









当组织开始采用人工智能、机器学习和大数据分析时,他们意识到这些技术都没有提供神奇的解决方案,可以在一夜之间改变他们业务的一切。事实上,要开始推动实际价值,它们需要对组织的文化、技术设置和运营模式进行根本的、长期的改变。可以实现成功转换的一个关键组件是数据目录,这是一种管理服务,可将您的数据组织在一个地方,并允许您使用元数据对其进行标记,以便您可以更有效地发现和管理它。
作为一直在帮助企业设计和构建强大的数据处理解决方案的人,我将分享我对一些最常见的数据目录的经验,以帮助您为您的组织选择正确的数据目录解决方案。
首先,让我们仔细看看数据目录及其帮助解决的挑战。
数据目录和数据发现和可观察性的挑战
今天,每个企业主都了解数据的重要性,以及它为您的公司和客户提供的宝贵见解。然而,随着数据量的爆炸式增长,找到正确的数据变得比以往任何时候都更加困难。您可以轻松地收集数据,但是数据处理、数据分析和 BI 等进一步的步骤呢?那么数据访问、数据发现、数据可观察性和数据治理呢?
事实上,大量精通技术的组织,更不用说任何数据和情报驱动计划的早期采用者,发现理解他们收集的数据、解释数据如何移动以及解释如何和不同业务部门使用数据的目的。
不幸的是,正确处理数据带来了许多挑战。这些包括:
- 难以找到和访问正确的数据
- 无效的数据收集:数据被转储与被组织
- 缺乏对整个组织中数据重要性的理解
- 数据处理效率低下:数据缺乏结构,难以理解
- 评估数据沼泽中数据的质量和可信度的效率低下
- 缺乏基础设施来捕获、增强和重用组织中的数据资产
- 依赖手动和临时数据准备工作
简而言之:数据变得过于复杂。专业人员需要越来越多的时间来高效、大规模地收集、处理、分析和管理数据。
