






1、传统消息队列的应用场景
传统消息队列的主要应用场景包括:缓存/削峰、解耦和异步通信
1.1 缓冲/消峰的应用场景:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
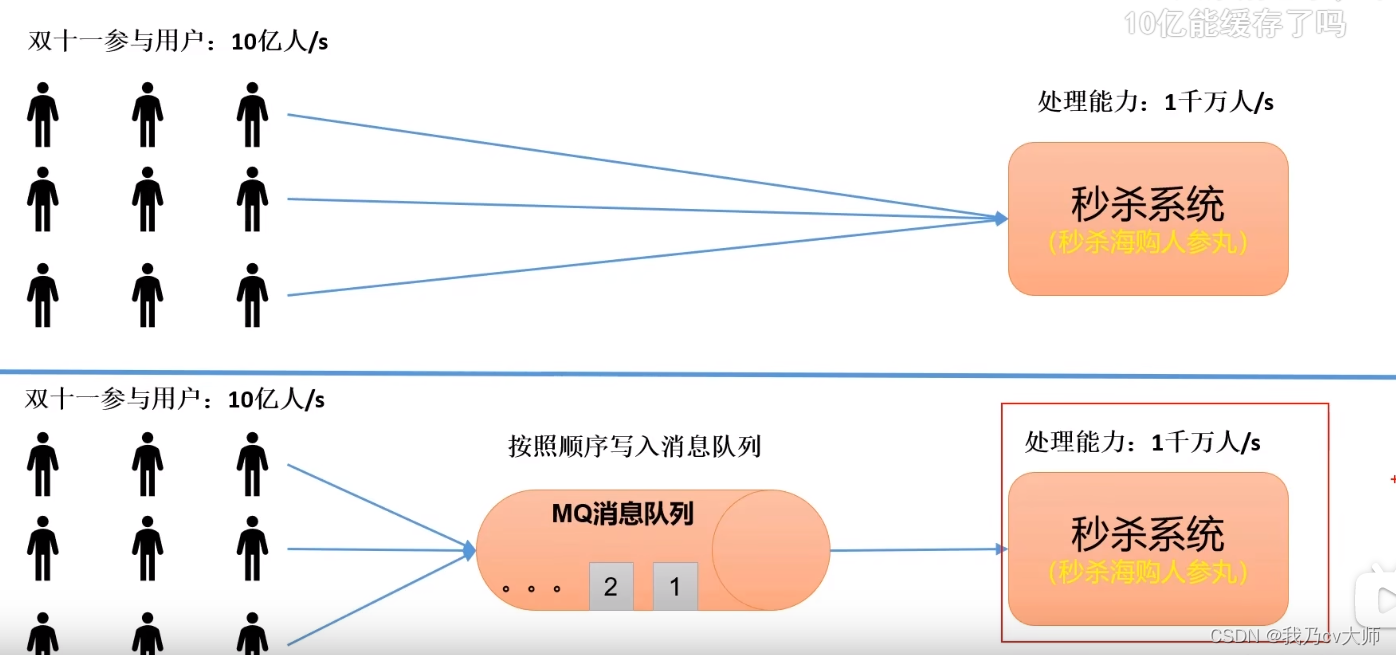
在用户高峰期,对于处理能力有限的服务器,突然遇到大量的用户进行访问;可以利用消息队列作为缓冲区,将用户的请求先存入消息队列中,再有服务器慢慢取出来进行响应。
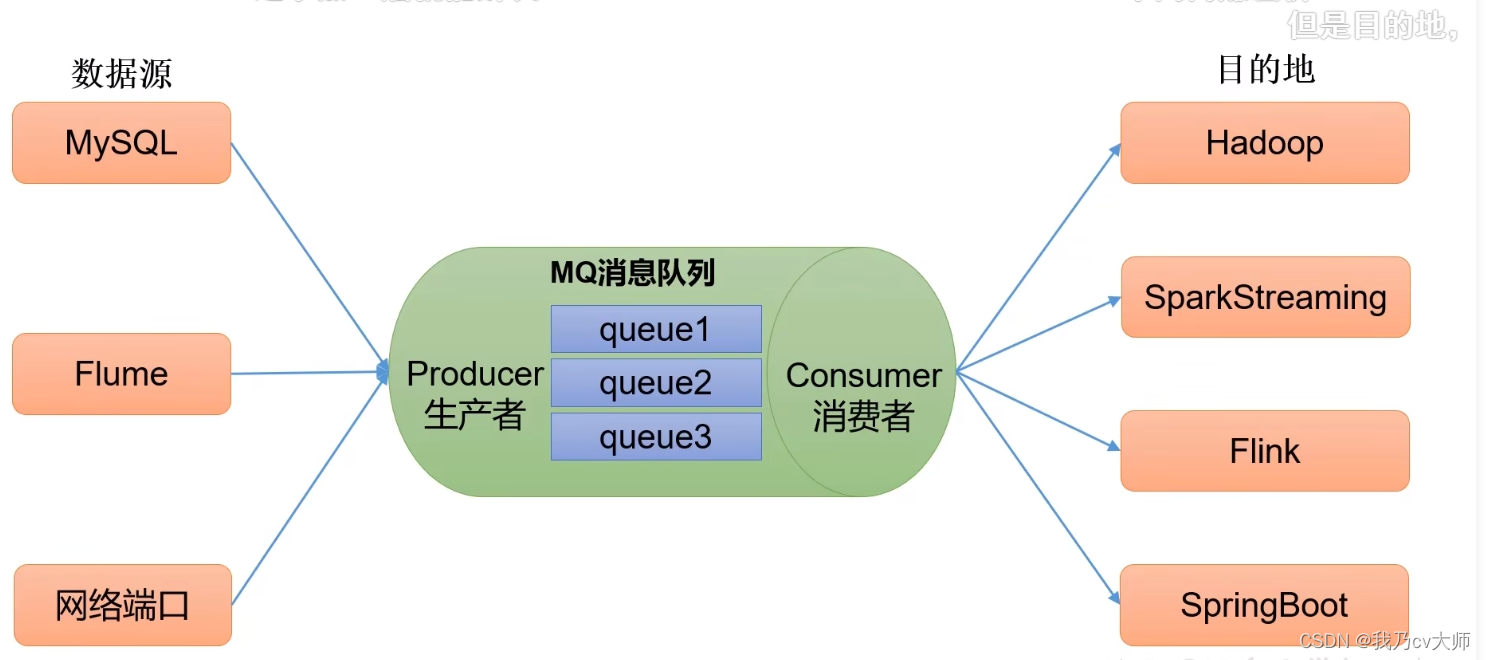
1.2 解耦的应用场景:
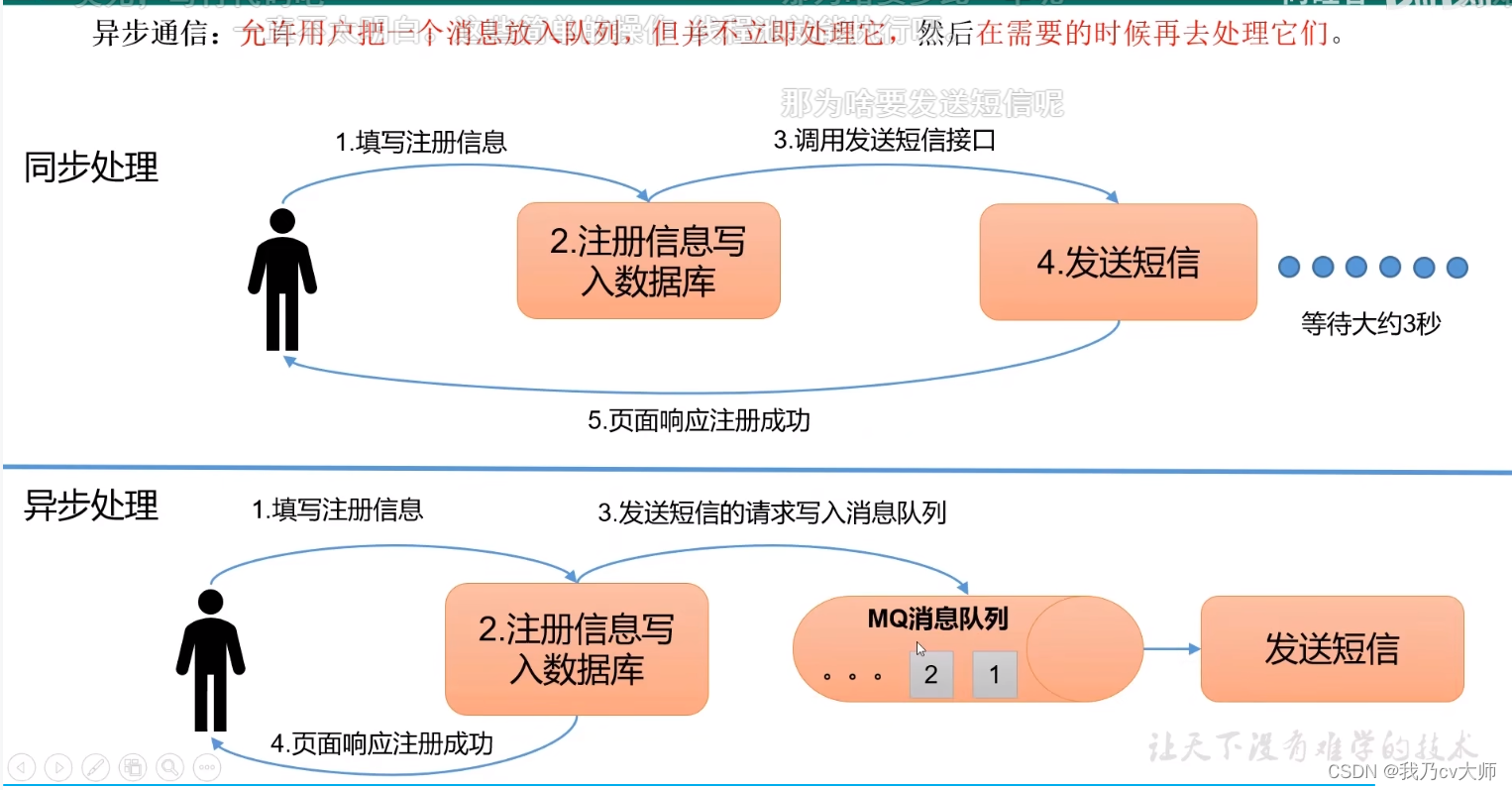
1.3 异步通信:
允许用户把一个消息放入消息队列,但不立即处理它,然后在需要的时候再去处理它
2、消息队列的两种模式
