







基于keras+keras-bert构建bert-textcnn模型实现多标签文本分类
跑别人的代码,最痛苦的莫不在于环境有错误、代码含义不懂。自己从头到尾尝试了一遍,过程很艰难,为了方便同样在学习的朋友,在这里,我会在项目文件中提供详细的requirements,保证你能一次性跑成功。此外,每个部分我都会尽可能的添加详细的注释,使得读者能够知道每一步的意义和结果。
前言
-
什么是bert?
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT是2018年Google AI Language提出的一种预训练语言模型。BERT通过联合调节所有层的左右上下文来预训练来自未标记文本的深度双向表示。因此,预训练的 BERT 模型可以通过一个额外的输出层进行微调,从而为各种任务(例如问答和语言推理)创建最先进的模型,而无需对特定于任务的架构进行大量修改。BERT 在概念上很简单,在经验上很强大。它在 11 个自然语言处理任务上获得了新的 state-of-the-art 结果,是NLP发展的里程碑。
-
什么是textcnn?
Convolutional Neural Network for Sentence Classification
TextCNN是Yoon Kim在2014年将CNN网络应用于句子级的文本分类所提出的结构。如下图所示,TextCNN利用多个不同的kernel size来提取句子中的关键信息,不同的kernel size的结果进行拼接进行pooling操作,以更好的获取文本的局部特征。
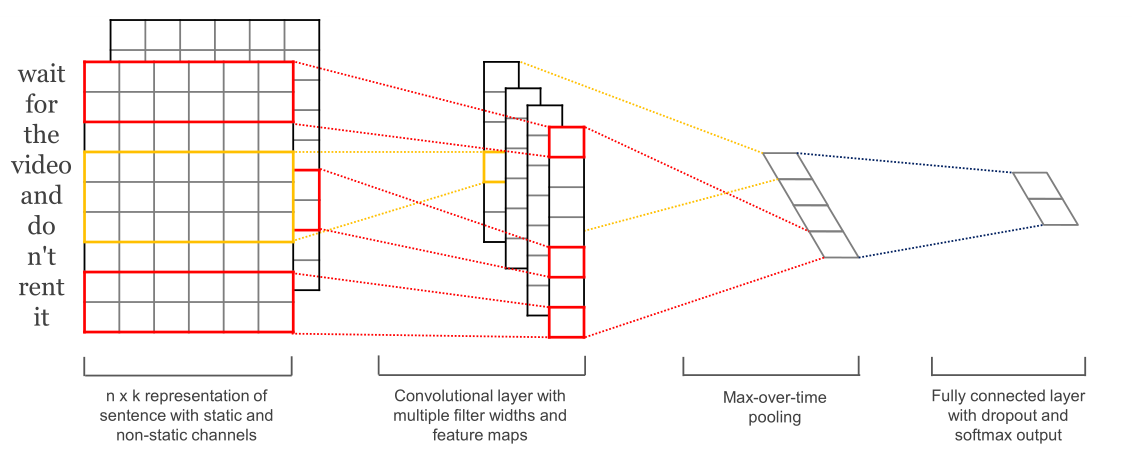
-
本项目中,我首先利用BERT输出句子的嵌入表示,然后将嵌入表示结果输入构造好的多尺寸TextCNN中进行特征提取,并用作最后的分类。
数据介绍
项目数据用的是2020语言与智能技术竞赛:事件抽取任务,数据我会直接放在项目的[data]文件夹中。
-
数据的基本结构:文本对应标签与文本之间用空格隔开,多个标签之间用|隔开。
组织关系-裁员 雀巢裁员4000人:时代抛弃你时,连招呼都不会打! 组织关系-裁员 美国“未来为”子公司大幅度裁员,这是为什么呢?任正非正式回应 组织关系-裁员 这一全球巨头“凉凉”“捅刀”华为后裁员5000现市值缩水800亿 组织关系-裁员 被证实将再裁员1800人AT&T在为落后的经营模式买单 组织关系-裁员 又一网约车巨头倒下:三个月裁员835名员工,滴滴又该何去何从 组织关系-裁员 8月20日消息,据腾讯新闻《一线》报道,知情人士表示,为了控制成本支出,蔚来计划将美国分公司的人员规模除自动驾驶业务相关人员外,减少至200人左右。截至美国时间8月16日,蔚来位于美国硅谷的分公司已裁减100名员工。 司法行为-起诉|组织关系-裁员 最近,一位前便利蜂员工就因公司违规裁员,将便利蜂所在的公司虫极科技(北京)有限公司告上法庭。 -
数据集的基本信息
模型搭建
-
构建包含多个kernel size的TextCNN网络。
def textcnn(inputs): # 选用3、4、5三个卷积核进行特征提取,最后拼接后输出用于分类。 kernel_size = [3, 4, 5] cnn_features = [] for size in kernel_size: cnn = keras.layers.Conv1D(filters=256, kernel_size=size)(inputs) # shape=[batch_size,maxlen-2,256] cnn = keras.layers.GlobalMaxPooling1D()(cnn) # shape=[batch_size,256] cnn_features.append(cnn) # 对kernel_size=3、4、5时提取的特征进行拼接 output = keras.layers.concatenate(cnn_features, axis=-1) # [batch_size,256*3] # 返回textcnn提取的特征结果 return output -
构建bert_textcnn模型。
-
首先利用keras-bert加载预训练好的bert,这里用的bert是哈工大训练的chinese_bert_wwm_L-12_H-768_A-12。
-
取出bert的输出中的[cls]向量,[cls]可以直接用于分类,也可以与其它网络的输出拼接。
-
取出bert输出中关于输入句子的表示(word_embedding),bert在输入时在句子的头和尾分类添加了一个[CLS]、[SEP],可以选择去除这两个标志。