更糟糕的是,现有的数据目录解决方案并不能完全满足 IT 组织和企业的需求。它们缺乏标准化的数据收集方法,与不同的目录不兼容,提供有限的数据沿袭,并且依赖于低效的数据质量和可观察性实践。
因此,数据科学家花费大量时间来发现可用的数据集并确保它们是可信的。数据科学和机器学习工程团队将大约 90% 的时间用于确保数据的清洁和可靠,以及调整、调试和维护为关键任务分析仪表板和机器学习模型提供动力的数据管道。企业被迫雇佣大量的数据专家,只是为了对数据集进行分类和管理。
数据发现、可靠性、可观察性和治理的挑战是真实存在的。领先的数据目录正在尽最大努力在这个领域有所作为。以下是一些我可以推荐用于数据和情报驱动的组织的数据目录。
企业顶级数据目录
让我们从开源数据目录解决方案的比较表开始,并继续更详细地研究它们中的每一个。请记住,我已经探索了近 30 家不同的数据目录供应商,并将其范围缩小到以下特色。
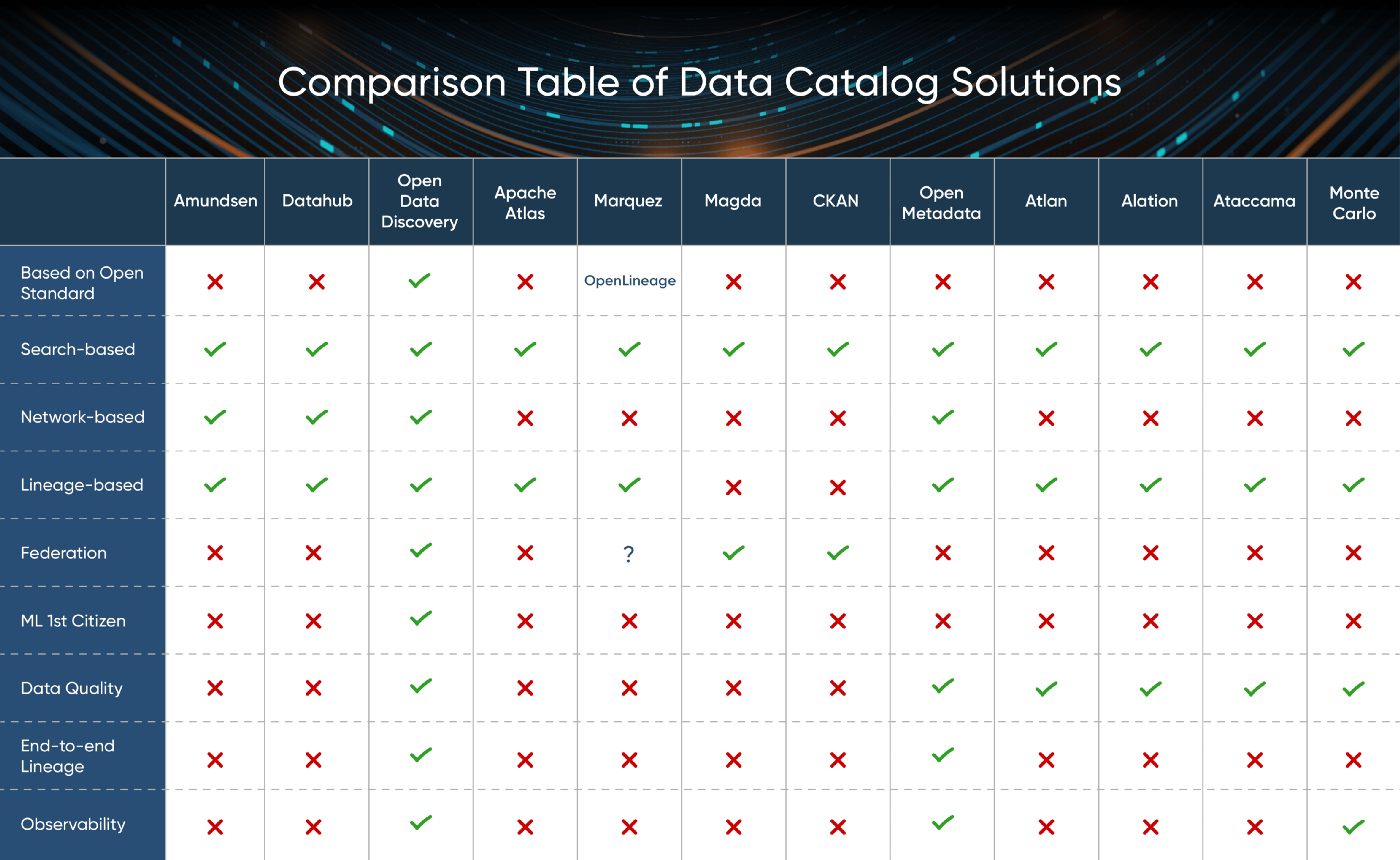
Amundsen
作者图片
- 优点:开源、良好的社区、广泛的文档
- 缺点:用户界面适中,缺乏机器学习实体
Amundsen是一个开源数据发现和元数据引擎,旨在满足分析师和数据科学家以及数据工程师和软件工程师的各种需求。该团队声称,他们的解决方案可以使数据工程师、数据分析师和数据科学家的工作效率提高 20%。
Amundsen 拥有一些最好的文档,开发人员称其为“数据编目领域的 Google”。它根据使用模式对数据进行排名。UI 本身的特点是适中的,因为它不提供空间和成本指标。但是,它确实提供了列统计信息和数据预览。它支持 Apache Hive、Amazon Redshift、Apache Druid、RDBMS、Presto、Snowflake 以及其 GitHub 页面上列出的其他几个。
