







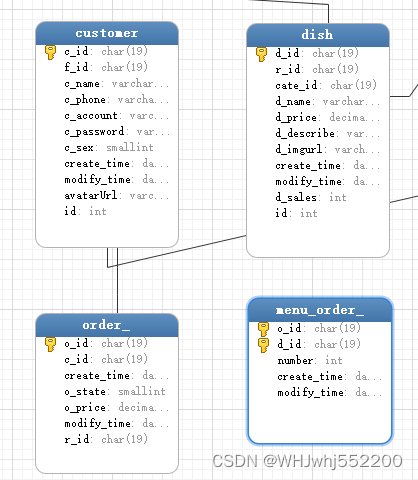
1、业务数据表说明
顾客与订单是一对多的关系;订单与菜品是多对多的关系,所以还有一张关系表menu_order_;
2、从数据库查询并构建训练集
现在需要从这四张表联合查询查出 每一个顾客的下单菜品的数量。
1)存着每个顾客的下单菜品的菜品id和此菜品的下单次数。
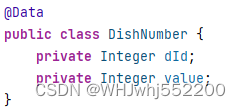
2)先查出所有顾客customers,再查出每一个顾客的下单菜品的菜品id和此菜品的下单次数,写出到文件中(filename1是不带评分的数据,即userId-dishId;而filename2是userId-dishId-value)。
@PostConstruct
public void getUserItems() {
try (Writer w1 = new BufferedWriter(new FileWriter(filename1));
Writer w2 = new BufferedWriter(new FileWriter(filename2))) {
// 查询所有用户
List<Customer> customers = customerMapper.selectList(null);
// 查询所有用户的下单菜品记录
for (Customer customer : customers) {
List<DishNumber> dishNumbers = orderMapper.getUserOrderDishes(customer.getCId());
if (dishNumbers.size() == 0)
continue;
for (DishNumber d : dishNumbers) {
w1.write(customer.getId() + "," + d.getDId() + "\n");
w2.write(customer.getId() + "," + d.getDId() + "," + d.getValue() + "\n");
}
}
w1.flush();
w2.flush();
} catch (IOException e) {
e.printStackTrace();
}
}getUserDishes的sql语句:根据cId查询结果。
<select id="getUserOrderDishes" resultType="com.firstGroup.restaurant.model.vo.DishNumber">
select d.id dId, count(*) value
from menu_order_ mo, order_ o, customer c, dish d
where o.c_id=c.c_id and mo.o_id=o.o_id and d.d_id=mo.d_id and o.c_id = #{cId}
group by d.d_id
</select>3)生成的训练集(数据时随意测试的,没有参考性)
数据说明:顾客id=1:下单菜品id=1,61次;菜品id=2,1次;菜品id=3,1次
filename1; filename2


3、使用Mahout实现基于用户的协调过滤推荐算法
1)有用户评分的:
/*
* @Author Haojie
* @Description 有评分的基于用户的协同过滤推荐算法
* @Param
* @return
**/
private List<Dish> userCFWithoutRecommend(String cId, Integer number) throws Exception {
// 建立数据模型,包含用户评分
DataModel dm = new GenericDataModel(
GenericDataModel
.toDataMap(new FileDataModel(new File(filename2))));
// 使用曼哈顿距离计算类似度
UserSimilarity us = new EuclideanDistanceSimilarity(dm);
//指定NearestNUserNeighborhood做为近邻算法
UserNeighborhood unb = new NearestNUserNeighborhood(10, us, dm);
// 构建包含用户评分的UserCF推荐器
Recommender re = new GenericUserBasedRecommender(dm, unb, us);
// 返回推荐结果,为cId用户推荐number个商品
Integer id = customerMapper.selectById(cId).getId();
List<RecommendedItem> list = re.recommend(id, number);
List<Dish> dishes = new ArrayList<>();
System.out.println("根据用户cId=" + cId + ", userId=" + id + "的点餐习惯,推荐的前" + number + "个菜品的id和推荐度如下:");
for (RecommendedItem recommendedItem : list) {
System.out.println(recommendedItem.getItemID() + " : " + recommendedItem.getValue());
dishes.add(dishMapper.selectOne(new LambdaQueryWrapper<Dish>().eq(Dish::getId,
recommendedItem.getItemID())));
}
return dishes;
}2)无用户评分的:
/*
* @Author Haojie
* @Description 无评分的基于用户的协同过滤推荐算法
* @Param
* @return
**/
private List<Dish> userCFWithoutScoreRecommend(String cId, Integer number) throws Exception {
// 建立数据模型,不包含用户评分
DataModel dm = new GenericDataModel(
GenericDataModel
.toDataMap(new FileDataModel(new File(filename1))));
// 使用曼哈顿距离计算类似度
UserSimilarity us = new CityBlockSimilarity(dm);
//指定NearestNUserNeighborhood做为近邻算法
UserNeighborhood unb = new NearestNUserNeighborhood(5, us, dm);
// 构建不包含用户评分的UserCF推荐器
Recommender re = new GenericBooleanPrefUserBasedRecommender(dm, unb, us);
// 返回推荐结果,为cId用户推荐number个商品
Integer id = customerMapper.selectById(cId).getId();
List<RecommendedItem> list = re.recommend(id, number);
List<Dish> dishes = new ArrayList<>();
System.out.println("根据用户cId=" + cId + ", userId=" + id + "的点餐习惯,推荐的前" + number + "个菜品的id和推荐度如下:");
for (RecommendedItem recommendedItem : list) {
System.out.println(recommendedItem.getItemID() + " : " + recommendedItem.getValue());
dishes.add(dishMapper.selectOne(new LambdaQueryWrapper<Dish>().eq(Dish::getId,
recommendedItem.getItemID())));
}
return dishes;
}最终都可以返回推荐的菜品数据。
问题
实现起来非常简单,但是有非常大的问题,那就是训练的数据只有id和评分,数据太少了;应该是整个菜品的属性,菜品分类,用户属性等等都拿去训练才比较合理。
参考:
1、Mahout实践,协同过滤算法介绍:
Java实现算法推荐:Mahout实践 - JavaShuo
2、具体实战:
Mahout推荐算法编程实践-demo说明 - JavaShuo
3、其他参考

















 829
829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