-
将word_embedding输入构造好的多kernel size的TextCNN网络,获得经由TextCNN获得特征(cnn_features)。
-
将[cls]与cnn_features进行拼接后用于分类。
-
根据输入和输出封装模型,并进行必要参数的配置。
-
模型最后的结果如下所示(bert仅展示最后一层):
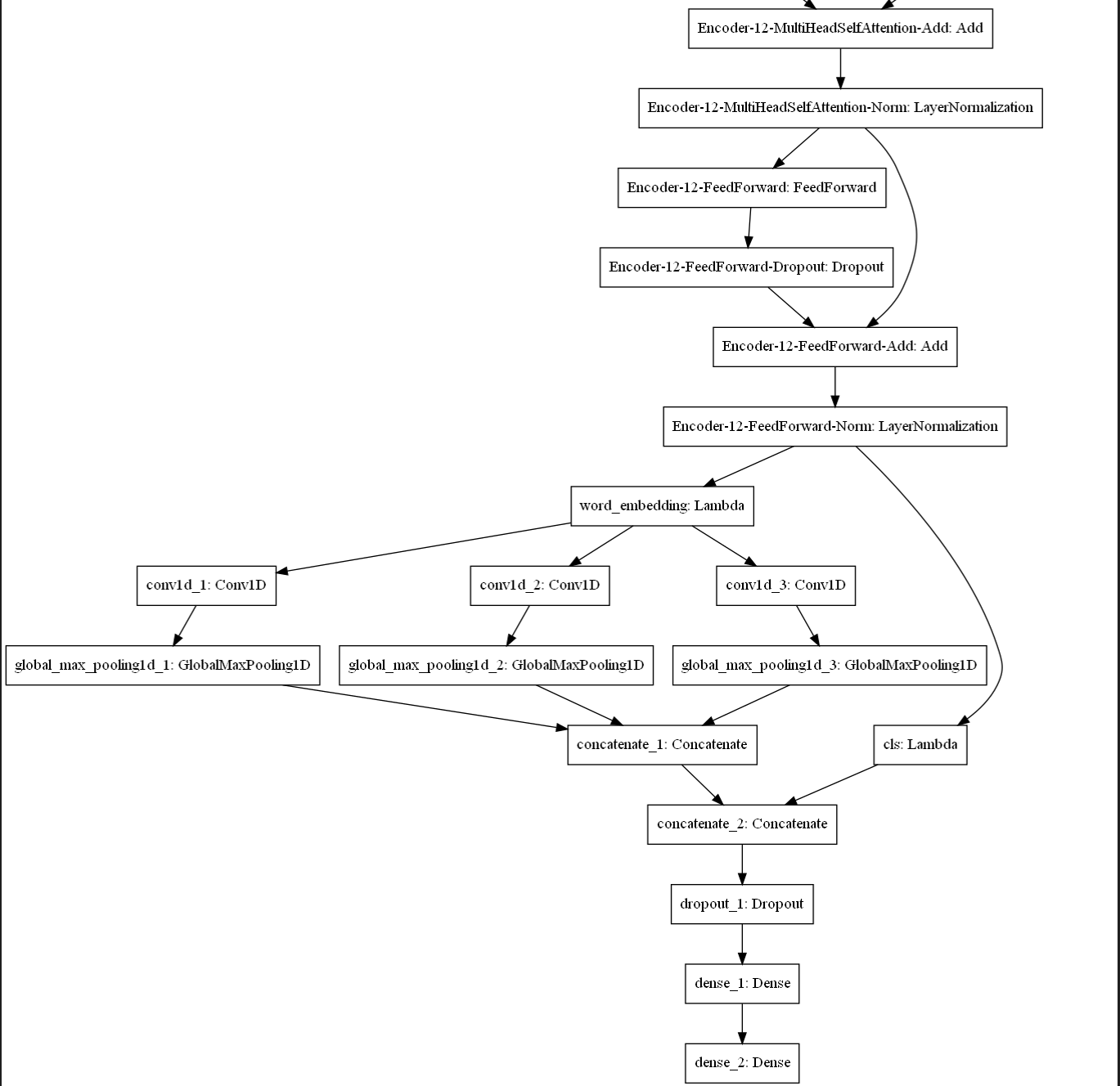
-
详细代码如下:
def build_bert_textcnn_model(config_path, checkpoint_path, class_nums): """ :param config_path: bert_config.json所在位置。 :param checkpoint_path: bert_model.ckpt所在位置。 :param class_nums: 最终模型的输出的维度(分类的类别)。 :return:返回搭建好的模型。 """ # 加载预训练好的bert bert = load_trained_model_from_checkpoint( config_file=config_path, checkpoint_file=checkpoint_path, seq_len=None ) # 取出[cls],可以直接用于分类,也可以与其它网络的输出拼接。 cls_features = keras.layers.Lambda( lambda x: x[:, 0], name='cls' )(bert.output) # shape=[batch_size,768] # 去除第一个[cls]和最后一个[sep],得到输入句子的embedding,用作textcnn的输入。 word_embedding = keras.layers.Lambda( lambda x: x[:, 1:-1], name='word_embedding' )(bert.output) # shape=[batch_size,maxlen-2,768] # 将句子的embedding,输入textcnn,得到经由textcnn提取的特征。 cnn_features = textcnn(word_embedding) # shape=[batch_size,cnn_output_dim] # 将cls特征与textcnn特征进行拼接。 all_features = keras.layers.concatenate([cls_features, cnn_features], axis=-1) # shape=[batch_size,cnn_output_dim+768] # 应用dropout缓解过拟合的现象,rate一般在0.2-0.5。 all_features = keras.layers.Dropout(0.2)(all_features) # shape=[batch_size,cnn_output_dim+768] # 降维 dense = keras.layers.Dense(units=256, activation='relu')(all_features) # shape=[batch_size,256] # 输出结果 output = keras.layers.Dense( units=class_nums, activation='sigmoid' )(dense) # shape=[batch_size,class_nums] # 根据输入和输出构建构建模型 model = keras.models.Model(bert.input, output, name='bert-textcnn') model.compile( loss='binary_crossentropy', optimizer=keras.optimizers.Adam(config.learning_rate), metrics=['accuracy'] ) return model
模型训练
模型的训练大致有以下4步:
- 加载训练集、测试集的数据。
- 对训练集的文本、标签;测试集的文本、标签分别进行编码。
- 初始化模型,将训练集、测试集的编码结果送入模型开始训练。
- 绘制训练过程中的训练与验证的loss与acc图像(可选)。
-
加载训练集
# 用以加载数据 def load_data(txt_file_path): text_list = [] label_list = [] with open(txt_file_path, 'r', encoding='utf-8') as f: for line in f.readlines(): line = line.strip().split() label_list.append(line[0].split('|')) text_list.append(line[1]) return text_list, label_list -
对文本编码