注意: Amundsen 有一个名为Stemma的 SaaS 版本。它本身就是一个完全托管的数据目录,并为数据仓库、编排和转换、商业智能、协作、安全和 HR 系统提供了许多有用的集成。
Datahub
- 优点:开源、良好的用户界面、许多有用的功能(例如词汇表和域)
- 缺点:难以安装,自定义摄取协议
Datahub是由 LinkedIn 的人员构建的开源项目。它具有推拉功能,其用户界面现代且易于使用。这个数据目录的主要问题是它需要大量的基础设施工作,使得较小的团队难以实施。它不提供列统计信息或指标,一个小缺陷是它仅支持有限的源,包括 Apache Hive、Apache Kafka 和 RDBMS。
Datahub 有一个出色的演示,可让您以较小的规模试用该产品。它还有一个名为Metaphor的 SaaS 版本——一种现代的、可扩展的、云优先的数据目录和发现服务。
Open Data Discovery (ODD)
作者图片
- 优点:良好的用户界面,基于规范的摄取
- 缺点:一些功能仍在开发中
Open Data Discovery (ODD)是一个开源数据发现和可观察性平台。它旨在帮助数据驱动型企业通过使其更易于发现、可管理、可观察、可靠和安全来实现数据民主化。由于支持开放数据标准,ODD 使数据团队能够在各种数据工具之间进行更高效的数据交换。
该平台的 UI 相当不错,它的摄取是基于规范的。请记住,该平台正在开发中,因此某些功能仍在开发中。
阿帕奇阿特拉斯