2.1、点对点模式
消费者主动拉取数据,消息收到后清除消息

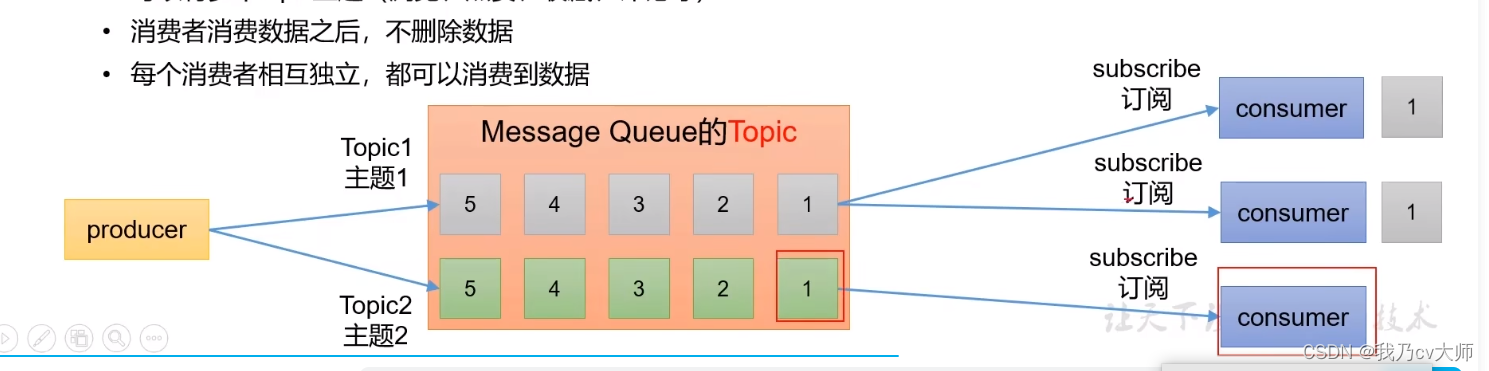
2.2 发布/订阅模式
可以有多个topic主题(浏览、点赞、收藏、评论等)
消费者消费数据之后,不删除数据
每个消费者相互独立,都可以消费到数据
3、基本架构
3.1、为了方便扩展,并提高吞吐量,kafka将一个topic分为多个partition
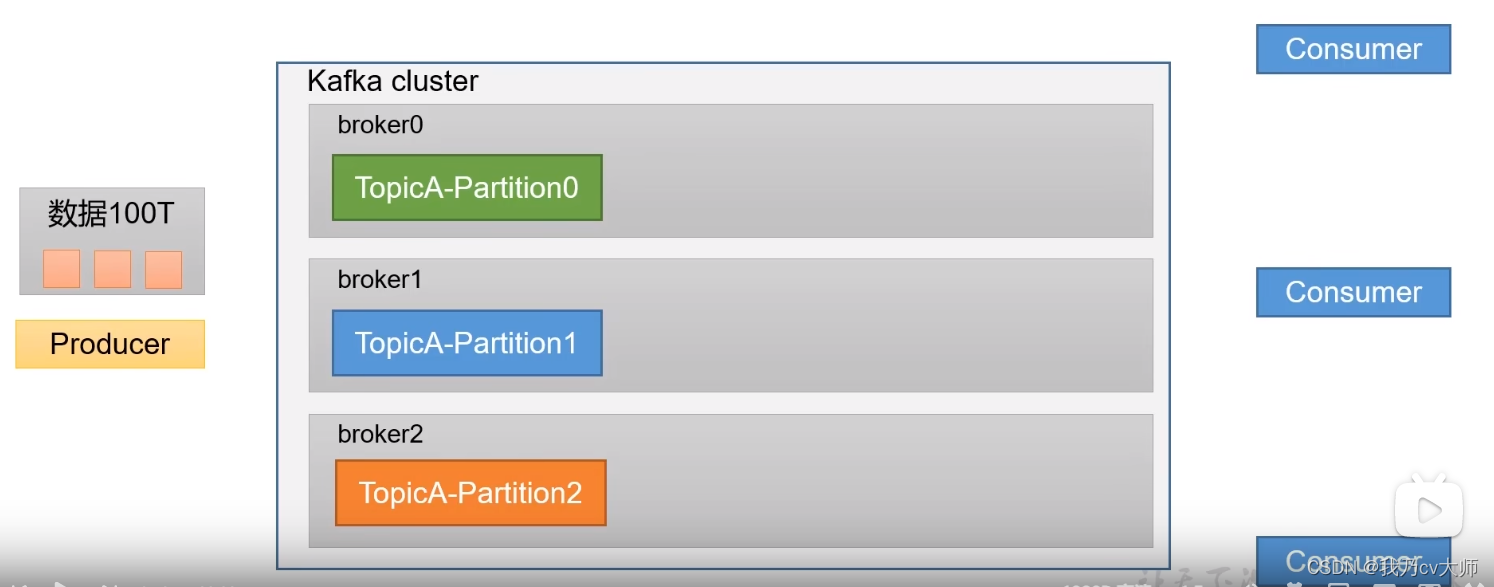
例子:如果生产者一下提供了一个100T大的数据量,一台服务器根本无法一次性存储那么多的数据量,即进行分区,将一个topic分为多个partition,将多个区分别部署在不同服务器上,每个区都存储一部分的数据,所有的区可以将100T的数据全部进行存储。
3.2 配合分区设计,提出消费者组的概念,组内每个消费者并行消费