对文本编码需要弄清楚,输入给bert的是什么,bert的输入需要token_id与segment_id,是tokenizer操作后的返回值。
# 加载bert字典,构造分词器。 token_dict = load_vocabulary(config.bert_dict_path) tokenizer = Tokenizer(token_dict) # 对文本编码 def encoding_text(content_list): token_ids = [] segment_ids = [] for line in tqdm(content_list): # max_len是用于保证所有的输入长度一致,长度不足时会补0,长度超过时会截断。 token_id, segment_id = tokenizer.encode(first=line, max_len=config.max_len) token_ids.append(token_id) segment_ids.append(segment_id) # 输入给模型的数据不能是list,这里需要做一下转换编程array。 encoding_res = [np.array(token_ids), np.array(segment_ids)] return encoding_res -
主函数
if __name__ == "__main__": # 读取训练集与测试集 train_content_x, train_label_y = load_data(config.train_dataset_path) test_content_x, test_label_y = load_data(config.test_dataset_path) # 打乱训练集的数据 index = [i for i in range(len(train_content_x))] random.shuffle(index) # 打乱索引表 # 按打乱后的索引,重新组织训练集 train_content_x = [train_content_x[i] for i in index] train_label_y = [train_label_y[i] for i in index] # 对训练集与测试集的文本编码 train_x = encoding_text(train_content_x) test_x = encoding_text(test_content_x) # 对标签集编码(调用sklearn的多标签编码器) mlb = MultiLabelBinarizer() mlb.fit(train_label_y) # 保存此时的mlb,后面在预测时评估时需要加载标签集。 pickle.dump(mlb, open('./data/mlb.pkl', 'wb')) # 分别对训练集和测试集的标签进行编码,并转换为array。 train_y = np.array(mlb.transform(train_label_y)) test_y = np.array(mlb.transform(test_label_y)) # 初始化模型,并输出模型的结果 model = build_bert_textcnn_model(config.bert_config_path, config.bert_checkpoint_path, len(mlb.classes_)) model.summary() # 开始模型的训练,并保存训练的历史数据(loss、accuracy)用以最后绘图 history = model.fit(train_x, train_y, validation_data=(test_x, test_y), batch_size=config.batch_size, epochs=config.epochs) # 保存模型为h5 model.save("./model/bert_textcnn.h5") # 训练过程可视化 # 绘制训练loss和验证loss的对比图 plt.subplot(2, 1, 1) epochs = len(history.history['loss']) plt.plot(range(epochs), history.history['loss'], label='loss') plt.plot(range(epochs), history.history['val_loss'], label='val_loss') plt.legend() # 