作者图片
- 优点:开源,优秀的元数据模型
- 缺点:复杂的用户界面,有点过时
Apache Atlas是一个开放的元数据管理和治理生态系统,使企业能够在 Apache Hadoop 中满足其合规性要求。通过支持对数据进行分类和管理的许多集成,它允许组织构建具有各种数据资产的可扩展目录,并为数据科学家、分析师和工程师提供围绕这些数据资产的协作能力。
所有这些使 Apache Atlas 成为处理元数据的便捷工具。挑战在于它的生态系统有点过时(例如,从历史上看,这是一个遗留产品),并且为高级用户提供了复杂的 UI。
马尔克斯

作者图片
- 优点:开源、基于规范的摄取协议、运行的基础设施要求最低
- 缺点:用户界面适中,只有几个适配器
Marquez最初由 WeWork 创建,是一种开源元数据服务,使组织能够收集、聚合和可视化数据生态系统的元数据。它允许简化跨所有数据集的灵活数据沿袭查询。它支持推送功能并适用于 Amazon S3 应用程序。
Marquez 带有一个基本的 UI 和只有几个适配器。但是这些缺点可以通过方便的基于规范的摄取协议来弥补。该服务不需要高级基础架构即可运行。
注意: Datakin是 Marquez 的 SaaS 版本。它支持 Apache Hive、Amazon RDS、Teradata、Amazon Redshift、Amazon S3 和 Cassandra。
玛格达

作者图片
- 优点:开源,适合地理数据,深入的文档
- 缺点:缺乏大数据解决方案的适配器