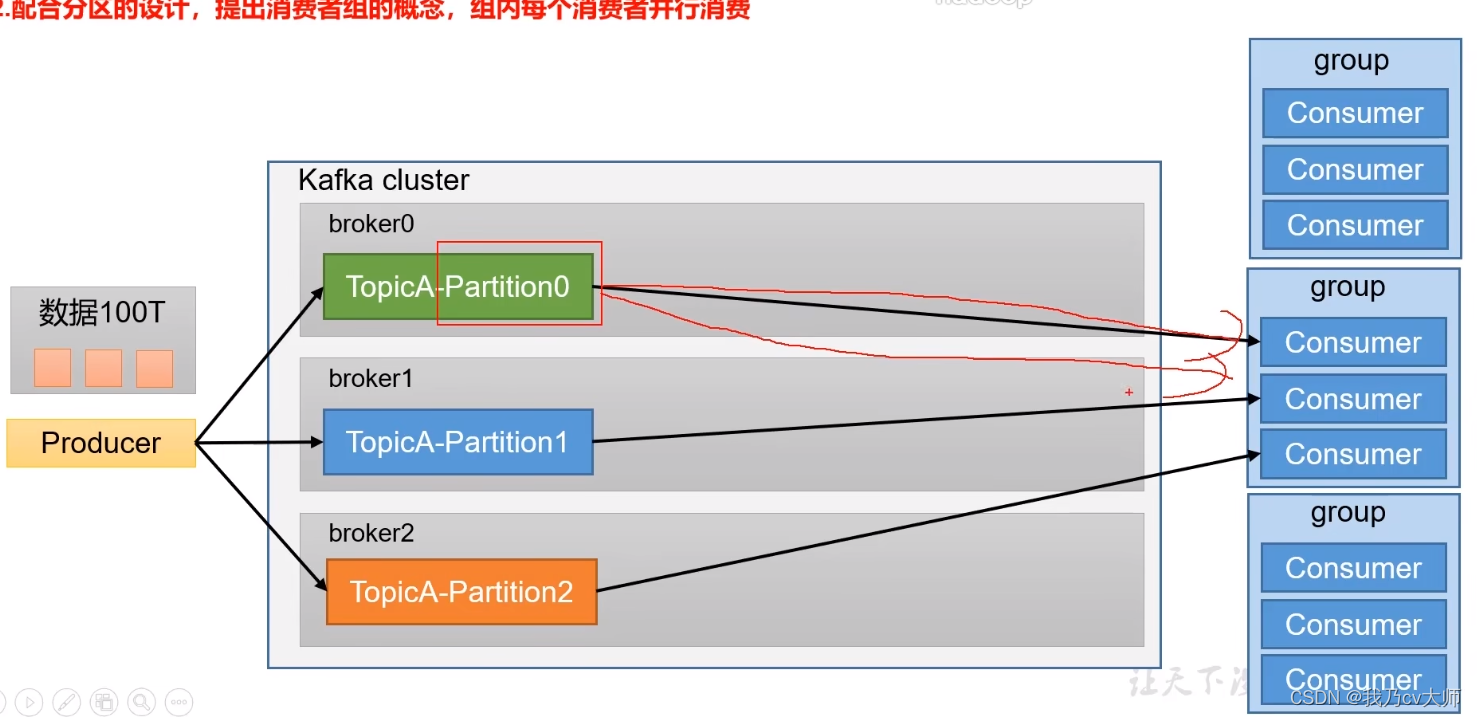
即分区可以对应着消费者组,即可以定义消费者组A,B,C。其中A用于消费分区1的数据、B用于消费分区2的数据,C用于消费分区3的数据。因此可以做到组内每个消费者进行并行消费。
3.3为了提可用性,可以为每个partition增加若干副本,类似NameNode HA
为了防止某分区挂掉,导致数据丢失,增加分区副本存储数据,当主节点挂掉,副本将成为主节点。
4、kafka 整体流程及原理
4.1 生产消息的流程
首先创建一个main线程,生产者在main线程内生产消息,到拦截器的时候,拦截器会对消费者进行一个处理(拦截器由开发者决定是否使用);经过序列化器,对消息进行序列化
到达分区器,分区器决定这个消息在缓冲区的哪一个分区中进行存储,方便数据的管理(在内存中进行操作)
