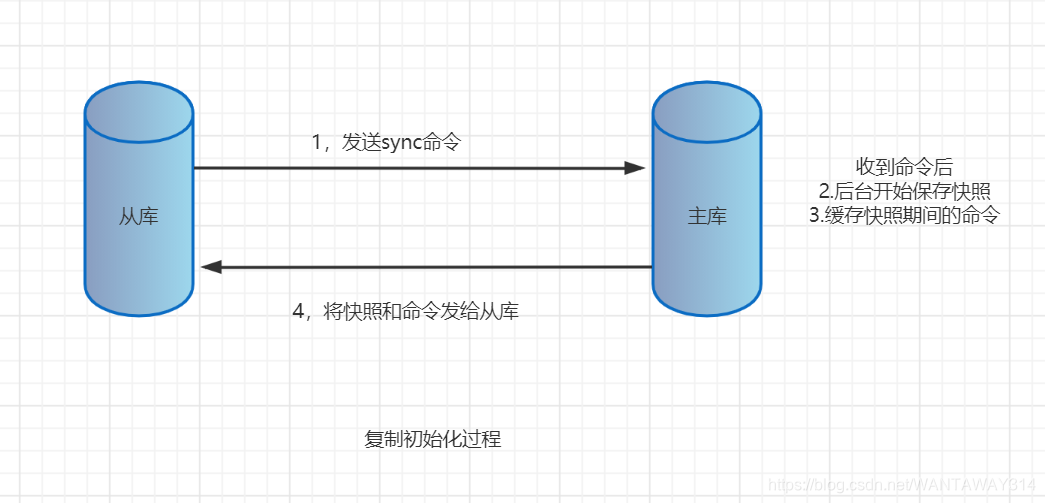
上面过程称为复制初始化。。复制初始化结束 后,主数据库每当收到写命令时就会将命令同步给从数据库,从而保证主从数据库数据一 致。
当主从数据库之间的连接断开重连后,Redis 2.6以及之前的版本会重新进行复制初始化 (即主数据库重新保存快照并传送给从数据库),即使从数据库可以仅有几条命令没有收到,主数据库也必须要将数据库里的所有数据重新传送给从数据库。这使得主从数据库断线 重连后的数据恢复过程效率很低下,在网络环境不好的时候这一问题尤其明显。Redis 2.8版 的一个重要改进就是断线重连能够支持有条件的增量数据传输,当从数据库重新连接上主数 据库后,主数据库只需要将断线期间执行的命令传送给从数据库,从而大大提高Redis复制的 实用性。
四、图结构
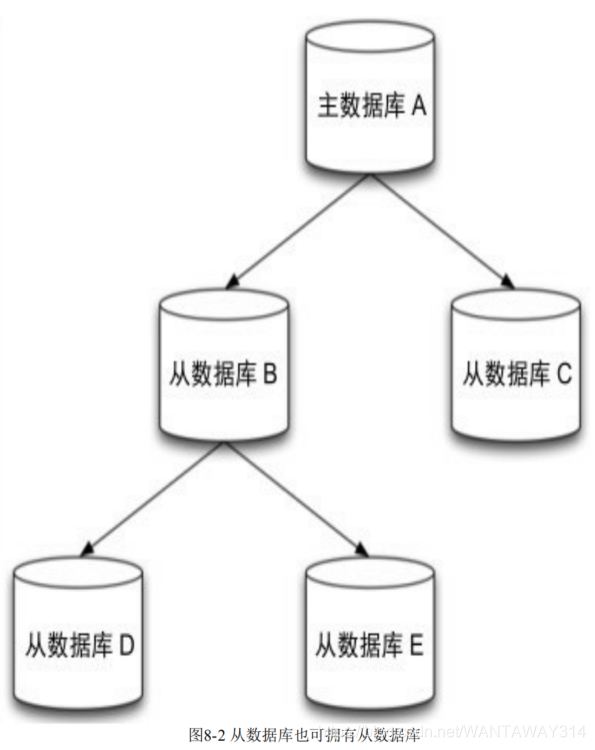
从数据库不仅可以接收主数据库的同步数据,自己也可以同时作为主数据库存在,形成 类似图的结构,如图所示,数据库A的数据会同步到B和C中,而B中的数据会同步到D和E 中。向B中写入数据不会同步到A或C中,只会同步到D和E中。
五、读写分离与一致性
通过复制可以实现读写分离,以提高服务器的负载能力。在常见的场景中(如电子商务 网站),读的频率大于写,当单机的Redis无法应付大量的读请求时(尤其是较耗资源的请
求,如 SORT 命令等)可以通过复制功能建立多个从数据库节点,主数据库只进行写操作, 而从数据库负责读操作。这种一主多从的结构很适合读多写少的场景,而当单个的主数据库 不能够满足需求时,就需要使用Redis 3.0 推出的集群功能,后续介绍;
六、从数据库持久化
另一个相对耗时的操作是持久化,为了提高性能,可以通过复制功能建立一个(或若干个)从数据库,并在从数据库中启用持久化,同时在主数据库禁用持久化。当从数据库崩溃重启后主数据库会自动将数据同步过来,所以无需担心数据丢失。
然而当主数据库崩溃时,情况就稍显复杂了。手工通过从数据库数据恢复主数据库数据 时,需要严格按照以下两步进行:
- 在
从数据库中使用 SLAVEOF NO ONE命令将从数据库提升成主数据库继续服务。 - 启动之前崩溃的主数据库,然后使用SLAVEOF命令将其设置成新的主数据库的从 数据库,即可将数据同步回来。
注意 当开启复制且主数据库关闭持久化功能时,一定不要使用 Supervisor 以及类似的进程管理工具令主数据库崩溃后自动重启。同样当主数据库所在的服务器因故关闭时,也要避免直接重新启动。这是因为当主数据库重新启动后,因为没有开启持久化功能,所以数据库 中所有数据都被清空,这时从数据库依然会从主数据库中接收数据,使得所有从数据库也被 清空,导致从数据库的持久化失去意义。
无论哪种情况,手工维护从数据库或主数据库的重启以及数据恢复都相对麻烦,好在 Redis提供了一种自动化方案哨兵来实现这一过程,避免了手工维护的麻烦和容易出错的问 题。
七、无硬盘复制
前面介绍Redis复制的工作原理时介绍了复制是基于RDB方式的持久化实现的,即主数 据库端在后台保存 RDB 快照,从数据库端则接收并载入快照文件。这样的实现优点是可以 显著地简化逻辑,复用已有的代码,但是缺点也很明显。
- 当主数据库禁用RDB快照时(即删除了所有的配置文件中的save语句),如果执行 了复制初始化操作,Redis依然会生成RDB快照,所以下次启动后主数据库会以该快照恢复数 据。因为复制发生的时间不能确定,这使得恢复的数据可能是任何时间点的。