Magda将自己定位为所有大数据和小数据(例如 Excel 和 CSV 文件)的联合开源数据目录。Magda 擅长的一个领域是地理空间和位置数据。如果您的组织使用地理位置,Magda 可能是您的最佳选择。它使用其 UI 支持推送功能,除了 Amundsen 之外,它是支持数据预览的少数几个之一。但请记住,缺乏大数据适配器可能是一个限制因素。
CKAN
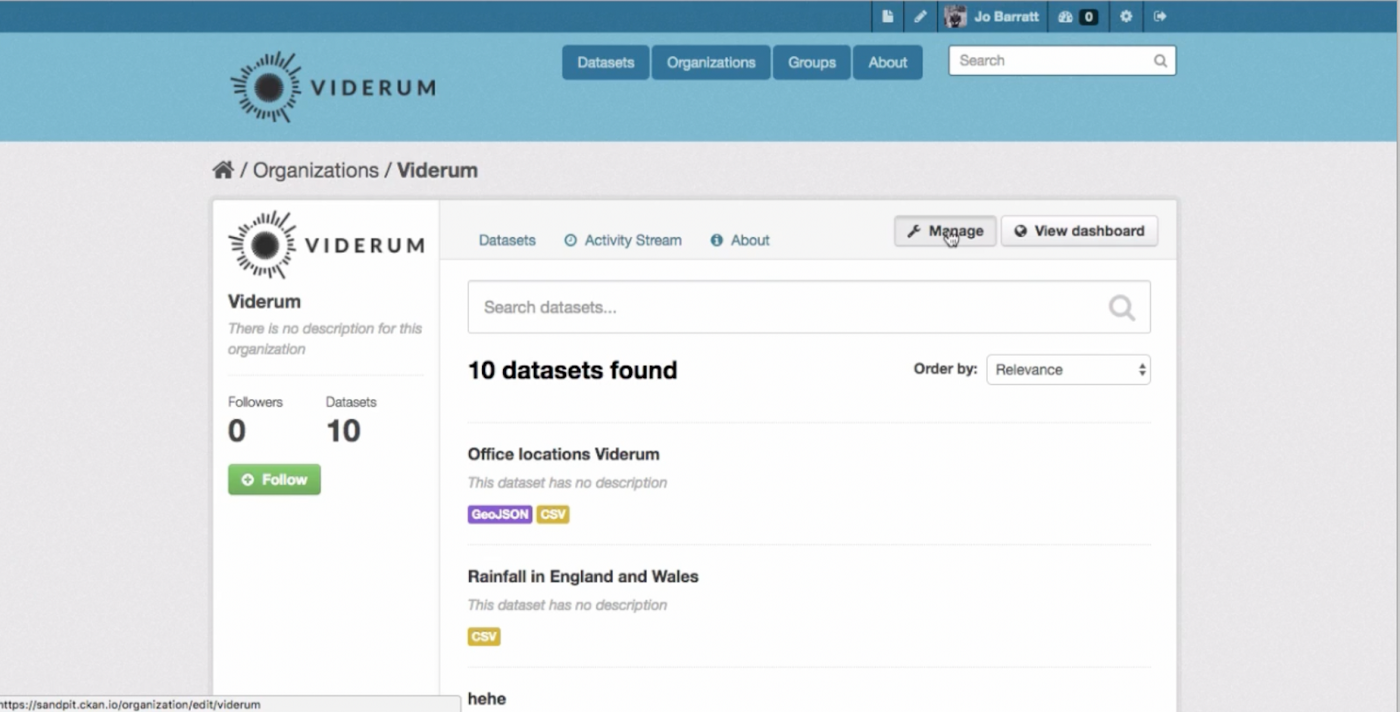
作者图片
- 优点:开源,完整的文档
- 缺点:缺乏大数据解决方案的适配器
CKAN是一个用于数据中心和门户的开源数据管理系统。它提供了使用 API 对数据集进行编目、存储和访问的功能,具有处理数据的工具、数据目录、可视化工具等。CKAN 以其丰富的文档和支持而闻名。但是,该工具缺少一些适用于大数据的适配器。
OpenMetadata
作者图片
- 优点:开源、良好的用户界面、快速的发布周期
- 缺点:安装复杂、自定义摄取协议、缺乏 ML 实体
OpenMetadata是元数据的开放标准,它为端到端元数据管理解决方案提供了基础。它包括数据发现和治理、数据质量和可观察性的所有必要组件。结合其优质的用户界面,这些功能确保了易用性和快速的发布周期。
然而,OpenMetadata 存在一些关键挑战。例如,它很难安装。它支持自定义摄取协议。最重要的是,它不包括机器学习实体,这可能是数据和人工智能驱动型企业的决定性因素。
Atlan
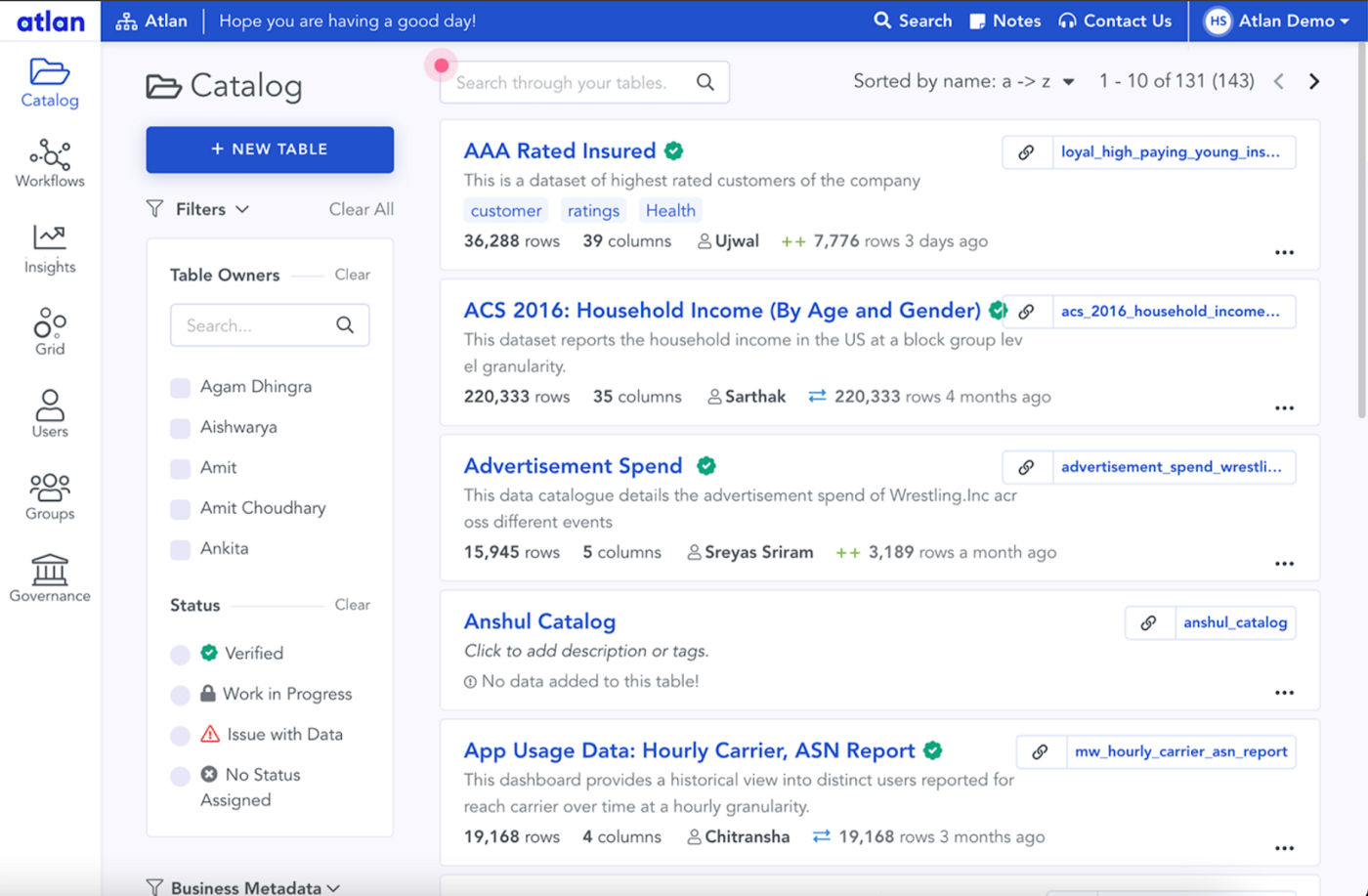
作者图片
- 优点:良好的用户界面、资金充足的初创公司、综合数据质量
- 缺点:自定义摄取协议(需要从 Atlan 云访问您的数据),缺乏 ML 实体