当缓冲区的数据累积量到达batch.size后,sender才会发送数据;默认为16k(提升效率)
或者说达到一定时间进行发送:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间,到了之后就会发送数据。单位是ms,默认值是0ms,表示没有延迟
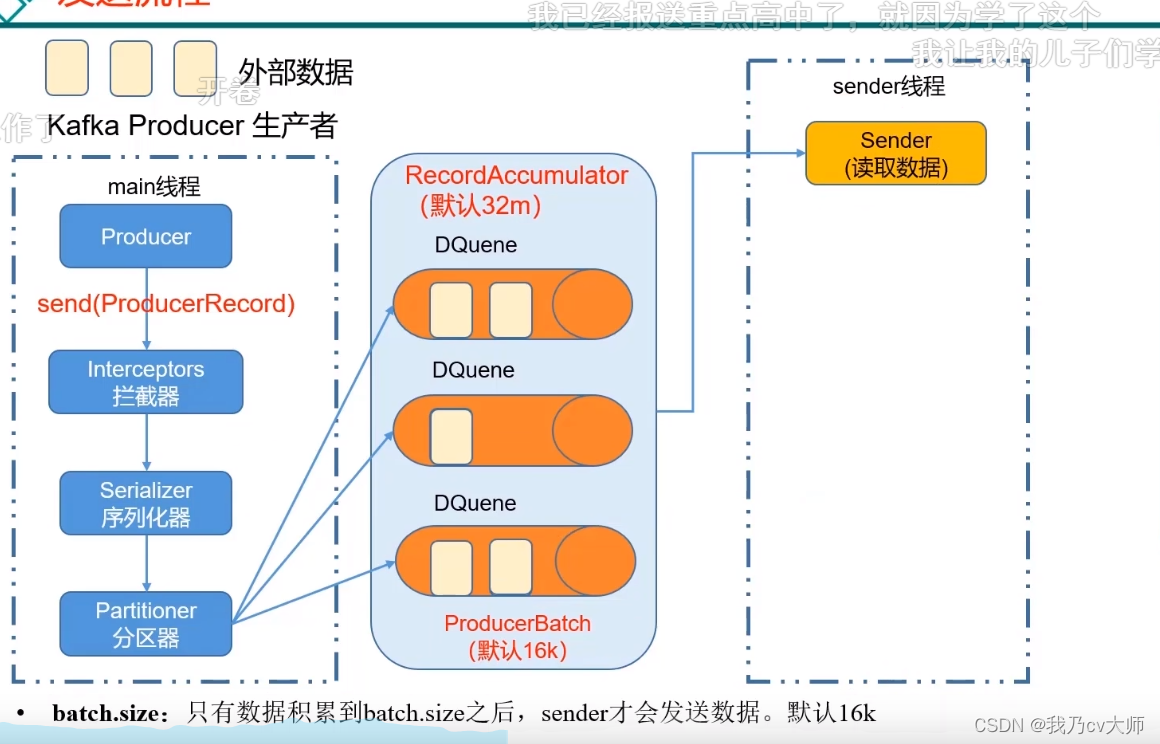
由sender线程将 数据发送到kafka集群,其中
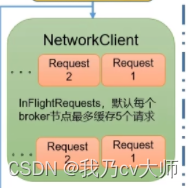
作为缓冲,当消息发送到集群中失败,会放在这里面作为缓冲存储,有效避免了一个数据发不过去而导致阻塞的问题;但是这个缓冲区最多只能缓存五个消息,当缓存的数据个数到达五个以后,缓冲区不再接收消息,队列阻塞住。
正常的话,就直接通过selector发送过去,sender线程与kafka集群之间还存在应答机制

