








关于本文是对POTATO库的介绍。POTATO 是一个独立于语言的human-in-the-loop XAI(可解释 AI)框架,用于提取和评估自然语言处理 (NLP) 中任何分类问题的可解释图特征。
文章包括:
- 1.基于规则的文本分类方法的简短介绍
- 2.在 POTATO 中定义图形模式简介
- 3.自动学习模式
- 4.human-in-the-loop (HITL) 框架
1.基于规则的文本分类方法的简短介绍
目前,文本处理任务(与许多其他领域一样)由机器学习模型主导。但随着这些模型的参数呈指数增长,可解释性下降。
可解释模型具有以下特征 [1]:
- 公平—— 无偏见的预测
- 隐私——更少的信息泄露
- 可靠性—— 输入的微小变化不会严重影响输出
- 信任、可审计性——我们知道是什么导致了预测
- 可调试——如果生产中发生错误,我们可以更改模型
最近在公共基准测试中取得最先进结果的 NLP 解决方案依赖于具有数百万参数的深度学习 (DL) 模型(例如 BERT [2])。这些模型需要大量的训练数据,很难解释它们的决定 [3]。此外,深度学习模型存在从数据集中学习意外偏差的风险 [4]。基于规则的系统可以提供准确和透明的解决方案,但构建和维护可能具有挑战性且耗时。POTATO 是一个快速原型设计框架,支持创建基于规则的文本分类器。在 POTATO 中,我们不是使用机器学习模型直接学习任务,而是学习规则系统。使用这种方法,最终模型保持完全透明。
基于规则的系统
优点
- 基于规则的系统在设计上是可解释和可解释的
- 在“现实世界”应用程序中很受欢迎,不需要大量的前期投资(不需要 GPU)
- 完全可定制,可调试
缺点
- 难以维护
- 基准测试表现更差(基准测试由 DL 方法主导)
- 需要领域专业知识
- 维护和开发耗时
在 POTATO 中,我们尝试通过结合机器学习和规则系统来解决基于规则的模型的一些缺点:学习规则!
为了演示规则系统,我们将使用Semeval 2010 关系提取数据集中的示例。关系提取(RE)是从文本中提取实体之间的语义关系的任务。通常在两个实体之间定义。关系具有语义类别(例如,Destination、Component、Employed by、Founded by 等),任务是将关系分类到正确的类别中。
我们将只使用Entity-Destination标签。类的一个例子
- The diamond ring(entity1) was dropped into a trick-or-treater’s bag(entity2).
要定义规则,我们可以只使用一个简单的正则表达式:
r”entity1 .* dropped into .* entity2"但是仅使用正则表达式是一种幼稚的方法,因为我们对文本的结构(标记、语法类别等)一无所知。我们可以使用更高级的 python 包,例如spaCy 的 TokenMatcher或Holmes Extractor。有了它们,我们将能够定义一个更复杂的规则,将词性 (POS) 标签考虑在内(词的语法类别)
pattern = [{‘POS’: ‘VERB’},
{‘LOWER’: ‘into’},
{‘TEXT’: {‘REGEX’: ‘.*’}},
{‘LOWER’: ‘entity2’}]但是,我们可以在可以利用文本的底层图结构的图上写规则,而不是在文本的标记上编写规则。在 POTATO 中,我们使用networkx python 包来表示图。通过networkx,我们为图形表示提供了一个统一的接口,用户可以在任意图形上编写图形模式。在 POTATO 中,目前我们支持三种类型的图:AMR [5]、UD(使用 stanza 包 [6])和4lang [7]。在图 1 中可以看到一个示例模式,在图 2 中我们可以看到我们上面定义的示例的4lang图(The diamond ring was dropped into a trick-or-treater’s bag) 和应用的模式。
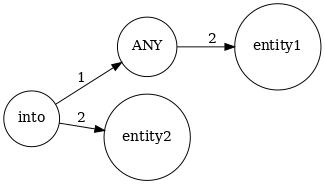
图 1:在图上定义的示例模式,ANY 节点表示我们匹配该节点中的任何字符串
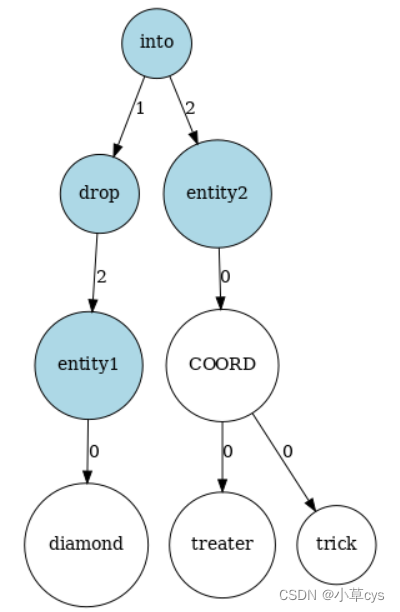
图 2:由文本和应用特征构建的 4lang [7] 语义图
与简单的正则表达式模式相反,此模式还将匹配以下示例:
The man placed the entity1 into the entity2.
