






报错时检查维度
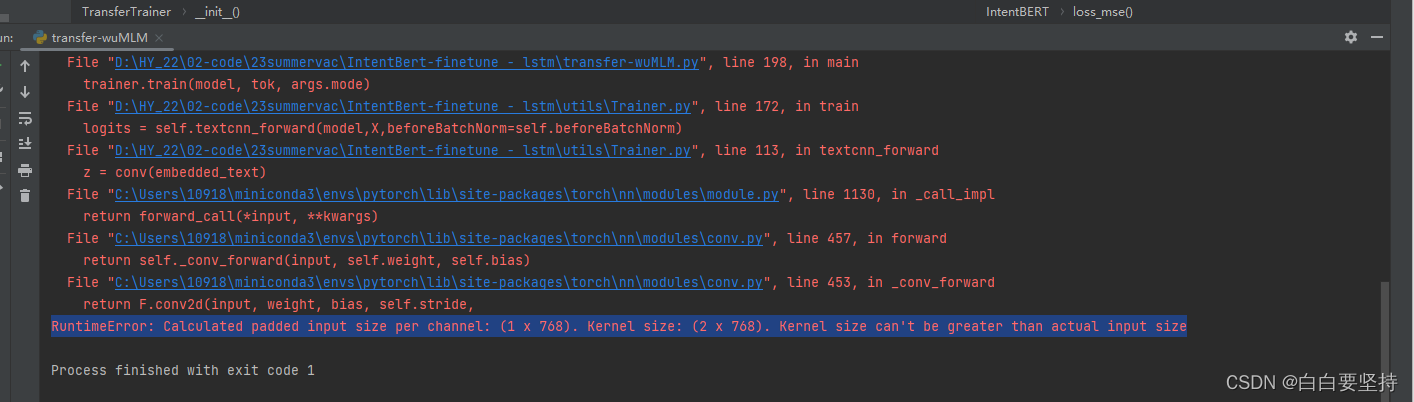
过程中报过2个主要错误
第一个expected input [1,32,768] to have 1 channel, but got 32 channels instead.
第二个calculated padded input size per channel: (1*768)...kernel size can't be greater than actaual input size.
但是实际上是textcnn输入维度的错误
这里模型的第4行,输出是有两个,两个的维度不同。对于textCNN来说,输入的维度是3维,如前者。对于LSTM来说,输入是后者
# encoder_out:[batch_size,seq_len,hidden_size],text_cls:[batch_size,hidden_size]
def forward(self, x): # x:{[batch_size,seq_len],[batch_size,],[batch_size,seq_len]}
context = x[0] # context:[batch_size,seq_len],输入的句子
mask = x[2] # mask:[bacth_size,seq_len],对padding部分进行mask
encoder_out, text_cls = self.bert(context, attention_mask=mask, output_all_encoded_layers=False) # encoder_out:[batch_size,seq_len,hidden_size],text_cls:[batch_size,hidden_size]
out = encoder_out.unsqueeze(1) # out:[batch_size,1,seq_len,hidden_size]
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1) # out:[batch_size,num_filters * len(filter_sizes)]
out = self.dropout(out)
out = self.fc_cnn(out) # out:[batch_size,num_class]
return out这部分代码
作者:影子
链接:https://www.zhihu.com/question/477075127/answer/2731541347
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
可运行代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextCNNBert(nn.Module):
def __init__(self, vocab_size, embedding_size, num_classes):
super(TextCNNBert, self).__init__()
self.filter_sizes = [2, 3, 4]
num_filter = 2
self.num_filters_total = num_filter * len(self.filter_sizes)
# 卷积核打包
self.filter_list = nn.ModuleList(
[nn.Conv2d(1, num_filter, (size, 768)) for size in self.filter_sizes])
self.dropout = nn.Dropout(0.5)
self.fc = nn.Linear(num_filter * len(self.filter_sizes), num_classes) #
def forward(self, x):
x = x.float()
x = x.unsqueeze(1) # ( 输入,输出 )
pooled_outputs = []
# 卷积运算
for i, conv in enumerate(self.filter_list):
conv_feature = F.relu(conv(x)) # 得到卷积后的特征
# 定义池化层
maxp = nn.MaxPool2d((x.shape[2] - self.filter_sizes[i] + 1, 1)) # 其中x.shape[1]代表句子的长度,
# self.filter_sizes[i]代表卷积核的宽度,1代表词语嵌入的维度
pooled = maxp(conv_feature).permute(0, 3, 2, 1) # 在进行最大池化之后,得到的张量是四维的,
# 包括了样本数、通道数、池化后的高度和宽度。而在这里,作者想要将高度和宽度的维度交换,
# 即从(样本数、通道数、高度、宽度)变为(样本数、宽度、高度、通道数)的形式。
# 这是为了后续的拼接操作,将不同窗口大小的池化结果按通道方向拼接,方便进行全连接层的处理。
pooled_outputs.append(pooled)
# 池化层的拼接
feature = torch.cat(pooled_outputs, len(self.filter_sizes)) # 在第3个维度上拼接起来,即在不同卷积核尺寸的特征图之间进行拼接。
# 改变尺寸
feature = torch.reshape(feature, [-1, self.num_filters_total])
# dropout
feature = self.dropout(feature)
outs = self.fc(feature)
return outs














 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