如果消息发送给集群成功,则将各个地方缓冲区的对应数据进行清理和删除,如果失败了则进行重试

4.2 消费者
4.2.1消费者消费方式
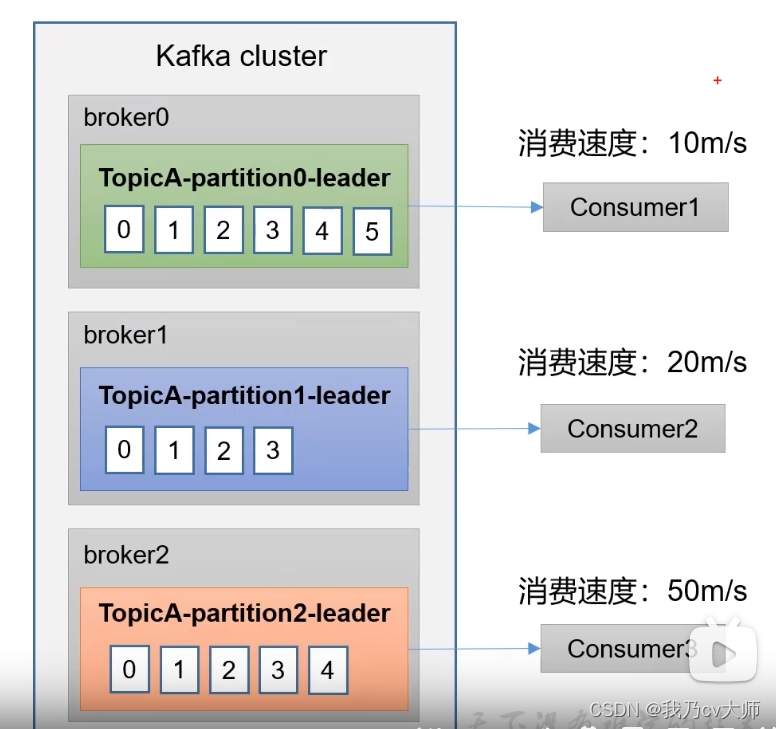
pull模式
消费者从kafka集群中的broker主动拉取数据,根据消费者自身处理信息的能力来定义
不足之处是如果kafka没有数据,消费者可能陷入循环,一直返回空数据。
push模式
由kafka集群中的broker主动向消费者推送数据(根据kafka集群的broker的推送能力来决定)。kafka并没有采用这种方式,因为由broker决定消息发送速率,很难适应所有消费者的消费速率,可能由部分消费者来不及处理消息。
4.2.2 kafka消费者总体工作流程
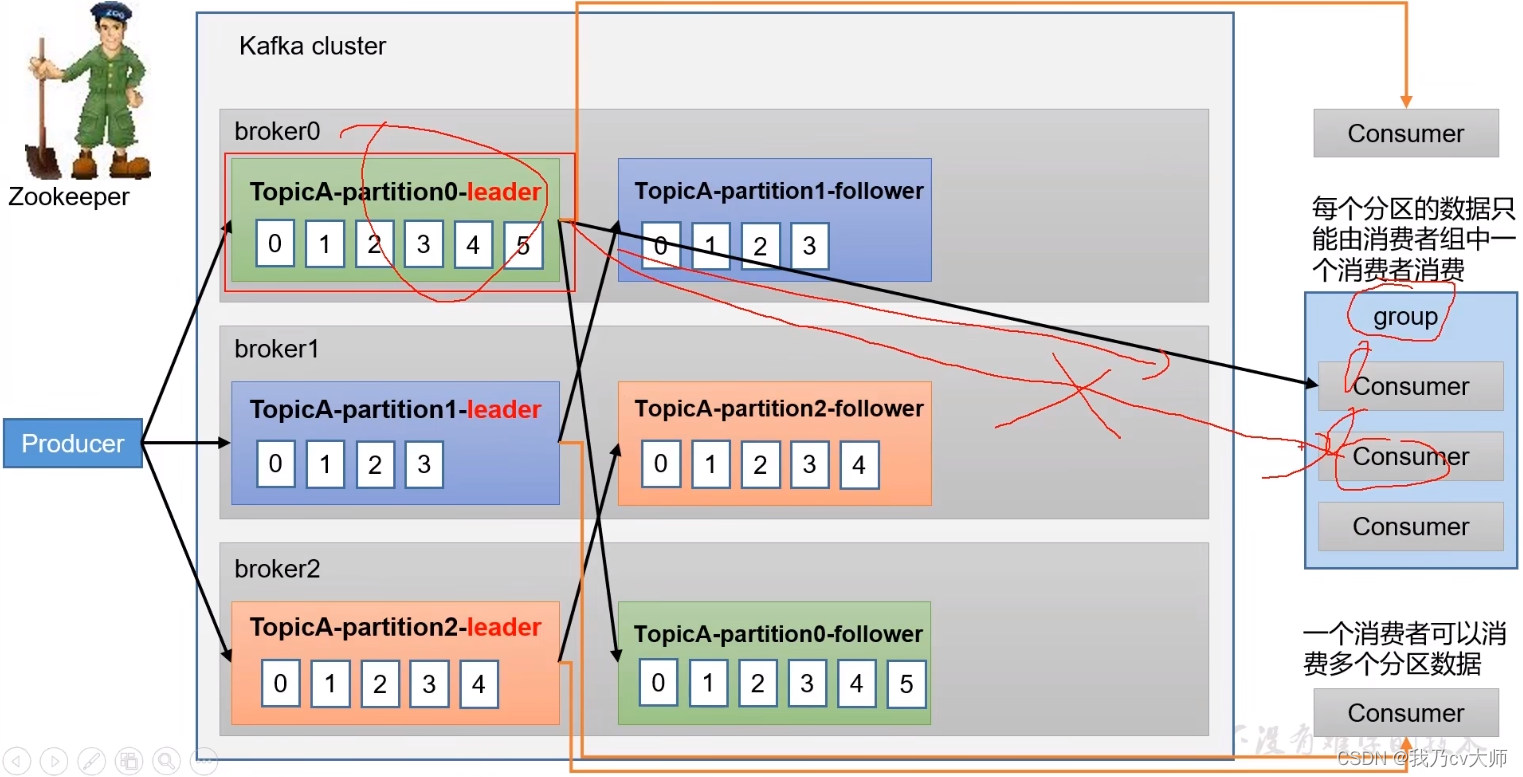
确定消费原则:
1、每个分区的数据只能由消费者组中的一个消费者消费
2、一个消费者可以消费多个分区的数据
3、每个消费者的offset由消费者提交到系统主题中保存,而并非保存在消费者的内部
4.2.3 什么是消费者组
消费者组:由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同
1、消费者组内每个消费者消费不同分区的数据,一个分区只能由一个组内消费者消费
2、消费者组之间互不影响。所有消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
3、如果向消费者组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置,不会接收任何消息。
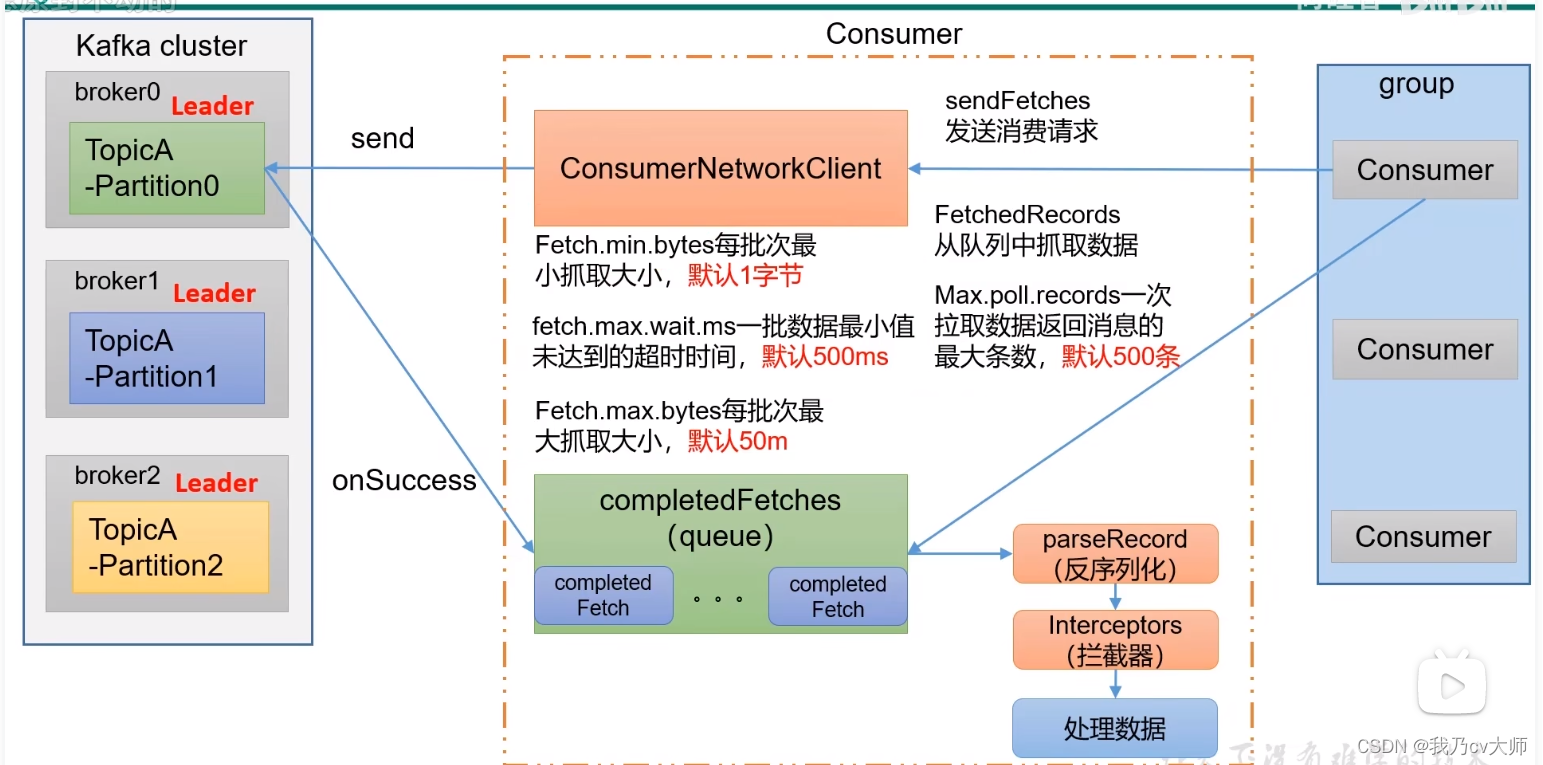