Industries have pushed entity1 into fragile marine entity2.
I am putting the entity1 into a MySQL entity2.
The entity1 were released into the entity2.使用和设置
POTATO使用的是MIT license,MIT与其他开源许可证的区别:

POTATO 是一个用 python 编写的human-in-the-loop XAI 框架,它提供:
- 用于多个图形库(4lang、stanza、AMR)的统一 networkx 接口
- 用于学习和评估可解释图特征作为规则的 python 包
- 内置在streamlit中的 Human-in-the-loop (HITL) UI 框架
- REST-API 在生产模式下使用提取的特征进行推理
我们所有的组件都是在 MIT 许可下开源的,可以使用 pip 安装。
该工具严重依赖tuw-nlp存储库来构建图形和匹配特征。您可以使用 pip 安装 tuw-nlp:
pip install tuw-nlp
然后按照说明设置软件包。
注意:此处需要安装Graphviz
On Windows and Mac, you might also need to install Graphviz manually.
还需要安装几个库
You will also need some additional steps to use the library:
Download nltk stopwords:
import nltk
nltk.download('stopwords')Download stanza models for UD parsing:
import stanza
stanza.download("en")
stanza.download("de")And then finally download ALTO and tuw_nlp dictionaries:
import tuw_nlp
tuw_nlp.download_alto()
tuw_nlp.download_definitions()然后从 pip 安装 POTATO:
pip install xpotato
先引入库 potato:
from xpotato.dataset.dataset import Dataset
from xpotato.models.trainer import GraphTrainer我们将通过从 Semeval 数据集 [8] 中手动挑选的几句话来演示 POTATO 的功能。

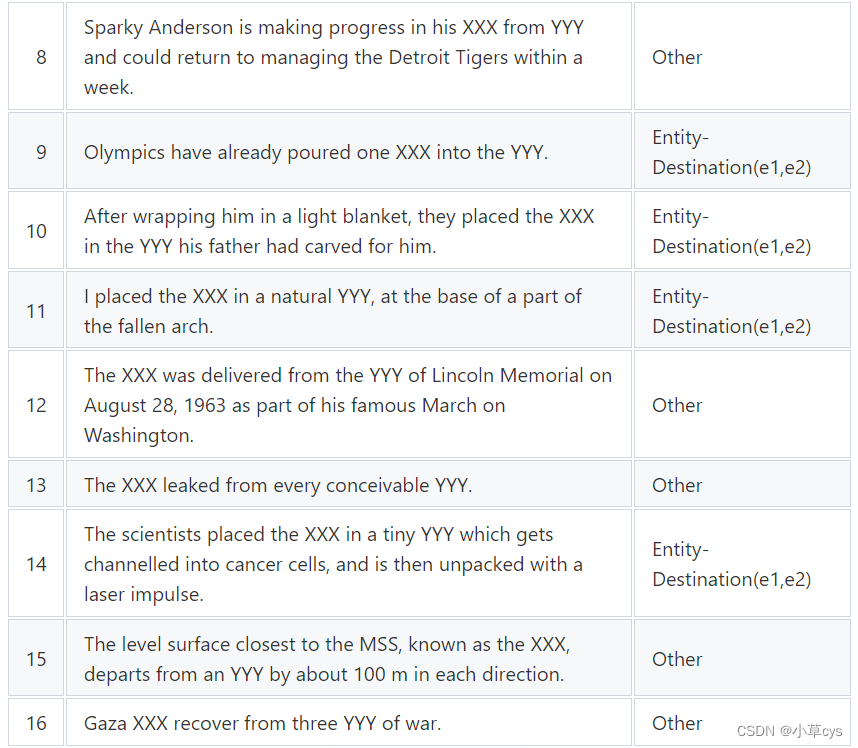
表 1:Semeval 2010 关系提取数据集 [8]中的例句
potato_example.md · GitHub
请注意,我们用XXX和YYY替换了有问题的两个实体。
然后,下一步是初始化数据集并提供标签编码。然后将句子解析成图形,为此我们可以使用parse_graphs()方法(也需要选择图形格式)。目前我们提供三种类型的图:ud、fourlang、amr。您还提供要解析的语言。目前我们支持英语(en)和德语(de)。
我们将使用表 1 中的示例(我们将引用具有在第一列中指定的 id 的示例)。在 python 中初始化的示例可以使用以下代码完成:
sentences = [("Governments and industries in nations around the world are pouring XXX into YYY.", "Entity-Destination(e1,e2)"),
("The scientists poured XXX into pint YYY.", "Entity-Destination(e1,e2)"),
("The suspect pushed the XXX into a deep YYY.", "Entity-Destination(e1,e2)"),
("The Nepalese government sets up a XXX to inquire into the alleged YYY of diplomatic passports.", "Other"),
("The entity1 to buy papers is pushed into the next entity2.", "Entity-Destination(e1,e2)"),
("An unnamed XXX was pushed into the YYY.", "Entity-Destination(e1,e2)"),
("Since then, numerous independent feature XXX have journeyed into YYY.", "Other"),
("For some reason, the XXX was blinded from his own YYY about the incommensurability of time.", "Other"),
("Sparky Anderson is making progress in his XXX from YYY and could return to managing the Detroit Tigers within a week.", "Other"),
("Olympics have already poured one XXX into the YYY.", "Entity-Destination(e1,e2)"),
("After wrapping him in a light blanket, they placed the XXX in the YYY his father had carved for him.", "Entity-Destination(e1,e2)"),
("I placed the XXX in a natural YYY, at the base of a part of the fallen arch.", "Entity-Destination(e1,e2)"),
("The XXX was delivered from the YYY of Lincoln Memorial on August 28, 1963 as part of his famous March on Washington.", "Other"),
("The XXX leaked from every conceivable YYY.", "Other"),
("The scientists placed the XXX in a tiny YYY which gets channelled into cancer cells, and is then unpacked with a laser impulse.", "Entity-Destination(e1,e2)"),
