






1.摘要:
提出了一个能够自动将低质量的图像(移动设备)转换到高质量图像(DSLR单反设备)的深度学习方法——WESPE。
这是一个弱监督的方法,不需要像之前强监督的转换方法,不需要将低质量和高质量的每一个图像进行配对。只需要提供一个低质量的数据集(来源手机),一个高质量的数据集(网络爬取),他们之间的视觉内容可以是无关的。
此外,训练了基于CNN的一个评估方法来模拟在Flickr数据集上人的打分,然后使用这个网络来获得原图和增强图的参考分数。
在一些开源数据集上做了实验:DPED,KITTI,cityscapes datasets,和几代智能手机。
2.介绍:
图像可以通过直方图均衡化,锐化,对比度等进行手工设计增强,但不符合大数据集的场景。
基于学习的方法,瓶颈是需要强监督,需要对高质量和低质量的图进行一一匹配,这通常限制了颜色、纹理转换和图像增强方法。
本文提出的方法能够将图像增强,不需要低质量图和高质量图的一一对应,只需要一个低质量数据集,一个高质量数据集。
做法是:改进了generative adversarial network(gan),和cnn:
1.使用cnn将增强后的图map回到原图空间,来减轻对真实标签图的配对需要
2.结合了颜色,内容和纹理损失的损失函数
本文的优点是很容易就能获取到两个数据集很快开始训练,而不用做配对。
贡献:在颜色,像素,和锐化等方面改进了图像质量:
1.WESPE方法:低质量-》高质量
2.一个cnn-gan的框架,结合了经典的loss和在输入图像上的内容loss
3.使用Flickr Faves Score(FFS)数据集(16K HD像素),包含相关的点赞数量,来训练一个单独的cnn网络来评估图像质量
3.方法:

网络的目标是学习到一个从低质量域X到高质量域Y的映射。网络主要组成是:
1.生成(generator)映射:G:X→Y
2.逆生成(inverse generator)映射:F:Y→X
3.两个判别网络(discriminator):Dc,Dt。
4.vgg19网络:测量输入图像x和**映射回来的 x ~ \widetilde{x} x **内容一致性
3.1损失函数:
1.content loss:
使用vgg19网络:测量输入图像x和映射回来的 x ~ \widetilde{x} x 内容一致性,使用content loss,这一部分规避了对原图和高质量图一一配对的需要,(我理解的是之前强监督的做了配对,他能让输入图像发生内容上的重大改变,但是现在是弱监督了,两者没有配对,如果不加限制,它在内容上就可能产生重大变化,于是加上增强后的图像和原图的一个内容上的一致性损失,致使内容不发生大的改变。)
损失函数为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2P0wOwsY-1637890304733)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/271750c6-689b-496c-b198-d8e2a16ab1fc/Untitled.png)]](https://img-blog.csdnimg.cn/781dc4f8be22468abc47a3ade7eb1fb7.png)
φj是vgg19网络的第j个卷积层的特征图,Cj,Hj,Wj分别是特征图的数量,高,宽
2.adversarial color loss(对抗颜色损失)
将增强后的图 y ~ \widetilde{y} y 和高质量图y通过高斯模糊,然后传入Dc判断网络,目的是为了让网络更加关注于二者之间的亮度,对比度,颜色差异,让网络能够判别出是增强后的图像还是高质量图。
颜色损失函数为:和gan的相同,是一个二分类的交叉熵损失函数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FXjW6b3H-1637890304739)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/e4d6c470-bf6d-4ad5-96cc-ff5f8ef00bc2/Untitled.png)]](https://img-blog.csdnimg.cn/3fe7a951da844fc7a94de1d89571ebfb.png)
例如:标签为1或者0,下图标签为1
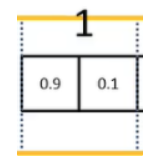
3.对抗纹理损失(adversarial texture loss):
将增强后的图 y ~ \widetilde{y} y 和高质量图y转为灰度图,这是为了让网络只关注二者的纹理信息,再传入Dt网络,计算纹理损失,和颜色损失函数类似:让网络能够判别出是增强后的图像还是高质量图。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2yyS8iWU-1637890304741)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/98ed32d1-59d1-4bec-8214-92851f91b634/Untitled.png)]](https://img-blog.csdnimg.cn/28abdbb079e143cf885dff269140e7cb.png)
4.TV loss(total variation loss):
为了让增强的图像更加平滑:使生成图像在x和y方向上的梯度之和变小
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7gBdQxgs-1637890304741)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/0bece935-e1ed-4066-bd14-873c09ba70e3/Untitled.png)]](https://img-blog.csdnimg.cn/b70b1cf5db0247daabfb87bb3a7cbc0e.png)
总的损失函数:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1vmuiRQB-1637890304742)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/48a8bf7f-ae85-43fd-9223-20e3c4525597/Untitled.png)]](https://img-blog.csdnimg.cn/6f6156dccd6f45d0ac800e9f7ca74bb4.png)
3.2一些训练细节:
输入图像块的尺寸为100x100
4.实验
通过实验评估wespe的能力和质量
4.1全参考评估:
比较增强后的图像和他们的目标图像(dslr拍的),使用的比较方法为:PSNR,和SSIM
这里使用DPED数据集,这个数据集是由3个低到终端手机iPhone 3GS, BlackBerry Passport、 Sony Xperia Z和高端的dslr相机canon 70D,并进行了 逐像素对应。
结果如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Kz1LQb4-1637890304743)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/5148e413-3e43-4a7b-9c1a-91f7b4e391f3/Untitled.png)]](https://img-blog.csdnimg.cn/ac51f4da6e8d4ae8bcc3e64dda71047d.png)
解释:APE为apple的增强方法之后的,wespe[div2k]是使用div2k数据集作为目标进行训练的,wespe[dped]是使用dped数据集作为目标进行训练的。最后一个为强监督的方法。
一个值得注意的点是:尽管wespe[dped]比wespe[div2k]的相似度高(理所当然嘛,最后使用的dped作为真实标签进行测试的,以dped作为target进行训练的网络取得的结果更接近),wesped[div2k]生成的图颜色更加鲜明。于是认为使用不同的数据集作为target进行训练是否能取得更好质量的增强图,于是有了下面一节用无参考的图像评价方法来对增强图像进行评价。
4.2无参考评价:
评价方法为**:image entropy,bit per pixel(bpp),CORNIA**(越低越好)
增加了一些数据集进来进行测试:这些数据集的质量如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D2vDm18F-1637890304743)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/600cfa96-3119-4a22-8f92-6b53c01882be/Untitled.png)]](https://img-blog.csdnimg.cn/d3e906ff8b1b4ffea615dcc2d6dcbe29.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBASFBVUFVQVVA=,size_20,color_FFFFFF,t_70,g_se,x_16)
对一些数据集的图像进行增强,结果如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KABTWCCK-1637890304744)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/cbe30b18-20a4-4fa6-813c-774c565090cf/Untitled.png)]](https://img-blog.csdnimg.cn/06559d9a559c4206baa5e93b7fa44501.png)
wespe【div2k】效果最好
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-heAVX49R-1637890304745)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/dee739c0-13df-482c-aa31-44548ad2021d/Untitled.png)]](https://img-blog.csdnimg.cn/d45ace46c3344ec78bb2d45a2801a38f.png)
4.3主观的评价方法
以上都是客观的分数,本文训练了一个神经网络来模拟人的打分。具体做法是:在flickr数据网站上取16k个图片,依据一张图片被喜欢的次数除以被浏览的次数,取中位数作为好图和坏图的打分。基于此训练一个二分类的网络,网络模型VGG19。
总图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EUwqTXvd-1637890304745)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/6f0acf6e-c3cc-4597-af3f-8b6f09c08f97/Untitled.png)]](https://img-blog.csdnimg.cn/9bfc07204ddd408288aa42a4a2c32c78.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBASFBVUFVQVVA=,size_20,color_FFFFFF,t_70,g_se,x_16)















 1515
1515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