Atlan将自己描述为一个现代数据工作空间,可帮助数据团队协作并使其企业数据民主化,同时自动执行重复性任务。其平台由三个主要组件组成:数据目录和发现、数据沿袭和治理以及数据探索和集成。Atlan 的优点之一是它具有用于数据质量保证的集成组件。干净和公正的数据是高级分析和 AI/ML 项目的关键。
Atlan 落后的一个方面是其自定义摄取协议。您需要从 Atlan 云访问您的数据才能开始使用它。它还缺少一些 ML 实体。
Atlan 支持 Presto、Deequ、Atlas、Airflow 和 Hudi。
Alation
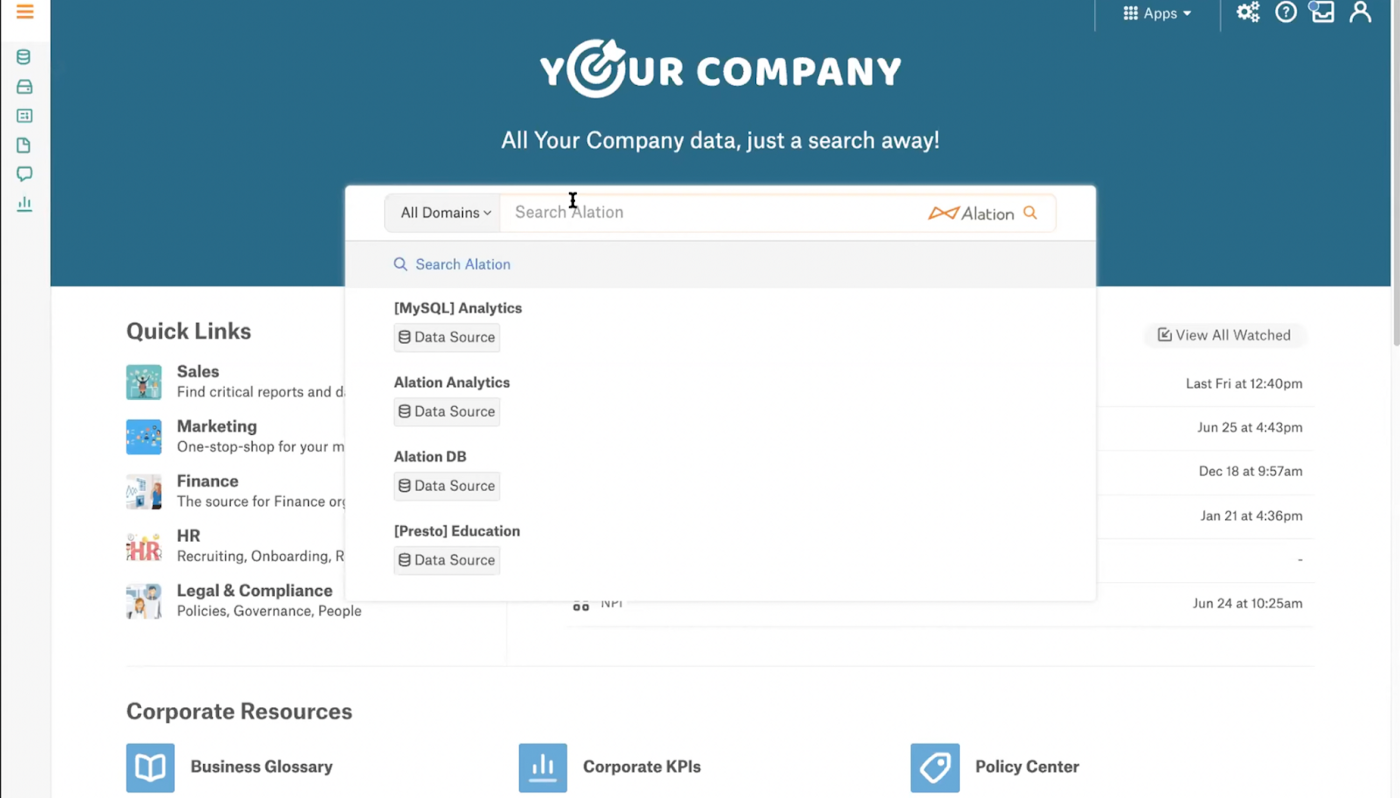
作者图片
- 优点:适当的用户界面,许多很棒的功能,如词汇表、政策等。
- 缺点:自定义摄取协议,缺乏 ML 实体
Alation是一个数据目录,它优先考虑处理数据的人为因素。它支持许多有用的功能,以加快入职、查询重用和自动管理。最重要的是,它的 UI 简单、一致且直观。但是,如果您要使用 Alation,请记住它具有自定义摄取协议并且缺少 ML 实体。这对于想要超越简单分析和商业智能,进入 AI/ML 领域的企业来说至关重要。
阿塔卡马
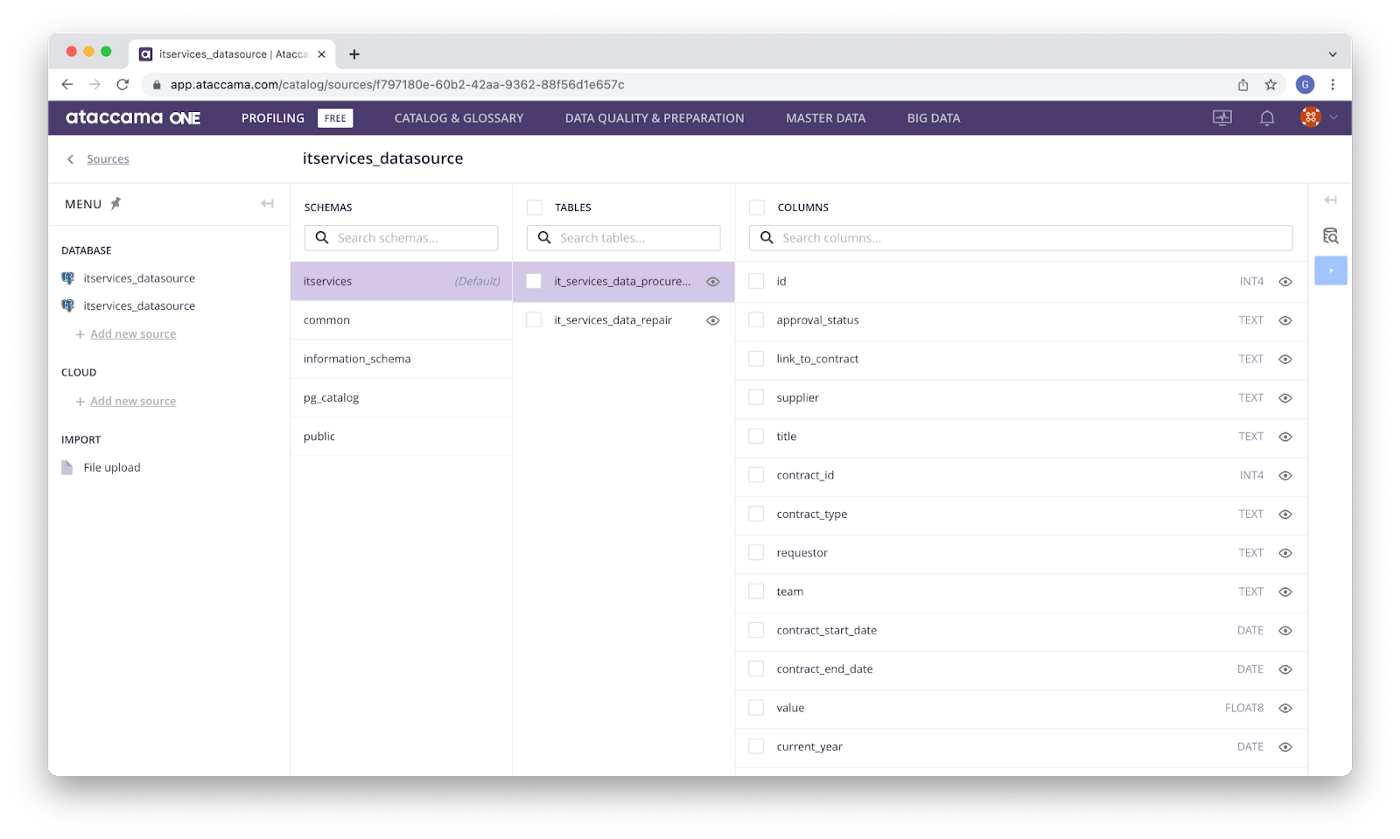
作者图片
- 优点:高质量的用户界面、集成的数据质量、SaaS
- 缺点:自定义摄取协议,缺乏 ML 实体
Ataccama是一个人工智能驱动的数据和元数据企业平台,具有数据质量、主数据管理和数据集成的组件。该平台的UI很好,它使快速分析团队、高度监管的治理团队和技术数据团队能够轻松处理他们的数据资产。Ataccama 的一大优点是它的设计非常注重数据质量。这对于敏捷、数据驱动的组织至关重要。