绘制训练acc和验证acc的对比图 plt.subplot(2, 1, 2) epochs = len(history.history['accuracy']) plt.plot(range(epochs), history.history['accuracy'], label='acc') plt.plot(range(epochs), history.history['val_accuracy'], label='val_acc') plt.legend() # 保存loss与acc对比图 plt.savefig("./model/bert-textcnn-loss-acc.png")
模型评估
模型评估大致有以下几步:
-
加载评估集(测试集)。
-
对评估集中数据逐条预测保存预测结果。
-
计算accuracy,调用classification_report输出各个标签的详细评估结果,调用hamming_loss输出汉明损失。
-
详细代码及注释如下:
# 加载bert字典,构造分词器。 token_dict = load_vocabulary(config.bert_dict_path) tokenizer = Tokenizer(token_dict) # 加载训练好的模型 model = load_model('./model/bert_textcnn.h5', custom_objects=get_custom_objects()) mlb = pickle.load(open('./data/mlb.pkl', 'rb')) def load_data(txt_file_path): text_list = [] label_list = [] with open(txt_file_path, 'r', encoding='utf-8') as f: for line in f.readlines(): line = line.strip().split() label_list.append(line[0].split('|')) text_list.append(line[1]) return text_list, label_list def predict_single_text(text): # 编码后得出句子给bert的输入 token_id, segment_id = tokenizer.encode(first=text, max_len=config.max_len) # 得到预测结果 prediction = model.predict([[token_id], [segment_id]])[0] # 这里以阈值0.5进行标签的筛选,取出值大于0.5标签的索引 indices = [i for i in range(len(prediction)) if prediction[i] > 0.5] # 将索引转换为最终的标签集 lables = [mlb.classes_.tolist()[i] for i in indices] # 输出最后结果的编码,用以评估 one_hot = np.where(prediction > 0.5, 1, 0) return one_hot, lables def evaluate(): test_x, test_y = load_data(config.test_dataset_path) true_y_list = mlb.transform(test_y) pred_y_list = [] pred_labels = [] for text in tqdm(test_x): pred_y, label = predict_single_text(text) pred_y_list.append(pred_y) pred_labels.append(label) # 计算accuracy,一条数据的所有标签全部预测正确则1,否则为0。 test_len = len(test_y) correct_count = 0 for i in range(test_len): if test_y[i] == pred_labels[i]: correct_count += 1 accuracy = correct_count / test_len print(classification_report(true_y_list, pred_y_list, target_names=mlb.classes_.tolist(), digits=4)) print("accuracy:{}".format(accuracy)) print("hamming_loss:{}".format(hamming_loss(true_y_list, pred_y_list))) if __name__ == "__main__": evaluate() -
评估结果下所示:
label precision recall f1-score support 交往-会见 1.0000 1.0000 1.0000 12 交往-感谢 1.0000 0.8750 0.9333 8 交往-探班 1.0000 0.9000 0.9474 10 交往-点赞 0.8889 0.7273 0.8000 11 交往-道歉 0.8182 0.9474 0.8780 19 产品行为-上映 0.9697 0.9143 0.9412 35 产品行为-下架 1.0000 1.0000 1.0000 24 产品行为-发布 0.9481 0.9733 0.9605 150 产品行为-召回 1.0000 1.0000 1.0000 36 产品行为-获奖 1.0000 0.9375 0.9677 16 人生-产子/女 0.8667 0.8667 0.8667 15 人生-出轨 1.0000 0.5000 0.6667 4 人生-分手 1.0000 0.9333 0.9655 15 人生-失联 1.0000 0.9286 0.9630 14 人生-婚礼 1.0000 0.6667 0.8000 6 人生-庆生 1.0000 0.8750 0.9333 16 人生-怀孕 1.0000 0.5000 0.6667 8 人生-死亡 0.9510 0.9151 0.9327 106 人生-求婚 1.0000 1.0000 1.0000 9 人生-离婚 0.9394 0.9394 0.9394 33 人生-结婚 0.9655 0.6512 0.7778 43 人生-订婚 1.0000 0.7778 0.8750 9 司法行为-举报 1.0000 1.0000 1.0000 12 司法行为-入狱 0.9000 1.0000 0.9474 18 司法行为-开庭 0.9231 0.8571 0.8889 14 司法行为-拘捕 0.9770 0.9659 0.9714 88 司法行为-立案 1.0000 1.0000 1.0000 9 司法行为-约谈 0.9697 1.0000 0.9846 32 司法行为-罚款 1.0000 0.8966 0.9455 29 司法行为-起诉 0.8750 1.0000 0.9333 21 灾害/意外-地震 1.0000 1.0000 1.0000 14 灾害/意外-坍/垮塌 1.0000 0.8000 0.8889 10 灾害/意外-坠机 1.0000 1.0000 1.0000 13 灾害/意外-洪灾 1.0000 0.7143 0.8333 7 灾害/意外-爆炸 1.0000 1.0000 1.0000 9 灾害/意外-袭击 0.8000 0.7500 0.7742 16 灾害/意外-起火 0.9643 1.0000 0.9818 27 灾害/意外-车祸 0.9394 0.8857 0.9118 35 竞赛行为-夺冠 0.8214 0.8214 0.8214 56 竞赛行为-晋级 0.8421 0.9697 0.9014 33 竞赛行为-禁赛 0.8824 0.9375 0.9091 16 竞赛行为-胜负 0.9722 0.9859 0.9790 213 竞赛行为-退役 0.9167 1.0000 0.9565 11 竞赛行为-退赛 0.8333 0.8333 0.8333 18 组织关系-停职 0.8462 1.0000 0.9167 11 组织关系-加盟 0.9231 0.8780 0.9000 41 组织关系-裁员 0.9474 0.9474 0.9474 19 组织关系-解散 0.9000 0.9000 0.9000 10 组织关系-解约 0.8000 0.8000 0.8000 5 组织关系-解雇 1.0000 0.3077 0.4706 13 组织关系-辞/离职 0.9221 1.0000 0.9595 71 组织关系-退出 0.8333 0.9091 0.8696 22 组织行为-开幕 0.9394 0.9688 0.9538 32 组织行为-游行 1.0000 0.8889 0.9412 9 组织行为-罢工 1.0000 0.8750 0.9333 8 组织行为-闭幕 1.0000 0.7778 0.8750 9 财经/交易-上市 1.0000 0.8571 0.9231 7 