("The level surface closest to the MSS, known as the XXX, departs from an YYY by about 100 m in each direction.", "Other"),
("Gaza XXX recover from three YYY of war.", "Other"),
("This latest XXX from the animation YYY at Pixar is beautiful, masterly, inspired - and delivers a powerful ecological message.", "Other")]dataset = Dataset(sentences, label_vocab={"Other":0, "Entity-Destination(e1,e2)": 1})
dataset.set_graphs(dataset.parse_graphs(graph_format="fourlang"))检查数据集:
df = dataset.to_dataframe()
我们还可以检查任何解析的图
from xpotato.models.utils import to_dot
from graphviz import Source
Source(to_dot(dataset.graphs[0]))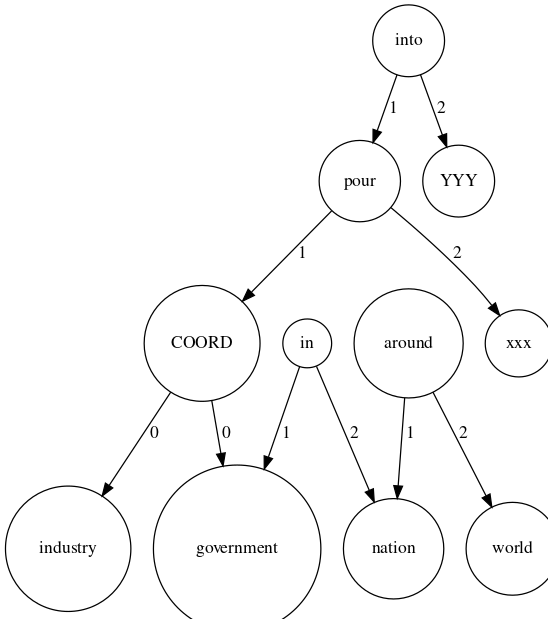
用 POTATO 编写规则
如果准备好数据集并解析图形,我们可以编写规则来匹配标签。我们可以手动编写规则,也可以自动提取它们(POTATO 还提供了一个前端,两者都可以)。
最简单的规则就是图中的一个节点(在本例中为 into):
# The syntax of the rules
# List[List[rules that we want to match]
# List[rules that shouldn't be in the matched graphs]
# Label of the rule
rule_to_match = [[["(u_1 / into)"], [], "Entity-Destination(e1,e2)"]]初始化规则匹配器:
from xpotato.graph_extractor.extract import FeatureEvaluator
evaluator = FeatureEvaluator()匹配数据集中的规则:
# The function will return a dataframe with the matched instances:
evaluator.match_features(df, rule_to_match)该函数将返回一个带有匹配示例的数据框。此规则将匹配其中包含节点into的任何句子。在我们的例子中,我们将匹配表 1 中编号为0、1、2、3、4、5、6、9、14 的示例(例如,科学家将 XXX 倒入品脱 YYY 中。)
我们工具的核心功能之一是我们还能够匹配子图。为了描述一个图,我们使用PENMAN符号。
例如,字符串(u_1 / into :1 (u_3 / pour))将描述一个具有两个节点(“into”和“pour”)以及在它们之间带有标签“1”的单个有向边的图。当我们只有一个节点作为特征时,使用字符串(u_1 / into :1 (u_2 / pour) :2 (u_3 / YYY))描述子图将只返回三个示例而不是 9 个。
#match a simple graph feature