- 因为复制初始化时需要在硬盘中创建RDB快照文件,所以如果硬盘性能很慢(如 网络硬盘)时这一过程会对性能产生影响。举例来说,当使用 Redis 做缓存系统时,因为不 需要持久化,所以服务器的硬盘读写速度可能较差。但是当该缓存系统使用一主多从的集群 架构时,每次和从数据库同步,Redis都会执行一次快照,同时对硬盘进行读写,导致性能降 低。
因此从2.8.18版本开始,Redis引入了无硬盘复制选项,开启该选项时,Redis在与从数据 库进行复制初始化时将不会将快照内容存储到硬盘上,而是直接通过网络发送给从数据库, 避免了硬盘的性能瓶颈。
目前无硬盘复制的功能还在试验阶段,可以在配置文件中使用如下配置来开启该功能: repl-diskless-sync yes
八、增量复制
前面在介绍复制的原理时提到当主从数据库连接断开后,从数据库会发送SYNC命令 来重新进行一次完整复制操作。这样即使断开期间数据库的变化很小(甚至没有),也需要 将数据库中的所有数据重新快照并传送一次。在正常的网络应用环境中,这种实现方式显然 不太理想。Redis 2.8版相对2.6版的最重要的更新之一就是实现了主从断线重连的情况下的增量复制。
增量复制是基于如下3点实现的.
- 从数据库会存储主数据库的运行ID(run id)。每个Redis 运行实例均会拥有一个 唯一的运行ID,每当实例重启后,就会自动生成一个新的运行ID。
- 在复制同步阶段,主数据库每将一个命令传送给从数据库时,都会同时把该命令 存放到一个积压队列(backlog)中,并记录下当前积压队列中存放的命令的偏移量范围。
- 同时,从数据库接收到主数据库传来的命令时,会记录下该命令的偏移量。
这3点是实现增量复制的基础。回到之前的主从通信流程,可以看到,当主从连接准 备就绪后,从数据库会发送一条 SYNC 命令来告诉主数据库可以开始把所有数据同步过来 了。而 2.8 版之后,不再发送 SYNC命令,取而代之的是发送 PSYNC,格式为“PSYNC主数 据库的运行 ID 断开前最新的命令偏移量”。主数据库收到 PSYNC命令后,会执行以下判断 来决定此次重连是否可以执行增量复制。
- 首先主数据库会判断从数据库传送来的运行ID是否和自己的运行ID相同。这一步 骤的意义在于确保从数据库之前确实是和自己同步的,以免从数据库拿到错误的数据(比如 主数据库在断线期间重启过,会造成数据的不一致)。
- 然后判断从数据库最后同步成功的命令偏移量是否在积压队列中,如果在则可以 执行增量复制,并将积压队列中相应的命令发送给从数据库。
如果此次重连不满足增量复制的条件,主数据库会进行一次全部同步(即与Redis 2.6的 过程相同)。
大部分情况下,增量复制的过程对开发者来说是完全透明的,开发者不需要关心增量复 制的具体细节。2.8 版本的主数据库也可以正常地和旧版本的从数据库同步(通过接收SYNC 命令),同样 2.8 版本的从数据库也可以与旧版本的主数据库同步(通过发送 SYNC命 令)。唯一需要开发者设置的就是积压队列的大小了。
积压队列在本质上是一个固定长度的循环队列,默认情况下积压队列的大小为 1 MB, 可以通过配置文件的repl-backlog-size选项来调整。很容易理解的是,积压队列越大,其允许 的主从数据库断线的时间就越长。根据主从数据库之间的网络状态,设置一个合理的积压队 列很重要。因为积压队列存储的内容是命令本身,如 SET foo bar,所以估算积压队列的大小 只需要估计主从数据库断线的时间中主数据库可能执行的命令的大小即可。
与积压队列相关的另一个配置选项是repl-backlog-ttl,即当所有从数据库与主数据库断开 连接后,经过多久时间可以释放积压队列的内存空间。默认时间是1小时。
















 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











