






在此之前成功的CNN模型有个重要的特点就是他们的特征图冗余。本文目的是用ghost module通过很少的计算生成更多的feature map。在和mobilenet v3相似的计算量下, 取得了更好的表现(75% top1accuracy)
介绍:
例如从下图中可以看出resnet50生成的特征图

从图中可以看出有很多相似的。这就是特征图的冗余,上图中的工具就是ghost,以很少的计算获得新的特征图。实验结果表明,提出的ghost模块能够减少计算成本,同时保证相似的识别能力。本文提出了ghost module 和ghostnet。
related work:
模型压缩:模型压缩能够减少计算,能量和存储计算。
紧凑的模型设计:mobilenetv1,v2,v3,shufflenet。尽管这些模型取得了很少的floating point operations(flops)浮点数计算次数,但是特征图之间的相关性和冗余性没有被很好的利用,而且保留的1x1卷积仍然会占用内存和flops。
3方法:
3.1ghost模块:
输入是X(cxhxw),c是channel数,输出是Y(h‘xw’xn)
设卷积核大小为kxk,传统的卷积方式的浮点数计算为nh’w’ckk。

ghost模块:

步骤,假设目标是生成通道数为n的output。
** 首先按传统卷积生成identity map,通道数为m,大小<n,**
** 再对这通道数为m的identity map做处理,对它的每一层分别采用3x3或者5x5的卷积,就又生成一套通道数为m的特征图。重复操作共生成(s-1)套新的特征图。加上原来的identity map,共生成s套特征图,通道数为sm=n。**
复杂性分析:(输入是X(cxhxw),c是channel数,输出是Y(h‘xw’xn))
把传统卷积换成ghost后,理论的加速率:
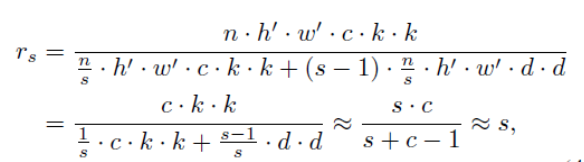
d是ghost中采用的卷积核size,k是普通卷积采用的卷积核size,s<<c。
模型压缩率:
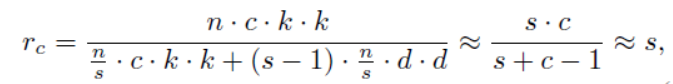
3.2ghost bottleneck

左图:第一个module增大channel,第二个module减小channel。channel最后和前面的shortpath匹配。shortpath中不变。
右图:shortpath中还需要进行下采样。
bottleneck和bottleneck之间的通道数变化通过ghost module中的第一个1x1的普通卷积实现。
3.3ghostnet
整体框架:
#exp为Ghost Bottleneck中第一个Ghost module的输出特征图数量

堆叠ghost bottleneck,在每个阶段的最后用stride=2的ghost bottleneck。
SE(squeeze and excite)module:
文中还使用了se模块,Sequeeze-and-Excitation(SE) block并不是一个完整的网络结构,而是一个结构快,可以嵌入到其他神经网络模型中。SEblock的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。

SEblock的工作就是将上图中左边的X特征图经过一系列运算得到上图中右边彩色的x̅,可将整个运算过程分为四步,接下来结合论文中的公式对这四个步骤做一个总结:
1.Ftr:Ftr这一步是转换操作,实际上它并不属于SEblock,在原网络中这一步仅仅是一个标准的卷积操作而已;且后面可以看到在定义SqueezeExcite函数时没有这一步操作。
2.Fsq:x经过 Ftr得到U。接下来是Squeeze操作,也就是简单的一个global average pooling:所以 Fsq 操作将H×W×C的输入转换成1×1×C 的输出,这一步相当于获取C个特征层的数值分布情况,或者叫全局信息。
3.Fex:这一步操作即是Excitation操作,计算过程将括号从里向外看。首先将第2步的结果Z乘以一个系数矩阵W1,这是一个简单的全连接层操作,W1的维度是C/r × C,这个r是一个缩放参数,目的是为了减少channel个数从而降低计算量z的维度是1×1×C,所以W1×z的结果就是1×1×C/r;然后再经过一个ReLU层,输出维度不变;
然后再与W2相乘,这也是一个全连接层操作。W2的维度是 C×C/r,因此输出的维度是1×1×C;最后再经过sigmoid函数得到结果s。这两个全连接层的作用就是融合各通道的feature map信息。
4.Fscale:第三步得到的结果s的维度是1×1×C。这个s其实是SEblock的核心,用它来刻画特征层U中的C个feature map的权重,而且这个权重是通过前面这些全连接层和非线性层学习得到的,因此可以end-to-end训练。
在得到s之后,就可以对原来的特征层U进行操作,即channel-wise multiplication。把Uc矩阵中的每个值都乘以Sc,故特征层U中的C个特征图都被S的每层对应的一个权重系数相乘。
经过以上四步后,将原始特征层X的每个通道分别乘以对应的权重系数,使得有效的特征图占比更大,无效或效果较小的特征图占比降低。整体来说仅仅是将特征图内的数值进行了调整,其大小及通道数均不发生改变。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