缺点是 Ataccama 将用户锁定,因为它需要自定义摄取协议。尽管情况正在发生变化,但它也缺乏某些用于机器学习的实体。
蒙特卡洛
作者图片
- 优点:不错的用户界面,数据可观察性功能
- 缺点:自定义摄取协议、缺乏 ML 实体、专注于数据可观察性而不是数据发现
Monte Carlo是一个数据平台,可帮助数据团队解决数据停机问题,使他们能够更有效地处理仪表板、更快地训练更准确的 ML 模型并推动分析操作。该平台广泛专注于机器学习驱动的数据可观察性,它为数据团队提供了查看数据和大规模识别潜在问题的高级能力。这使蒙特卡洛在数据可观察性方面比其竞争对手具有相当大的优势。
与许多其他专有数据目录解决方案一样,Monte Carlo 将用户锁定在其自己的数据摄取协议中。它还缺少某些 ML 实体,这可能会成为当今许多组织的交易破坏者。
结论
数据目录是数字、数据和 AI 转换的重要组成部分。它们将您的所有数据组织在一个地方,并为您提供更有效、更大规模地处理数据的工具。通过将数据目录整合到您的工作流程中,可以改进和简化数据发现、数据可观察性、数据治理和其他与数据相关的活动。
我探索了近 30 家不同的数据目录供应商,我们选择了几个首选,您可以使用它们来比较和对比不同的选项。其中一些是开源的,一些是专有的,因此您可以挑选并选择适合您的团队、组织或公司的解决方案。
参考https://medium.com/@gosin/finding-the-right-data-catalog-solution-a265a4b3c0c3


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