财经/交易-出售/收购 1.0000 0.9167 0.9565 24 财经/交易-加息 1.0000 0.3333 0.5000 3 财经/交易-涨价 0.8000 0.8000 0.8000 5 财经/交易-涨停 1.0000 1.0000 1.0000 27 财经/交易-融资 1.0000 1.0000 1.0000 14 财经/交易-跌停 0.9333 1.0000 0.9655 14 财经/交易-降价 1.0000 0.6667 0.8000 9 micro avg 0.9450 0.9234 0.9341 1657 macro avg 0.9509 0.8780 0.9029 1657 weighted avg 0.9476 0.9234 0.9309 1657 samples avg 0.9302 0.9347 0.9265 1657 accuracy:0.8344459279038718 hamming_loss:0.002218342405258293
模型预测
-
模型预测其实就是将evaluate中的部分操作单独出来,具体的代码如下所示
# 加载bert字典,构造分词器。 token_dict = load_vocabulary(config.bert_dict_path) tokenizer = Tokenizer(token_dict) # 加载训练好的模型 model = load_model('./model/bert_textcnn.h5', custom_objects=get_custom_objects()) mlb = pickle.load(open('./data/mlb.pkl', 'rb')) # 预测单个句子的标签 def predict_single_text(text): token_id, segment_id = tokenizer.encode(first=text, max_len=config.max_len) prediction = model.predict([[token_id], [segment_id]])[0] indices = [i for i in range(len(prediction)) if prediction[i] > 0.5] lables = [mlb.classes_.tolist()[i] for i in indices] return "|".join(lables) if __name__ == "__main__": text = "美的置业:贵阳项目挡墙垮塌致8人遇难已责令全面停工" result = predict_single_text(text) print(result)
项目结构、下载、使用方法
-
项目结构
BERT-TEXTCNN-MULTI-LABEL-TEXT-CLASSFICATION │ bert_textcnn_model.py # 构建模型的文件 │ config.py # 项目的相关配置及参数文件 │ model_evaluate.py # 用于模型评估的文件 │ model_predict.py # 用于模型预测的文件 │ model_train.py # 用于模型训练的文件 │ requirements.txt # 项目所需的环境依赖(python3.6下直接运行安装本文件里的所有依赖可以稳定运行) │ ├─chinese_bert_wwm_L-12_H-768_A-12 # 预训练的bert模型,使用时需要自行去下载后复制到项目中。 │ bert_config.json │ bert_model.ckpt.data-00000-of-00001 │ bert_model.ckpt.index │ bert_model.ckpt.meta │ vocab.txt │ ├─data # 数据集 │ mlb.pkl # 训练时生成(项目中已移除) │ multi-classification-test.txt │ multi-classification-train.txt │ ├─model # 此文件夹需自行新建 │ bert-textcnn-loss-acc.png # 训练时的loss-acc图像(运行model_train.py可得) │ bert_textcnn.h5 # 训练得到的模型(运行model_train.py可得) │ model.png # 模型结构图(运行bert_textcnn_model.py可得) └─ -
项目下载地址














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