evaluator.match_features(df, [[[“(u_1 / into :1 (u_2 / pour) :2 (u_3 / YYY))”], [], “Entity-Destination(e1,e2)”]])此功能将匹配示例 0、1、9。
我们还可以添加我们不想匹配的否定特征(这不会匹配存在 'pour' 的第一行):
<span style="background-color:#f2f2f2"><span style="color:rgba(0, 0, 0, 0.8)"><span style="color:#292929"><em># 匹配一个简单的图形特征和一个否定的特征。
#否定的特征进入第二个参数。
</em>evaluator.match_features(df, [[[“(u_1 / into :2 (u_3 / YYY))”], [“(u_2 / pour)”], “Entity-Destination(e1,e2)”]])</span></span></span>匹配示例 2、3、5、6。
如果我们不想指定节点,也可以使用正则表达式代替节点和边名:
<span style="background-color:#f2f2f2"><span style="color:rgba(0, 0, 0, 0.8)"><span style="color:#292929"><em># 正则表达式可用于匹配任何节点(这将匹配实例
# 其中 'into' 连接到任何具有 '1' 边的节点)
</em> evaluator.match_features(df, [[[“(u_1 / into :1 (u_2 / . *) :2 (u_3 / YYY))”], [], “实体-目的地(e1,e2)”]])</span></span></span>我们还可以从训练数据中细化正则表达式规则,这将自动将正则表达式“.*”替换为具有高精度的节点。
<span style="background-color:#f2f2f2"><span style="color:rgba(0, 0, 0, 0.8)"><span style="color:#292929">evaluator.train_feature("Entity-Destination(e1,e2)", "(u_1 / into :1 (u_2 / .*) :2 (u_3 / YYY))", df)</span></span></span>这将返回(u_1 / into :1 (u_2 / push|pour) :2 (u_3 / YYY))(将 '.*' 替换为push和pour)
人在环规则学习
POTATO的理念是:
- 使用子图作为训练简单分类器(LogReg、随机森林等)的特征
- 仅生成不超过一定边数的子图(以避免大量特征)
- 根据特征重要性向用户建议规则
- 用户可以通过 UI 接受、拒绝、编辑、组合模式
- 子图可能有正则表达式作为节点或边缘标签
- 可以细化未指定的子图
要从标记的数据集中自动提取规则,请使用图形特征训练数据集并根据相关性对其进行排名:
from sklearn.model_selection import train_test_split
train, val = train_test_split(df, test_size=0.2, random_state=1234)
trainer = GraphTrainer(train)
features = trainer.prepare_and_train(min_edge=1)features 变量将包含自动提取的规则:
<span style="background-color:#f2f2f2"><span style="color:rgba(0, 0, 0, 0.8)"><span style="color:#292929">(u_15 / into :1 (u_26 / push))
(u_15 / into :1 (u_19 / pour :2 (u_0 / xxx)))
(u_15 / into :1 (u_19 / pour))
(u_19 / pour :2 ( u_0 / xxx))
(u_15 / into :2 (u_3 / yyy))</span></span></span>用户界面
除了前面章节中描述的后端,POTATO 还带有一个 HITL 用户界面,允许用户从数据集中提取规则。为了启动 HITL 用户界面,我们需要将数据集加载为一组标记或未标记的图。除了我们预定义的格式(ud、4lang、amr)之外,任何有向图都可以加载。建议和评估规则需要 ground truth 标签(使用上一节中描述的特征学习方法),如果这些不可用,则可以在高级模式下启动 UI,以使用规则引导和注释标签。加载数据集后,可以启动 HITL 前端并向用户呈现图 3 所示的界面,该界面是使用streamlit库构建的。
图 3 所示的前端提供:
- 1 —允许用户查看数据集所有行的文本、图形和标签的数据集浏览器。查看器使用graphviz库呈现图形,还提供了 PENMAN 符号,用户可以复制该符号以快速编辑规则。
- 2 -用户可以选择要处理的类(如果处理多标签分类,则很少)。
- 3 -为每个类构建的规则列表保存在一个列表中,可以修改、删除或添加新功能。
- 4 —可以在训练和验证数据集上查看和评估规则。
- 5 —可以通过查看真阳性、假阳性或假阴性示例来分析每个规则的预测。
- 6 -按钮建议新规则返回一个建议图表列表及其在训练数据上的表现,允许用户选择应该添加到规则列表中的那些,这个界面如图 4 所示。对于包含正则表达式的规则,优化按钮将用高精度标签的析取替换正则表达式。该功能是使用上一节中描述的方法实现的。
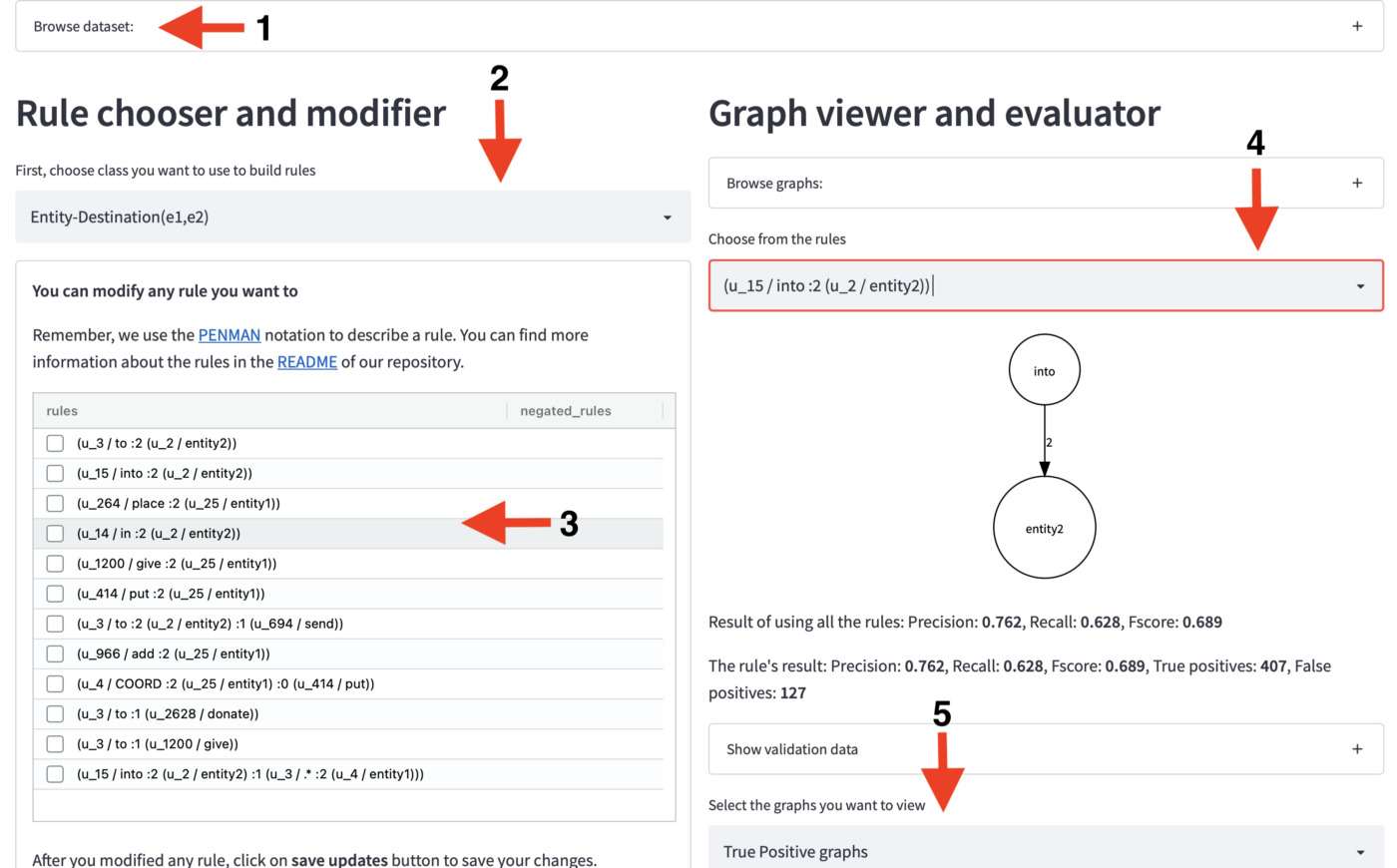
图 3:POTATO 的主页允许用户1浏览数据集并查看处理后的图形,2选择要在其上构建基于规则的系统的类,3修改、删除、添加新规则并获取建议,4查看所选规则的结果,每个规则的5 个视图示例预测
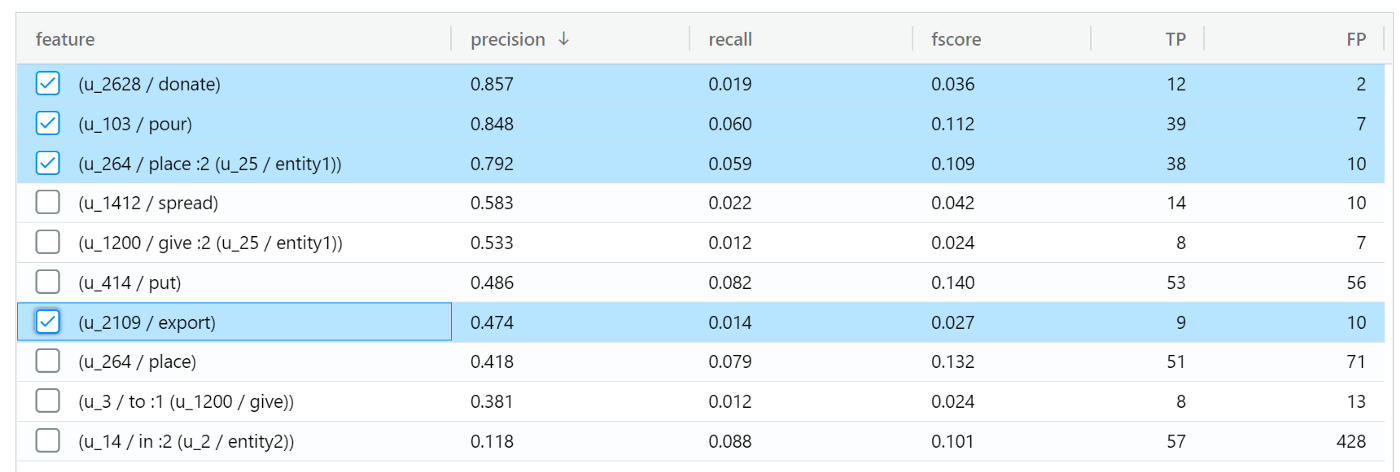
图 4:POTATO 建议的模式,按精度排序
如上所述,前端是一个流线型应用程序,我们可以从训练和验证数据集开始。首先使用以下代码保存它们:
train.to_pickle(“train_dataset.pickle”)
train.to_pickle(“val_dataset.pickle”)然后可以使用一行命令启动 streamlit 应用程序:
streamlit run frontend/app.py -- -t train_dataset.pickle -v val_dataset.pickle每个类的规则以 JSON 格式自动保存到磁盘,可以加载此文件以进行进一步编辑或推理。
streamlit run frontend/app.py -- -t notebooks/train_dataset -v notebooks/val_dataset -hr features.json高级模式