4.2.4 消费者的详细流程
1、消费者组发送消费请求给消费者网络连接客户端,网络连接客户端向kafka集群的broker发送send请求;
2、broker收到请求,会发送消息进一个消息队列中
3、消费者会从这个消息队列中拉取消息,首先将消息进行反序列化,再经过拦截器,最后进行数据的消费处理。
4.2.5 重复消费和漏消费
重复消费:由自动提交offset引起的
可以举个例子:
一个消费者每隔五秒,向broker自动提交offset;但是突然消费者挂了,即原本计划是要从2消费到“4’的,但是消费者消费到3的时候挂掉了;等到消费者恢复后,又要重新从2这个消息开始消费了,这就是重复消费。
漏消费:
设置offset为手动提交,当offset被提交时,数据还在内存中未落盘,此时消费者线程被kill,那么offset已经提交,但是数据并未处理,导致这部分内存的数据丢失。
解决方法:
采用消费者事务
下游消费者必须支持事务,才能做到精确一次性消费。
如果想要完成Consumer端的精确一次性消费,那么需要Kafka消费端将消费过程和提交offset过程做原子绑定。此时我们需要将kafka的offset保存到支持事务的自定义介质(比如MYSQL)中
4.2.6 消费积压
什么是消费积压:即生产者生产过多消息,消费者来不及消费,导致消息积攒越来越多,这就是消费积压。
如何解决消费积压问题呢:
1、如果是kafka消费能力不足,则可以考虑增加topic的分区数,并且提升消费者组的数量,使得消费组数=分区数
2、如果是下游的数据处理不及时:提高每批次拉取的数据。批次拉取数据过少(拉取数据/处理时间<生产速度)使得处理的数据小于生产的数据,也会造成数据积压。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