如果没有或只是部分提供标签,也可以在高级模式下启动前端,用户可以在开始时注释几个示例,然后系统根据提供的示例逐步提供规则。
然后,可以启动前端:
streamlit run frontend/app.py -- -t unsupervised_dataset -m advanced评估
如果您已经准备好功能并且想要在测试集上评估它们,您可以运行:
python scripts/evaluate.py -d test_dataset.pickle -f features.json结果将是一个带有标签和匹配规则的csv文件。
服务
如果您已准备好提取的特征并希望在生产中使用我们的包进行推理(为句子生成预测),我们还提供了一个基于 POTATO 的 REST API(基于fastapi)。
首先安装 FastAPI 和Uvicorn
pip install fastapi
pip install "uvicorn[standard]"要启动服务,您应该设置语言、图形类型和服务的功能。这可以通过环境变量来完成。
例子:
export FEATURE_PATH=/home/adaamko/projects/POTATO/features/semeval/test_features.json
export GRAPH_FORMAT=ud
export LANG=en然后,启动 REST API:
python services/main.py它将启动一个在localhost的8000端口上运行的服务(它还将初始化正确的模型)。
然后您可以使用任何客户端发出 post 请求:
curl -X POST localhost:8000 -H 'Content-Type: application/json' -d '{"text":"The suspect pushed the XXX into a deep YYY.\nSparky Anderson is making progress in his XXX from YYY and could return to managing the Detroit Tigers within a week."}'答案将是一个带有预测标签的列表(如果没有规则匹配,它将返回“NONE”):
["Entity-Destination(e1,e2)","NONE"]streamlit 前端还具有推理模式,其中实现的规则系统可用于推理。它可以从以下开始:
streamlit run frontend/app.py -- -hr features/semeval/test_features.json -m inference结论
POTATO 能够快速构建基于规则的系统,并为 NLP 任务的深度学习模型提供透明、可解释和可审计的替代解决方案。
翻译:https://towardsdatascience.com/using-potato-for-interpretable-information-extraction-f2081a717eb7
问题:
1.【问题已解决】,运行streamlit run frontend/app.py -- -t notebooks/train.tsv -v notebooks/val.tsv -g ud会报错,notebook中没有相关文件,是需要按步骤去训练出初步的数据根据GitHub - adaamko/POTATO: XAI based human-in-the-loop framework for automatic rule-learning.
之前的步骤一步步想办法运行即可,不能出错!
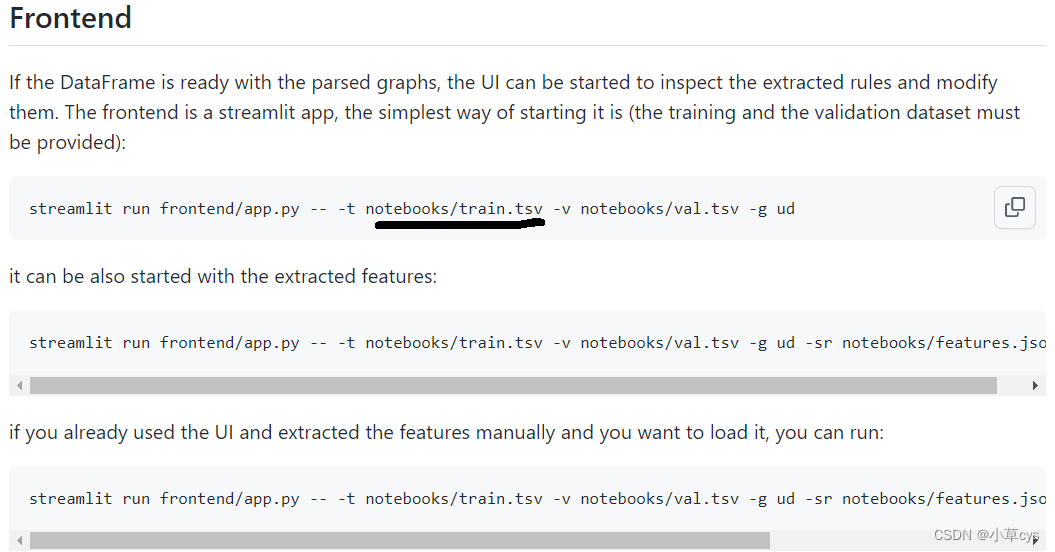
2.【已解决】这一个jupyter notebook文件presentation.ipynb没有给出,可以参考GitHub - adaamko/POTATO: XAI based human-in-the-loop framework for automatic rule-learning.写XAI based human-in-the-loop framework for automatic rule-learning. - GitHub - adaamko/POTATO: XAI based human-in-the-loop framework for automatic rule-learning. https://github.com/adaamko/POTATO
https://github.com/adaamko/POTATO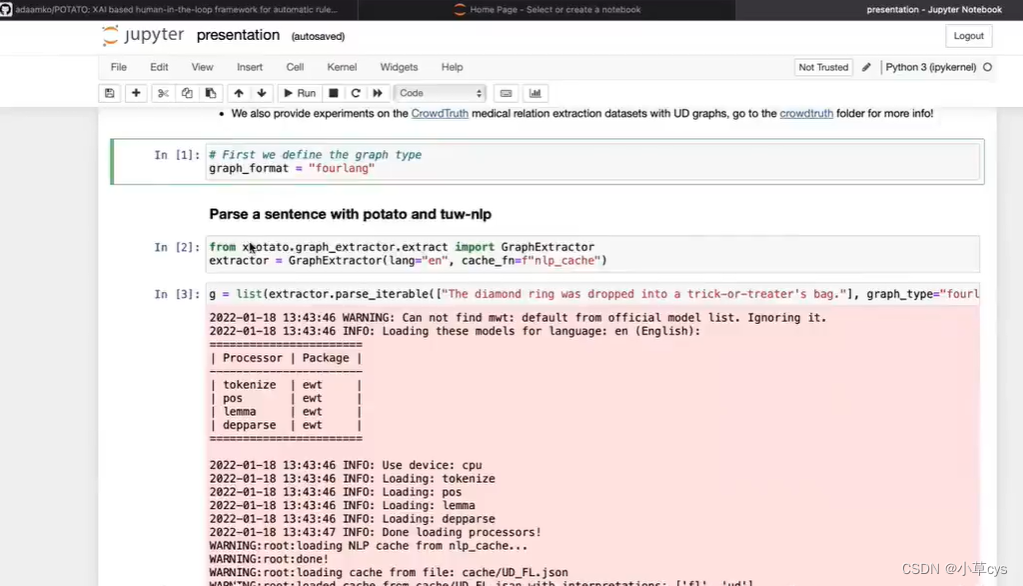
3.【问题已解决】Graphviz报错,make sure the Graphviz z executables are on your systems‘ path
解决方法:
1.卸载graphviz
pip uninstall graphviz
2.运行下面两条命令
sudo apt-get install graphviz
pip install graphviz补充:
F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的精确率和召回率。F1分数可以看作是模型精确率和召回率的一种调和平均,它的最大值是1,最小值是0。
F分数被广泛应用在信息检索领域,用来衡量检索分类和文档分类的性能。早期人们只关注F1 分数,但是随着谷歌、百度等大型搜索引擎的兴起,召回率和准确率对性能影响的权重开始变得不同,人们开始更关注其中的一种,所以F_\beta 分数得到越来越广泛的应用。F分数也被广泛应用在自然语言处理领域,比如命名实体识别、分词等,用来衡量算法或系统的性能。
F_\beta的物理意义就是将精准率和召回率这两个分值合并为一个分值,在合并的过程中,召回率的权重是精准率的\beta 倍 。F1 分数认为召回率和精准率同等重要,F2分数认为召回率的重要程度是精准率的2倍,而F0.5分数认为召回率的重要程度是精准率的一半。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









